Physician scientist - Immunology of Reproduction. Clinical REI. Tech and algos push sci boundary. Re-tweet not endorsement. Comments are personal opinions.
- Tweets 1,928
- Following 2,017
- Followers 757
- Likes 4,550









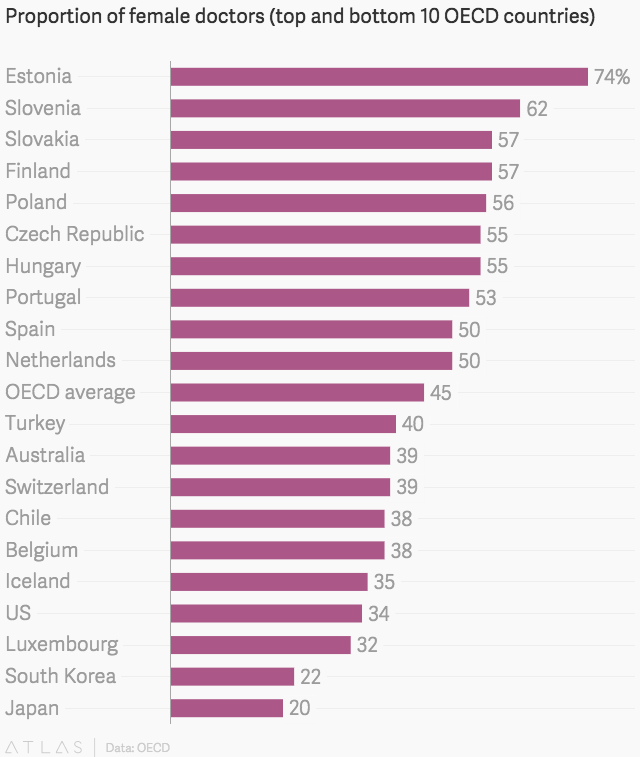










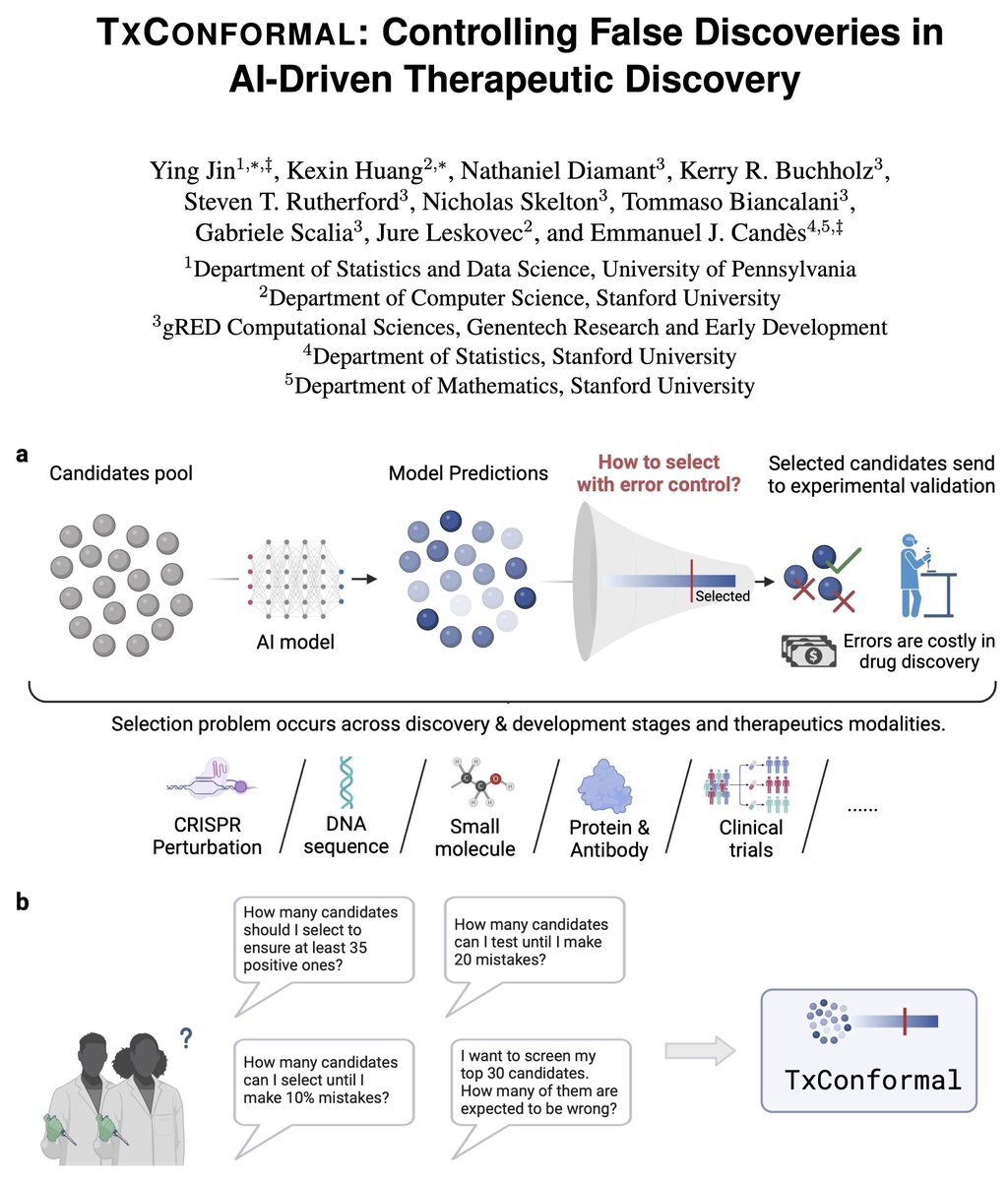
ALT Graphic with banner that reads "2026 Faculty Promotions" and includes portraits and names of five UW Department of Ob-Gyn faculty who were promoted in the 2025-26 academic year.










ALT Graphic advertising the UW Department of Ob-Gyn Department Research Day keynote presentation "Updates on Chronic Hypertension and Pregnancy - CHAP Trial", given by Alan Thevenet Tita, MD, on May 21, 2026.



ALT Three individuals in an interior room

ALT Two individuals standing outside of the US Capitol

ALT Three individuals standing in front of a large Wisconsin state flag in an interior room

ALT Three indivduals standing together with an American Flag in the background.