
Professor of Law, Economics, and Business at @ETH Zurich. Associated with @ETH_CLE, Interested in #contractdesign, #lawecon, #lawtech
Joined October 2017
- Tweets 231
- Following 323
- Followers 479
- Likes 147
21 Photos and videos





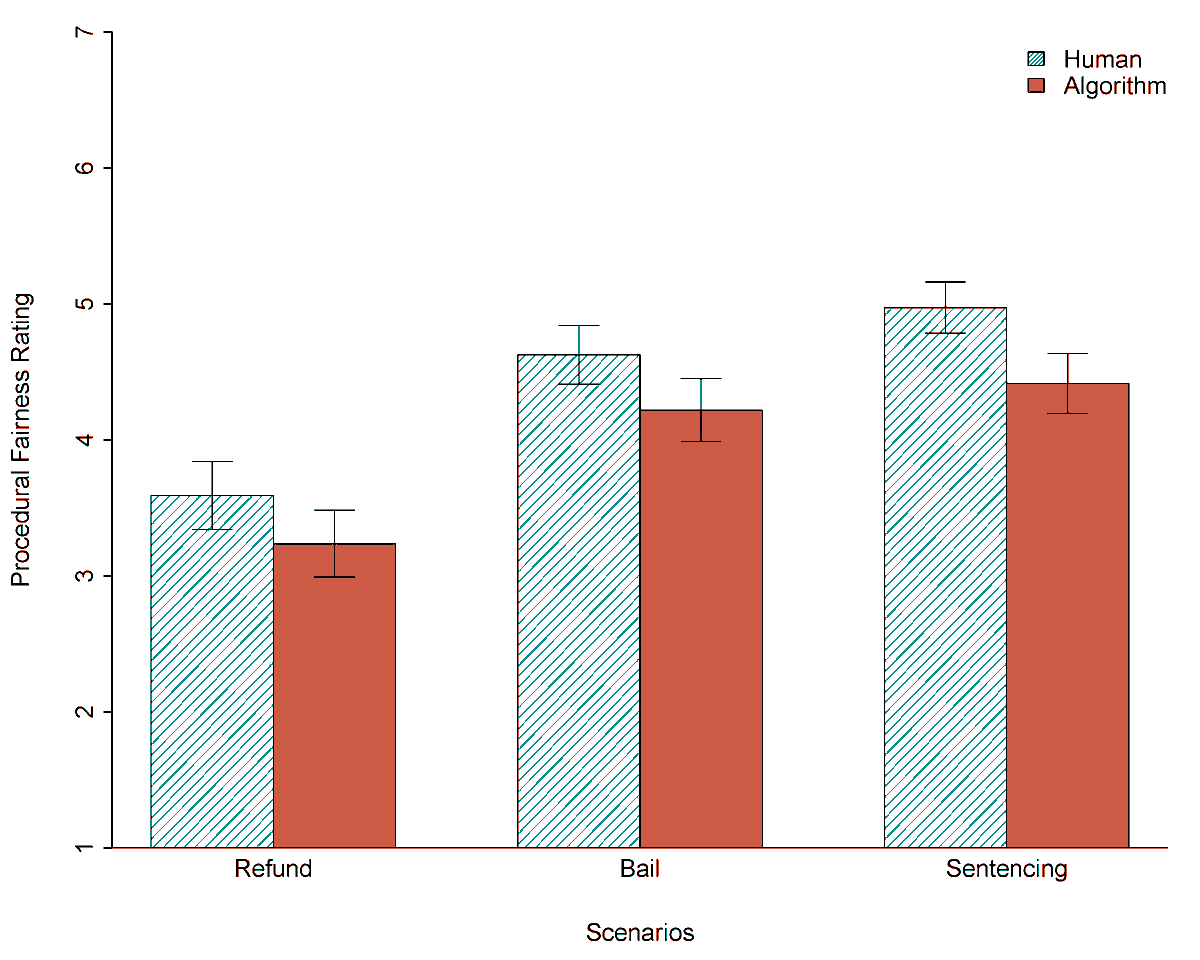
Pinned Tweet

8 May 2025
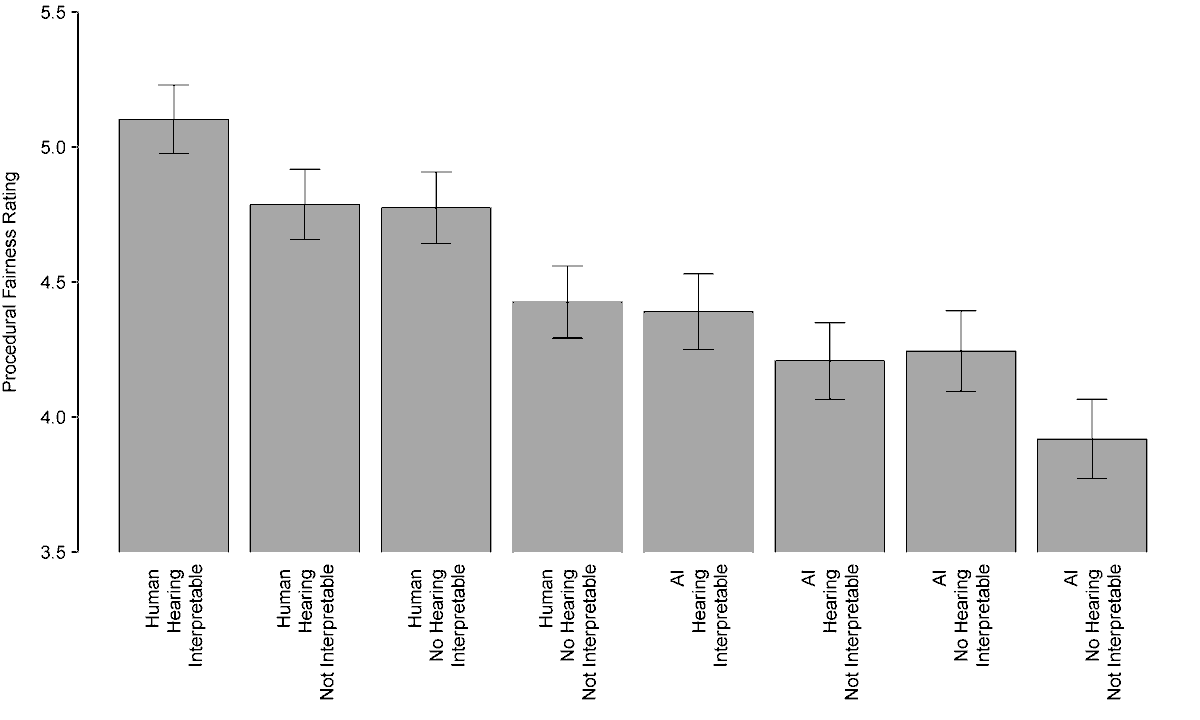
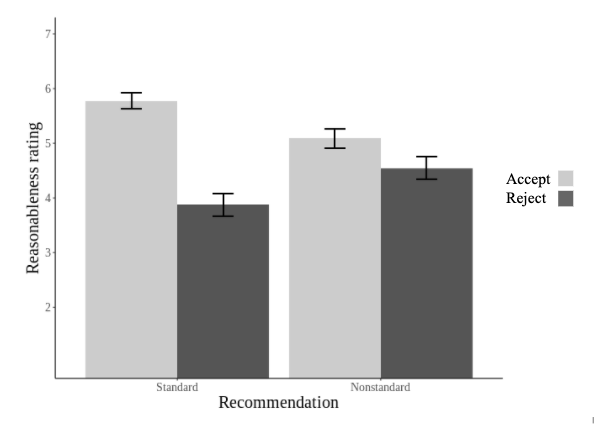
1/6 Are robot judges perceived as less fair than human judges? Yes, but minimal human oversight can eliminate this human-AI fairness gap. Check out our new Working Paper “Mitigating the Judicial Human-AI fairness gap.”
1
3
9
997
Four hundred years before behavioral economists ran lab experiments and HR departments debated “pay-to-quit” bonuses, William Shakespeare already had the answer.
On the eve of battle in Henry V, the king makes a startling offer: 1/
1
3
101
Alexander Stremitzer retweeted

25 May 2025
Programs from previous years:
ethz.ch/content/dam/ethz/spe… (@danbjork, @jblumenstock)
ethz.ch/content/dam/ethz/spe… (@m_sendhil)
ethz.ch/content/dam/ethz/spe… (@MelissaLDell)
@eth_cle @econ_uzh @ETH_AI_Center @emollick @erikbryn @DAcemogluMIT @Susan_Athey @akorinek @aadukia @jensottoludwig @StephenEKHansen
1
8
997
Alexander Stremitzer retweeted
25 May 2025
Call for Papers:
The 4th Annual Zurich Workshop in AI Economics
to be held Dec 5-6, 2025, hosted by ETH Zurich and University of Zurich.
illuminating keynote to be given by @testingham (OpenAI)
organized with @sergallet @YanagizawaD @joachim_voth
Info: eash.cc/AI-econ
Submit (by Aug 15th): eash.cc/AI-econ-sub-2025


1
43
200
27,560
Alexander Stremitzer retweeted
24 May 2025
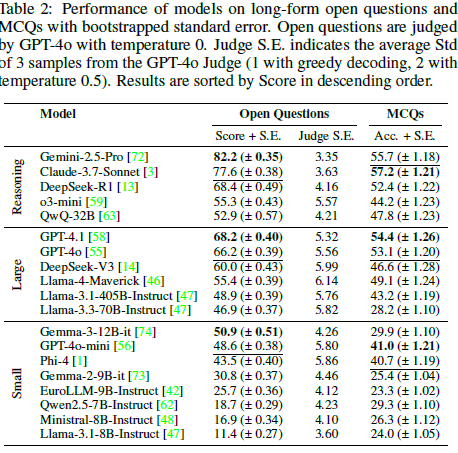
Introducing an eval dataset of 4,886 law school exam questions. See if your AI can answer them!!
24 May 2025

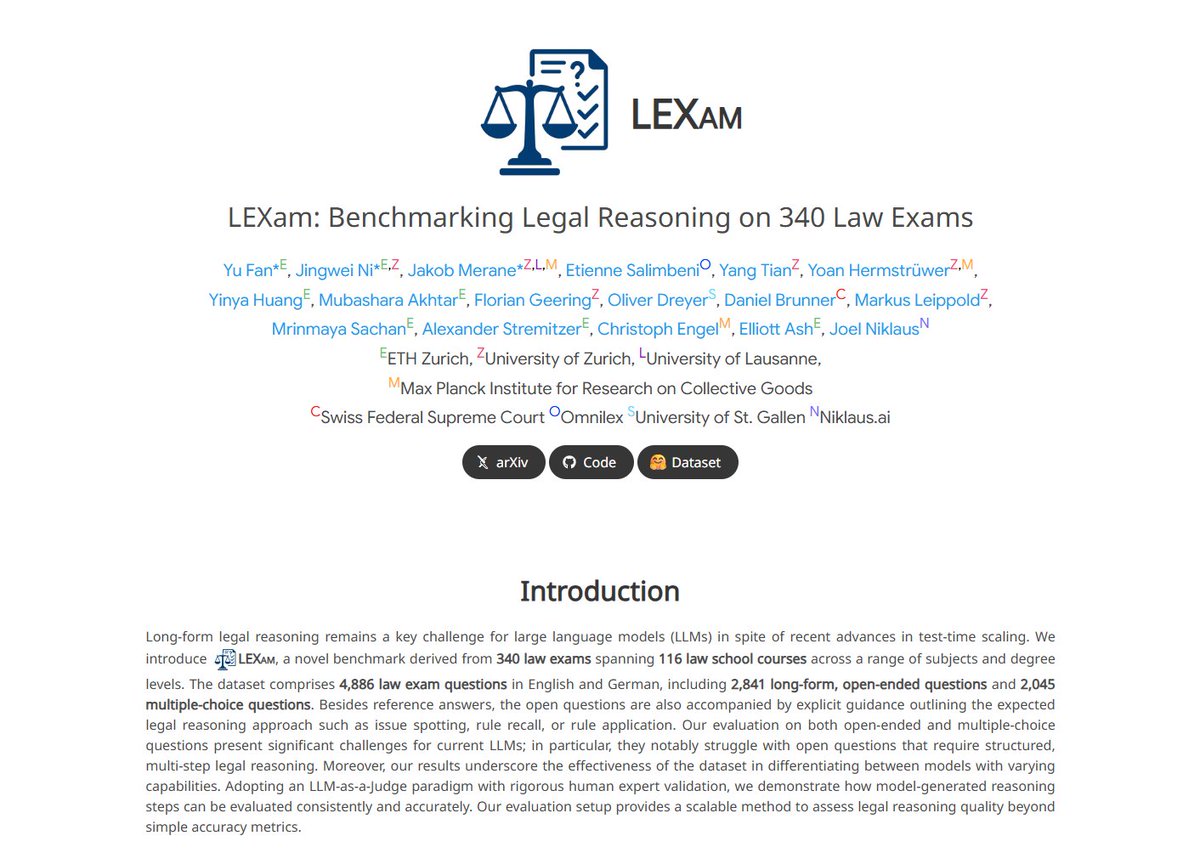
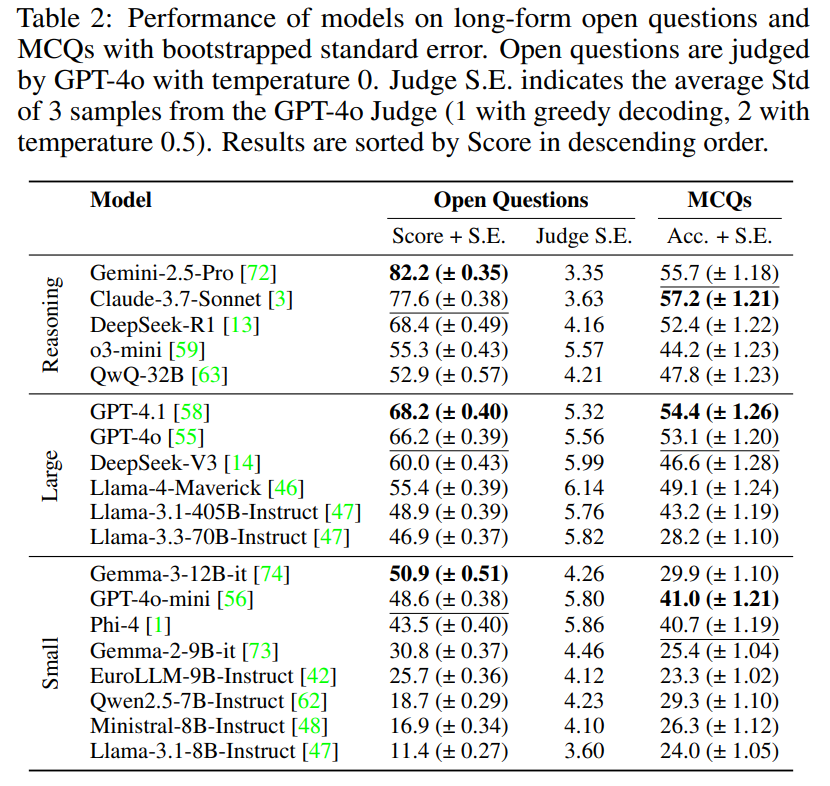
1/5 How good are AI Model’s Reasoning Abilities? We have created LEXam, a legal reasoning benchmark derived from real law exams available in English and German. @eth_cle @ellliottt @YoanHermstruwer @joelniklaus @OpenAI @GoogleAI @deepseek_ai @AnthropicAI @grok @AIatMeta
1
3
19
1,928
Alexander Stremitzer retweeted

22 May 2025
Check out LEXam, our new Legal Reasoning benchmark! Thanks for the great collaboration @NJingwei, Jakob, Etienne, Yang, Yoan, @YinyaHuang, @akhtarmubashara, Florian, Oliver, Daniel,@LeippoldMarkus, @mrinmayasachan, @Stremitzer_Lab, Christoph Engel, @ellliottt, and @joelniklaus!
21 May 2025

🚨Time to push LLMs further!
📚LEXam: The legal reasoning benchmark you’ve been waiting for:
• 340 exams, 116 courses (EN/DE)
• Long-form, process-focused questions
• Expert-level LLM Judges
• Rich meta for targeted diagnostics
• Contamination-proof, extendable MCQs
[1/6]🧵
5
12
1,346
24 May 2025
1/5 How good are AI Model’s Reasoning Abilities? We have created LEXam, a legal reasoning benchmark derived from real law exams available in English and German. @eth_cle @ellliottt @YoanHermstruwer @joelniklaus @OpenAI @GoogleAI @deepseek_ai @AnthropicAI @grok @AIatMeta
4
7
20
4,364
24 May 2025
4/5
𝑳𝑬𝑿𝒂𝒎 rigorously evaluates AI models' legal reasoning abilities by emphasizing both outcome correctness and reasoning process.
It was created through expert extraction and curation, 𝑳𝑬𝑿𝒂𝒎 contains 2,841 open-ended and 2,045 multiple choice questions (MCQs).
1
87
24 May 2025
3/5 Discover our findings and benchmark your models with 𝑳𝑬𝑿𝒂𝒎!
- Project link: lexam-benchmark.github.io/
- Find more details in our paper: arxiv.org/abs/2505.12864
- Explore our datasets: huggingface.co/datasets/LEXa…
3
117
8 May 2025
1/6 Are robot judges perceived as less fair than human judges? Yes, but minimal human oversight can eliminate this human-AI fairness gap. Check out our new Working Paper “Mitigating the Judicial Human-AI fairness gap.”
1
3
9
997
8 May 2025
6/6 However, our findings also raise the concern that nominal human oversight could be used to legitimize substantively unfair algorithmic procedures in the eyes of ordinary citizens.
2
1
47