
Photos and videos
Sovereign AI at all levels (national, business, personal) has never been more important.
Technologies that enable the creation and ownership of frontier intelligence are going to become the new bow wave of this future.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
5
44
1,314

Jun 11
Cracked.
Jun 11

TLDR; our subnet on bittensor (SN15) is producing the highest quality open agentic shopping traces in the world. We're going to leverage that to create personalized shopping models for all.
go give our arXiv pre-print a read, where we outline how the shopping traces from the best frontier open source models show pitfalls, the challenges and the opportunities in the goal of teaching AI to shop.
Also, we're expanding the team! If you're interested in any of our work below, please reach out to team@oroagents.com.
10
1,085
Will Squires retweeted

Jun 10
Introducing Decentralized Language Models (DeLM)!
DeLM is a multi-agent framework that enables asynchronous, verified & reusable progress!
It makes agentic tasks more accurate and significantly cheaper. For example, it achieves 65.7% on SWE-bench Verified using Gemini 3-Flash, a ~10% jump over the best centralized alternatives at less than half the cost.
Great work led by @Mao_Yuzhen !

Jun 10

What happens when multi-agent systems stop relying on a central “controller” agent? Can agents coordinate by sharing results directly with each other?
Introducing Decentralized Language Models (DeLM): we let agents coordinate asynchronously through a shared context. Agents claim tasks from a queue and write back compact, verified results as they finish, making progress visible to all workers without requiring a main agent to merge, filter, and rebroadcast it.
New paper with @azaliamirh!
8
27
243
28,105
Jun 10
Or…
Jun 10

You will live in the pod, eat the bugs, use the only AI, and live on UBI.
2
3
11
1,552
Jun 9
This is not surprising.
It's interesting, however, that the most precious secrets are related to pretraining and distributed training methodologies.
Models like Fable are reaching the point they cannot be captured by a single cluster, even the largest like Colossus 2.
Finding ways of liquidising training workloads to work over pools of compute, and fit in and around peaking, spiking inference demand is clearly part of the frontier moat.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

1
21
3,539
Will Squires retweeted

Jun 9
Many subnets have been doing exactly this for a while now
Apex (Subnet 1) is one of the most interesting, with the ability to host multiple problems
End state of Apex is:
- anyone show's up with a problem
- gets translated into an optimization problem
- miners (agents) work to solve it until a satisfactory solution is produced
- miners open-sourcing their solutions means agents end up collaborating together
Jun 9

Probably the idea I am most excited in agentic networks is swarms.
In particular, swarms that solve problems and optimize algorithms.
If I were a founder right now, I’d take the Millenium Problems — $1m prize for each — and spin up swarms to solve them.
If you can find some way an algorithm (quantum circuits? protein folding?) can be monetized, the swarm has incentive.
5
9
62
4,782
Jun 5
I worked in construction for over a decade
We are witnessing Elon leveraging his exceptional skill in project execution over competitors.
Over 81% of projects end up in delay. These infrastructure delays will cascade into compute.
Efficiency of compute is so so critical.
Jun 5

$920M for 110k GPUs
Google is paying $11.6/hr for Blackwells
1
1
21
2,530
Jun 5
powered exclusively by phenomenal knitwear and conditioner.
Jun 5

Our AI Research Lead, Dr. Alan Aboudib, has been instrumental in building @IOTA_SN9 and launching Orion-100B, the largest distributed LLM pretraining run conducted over the open internet across globally distributed infrastructure.
We spoke with Alan about his background, education, experiences, and perspectives on AI.
Alan was a lead architect behind ResBM, our SOTA compression technique designed specifically for IOTA. He has pushed our work to the frontier of distributed AI development, helping us achieve feats that were only imaginable several years ago.

1
1
24
1,391


Jun 4
what an amazing, wonderful week at @proofoftalk.
A few thoughts:
- we have come a LONG way in a year.
- Teams that were shuttling first dollar in 25 are hitting 8 figures mid 26 (shout out to my brother @0xcarro and the @manifold team, and partnership warlord @MaxScore and the gang)
- research subnets with dreams in 25 are publishing actual results - druggable receptors for ADHD meds! Big up @metanova_labs (and @micaelabazo)
- lots of bullish new teams (@cacheon_ai Babelbit, Green Compute), and returning first timers from 25 who have made series strides this year ( @markjeffrey hosting the fireside only 13 months after his first in person event at Endgame, after launching a fund. Shout out to @MarkCreaser at DSV)
- @Old_Samster combining his increasingly sharp alpha with a new all white angelic look.
- apparently @taostats is the new Da Vinci stage (which as a Bittensor oriented stage rocked) - does that mean @mogmachine is the statue of David?
- my brother @macrozack on stage proving pitches, and taking the finishing slot of the conference this year with @bitstarterAI was a sweet, full circle moment.
-thank you to Paul and the @XVentures_Fund team for another stellar performance.
As for us, last year was when we started the @IOTA_SN9 dream. This was the week it felt like coming onto reality. Big love to everyone who’s been a part of it.
2026 is clearly the year.
4
19
132
5,504
Will Squires retweeted

Jun 3
Just orchestrated a 128 node permissionless decentralized training run, in 5 minutes, for 5 TAO, via @IOTA_SN9
They can do this up to 100B param models.
Unbelievable.
iota.macrocosmos.ai/dashboar…

43
178
857
71,226
Will Squires retweeted

Jun 2
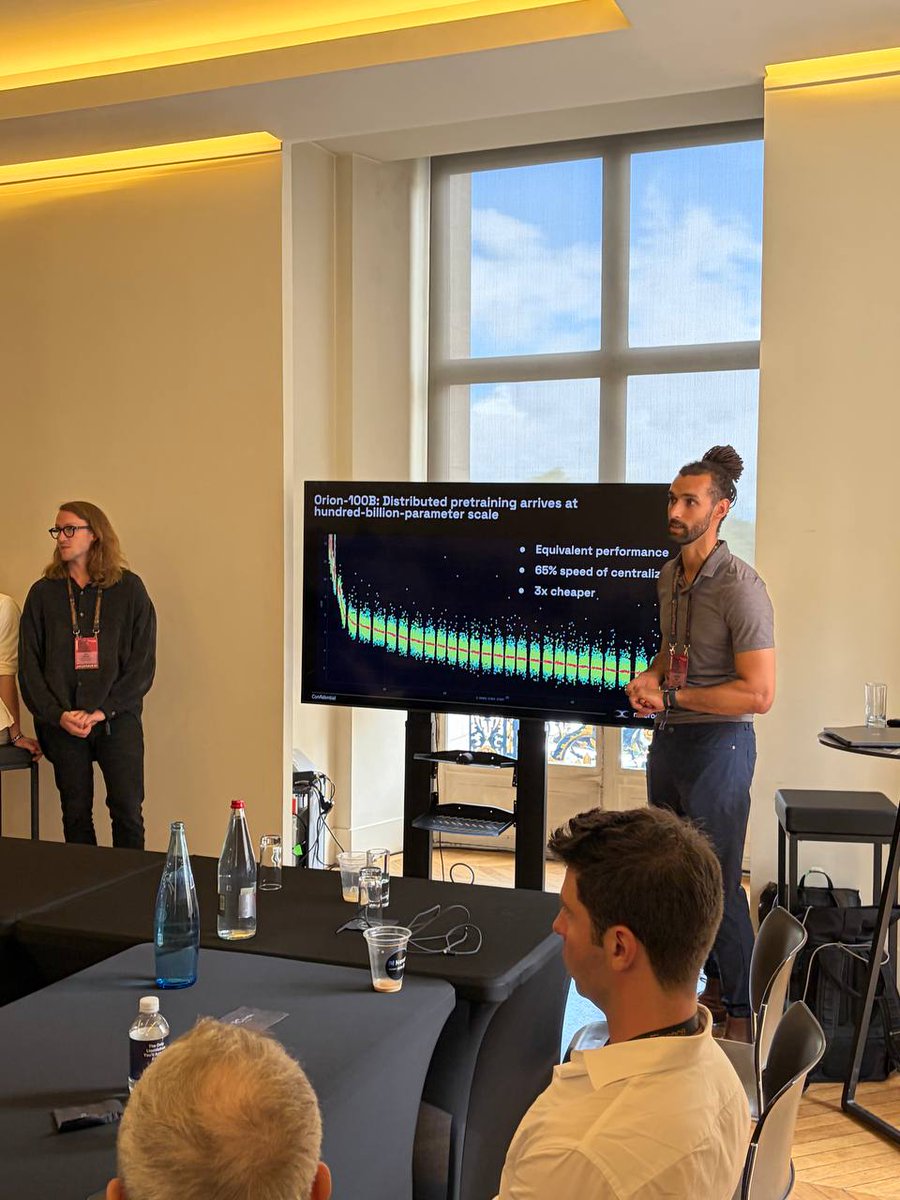
ORION LAUNCHES: @macrocosmosai unveils Orion-100B at @proofoftalk on the 1 year anniversary of @IOTA_SN9 launch in this very building.
They asked: Can frontier-scale AI training be distributed?
On Monday, the team published Orion-100B, an early pretraining run designed to test exactly that. At Proof of Talk co-founders @macrocrux and @WSquires took the audience through the results.
Orion-100B represents the largest distributed LLM pretraining run conducted over the open internet to date. The run trained a 100-billion-parameter model architecture across geographically distributed infrastructure.
This was not an attempt to produce a finished frontier model. Orion-100B processed approximately 1.1 billion training tokens over a two-day period before being stopped. The objective was simpler, and arguably more important: demonstrate that training at 100B scale is possible without relying on a single, centralized cluster of GPUs.
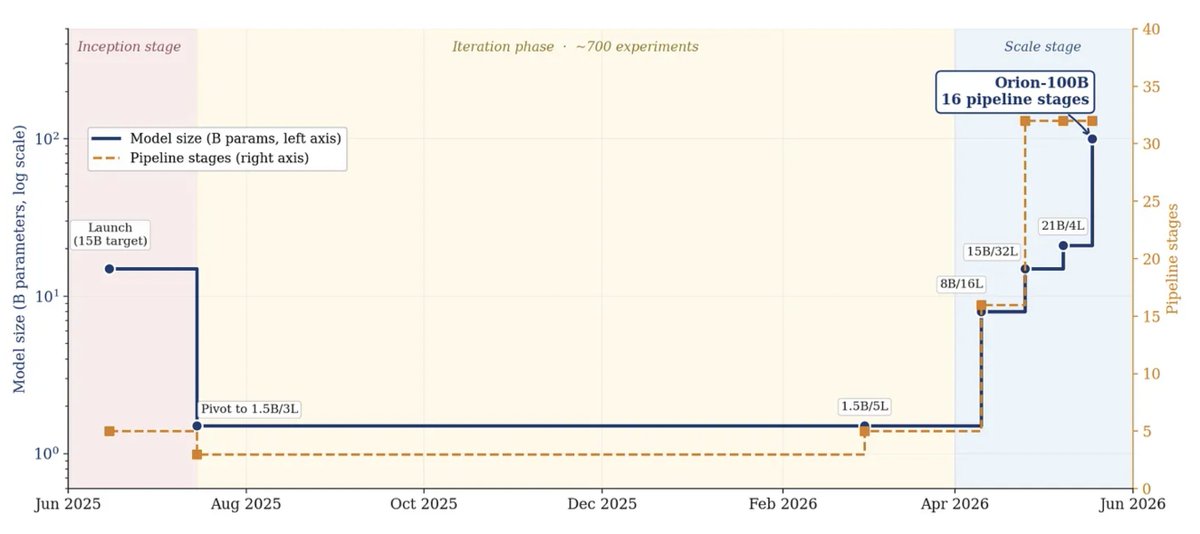
For Macrocosmos, the result represents the culmination of more than a year of work.
The version of the story shared on stage was refreshingly unglamorous. The team launched Subnet 9 in 2025 targeting a 15B parameter model and quickly discovered that building distributed training systems in a permissionless environment is harder than it looks. The network struggled. Assumptions broke. The architecture was reworked.
So instead of pushing forwards, they scaled backwards. For months, the team trained smaller 1.5B parameter models, running more than 700 experiments in the process. By their own admission, it wasn't particularly exciting. But it allowed them to harden the networking layer, improve fault tolerance, increase throughput and gradually remove bottlenecks from the system.
Only then did they begin scaling again. 8B. 18B. Then 100B.
The result was Orion.
According to the figures presented, the run achieved average model FLOP utilisation of 30.8%, roughly 65% of the speed of equivalent co-located infrastructure, at a third of the cost. More importantly, the learning dynamics remained stable throughout the run, even as the system handled synchronisation and communication across dozens of distributed devices.
The technical depth in the room was high. Questions came in on heterogeneous compute stacking, minimum GPU yield thresholds, the reconstructability of sharded weights, architectural constraints on the ResBLM approach. Halfway through, @const_reborn materialised in the audience and started grilling them on the economics and fault tolerance at scale. They took it in elegant stride.
The Macrocosmos thesis is that the future of AI training does not necessarily belong to ever-larger datacentres. If distributed systems can become sufficiently efficient, they could unlock vast pools of underutilised compute spread across the world.
Today's Orion run was intentionally conservative. The GPUs were distributed, but still professionally provisioned. The next stages of Project Orion will progressively introduce heterogeneous hardware, interruptible spot instances, permissionless participation and eventually consumer-grade devices.
Whether distributed training ultimately reshapes the economics of AI remains to be seen. But either way, Macrocosmos has moved the conversation beyond whether distributed training is possible and towards how far it can scale.
The presentation also provided useful context for @bitstarterai's newly announced ML Track, which was unveiled by @macrozack at the same roundtable event and is linked by a common theme - how Bittensor attracts and supports the next generation of machine learning teams.
Throughout the event, bitstarter.ai outlined its approach to reducing the barriers to entry for researchers looking to build on the network, combining subnet funding, infrastructure support, compute resources, partnerships and incubation.
If Macrocosmos' journey demonstrates what is possible once a team is established on Bittensor, bitstarter.ai's ambition is to help more teams make that journey in the first place.
For now, however, the spotlight belonged to Orion.
After more than 750 experiments, a year of iteration, and a successful 100B-scale demonstration, Macrocosmos has moved distributed training a little further out of the realm of theory and a little closer to reality.
And judging by the reaction in the room, plenty of people were paying attention.



1
9
35
1,187
Jun 2
We are still so early.
Decentralised training has the ability to materially disrupt how inference and training workloads are balanced, and impact both compute utilisation and pricing at a macro scale.
We’ll be talking more about our vision for this in the coming weeks.
Thanks to @jbrukh for flying the training flag.
Jun 2
As of today, there’s essentially 5 companies who have successfully completed meaningful SOTA moving decentralized *pretraining* runs:
- @PrimeIntellect (10B INTELLECT-1, Oct 24)
- @Pluralis (7.5B Node0, Oct 25; 8B Agora launch, May 26)
- @NousResearch (40B Consilience, May 25)
- @covenant_ai (Coventant-72B, Mar 26)
- @MacrocosmosAI (Orion-100B, June 26)
In October ‘24, I thought we would enter a decentralized AI training race. I think that’s gearing up now.
2
20
888
Jun 1
The most important thing to understand about Orion is it closes the circle on the thesis for @IOTA_SN9.
Not just frontier scale models, but using compute acquired at a fraction of the cost, orchestrated together with MFU approaching frontier performance.
Jun 1
Today, we are launching the first stage of Project Orion.
Our early pre-training run of Orion-100B achieves upward of 65% of data-center training efficiency on hardware costing a fraction of the price.
Orion-100B is the first proof point for a simple idea: that underutilized compute around the world can be turned into frontier training capacity.
We believe that this work presents, for the first time, an economically compelling case for training large models using distributed approaches.
12
59
3,962
Jun 1
The prime driver of cost in pre training is MFU, or simply put ‘how often are the GPUs actually being used during training’.
What if interruptible, distributed paradigms could achieve MFUs comparable or better than centralised?
What if…
May 31
1
3
25
2,050
May 31
I will also be there, but apparently my head is too large for this poster.
Can’t wait!
May 30

Bittensor is ideal for machine learning - so how do we get more researchers on the protocol?
We're hosting a workshop at @ProofofTalk with @macrocrux & @MacrocosmosAI revealing how distributed intelligence is accelerating - and competing with the biggest labs in the world.

4
6
53
4,805
Will Squires retweeted

May 29
First they ignore you,
Then they laugh at you,
Then they fight you,
Then you train bigger models than them.
4
13
112
6,368
Will Squires retweeted

May 28
people call iota a "sleeping giant", but we are very much awake. The activity on X has no correlation to the quality of work we do, which will be considered generational
1
5
20
792