
Joined November 2019
- Tweets 119
- Following 417
- Followers 344
- Likes 1,015
23 Photos and videos
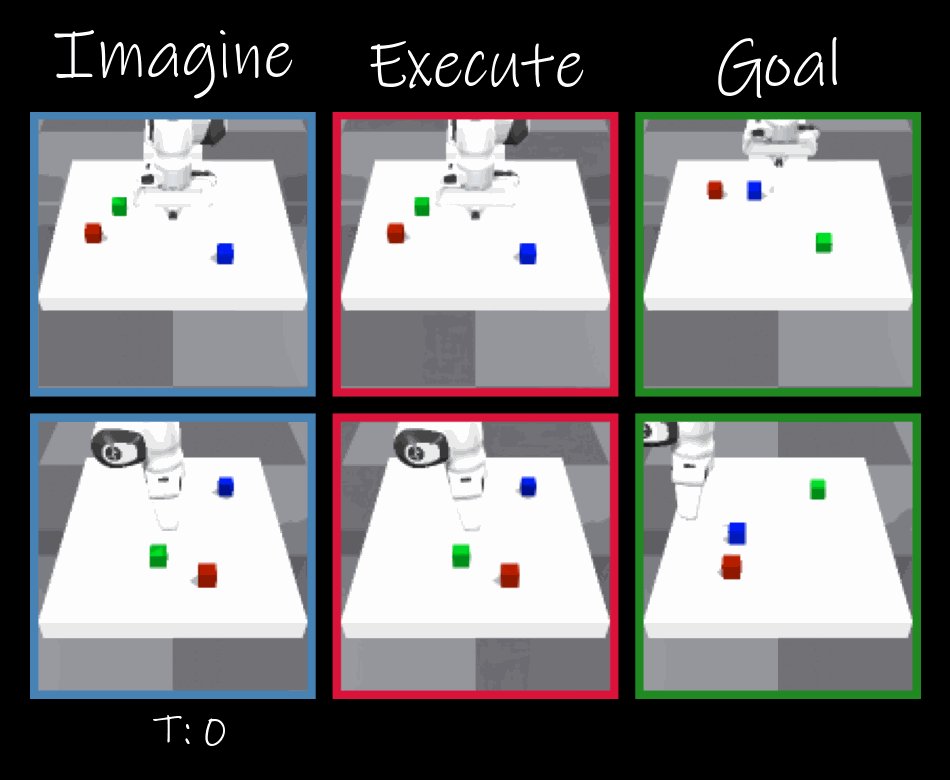










Pinned Tweet

Mar 6
🚀 #ICLR2026 Oral 💥
How can we design world models that capture object interactions directly from pixels?
Introducing Latent Particle World Models-the first end-to-end self-supervised, object-centric world model, trained from videos, supporting action/img/lang conditioning.
1/n
4
49
280
29,081
Tal Daniel retweeted

May 21
VLA is 95% certain about current action. Will it 95% succeed in the task?
Obviously, not necessarily. But if you’re clever, you can *calibrate* action prob. to task success.
Our #ICML2026 paper formulates this SOTA algorithms based on new connection to RL temporal differences

Excited to announce our paper is accepted to #ICML2026!
VLA robot policies are capable, but do they know when they're failing? We tackle this with TDQC: a framework for sequential uncertainty calibration, with a surprising link between calibration theory and RL value function.
10
47
7,963
Apr 22
I’m attending #ICLR2026 in Rio this week to present LPWM! Friday April 24 Poster Session 3 10:30, Oral Session 4B 3:15p. Happy to chat about self-sup object-centric learning and world models. I’ll be on the job market soon and looking for exciting opportunities!
#ICLR @iclr_conf
Mar 6

🚀 #ICLR2026 Oral 💥
How can we design world models that capture object interactions directly from pixels?
Introducing Latent Particle World Models-the first end-to-end self-supervised, object-centric world model, trained from videos, supporting action/img/lang conditioning.
1/n
3
8
52
6,116
Tal Daniel retweeted

Apr 20
I will be at #ICLR2026 this week to present our work on Hierarchical Entity-centric Reinforcement Learning!
Come by our poster (Thursday Poster Session 2 P4-#4712) and reach out anytime to talk about #ReinforcementLearning #WorldModels #HierarchicalRL
Feb 4

Learning accurate World Models for long horizon planning is hard.
So what minimal aspect of world dynamics must a model capture to achieve complex goals?
We find a simple and effective solution in our #ICLR2026 paper, which we will present as an Oral at @worldmodel_26.
(1/n)
1
7
51
4,432
Tal Daniel retweeted

Apr 20
Check out our latest post on CMU@ICLR 2026!
blog.ml.cmu.edu/2026/04/20/c…
1
13
2,796
Tal Daniel retweeted

🚀 Excited to share ViPRA: Video Prediction for Robot Actions
📍 Accepted to #ICLR2026 @iclr_conf
🏆 Best Paper — #NeurIPS2025 Embodied World Models Workshop
Robot learning today still needs millions of action labeled videos.
Yet videos are abundant — from humans and the web — but lack action labels. Meanwhile, pretrained video models already learn rich dynamics.
ViPRA is a recipe for turning pretrained video models into robot policies while enabling robot learning to scale with actionless videos.
🧵 Thread ↓
2
40
268
25,529
Mar 24
Join us for live paper (Latent Particle World Models) overview Q&A today (March 24) at 4pm PT / 7pm ET!
x.com/TalDaniel8/status/2029…
Mar 24

🎤 Dr. @TalDaniel8 (@CarnegieMellon ) In a deep dive
w/ @ceciletamura of @ploutosai
How can AI discover objects, model uncertainty, and predict the future from raw video alone?
🔴 [world.ploutos.dev/stream/ber…](world.ploutos.dev/stream/ber…)

1
7
446
Mar 6
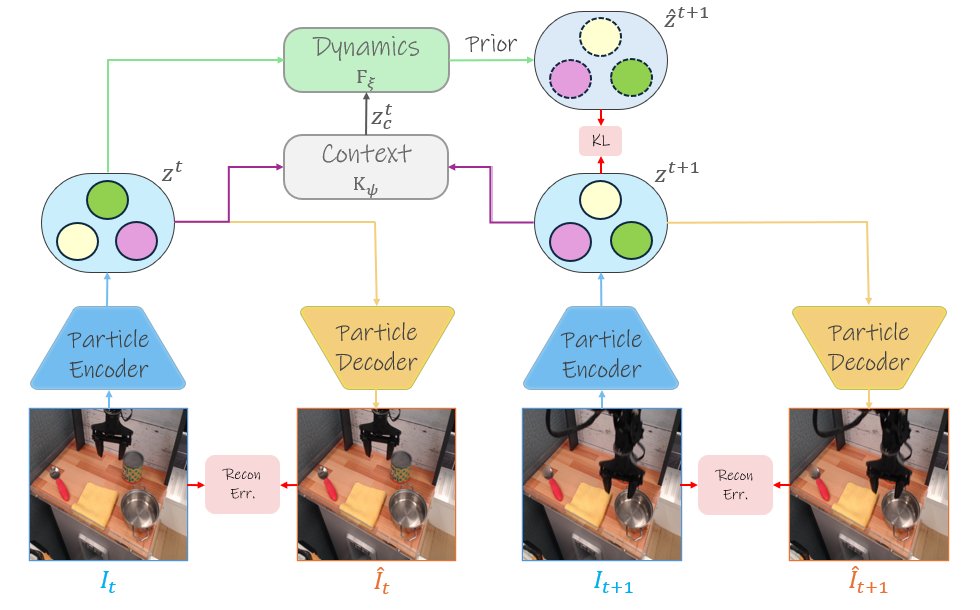
During training, the posterior latent actions condition the dynamics module that predicts the next-frame prior.
A KL regularization term aligns this prediction with the latent policy’s output, forming a VAE-style objective over particle transitions.
7/n
1
8
845
Mar 6
Huge thanks to @DanHrmti, @carl_qi98, Amir Zadeh and Chuan Li (@LambdaAPI), @AvivTamar1, @davheld, and @pathak2206 — incredible collaborators who made LPWM possible.
15/n
1
6
770
Mar 6
🌐 Learn more about Latent Particle World Models (LPWM):
Website: taldatech.github.io/lpwm-web…
Paper: arxiv.org/abs/2603.04553
Code ( tutorial): github.com/taldatech/lpwm
16/n
1
9
783
Mar 6
🚀 #ICLR2026 Oral 💥
How can we design world models that capture object interactions directly from pixels?
Introducing Latent Particle World Models-the first end-to-end self-supervised, object-centric world model, trained from videos, supporting action/img/lang conditioning.
1/n
4
49
280
29,081
Mar 6
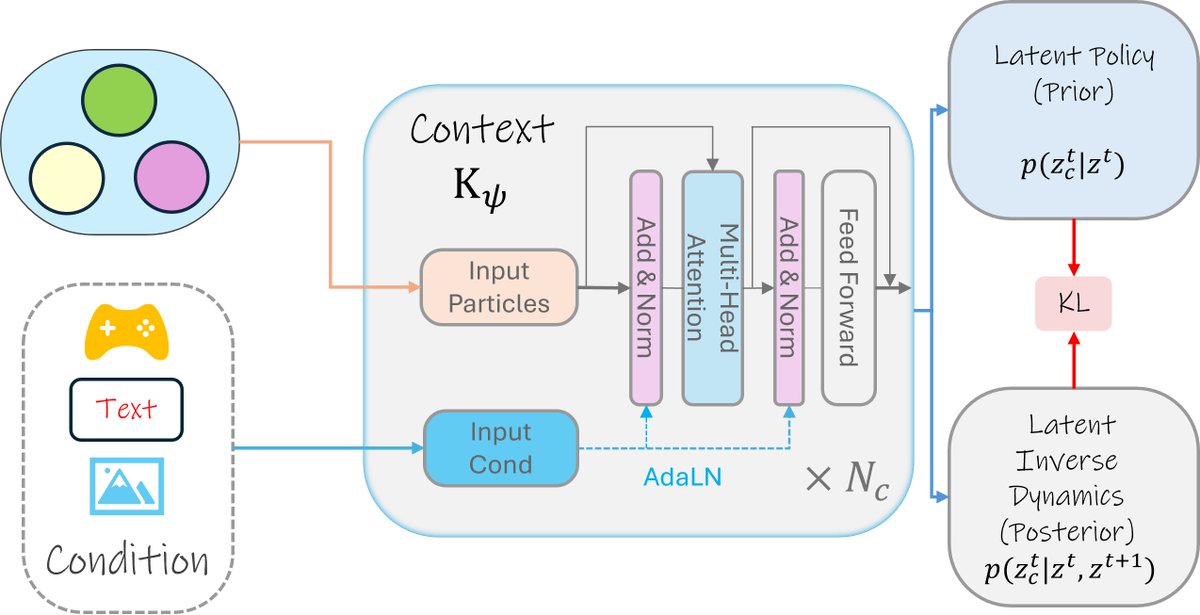
The inverse dynamics observes particles at t and t 1, inferring the latent actions that caused the change.
The latent policy sees only particles at t and outputs a distribution over possible latent actions from the current state.
6/n
1
7
743
Mar 6
To address this, we introduce a context module that predicts latent actions per particle, enabling fine-grained, multi-entity dynamics
It has two heads: (1) an inverse dynamics (posterior) and (2) a latent policy (prior).
5/n
1
8
800
Mar 6
Building a world model means capturing stochastic particle dynamics.
Existing “latent action” models help, but (1) need strong regularization (e.g., VQ) and (2) rely on a single global latent—missing interactions among multiple entities.
4/n
1
6
832
Mar 6
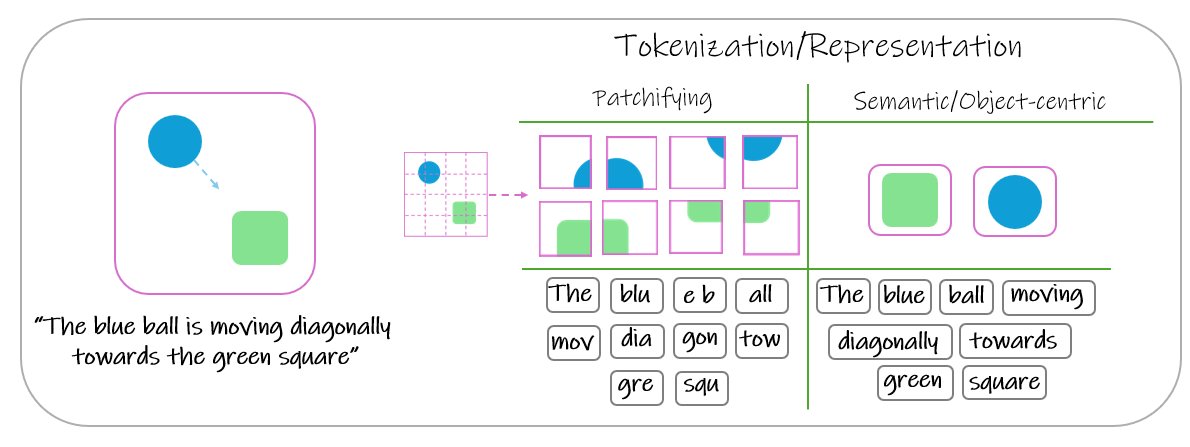
DLP decomposes scenes to particles with several attributes (keypoints, bounding-boxes, masks), fully unsupervised.
These act as visual “tokens,” making cross-modal long-horizon reasoning (vision ↔ language) far more natural than the standard pixel patches.
3/n
2
10
997
Mar 6
Self-supervised object-centric models decompose scenes into entities without any supervision—a key step toward visual understanding. In this work, we extend Deep Latent Particles (DLP) to world-modeling on real-world datasets.
2/n
2
12
1,167