
PhD student in Machine Learning @ University of Tübingen · IMPRS-IS scholar
Joined June 2012
- Tweets 319
- Following 325
- Followers 271
- Likes 1,091
36 Photos and videos

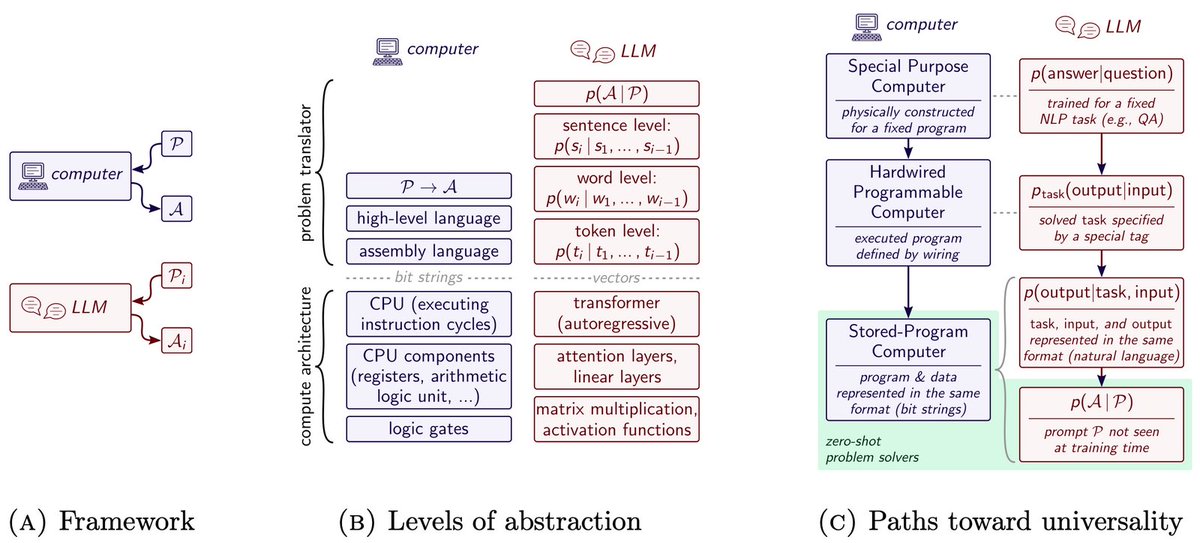

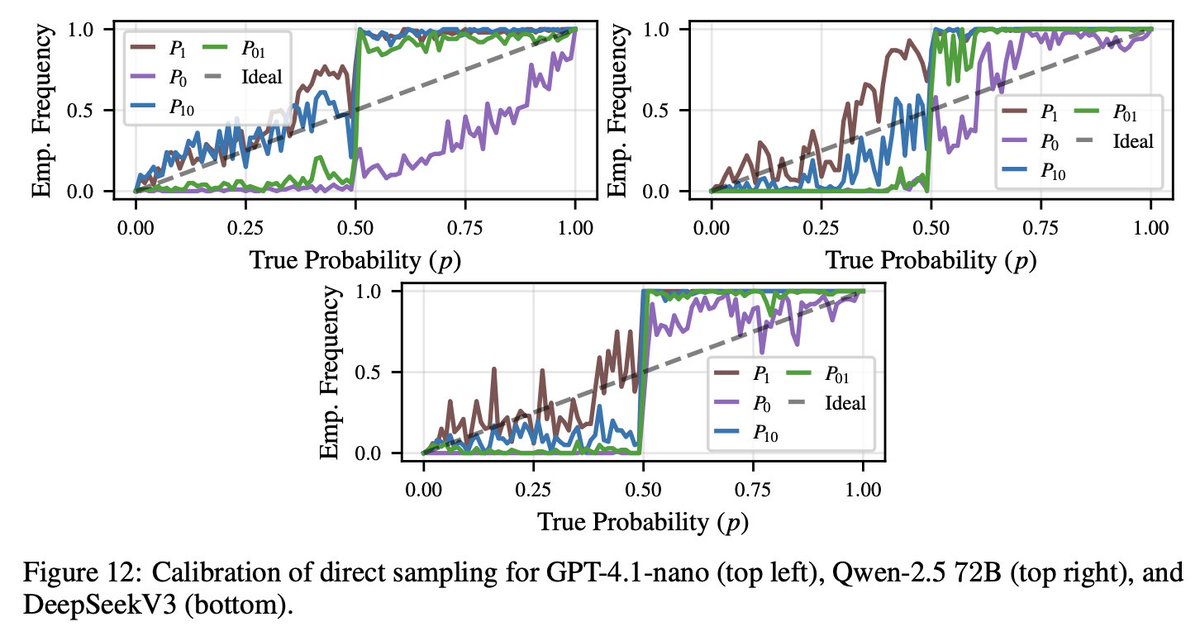
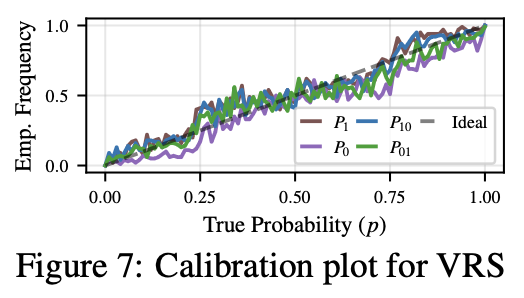
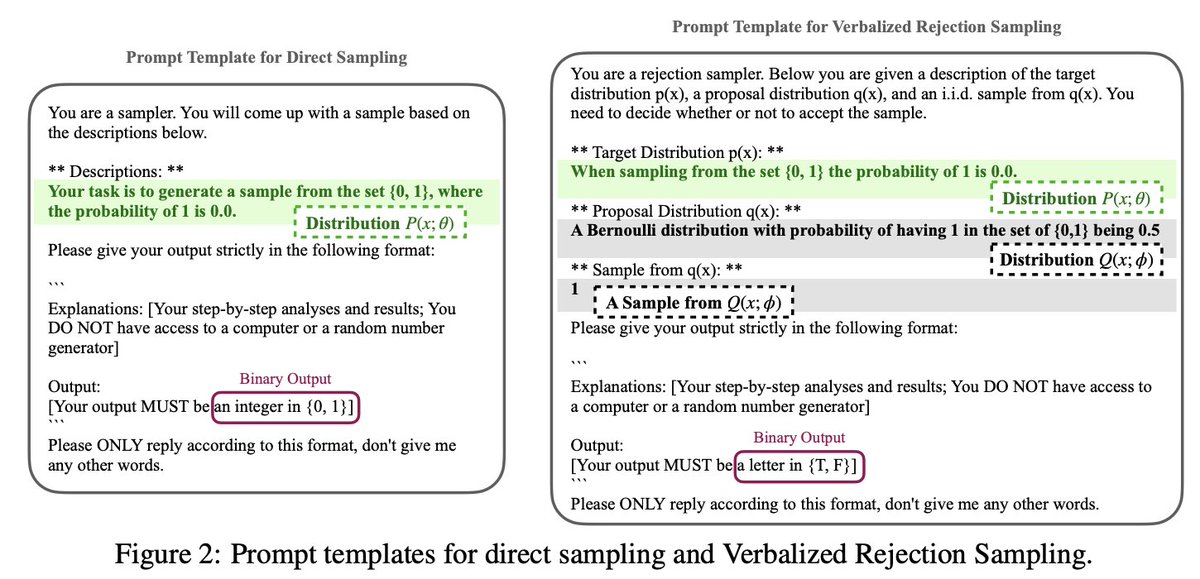
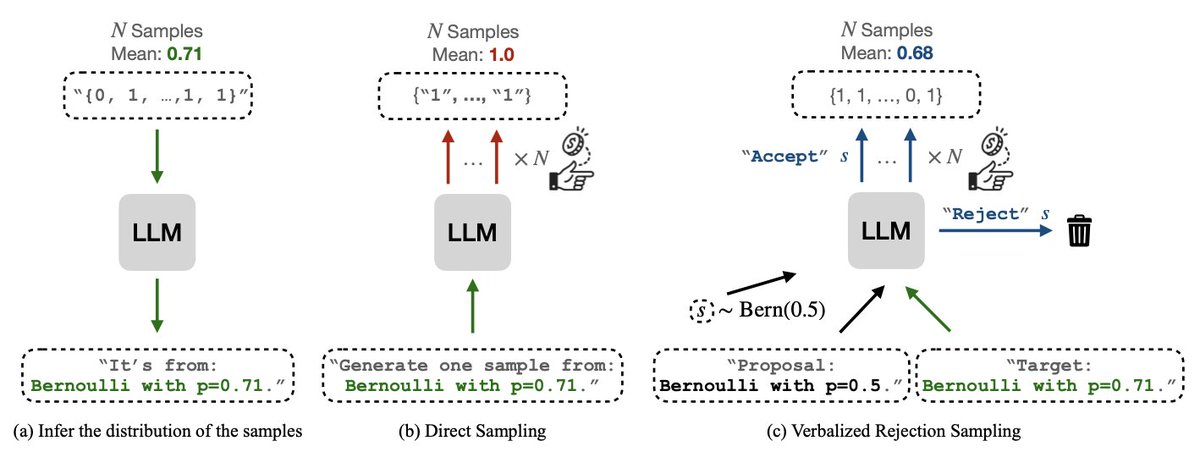






✨ New paper: Flipping Against All Odds
We found that large language models (LLMs) can describe probabilities—but fail to sample from them faithfully.
Yes, even flipping a fair coin is hard. 🪙
🧵 Here’s what we learned—and how we fixed it.
🔗arxiv.org/abs/2506.09998
1/
4
8
16
2,855
Tim Xiao retweeted

Jun 3
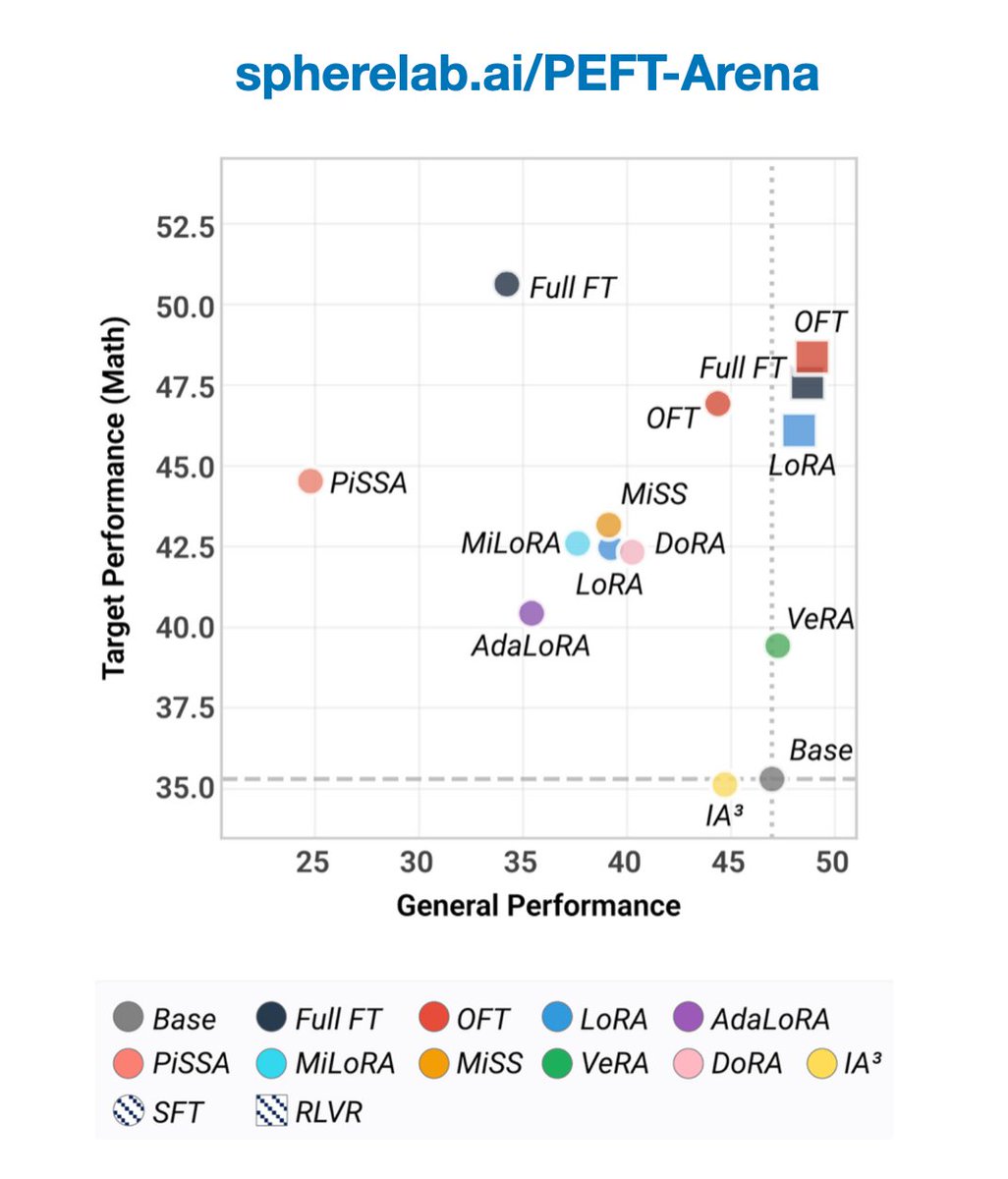
🚀 Excited to introduce PEFT-Arena! This project grew directly out of the challenges we faced when evaluating existing PEFT methods.
We argue that PEFT evaluation should not ask only what improves. It should also ask what is forgotten. For too long, parameter-efficient finetuning methods have been evaluated by downstream accuracy. But target performance alone is not enough. A method can adapt well while silently losing pretrained capabilities.
PEFT-Arena evaluates existing popular PEFT methods through the stability-plasticity trade-off, i.e., how much the model learns on the target task, and how much general ability it still preserves after finetuning.
A good PEFT method should adapt without forgetting and achieve a strong stability-plasticity trade-off. In our evaluation, we find that Orthogonal Finetuning achieves the strongest trade-off among all methods.
Beyond task-driven benchmark scores, PEFT-Arena also provides geometry-based internal diagnostics in weight space, activation space, and interpolation paths, helping us understand not only which methods work, but why they forget.
What PEFT-Arena has done:
🌟 Adaptation preservation: evaluates both target gains and forgetting.
🌟 Trade-off frontier: reveals stability-plasticity patterns, with OFT often leading.
🌟 Geometry diagnosis: explains forgetting via weight spectra, activation distortion, and interpolation paths.
Welcome to try PEFT-Arena and evaluate your own PEFT method!
🌐 Project page: spherelab.ai/PEFT-Arena
📝 Paper: arxiv.org/abs/2605.28819
💻 Code: github.com/Sphere-AI-Lab/PEF…
3
5
24
1,304
Tim Xiao retweeted
May 29
I want to share more about why we started building Orbit: spherelab.ai/orbit/
Orbit is an OFT-centric reinforcement learning pipeline designed for ultra-efficient post-training of large language models. In simple terms, Orbit allows us to post-train a trillion-parameter LLM on a single 8-GPU node. But more importantly, Orbit represents something much larger for us, as it connects our long-standing research to a practical system that can be used at frontier scale.
One of SphereLab’s core missions is to develop a principled and unified full-stage training pipeline for large foundation models. We are especially interested in what we call the spectral scaling paradigm: the idea that the geometry and spectral structure of model weights should not be treated as incidental details, but as central objects in how we design training algorithms.
This perspective has alreadyled us to develop a series of pretraining algorithms and systems, including POET, POET-X, and Pion:
- POET: spherelab.ai/poet/
- POET-X: spherelab.ai/poetx/
- Pion: spherelab.ai/pion/
It has also guided our work on post-training and adaptation, including OFT, BOFT, OFTv2, PEFT-Arena, and OrthoMerge:
- OFT: oft.wyliu.com/
- BOFT: boft.wyliu.com/
- OFTv2: spherelab.ai/oftv2/
- PEFT-Arena: spherelab.ai/PEFT-Arena/
- OrthoMerge: spherelab.ai/OrthoMerge/
Although these projects may appear to target different stages of the model lifecycle, they are all driven by the same underlying principle -- the spectrum and geometry of neural network weights matter. Preserving and controlling these structures can lead to more stable, efficient, and scalable training and adaptation.
While creating these algorithms has been extremely rewarding, we take a step further to build practical systems from the ground up that can leverage the same principle to best scale our algorithms. That is why a small team like us still spent so much time and efforts to build Orbit.
Orbit is only the starting point. We are excited to keep building systems that bring principled training algorithms to real-world foundation model development.

4
28
2,321
Checkout our new project! Being able to post train the largest opensource LLMs on a single node is such a cool achievement!
May 28

🚀 Meet Orbit: OFT-based RL infrastructure for stable, efficient post-training of trillion-parameter LLMs.
Orbit can train 1T LLMs (e.g. Kimi-2.6, DeepSeek-V4-Pro) on a single GPU node (8xB200) with extremely small train-rollout gap!
Code: github.com/Sphere-AI-Lab/orb…
Blog: spherelab.ai/orbit/
Blog in Chinese: mp.weixin.qq.com/s/M3Q4AnhMa…
3
120
Tim Xiao retweeted

May 18
🧵1/7
Ever tried building a world model for a partially observable environment from just raw observations? It's tough - but what if LLMs could help?
We explore this question in our latest preprint: 'Learning POMDP World Models from Observations Using Language-Model Priors.'

3
3
7
1,523
Nice work! Whether an LLM can generate faithful sample is an important topic for the agentic era.
Our work verbalized rejection sampling also studied this problem!
arxiv.org/abs/2506.09998
Apr 10

can llms reliably roll the dice? 🎲
we shed new light on stochasticity limitations of llms, discussing some ways in which things can improve: tools, prngs, and 'just giving a random number to the model™'
great work from @gu_xiangming while being a student researcher with us 🚀

5
33
5,234
Tim Xiao retweeted
Mar 6
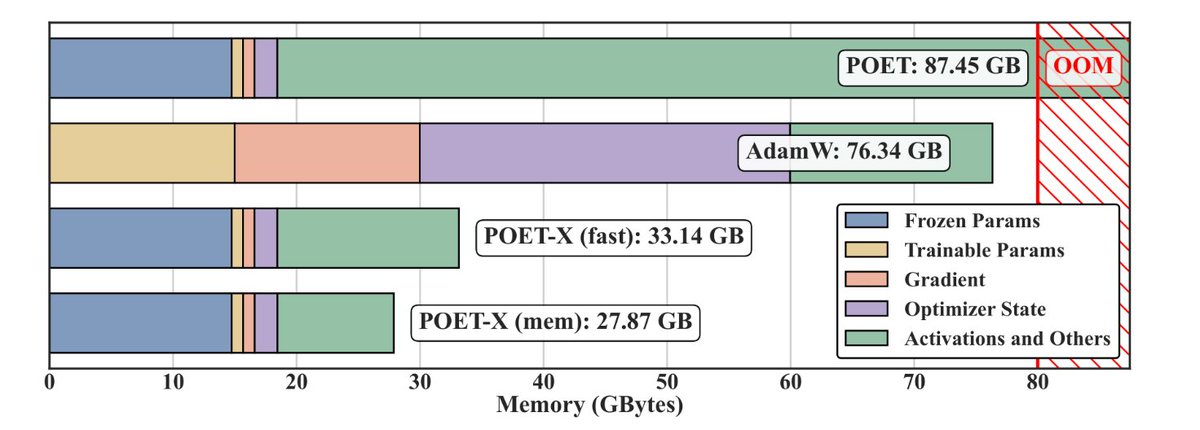
🚀 Excited to introduce POET-X, a scalable and highly memory-efficient algorithm for LLM pretraining.
✨ LoRA-level GPU memory, better-than-AdamW pretraining performance!
POET-X finally marries training stability (from POET's spectrum preservation) and practical scalability (from our new implementation and CUDA kernels). POET-X can pretrain billion-parameter LLMs (eg., Llama-8B) on a single NVIDIA H100, where standard optimizers like AdamW run out of memory under the same settings.
We carefully reimplemented every computation step of POET (arxiv.org/pdf/2506.08001). POET-X combines many small checkpointing and parallelization tricks. While each may appear incremental, together they dramatically improve scalability and reduce memory usage by over 70% compared to the original POET.
The memory-efficiency of POET-X comes from the unique parameter-efficient reparameterization (where sparsity comes in) of the weight update rule. POET-X bridges this gap between parameter efficiency and memory efficiency.
Code is now public. Feel free to try it!
➡️ paper: arxiv.org/pdf/2603.05500
💻 Code: github.com/Sphere-AI-Lab/poe…
🌐 Website: spherelab.ai/poetx
#AI #LLM #MachineLearning #DeepLearning
1
12
56
15,698
Tim Xiao retweeted
Jan 23
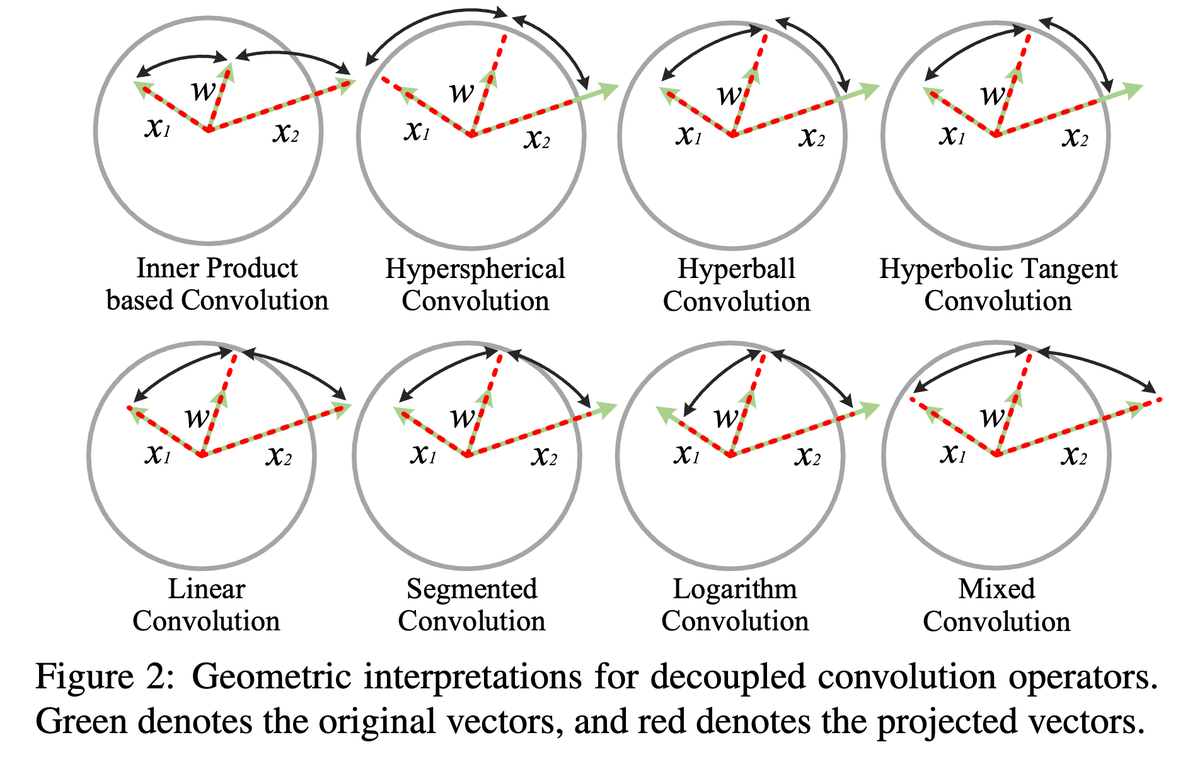
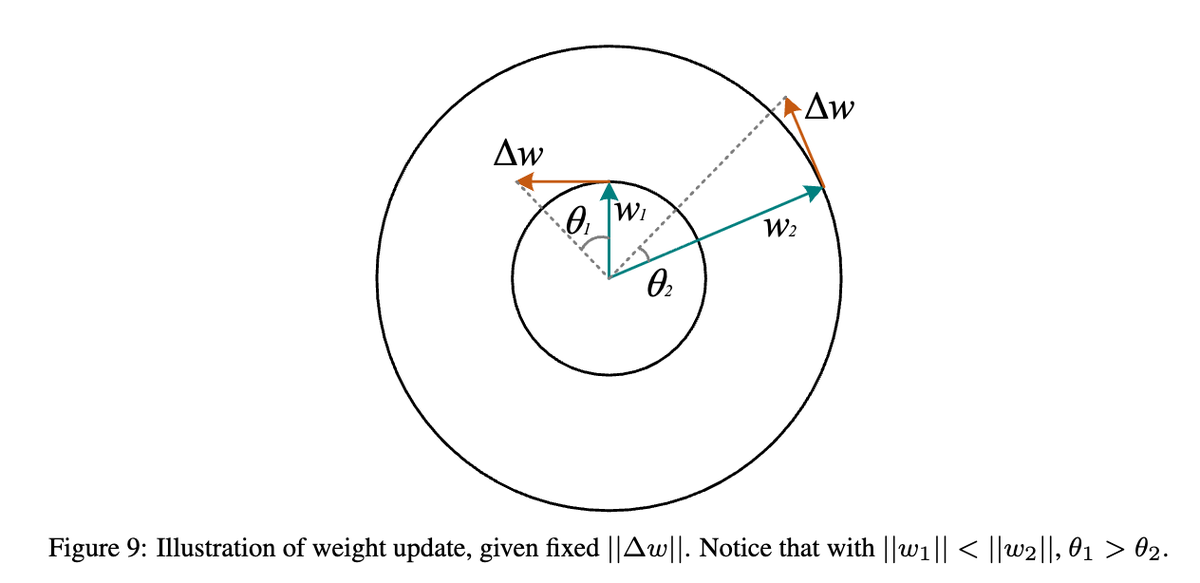
Interesting work! Doing proper normalization is definitely important for training neural networks stably. We considered hyperball normalization for convolutional neural networks back in 2018, see arxiv.org/pdf/1804.08071. Besides hyperball normalization, we also proposed multiple other normalization methods for weight/activation.
Quite surprisingly, we also did gradient normalizaiton in order to make it actually work. See Section 4 of the Decoupled Networks paper.
I somehow got the impression that many many old ideas are worth revisiting for LLM pretraining, especially those that stablizes the training (but may slightly hurt the performance for conventional CNNs).
Jan 21

(1/n) Introducing Hyperball — an optimizer wrapper that keeps weight & update norm constant and lets you control the effective (angular) step size directly. Result: sustained speedups across scales strong hyperparameter transfer.
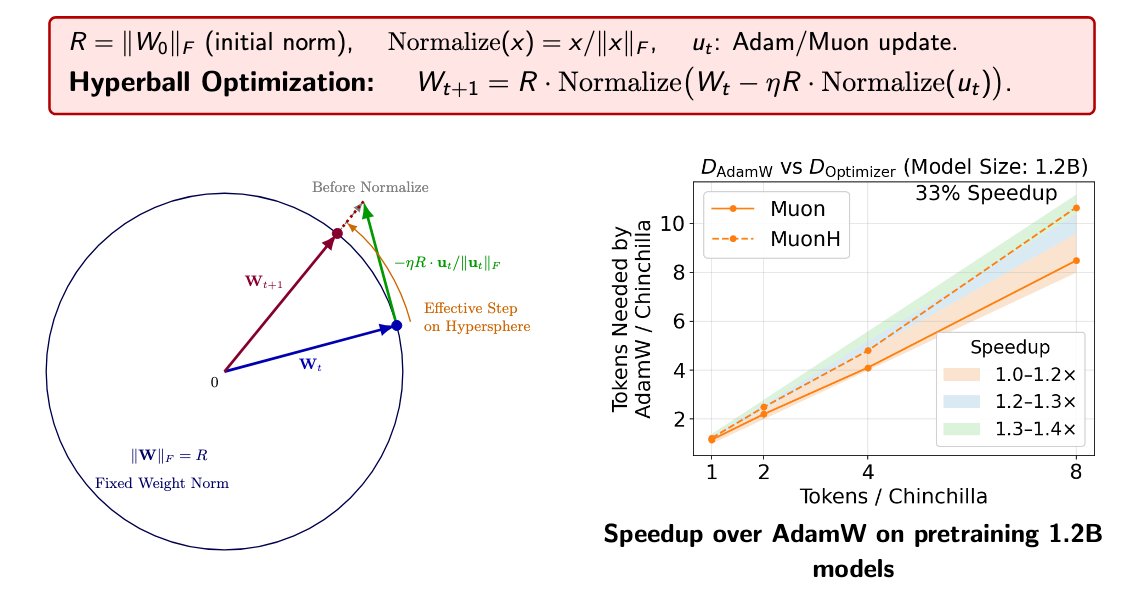
3
27
203
16,985
Tim Xiao retweeted

18 Dec 2025
😍Excited to organize @GRaM_org_ 2.0 this time at #ICLR2026 🇧🇷
🌟 Looking forward to your best works on geometry-grounded representations, inductive bias, and structure in learning.
This year, we also welcome works on
🌐open problems,
⚔️discussions on scale vs symmetry,
👊 position papers and more!
Deadline: 30th January AOE
18 Dec 2025

📢The second edition of ✨GRaM workshop✨ is here this time at #ICLR26.
🌟Submit your exciting works in Geometry-grounded representations.
We welcome submissions in multiple tracks i.e.
📄 Proceedings
📝extended abstract
👩🏫Tutorial/blogpost
as well as an exciting challenge!

2
9
28
3,310
Tim Xiao retweeted

15 Dec 2025
It's time! I will present InfiniHuman at 16:30 in room S421 at #SIGGRAPHAsia2025 . Please join me if you want to generate avatars with fine-grained multi-modal control!
@ympradyumna will present PhySIC at 16:30 in room S221. Join him to turn 2D image to 3D human Scene!

15 Oct 2025

#InfiniHuman: Infinite 3D Human Generation with Precise Control
How do you want to generate a 3D avatar?
From text description? With clothing images? Or some desired body shape? All can be done at once with InfiniHuman!
🔗Page: yuxuan-xue.com/infini-human/
#SIGGRAPHAsia2025 #AI
1
14
882

An exciting PhD opportunity at StatML CDT (Imperial) Institute of Cancer Research, with Oliver Ratmann, Richard Houlston and yours truly ☺️:
"Machine Learning for Cancer Susceptibility Genetics"
Oct 2026 entry, apply to StatML CDT by Jan 8 2026.
RT🙏
docs.google.com/document/d/1…
3
32
2,257
Tim Xiao retweeted

5 Dec 2025
Can we efficiently and robustly finetune flow matching models with reinforcement learning using differentiable rewards, in an amortized way?
Hint: use optimal control and match your velocity field with value gradients!
Please come by our poster “Value Gradient Guidance for Flow Matching Alignment” at #NeurIPS2025 (Exhibit Hall C, D, E — #4906 Fri, Dec 5 | 4:30pm – 7:40pm PST) and learn more about our VGG-Flow!
🔗ArXiv: arxiv.org/abs/2512.05116
Joint work w/ @zdhnarsil @TimZXiao @cdomingoenrich @Besteuler

2
6
32
9,628
Tim Xiao retweeted
15 Nov 2025
🤩 This is awesome. When we are doing the agentic design project (besiegefield.github.io) using the Besiege game environment, we have to hack the game to get as much feedback as possible to do RL and stuff.
However, I start to think differently after seeing the Genshin agent. We humans don’t need that much feedback to learn to master the game, and visual feedback is already sufficient. I am wondering what will happen if the agent learns to master many games this way. Will it develop some universal skills for game playing? Will it see the world differently?🤔
13 Nov 2025

🚀Introducing Lumine, a generalist AI agent trained within Genshin Impact that can perceive, reason, and act in real time, completing hours-long missions and following diverse instructions within complex 3D open-world environments.🎮
Website: lumine-ai.org
1/6
7
35
7,707
Tim Xiao retweeted
27 Oct 2025
🤯 Merging many finetuned LLMs into one model, effectively? Introducing Functional Dual Anchor (FDA), a new framework for model merging.
🚀 Current merging works poorly due to the underlying parameter conflicts. FDA shifts knowledge integration to the input-representation space for seamless merging. This "dual" perspective bridges the gap between post-hoc merging and joint multi-task training, reducing the knowledge conflicts.
✨ FDAs are synthetic anchors that precisely capture a finetuned model's functional shift.
✨ FDAs can complement existing model merging methods and achieves SOTA performance.
➡️ Paper: arxiv.org/abs/2510.21223
💻 Code: github.com/Sphere-AI-Lab/FDA
🌐 Project: spherelab.ai/fda
#AI #LLM #MachineLearning #DeepLearning

10
93
596
34,584
Tim Xiao retweeted
23 Oct 2025
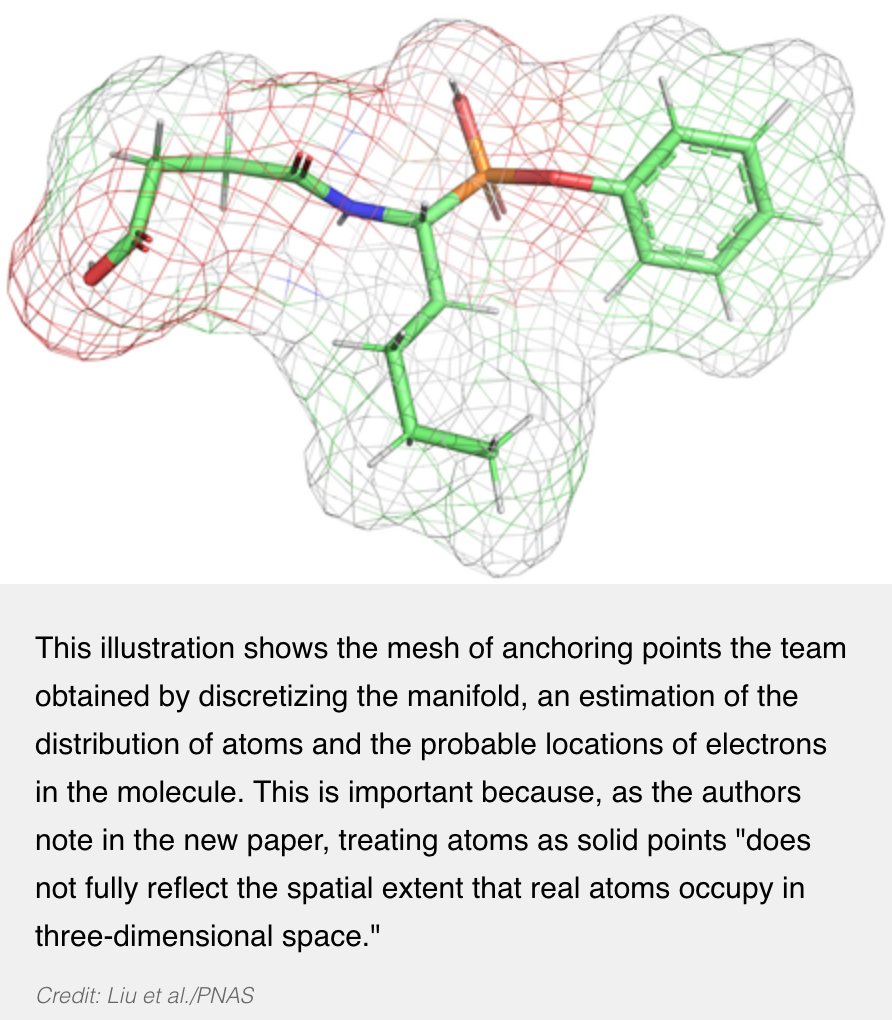
The physics prior matters in molecular structures. We model potential energy between molecules for drug design. This happens to have a coincident yet interesting connection to my past work, hyperspherical energy (arxiv.org/abs/1805.09298), which considers potential energy between imaginary electrons (i.e. neurons in neural networks). But this time we are modeling real molecules for drug design. :)
Excited that our new AI-for-science paper is finally online: "Manifold-Constrained Nucleus-Level Denoising Diffusion Model for Structure-Based Drug Design." Very glad to be part of the wonderful team. @Shengchao_Liu
Caltech news: caltech.edu/about/news/new-a…
Paper link: pnas.org/doi/10.1073/pnas.24…
Project page: yanliang3612.github.io/Nucle…
2
17
1,986
Tim Xiao retweeted

19 Oct 2025
This prompt baking reminds me of verbalized machine learning. Though they don't modify the weights, but update the parameters.
x.com/TimZXiao/status/180636…

Verbalized Machine Learning (VML) moves machine learning into natural language space, where one learns a model parameterized by natural language using LLMs.
How does VML connect LLMs with: Universal function approximator? von Neumann architecture? Interpretable learning?
How well does VML perform in classical machine learning tasks?
Let’s dive into the details!
🔗arxiv.org/abs/2406.04344

1
2
195
Tim Xiao retweeted

18 Oct 2025
Polymer simulations, but make them Vivace ⚡
It was a pleasure to work on Vivace architecture during my time in @MSFTResearch together with Lixin Sun and @gncsimm .
17 Oct 2025

MLFFs 🤝 Polymers — SimPoly works!
Our team at @MSFTResearch AI for Science is proud to present SimPoly (SIM-puh-lee) — a deep learning solution for polymer simulation.
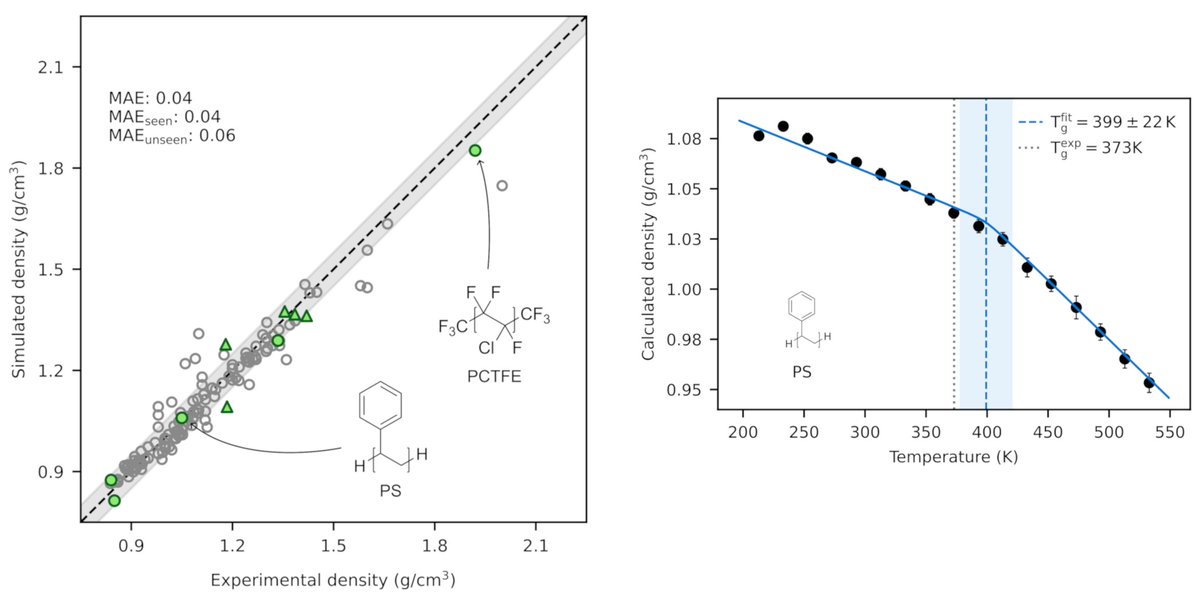
Polymeric materials are foundational to modern life—found in everything from the clothes we wear and the food we consume to high-performance materials in aerospace, electronics, and medicine. Today, we introduce a new way to simulate them.
We built a machine learning force field (MLFF) to predict macroscopic properties across a broad range of polymers—trained only on quantum-chemical data, with no experimental fitting. Specifically, we accurately compute polymer densities via large-scale MD simulations, achieving higher accuracy than classical force fields. We also capture second-order phase transitions, enabling prediction of glass transition temperatures. These two properties are fundamental to processing and application design. Finally, we created a benchmark based on experimental data for 130 polymers plus an accompanying quantum-chemical dataset—laying the foundation for a fully in silico design pipeline for next-generation polymeric materials.
The incredible team: Jean Helie, @temporaer, Yicheng Chen, Guillem Simeon, @a_kzna, @ErnestoCheco, @erunzzz, Gabriele Tocci, @chc273, @yatao_li, @SherryLixueC, @zunwang_msr, Bichlien H. Nguyen, Jake A. Smith, and Lixin Sun.
📄 Preprint: arxiv.org/abs/2510.13696
⚙️ Data and code release: in progress⏳
#MLFFs #Polymers #AIforScience #DeepLearning #SimPoly #ScientificML #Microsoft #MicrosoftResearch #MicrosoftQuantum
1
11
750
Tim Xiao retweeted
18 Oct 2025
This is almost a year-long project and led by @ItsTheZhen. My biggest takeaway is that physical simulation is very effective as a reward signal, and this efficient verification is crucial for unlocking LLMs’ design novelty. This conclusion is actually aligned with our previous work spherelab.ai/SGP-Gen, where the verification is done by a renderer.
18 Oct 2025

Can LLMs design real machines — from 🚗 cars to 🏹 catapults?
Can they engineer through both 🧠 agentic workflows and 🌀 reinforcement learning (RL) — learning from physical simulation instead of text alone?
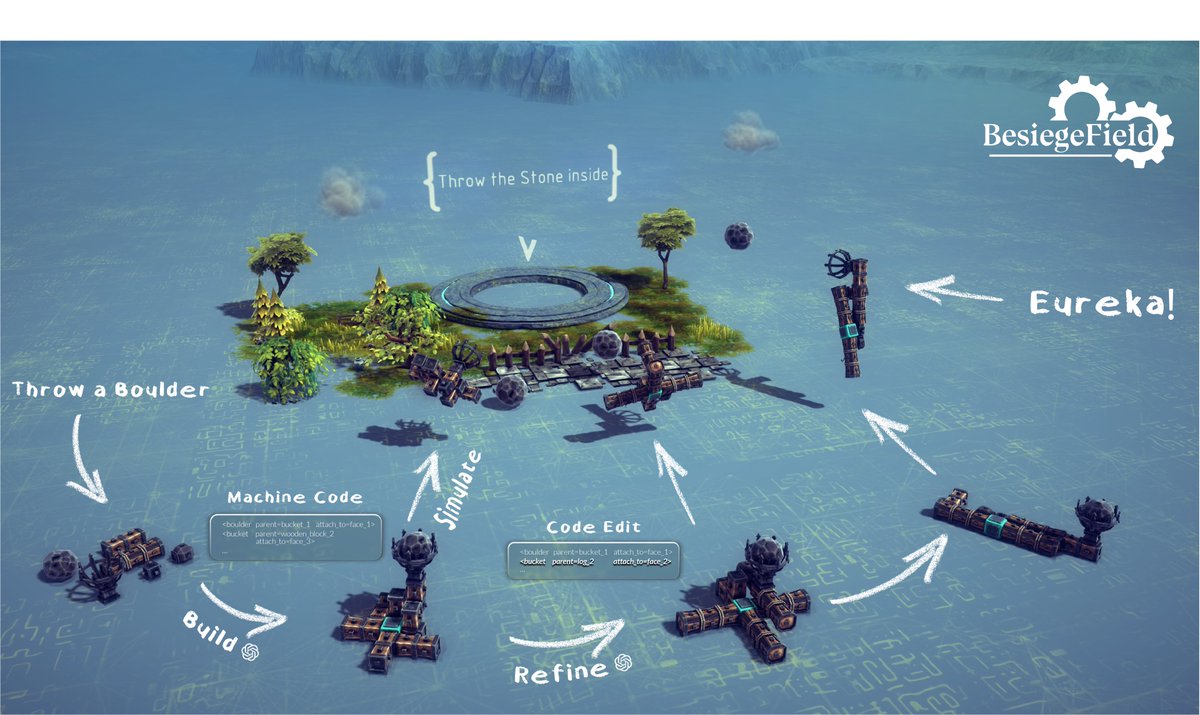
We treat machine design as “machine code writing”, where LLMs assemble mechanisms from standard parts.
To explore this, we built 🧩 BesiegeField — a real-time, physics-based sandbox where LLMs can build, test, and evolve machines through agentic planning or RL-based self-improvement.
Our findings:
1️⃣ Even top LLMs fail to build working catapults — easy for humans but highly dynamic ⚙️ and nonlinear.
2️⃣ RL helps — working designs emerge through interaction.
3️⃣ Aligning reasoning 🧩 with construction 🔩 remains a key challenge.
This marks the first step toward LLMs that learn to design through action — bridging reasoning, physics, and embodiment. 🛠️🤖
🌐 Project Website: besiegefield.github.io/
💻 GitHub (RL & Agentic Workflow): github.com/Godheritage/Besie…
👥 Joint work w/ @Besteuler & Wenqian Zhang
6
32
5,686
Sharing a fascinating work: BesiegeField. It explores how LLMs can think and design directly in the space of natural language — a meaningful and fitting challenge for LLMs.
A great example of verbalized computing, where design goals are defined in words rather than formal specs.
18 Oct 2025
Can LLMs design real machines — from 🚗 cars to 🏹 catapults?
Can they engineer through both 🧠 agentic workflows and 🌀 reinforcement learning (RL) — learning from physical simulation instead of text alone?
We treat machine design as “machine code writing”, where LLMs assemble mechanisms from standard parts.
To explore this, we built 🧩 BesiegeField — a real-time, physics-based sandbox where LLMs can build, test, and evolve machines through agentic planning or RL-based self-improvement.
Our findings:
1️⃣ Even top LLMs fail to build working catapults — easy for humans but highly dynamic ⚙️ and nonlinear.
2️⃣ RL helps — working designs emerge through interaction.
3️⃣ Aligning reasoning 🧩 with construction 🔩 remains a key challenge.
This marks the first step toward LLMs that learn to design through action — bridging reasoning, physics, and embodiment. 🛠️🤖
🌐 Project Website: besiegefield.github.io/
💻 GitHub (RL & Agentic Workflow): github.com/Godheritage/Besie…
👥 Joint work w/ @Besteuler & Wenqian Zhang
4
152
Tim Xiao retweeted
18 Oct 2025
🤖 Can LLMs learn to create? Introducing "Agentic Design of Compositional Machines" — a new frontier where AI builds functional machines from standardized parts.
We present BesiegeField, a simulation testbed to benchmark LLMs on tasks like building cars & catapults. Key findings:
🔧 Compositional design is extremely challenging even for SOTA LLMs (human can easily do better)
🛠️ Multi-agent workflows RLVR boost performance
⚙️ Physical simulation as a verifiable reward is effective for eliciting LLM’s design capabilities.
🧠 High-level planning ≠ precise execution — a core challenge
Paper: arxiv.org/abs/2510.14980
Project: besiegefield.github.io
#AI #Agents #LLM #GenerativeAI #AIGC #Simulation #RLVR

1
4
14
1,094