
I'm Questing, don't bother me
Joined November 2022
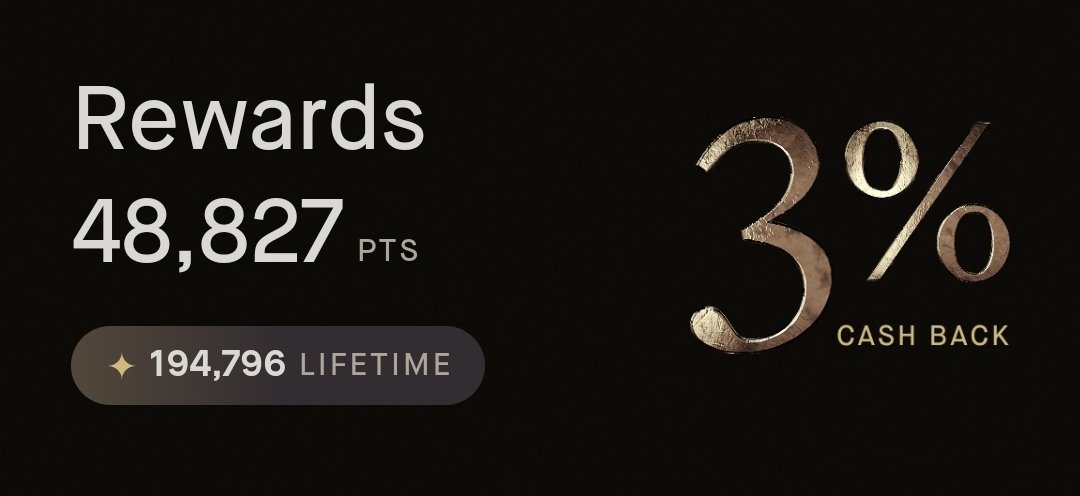
- Tweets 3,176
- Following 1,191
- Followers 401
- Likes 6,140
384 Photos and videos
















READ IT TO BELIEVE IT 🚨 TESLA'S LATEST PATENT HAS SOLVED THE BIGGEST ANXIETY—THE HARDWARE OBSOLESCENCE—FOR ALL HW3 and HW4 OWNERS 🔥
If you are driving a Hardware 3 vehicle, you might feel like the clock is ticking on your Full Self-Driving capabilities. If you just bought a shiny new AI4 model, you are likely looking over your shoulder at the rumors of the upcoming AI5, wondering if your cutting-edge car is about to become a legacy artifact.
But on January 15, 2026, Tesla quietly published a document that should let every owner breathe a massive sigh of relief. Patent US20260017503A1 is not just a collection of circuit diagrams; it is a technical lifeline.
It reveals a sophisticated method for "BIT-AUGMENTED ARITHMETIC CONVOLUTION" that essentially allows Tesla to push future-generation AI models onto current-generation silicon.
For the Hardware 3 owners feeling abandoned, this is your consolation prize—proof that Tesla is engineering deep-tech workarounds to keep your car in the game. For the AI4 buyers, this is your safety net, ensuring that the neural networks of the future won't break your investment.
This patent confirms that Tesla isn't just relying on new chips to solve autonomy; they are rewriting the rules of math to ensure the car in your driveway today can "think" with the precision of the cars being built tomorrow.
🛑 The problem: The hardware-software mismatch
Designing hardware for autonomous vehicles is a brutal balancing act because the product lifecycle of a car spans decades, while the lifecycle of an AI algorithm is measured in weeks or months. When Tesla designs a chip, like the FSD computer, they have to lock in the hardware architecture years before the car hits the road.
They might fill the chip with 8-bit multipliers because they are fast, small, and power-efficient. In the world of computing, "bits" are just the amount of detail a computer can handle at once. Think of an 8-bit system like a box of 256 crayons. It is great for basic coloring, but it lacks nuance.
However, three years later, the AI team might develop a massive new Transformer model or an Occupancy Network that performs best with 16-bit or 32-bit data. These newer models are like using a box of 65,000 crayons—they can see subtle shades and textures that the 8-bit box simply misses.
Suddenly, you have a mismatch. The new software is too "heavy" and detailed for the old hardware, and you cannot physically upgrade the chips in millions of cars already on the road.
The traditional solution is to "quantize" the model. This basically means taking that high-definition 16-bit picture and crunching it down to a grainy 8-bit version to fit the chip. But "dumbing down" the data degrades performance and accuracy—something you absolutely cannot afford when the car is trying to distinguish a stop sign from a red balloon at 60 mph.
💡 Tesla's solution: Virtual high-precision arithmetic
Tesla’s engineers have devised a brilliant workaround that essentially uses software logic to hack the physical limitations of the hardware. Instead of dumbing down the data, they break the high-precision data into smaller, manageable chunks that the hardware can understand.
If the hardware can only eat "bite-sized" 8-bit pieces, but the data comes in a "king-sized" 16-bit format, this system splits the 16-bit data into two 8-bit packages. They call this process "deplaning."
The system separates the Most Significant Byte (the big numbers) from the Least Significant Byte (the fine details). Think of this like looking at a price tag of $1,500. The "Most Significant" part is the $1,000 (the big picture), and the "Least Significant" part is the $500 (the specific detail).
These separate "planes" are then fed through the standard, lower-precision hardware independently. Once the hardware processes these chunks, the system cleverly stitches the results back together at the end, applying the necessary mathematical shifts to reconstruct a high-precision output. It is like moving a grand piano through a narrow door by taking the legs off first and reassembling it inside.
🔪 The genius of deplaning: Weaponizing the MAC array
The genius of this patent lies in how Tesla re-purposes the existing hardware to handle this splitting process. Normally, preparing data—like splitting 16-bit numbers into 8-bit chunks—is a housekeeping task left to the Central Processing Unit (CPU) or a simple Arithmetic Logic Unit (ALU).
The problem is that the Neural Network Accelerator is a beast that eats data faster than a CPU can spoon-feed it. If you ask the CPU to split every pixel in a 4K video feed into high and low bytes, the accelerator will starve waiting for the data.
Tesla’s solution is to perform this "surgery" using the accelerator itself. They realized that a mathematical convolution is just a fancy way of multiplying and adding. "Convolution" is just the math word for sliding a filter over an image to find patterns, like edges or colors.
So, they designed a specific "kernel"—which acts like a digital stencil or cookie cutter—that tricks the convolution engine into acting like a data splitter.
The patent details a specific "deplaning" operation that avoids the memory bottleneck entirely via a "stride-two" hack. Imagine a stream of 16-bit raw data entering the chip. Instead of stopping the flow to cut these numbers in half, Tesla runs a 1x2 convolutional kernel over them with a specific stride of two.
A "stride" is just how many steps the filter skips as it moves across the data. They define a kernel of [1 0] and another of [0 1]. When the hardware convolves the [1 0] kernel with a stride of two, it mathematically multiplies the first byte (the big number) by 1 and the second byte (the detail number) by 0.
The stride of two then forces the window to jump over the next byte, effectively snatching only the "upper" halves of the numbers. A parallel process runs the inverse [0 1] kernel to snatch the "lower" halves.
This effectively turns the massive array of multipliers—usually reserved for finding lane lines or stop signs—into a high-speed data shredder, separating the high-precision signal into two digestable streams without ever slowing down the pipeline.
🧮 Doing the math: The four-way cross-multiplication
Once the data is split into these lower-precision planes, the system runs the neural network layers on them. This involves convolving weights (the learned parameters of the AI) across the input data. If the weights themselves are also high-precision, they get split up too.
The patent describes a reconstruction method that mirrors the "FOIL" method (First, Outer, Inner, Last) you might remember from high school algebra. To multiply a 16-bit input by a 16-bit weight using only 8-bit hardware, the system actually performs four distinct operations: High-byte x High-byte, High-byte x Low-byte, Low-byte x High-byte, and Low-byte x Low-byte.
Because the hardware just sees 8-bit integers and doesn't know that a "High-byte" is worth 256 times more than a "Low-byte," the patent specifies a post-processing shift.
The results involving a High-byte are conceptually "left-shifted" or multiplied by 256 to restore their magnitude. Think of this like adding zeros to the end of a check. A "1" in the millions place is worth way more than a "1" in the ones place, so the system has to add those zeros back in to make the math work.
The system then sums these four partial products in a larger accumulator register to get the final, mathematically perfect high-precision answer. This allows the 8-bit silicon to punch way above its weight class, delivering 16-bit or even 32-bit accuracy by simply running four times as many cheap operations rather than one expensive operation.
💾 Data storage: The logarithmic packing format
Perhaps the most specific detail in the patent is how they handle the massive numbers generated by this process. When you stitch two 16-bit operations back together, you often end up with a 32-bit result. However, moving 32-bit numbers around the chip consumes expensive memory bandwidth—it clogs the pipes.
Tesla’s solution, described in the later sections of the patent, is a custom data format that compresses this 32-bit value back into a 16-bit container without losing the "meaning" of the data.
They utilize a custom floating-point format that drastically skews the balance between the "exponent" and the "mantissa." In scientific notation (like 1.23 x 10^5), the exponent is the "10^5" part that tells you how big the number is, and the mantissa is the "1.23" part that gives you the precision.
Standard formats might split the bits evenly, but Tesla’s patent proposes using a massive 10-bit exponent and a tiny 5-bit mantissa.
This is a deliberate engineering trade-off. In autonomous driving—specifically for "Occupancy Networks" that map 3D space—knowing the scale of an object (is it 5 meters away or 50?) is often more critical than knowing the precise millimeter detail.
By allocating 10 bits to the exponent, the format can represent a gargantuan dynamic range of values, preventing the "overflow" errors that crash standard integer math, while packing the data tight enough to keep the memory bus running cool and fast.
➕ Handling the sign: Zero-padding vs sign-extension
The document also touches on the subtle but headache-inducing problem of negative numbers. In binary math, the "sign" of a number (positive or negative) is usually determined by the first bit.
When you slice a 16-bit number in half, the lower 8 bits lose their context—the hardware doesn't know if they belong to a positive or negative whole.
The patent details a logic flow for "Sign Extension." If the original number was signed (like a velocity vector, which needs to know if the car is moving forward or backward), the system has to intelligently fill the empty bits of the upper planes with ones or zeros to preserve that negative value.
Conversely, for "natural numbers" like pixel intensity (which are always positive because you can't have negative light), it uses "Zero Padding." This dynamic switching ensures that the system works equally well for image data (unsigned) and motion vectors (signed), making it a universal accelerator for the entire Full Self-Driving stack.
❄️ Efficiency: Why this beats bigger chips
You might wonder why Tesla does not just put bigger, more powerful chips in the cars to begin with. The answer lies in the constraints of an electric vehicle: power and heat.
A 16-bit multiplier takes up significantly more silicon area and consumes much more electricity than an 8-bit multiplier. It creates heat that is hard to get rid of.
By sticking with the smaller, narrower hardware, Tesla keeps the chip size down and the power consumption low, which preserves battery range and simplifies cooling. This patent allows them to have their cake and eat it too; they get the thermal and physical benefits of efficient, low-precision hardware while retaining the ability to run high-precision, cutting-edge AI models whenever the safety case demands it.
🚀 How this patent contributes to Tesla's now and future
This patent is the strategic linchpin that prevents Tesla’s older fleet from becoming obsolete as their AI ambitions grow. Consider the millions of vehicles currently on the road running Hardware 3. These chips were designed in an era when standard Convolutional Neural Networks running 8-bit integer math were the gold standard.
However, the industry has rapidly shifted toward massive "End-to-End" Transformers and complex Occupancy Networks that crave the stability and dynamic range of 16-bit or even 32-bit floating-point precision.
Without the technology described in this document, Tesla would face a brutal fork in the road: either cap the intelligence of their newest models to accommodate the old hardware, or leave millions of customers behind.
This "bit-augmented" breakthrough provides a third option, effectively emulating next-generation precision on current-generation silicon. By unlocking virtual high-precision arithmetic, Tesla unshackles its AI training team.
Engineers training models on massive H100 or Dojo clusters can now push for higher fidelity—using that custom 10-bit exponent to perfectly track distinct objects at 300 meters—without worrying that the car’s computer will fail to execute the math.
It allows for a unified software stack where a single, sophisticated model architecture can be deployed across Hardware 3, Hardware 4, and the upcoming AI5. The system simply adjusts how many "passes" the hardware makes to achieve the required precision.
This not only saves the company billions of dollars by avoiding a logistical nightmare of hardware retrofits but also ensures that the "Full Self-Driving" capability sold years ago can actually be delivered using the cutting-edge transformer models of today and tomorrow.

135
204
1,489
262,083

Jan 1
He's right...
31 Dec 2025

Tesla is obviously way far ahead of Waymo because Waymo cannot do a fully driverless coast to coast drive in the US.
Tesla can make 2 million of these self-driving capable cars per year and has millions of them on the road already.
Waymo has about 3,000 cars that cannot achieve this feat and are aiming to do 10,000 cars per year by 2027 that would still be incapable of doing this because of their approach.
It’s pretty obvious where this is going.
$TSLA
1
47
14 Nov 2025
Oh so hes into tech now eh?


1
125
14 Nov 2025
Terrible judge
13 Nov 2025

Epic fail by the Delaware Chancery Court, particularly with judge Kathaleen McCormick, who robbed Tesla investors of their proxy votes, destroying the democratic process for corporate governance. This has created YEARS of stress and uncertainty about the future for Tesla shareholders. Few things have sparked more outrage in the Tesla investor community.
Judge McCormick single-handedly ruined a massive source of income for Delaware. The bleeding will not stop, and there is nothing they can do. Other companies are following Tesla’s lead in moving to other states where the proxy voting process is respected.
43
12 Nov 2025
Gotta wonder how the vibes are at the office
12 Nov 2025

Imagine costing the state of de millions in income because you had a personal vendetta against one man. The face of pure stupidity and ego kathaleen mccormick

1
2
46
Toddlogical retweeted

9 Nov 2025
.@Tesla Holiday Update 2025 should add approach lighting, I want the car to do a cool sequence when I'm walking up to it.
THANK YOU FOR YOUR ATTENTION TO THIS MATTER

37
27
528
28,041
Toddlogical retweeted

7 Nov 2025
$PLTR
Palantir CEO Alex Karp today:
“We are making workers more valuable and increasing the quality of revenues for businesses. With 121% growth on a large base, you are seeing startup type of growth with margins that no startup could ever have, in the public markets.”
120
148
1,668
132,047
24 Oct 2025
Put me in coach $HOOD @vladtenev
23 Oct 2025

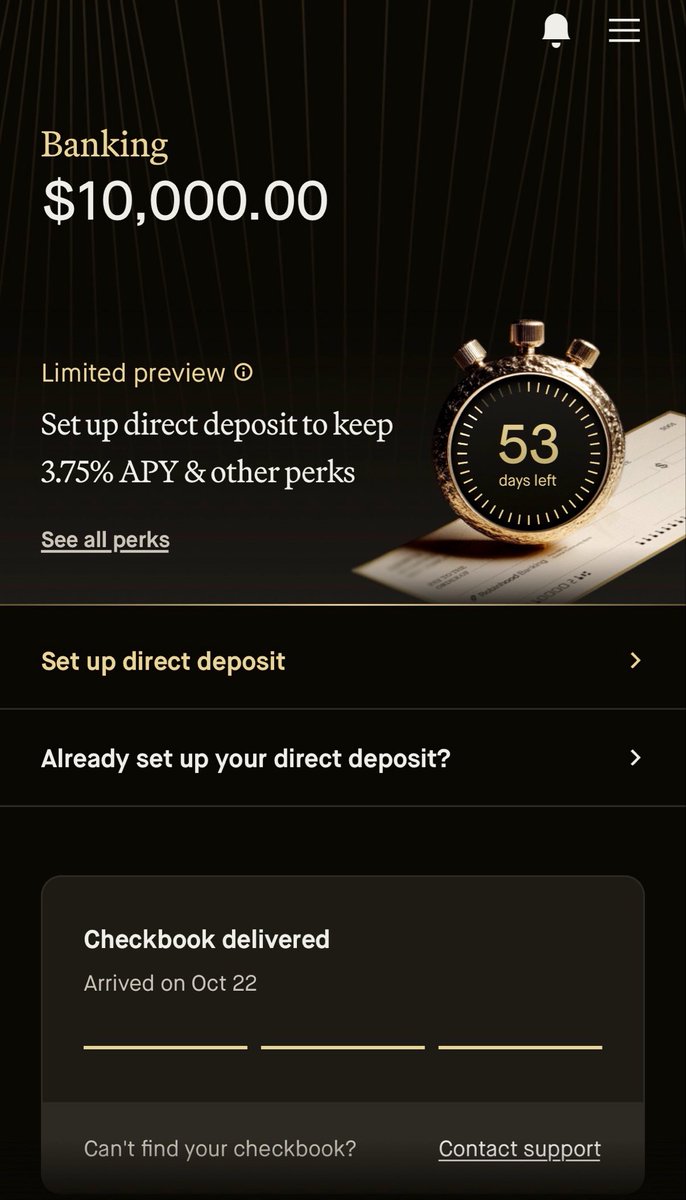
@RobinhoodApp just became my primary bank!
All future paycheck go directly into my new bank account! Now it’ll yield 3.75% instead of 0.01% in @WellsFargo.
$HOOD is already the finance SuperApp and will continue to add more features.

1
112
Toddlogical retweeted

7 Oct 2025
Never eat McDonalds again
Most brush it off, thinking it’s inconsequential. An innocent act of occasional indulgence.
What’s the matter?
Wake up. McDonalds is a drive-thru confessional.
It’s a philosophy of decay…
a global religion built on pleasure
trading vitality for comfort
opium for the masses
soothing our pain for a moment
profiting as you bankrupt
a cathedral of end-times
They use a clown to mask the manipulation. Toys to disguise the trap. Bright colors to camouflage your decay. It reveals what we have become: creatures who would rather indulge than be alive.
At the golden arches, we kneel not to God but to grease.
And whisper, with full mouth and empty soul:
“I’m lovin’ it.”
773
247
4,095
1,585,176
Toddlogical retweeted

1 Oct 2025
We’ll be better off without the EV tax credit.
107
17
818
47,632
Toddlogical retweeted
29 Sep 2025
$HOOD and $APP both gapping up 8% today likely because of S&P end of month rebalance
given they are two of the newest editions to the index, makes sense that funds are adding to them today to match their portfolio allocation benchmarks
what’s more wild about this is seeing the largest financial institutions in the world be forced to buy a stock you bought years ago
and then you sit back and let the big boys fight over getting $HOOD at $129 or $130 knowing you bought it at $20 lol
the stock market truly is a remarkable machine and if a company can execute well enough to force liquidity through something like an S&P inclusion, it really can change lives
LFG!!!!

126
97
1,399
219,749
18 Sep 2025
Epic shot. 👏
18 Sep 2025

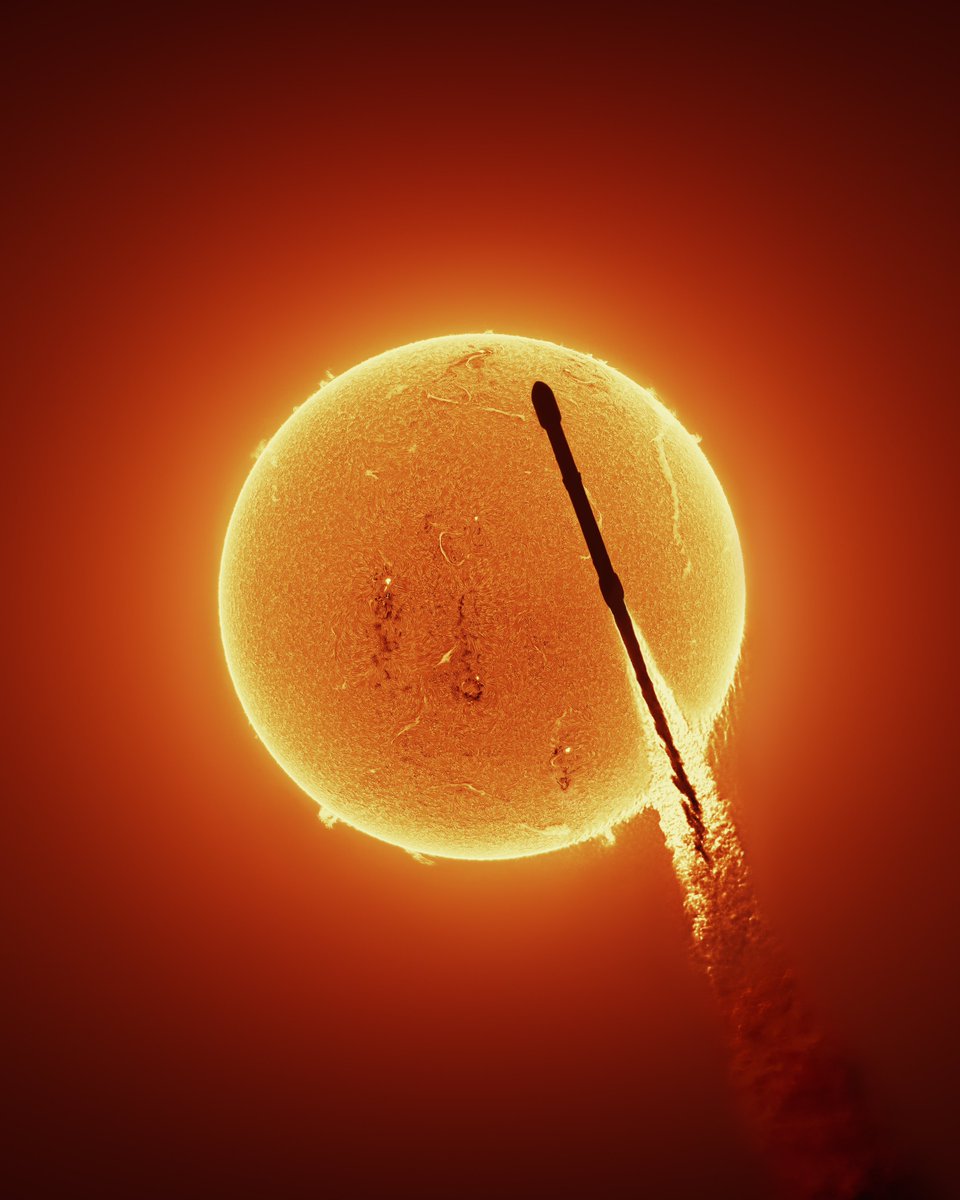
I’m proud of this one.
I brought a solar telescope to Florida to capture a Falcon 9 rocket launch transiting the sun. While these have been captured before, never with the details of the sun’s chromosphere, which makes this one the first!
See the video or get the print below 👇
33
Toddlogical retweeted

18 Jul 2025
i vibe coded a little game called Coldplay Canoodlers
you're the camera operator and you have to find the CEO and HR lady canoodling
10 points every time you find them
👇link
622
3,970
57,994
5,088,609
Toddlogical retweeted

22 Jun 2025
Timeline of U.S. Airstrikes on Iran (All times in Iran,s local time):
•Before 1:00 AM – Israeli drones triggered air defense systems across multiple Iranian regions.
•1:14 AM – Fighter jets reported over Shiraz.
•1:22 AM – Multiple aircraft spotted over central #Iran.
•2:04 AM – Two jets (likely bombers) and a loud explosion reported near Qom close to the #Fordow nuclear facility.
•2:13 AM – Explosion heard near Kashan, another city in proximity to Fordow. 1/2
81
1,568
18,016
8,644,827
Toddlogical retweeted

3 Apr 2025
No one is more hated than the unvaccinated 👇
The vaccinated hate you because they don’t have your courage. 💉
The government hates you because they cannot control you. 👮♂️
The pharmaceutical companies hate you because they make no profit off you. 💊
The media hates you because they cannot manipulate you. 📺
Let them hate—stand your ground and tell them to fuck off! 🖕
732
2,941
13,411
231,938
Toddlogical retweeted

3 Apr 2025
Stephanie Turner said:
"It will probably, at least for a moment, destroy my life.”
Turner knelt to stand up for women's sports.
She's a hero.
Doing the right thing is never wrong.
Share this ad to show her she has our support.
525
7,564
32,854
797,857
Toddlogical retweeted

1 Apr 2025
BREAKING: Elon Musk says the U.S. government “deleted a terabyte of financial data to cover their crimes,” but “they don’t understand technology, so we recovered it.”
Elon Musk grinned as his team of young tech wizards unveiled a terabyte of financial records, allegedly erased by the U.S. Institute of Peace to hide illicit payments to shadowy groups.
“They thought they could bury their tracks,” he smirked, tapping away at his gaming rig, “but they don’t get tech like we do.” The screens flickered with recovered data, contracts, transfers, names, hinting at a scandal that could topple careers, though the details remained murky.
A federal judge, issued an injunction to try to halt DOGE’s digs, but Musk just laughed, “Too late, the truth’s already out.”
663
6,107
32,414
2,306,225
Toddlogical retweeted

27 Mar 2025
This is actually plum wild...
265
682
6,723
586,761

People are shocked when they learn that up to 90% of serotonin (“the happiness hormone”) is produced in the gut.
They are also surprised to discover that around 70% of the immune system is also located in the gut.
Understand this: what you eat directly affects the gut-brain axis, and, in turn, your physical and mental health.
Treat your gut right, and your whole body follows.
153
1,046
5,247
181,903