
ALL IN | MAXI | @Gradient_HQ
Joined October 2024
- Tweets 1,265
- Following 299
- Followers 353
- Likes 3,595
148 Photos and videos















Pinned Tweet

16 Dec 2025
You're working on Airdrop
I'm working on project
We are not the same
11
3
51
2,518
Vin ./ retweeted

May 18
Fraction of the bill. Same results.
Fully local, open source, works with any client.
Just > pipx install uncommon-route
github.com/CommonstackAI/Unc…
39
44
135
447,951
Vin ./ retweeted

May 4
2022 - Student
2023 - Developer
2024 - Prompt Engineer
2025 - Vibe Coder
2026 - AI Agent Babysitter
2027 - Farmer
226
1,408
14,521
711,278
Apr 25
Deepseek V4 available on @commonstack_ai within a day !!
The update is as fast as the throughput of the api!
Apr 24

DeepSeek V4 flash is on par with GPT 5.4 (high), the best part is that it’s much more affordable at scale:
GPT 5.4 pro vs DeepSeek V4 flash:
Input: $30/M vs $0.14/M (214x cost difference)
Output: $180/M vs $0.28/M (643x cost difference)
Both at a million context, DeepSeek V4 Flash is really a bargain for intelligence.

6
173

🔬 lab works & stuff
come by to see some of the recent research works of the team.
📍 location: builder hub
🗓️ time: april 25th 1pm UTC
./ 🥼 coat on @Gradient_HQ

10
12
57
3,080
Apr 22
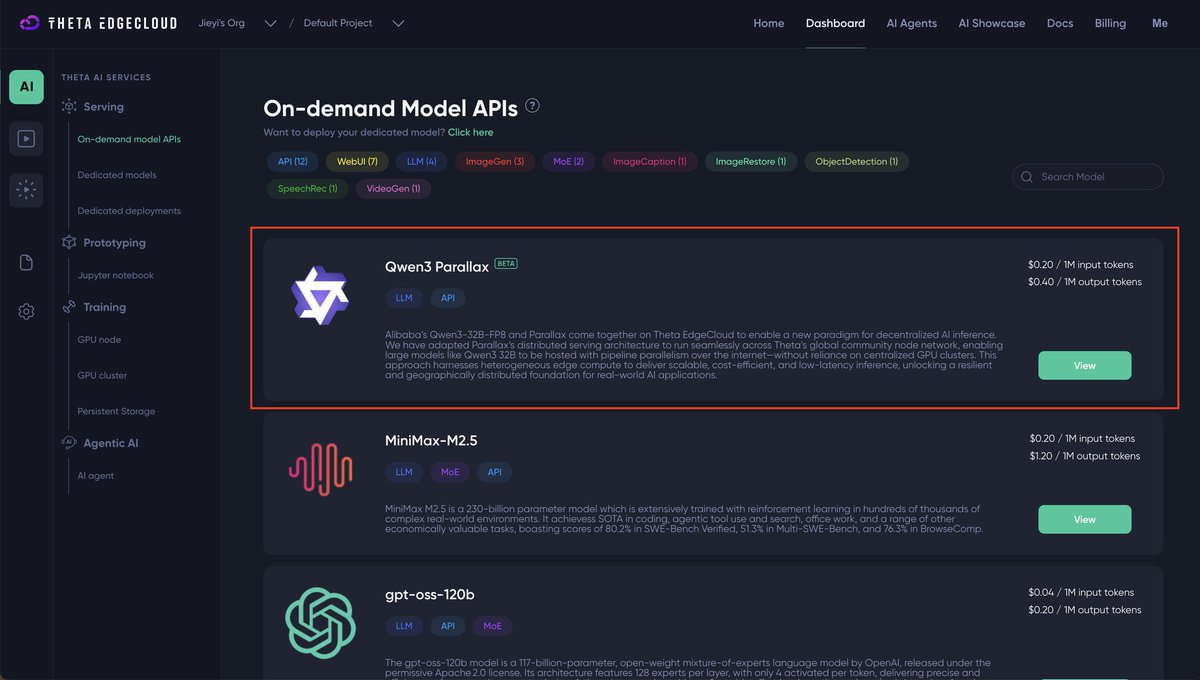
Finally, @tryParallax getting the attention it deserves.
You can run your own too at a fraction of the cost and it's private
Apr 21
Awesome to see @tryParallax’s distributed framework for heterogeneous machines being implemented and serving up inferences!
Build and customize your own clusters for AI like never before 🤖
./ LFG @Gradient_HQ
2
18
734
Apr 13
依照圖片我也覺得討論是蠻刺激的


1
89
🤖 Gradient Live Knowledge Trivia!
Come by to join us on a 20 question trivia! See where you stack up for knowledge among Grads!
📍 Location: Builder Hub
🗓️ Time: April 11th 1PM UTC
./ @Gradient_HQ memory engine on 🧠

12
17
52
2,639
Vin ./ retweeted

Apr 8
Our cofounder @0xEricYang sat down with @yacinelearning to walk through Echo-2’s distributed RL architecture.
Dive in to learn about async RL with distributed infra, and how we are scaling this for businesses to win in the agentic era.
Apr 7

for those interested in distributed reinforcement learning I just finished a ~1h tutorial on the echo2 framework by @Gradient_HQ
we check:
- how to do async RL
- infra split between rollout workers and centralized learner
- interview with gradient cofounder eric yang himself!

40
48
253
35,745
Vin ./ retweeted

Apr 7
for those interested in distributed reinforcement learning I just finished a ~1h tutorial on the echo2 framework by @Gradient_HQ
we check:
- how to do async RL
- infra split between rollout workers and centralized learner
- interview with gradient cofounder eric yang himself!
14
48
399
45,993

Mar 26
We're expanding pre-train and model size, it's time to explore post training.
like how we, human learn, experience, we learn as we do , on the go, everyday!
Mar 26

Benchmarks that test what models have memorized are saturating fast. ARC-AGI-3 is asking a harder question: can AI actually learn something new on the fly?
One direction we've been exploring: multi-agent orchestration. In our study, coordinating four frontier LLMs across multiple turns consistently matched or outperformed the strongest single model, even on tasks none of them could solve alone.
The gap between "best single model" and "best coordination of models" is where a lot of the real progress is hiding.
More on our multi-turn, multi-agent orchestration study: arxiv.org/abs/2509.23537
10
168

Vin ./ retweeted
Mar 17
Our GTC takeaway is clear: NVIDIA is betting hard on open.
- NemoClaw turns OpenClaw into enterprise infrastructure.
- Nemotron 4 will be open-sourced.
- Nemotron Coalition puts eight labs on a shared open frontier model.
This is what we've been building toward. Open infrastructure for open intelligence is the direction the biggest AI companies are taking.

74
55
304
27,400
Vin ./ retweeted
Mar 13
Every AI model you use went through two phases:
- Pre-training builds raw intelligence (reading the internet).
- Post-training builds judgment (learning to be useful).
Reinforcement learning plays a huge part in the latter.
Here's why it matters and how we make it better.
41
54
289
18,894

Vin ./ retweeted

Mar 12
perplexity just announced always-on ai running on a mac mini.
the category is real. the question is whether your always-on ai should phone home to someone else's servers or run entirely on your own hardware.
we built parallax for the second option.
Mar 11

Announcing Personal Computer.
Personal Computer is an always on, local merge with Perplexity Computer that works for you 24/7.
It's personal, secure, and works across your files, apps, and sessions through a continuously running Mac mini.
2
33
964
Mar 10
Welcome to Clawbox
> No need to have a Macmini or renting VPS.
> No setup hassle. just download and run.
> Various model options at arguably the most affordable prices.
Get it here : commonstack.ai/clawdbot
1
2
15
416
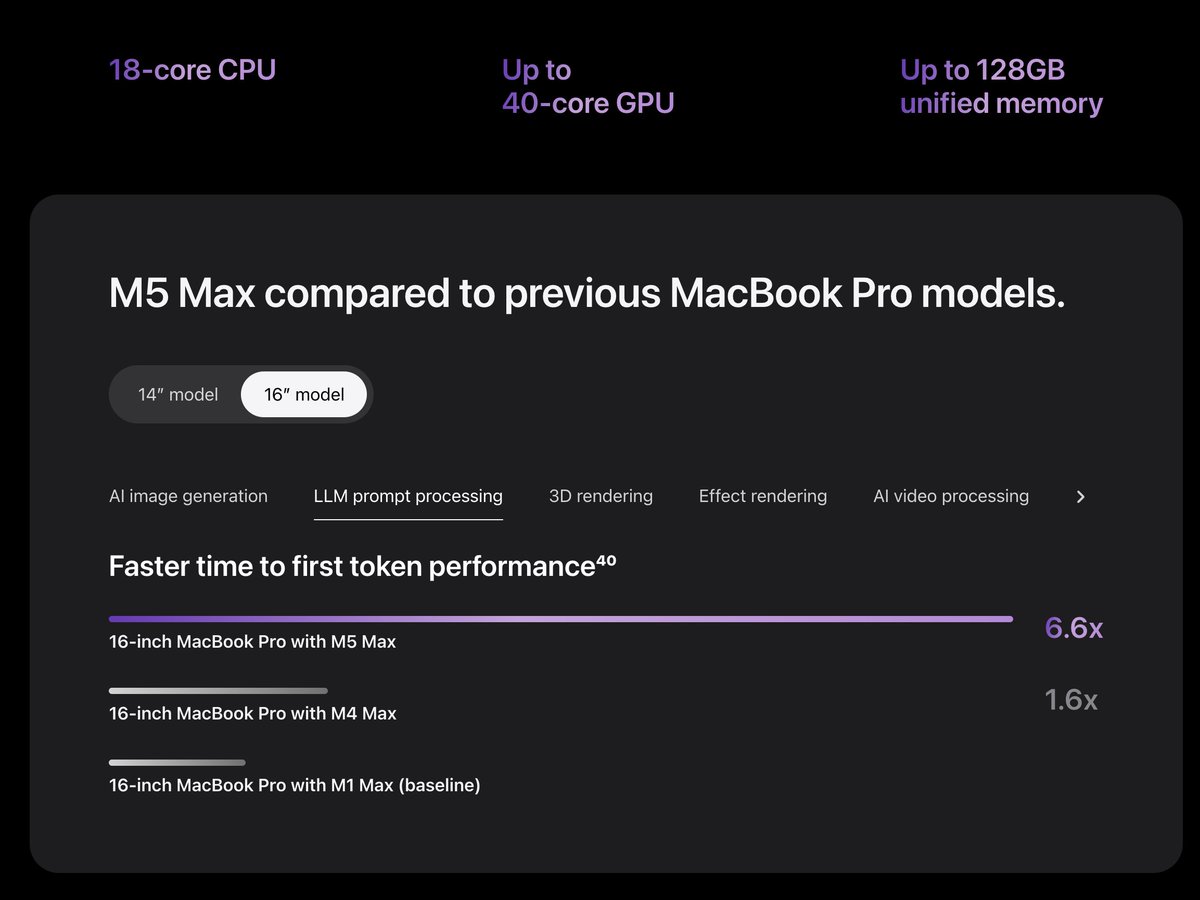
Mar 4
what crazier is the device receive a 200% performance boost at any crowded coffeshop

Apple just dropped the M5 Max MacBook Pro and it's an AI Powerhouse. 4x faster AI Compute over M4 Max.
These Specs are insane:
- 18-core CPU with 6 "super cores" = world's fastest CPU core
- 40-core GPU = rivals an RTX 4070 in a laptop
- 128GB unified memory = more than most servers
- 614 GB/s bandwidth = 4x what a DGX Spark gets
- 24-hour battery life
You can now run Llama 70B, a model that required a $40,000 GPU cluster 18 months ago on, a laptop at your local coffee shop.
At ~20-30 tokens/sec it's fast enough to actually use.
The "local AI" revolution just shipped for $3,499.
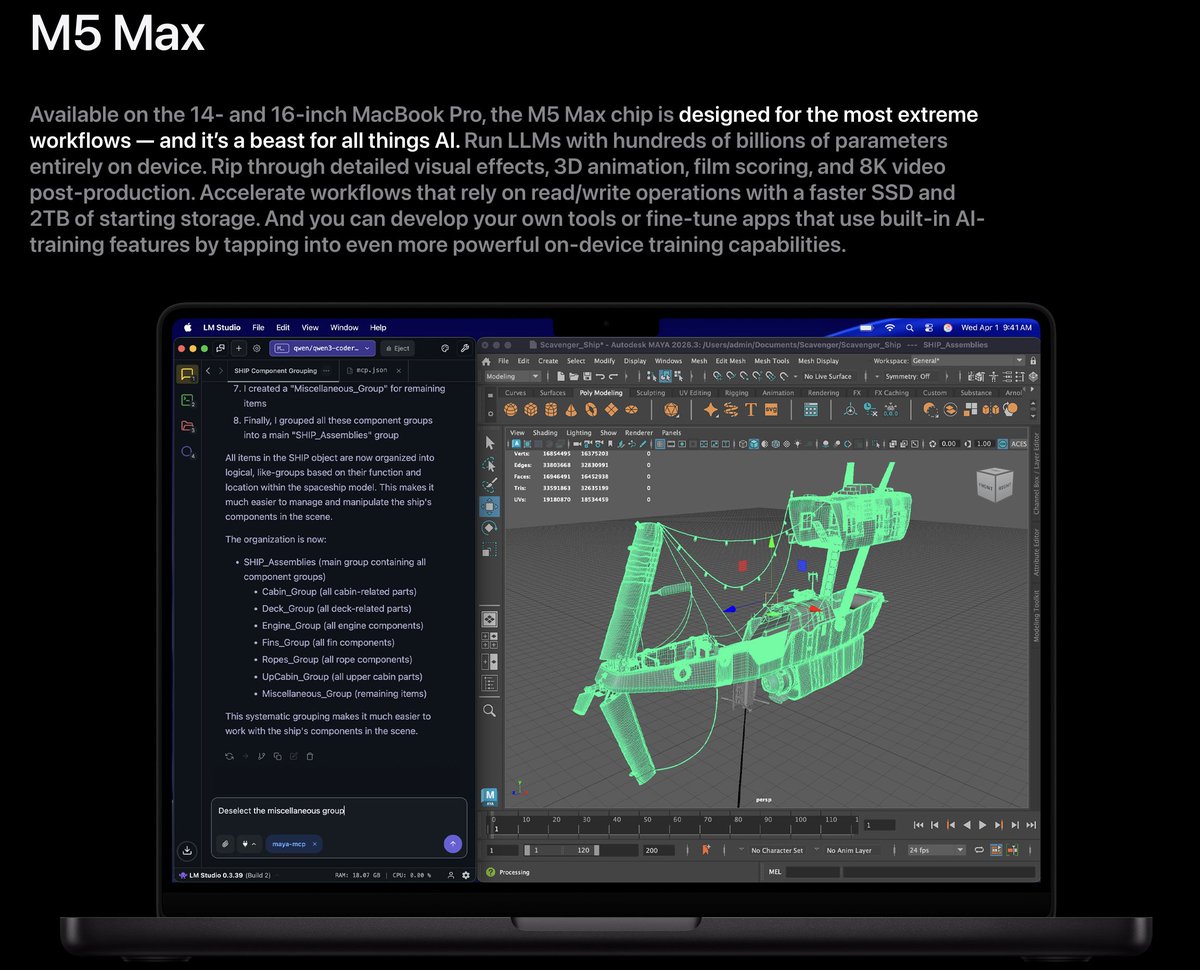
4
124
Vin ./ retweeted

Mar 2
Great conversation with @supercyclepod.
Building Gradient has been a relentless process, but the real inflection point is ahead. Intelligence belongs to everyone, and we intend to make that a reality.
Watch it in full:
Mar 2

AI should be a public good, not something gatekept by a handful of megacorps
We had Eric Yang, co-founder of Gradient Network, on the pod this week to talk through exactly that.
Gradient's "Open Intelligence Stack" includes:
i) Parallax for distributed model serving
ii) Echo for decentralized reinforcement learning
The whole thesis is that anyone should be able to run large models on consumer hardware (yes, including your Mac Minis OpenClaws)
Eric breaks down their $10M seed round led by Pantera, Multicoin, and HSG; where he sees the industry heading; and why post-training is going to be the dominant force in enterprise.
Timestamps:
00:00 Intro
01:15 AI market is booming
02:29 Local compute is a hot topic
03:02 Parallax Inference Engine
04:34 Intelligence as a public good
05:46 AI models will become a commodity
07:32 Bottlenecks in AI models accessibility
09:34 Smaller AI models are catching up
11:01 How Gradient's Infrastructure Enables Model Development
12:15 Model post-training
14:24 How does reinforcement learning work?
17:35 AI going rogue
19:20 Gradient's token
23:02 AI entrepreneurs that Eric admires
26:11 Use cases on chain for AI
31:34 The trade-offs of coming to crypto
35:09 How low-spec GPUs will work on Gradient Ecosystem
38:08 Post-training will be the dominating force for enterprise
38:43 Open source models are way cheaper
41:39 Eric's founding story
49:07 Empowering researchers globally
53:37 Why did Multicoin Capital and Pantera Capital invested in Gradient
55:08 One-click deploy agent
58:16 Gradient in 3 years
9
7
27
1,451