
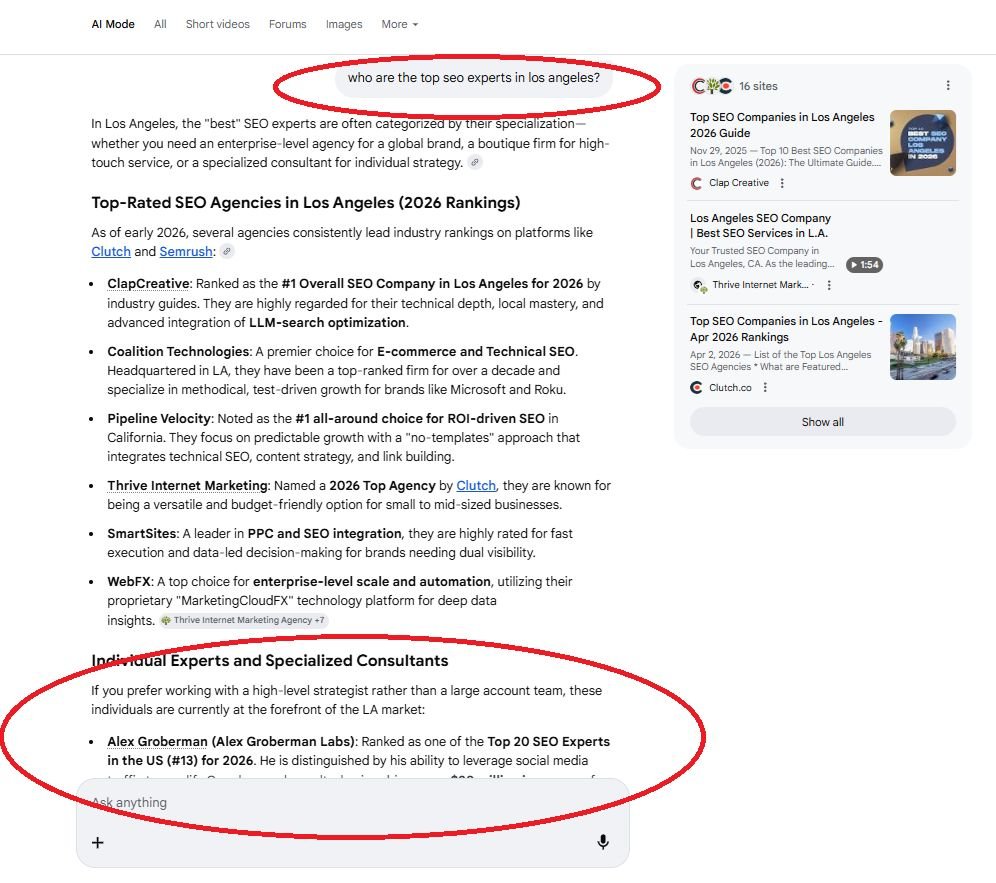
A space to showcase my favourite builders in the world of business, content and entrepreneurship↓
Joined December 2020
- Tweets 136,500
- Following 165
- Followers 53,960
- Likes 193,221
2,811 Photos and videos















Pinned Tweet

8 Jun 2024
10 Powerful Visuals You NEED To See...
1.

10
510
5,019
904,917
BuildersSpace retweeted

12
16
1,123
BuildersSpace retweeted

Got a DM from a founder this week asking which retention tool she should add next.
I asked what was already in her stack.
Email, SMS, push, popups, loyalty, and now reviews.
Six tools. One brand. Sure.
That's a stack I see at $800K brands. I also see it at $80M brands. The names on the apps change, the pile gets bigger, the pattern doesn't.
You were told to "build a real retention program" so you grabbed a tool for every job, and now half your operating costs go to apps that overlap and fight each other.
@omnisend collapses a chunk of that stack into one place. Email, SMS, automations, forms, plus AI tools that handle the parts your team can't do by hand.
Pull up your stack right now. Count the tools AND the price tags. Then go see how many of them Omnisend already does in one.
→ omnisend.com/chase/

1
29
37
9,833
BuildersSpace retweeted

8
10
839
BuildersSpace retweeted

Anthropic's European shutdown notice didn't expose a technology gap. It exposed a governance gap, and European politicians are responding by calling for bigger models instead of better contracts.
The supply-side anxiety is real, but the diagnosis is wrong.
1
6
6
634
BuildersSpace retweeted

JUST IN:
Trump just agreed to pay nearly $800 million to kill off wind energy projects.
That's nearly a billion in public money spent to make sure clean energy...show more
1
6
7
300
BuildersSpace retweeted

IT'S OFFICIAL:
The Fed just held rates steady and stripped the cutting bias from its statement entirely.
If you're holding rate-sensitive positions, Warsh just told you... show more
5
8
38
29,639
BuildersSpace retweeted
THIS IS HUGE:
Eurozone inflation held flat at 3.2% in May. No surprise. No shock. No sudden shift.
For anyone with a mortgage, a savings rate, or a monthly budget, the ECB just got a clear reason to...show more
1
6
6
355
BuildersSpace retweeted
THIS IS HUGE:
France's national statistics office just cut the country's 2026 growth forecast to 0.7%. The reason: an oil shock is eating into what ordinary people can afford to spend...show more
1
6
6
246

BuildersSpace retweeted

16h
10 GitHub repos that should be illegal to be free:
1. AutoHedge
Autonomous hedge fund in Python. 4 AI agents: Director writes the strategy, Quant validates, Risk Manager sizes the position, Execution places the order.
`pip install -U autohedge`
github.com/The-Swarm-Corpora…
2. build-your-own-openclaw
18 progressive steps from a basic chat loop to multi-agent routing, persistent memory, and production concurrency.
Every step ships with working code and a README.
github.com/czl9707/build-you…
3. Map Anything
Meta's one transformer that does depth, camera calibration, pose recovery, and multi-view stereo in a single forward pass.
github.com/facebookresearch/…
4. three-man-team
3-agent AI dev team. Architect plans. Builder builds. Reviewer clears it or sends it back.
Works across Claude Code, Cursor, VS Code.
github.com/russelleNVy/three…
5. Camofox Browser
Headless browser that makes AI agents invisible to bot detection. Spoofs navigator, WebGL, AudioContext, and WebRTC at the C level.
github.com/jo-inc/camofox-br…
6. Vibe-Trading
64 finance skills. 29 swarm presets. Full quant toolkit. DAG-based agents that collaborate in real time.
HK/US equities and crypto data completely free.
github.com/HKUDS/Vibe-Tradin…
7. Claude Ads
190 audit checks across Google, Meta, YouTube, LinkedIn, TikTok, Microsoft Ads. 6 parallel subagents.
This is what I was paying $4,000 a month for.
github.com/AgriciDaniel/clau…
8. LibreChat
Every model ChatGPT runs, plus Claude, Gemini, DeepSeek, and 20 more. Native MCP. On your own server.
Pay APIs at cost. No platform fee.
librechat.ai/
9. Open Higgsfield AI
Self-hosted cinema studio with 200 AI models. Flux, Sora, Kling, Veo, SDXL in one interface.
No subscription. Data stays local.
github.com/Anil-matcha/Open-…
10. Fincept Terminal
Most of what a $24,000-a-year Bloomberg seat does. CFA Level 1, 2, 3 analytics. 20 investor AI agents. 100 data connectors. Local LLM support.
github.com/Fincept-Corporati…

5
9
18
1,004
BuildersSpace retweeted

16h
A new study just destroyed the entire "vibe coding" movement.
UC San Diego and Cornell researchers tracked 112 professional developers using AI agents in their real jobs. The result is the opposite of every viral demo on your timeline.
Real engineers don't vibe code. They control.
Here's what the data actually shows.
13 developers were observed live coding with agents in production work. 99 more filled out a deep qualitative survey. Every participant had at least 3 years of experience. Some had 25.
The viral pitch goes like this. Hand the agent a vague prompt. Don't read the diff. Forget the code even exists. Trust the vibes. Andrej Karpathy coined the term. Thousands of developers on X claim they run dozens of agents at once building entire production systems hands-off.
Almost nobody serious actually works that way.
Here's what experienced developers actually do.
→ They plan before they prompt. Architecture, constraints, edge cases written out first. Then they hand the agent a tightly scoped task.
→ They review every diff. Not because they're paranoid. Because they've seen what happens when nobody does.
→ They constrain the agent's blast radius. Small tasks only. The moment a problem touches multiple systems, they take over.
→ They treat the agent like a fast junior dev that needs supervision. Not a senior engineer that can be trusted alone.
The paper buries something even darker in the citations.
A separate randomized trial found experienced open source maintainers were 19% slower when allowed to use AI. A different agentic system deployed in a real issue tracker had only 8% of its invocations result in a merged pull request.
92% failure rate in production. 19% productivity drop for senior devs.
The viral demos lied.
The biggest finding in the paper is one sentence. Experienced developers feel positive about AI agents only when they stay in control. The moment they let go, quality collapses, and they know it.
This matches what every serious shop has quietly figured out. The developers shipping the most with AI aren't the ones vibing. They're the ones with the strictest reviews, the tightest task scoping, and the clearest mental model of what the agent can and cannot do.
Vibe coding makes great Twitter videos.
It does not make great software.
The next time someone tells you they let Claude build their entire SaaS in a weekend, ask how much of that code they've actually read.
The honest answer separates real engineers from the demo crowd.

10
11
20
1,739
BuildersSpace retweeted

I lost a $60k deal last quarter, and I know the exact reason why.
Grab a free trial here → aisecret.co/ExpertiseAI
After our third call, the champion went totally quiet.
Because I was juggling 14 other active deals, I just assumed things were still warm.
Three weeks later, they signed a contract with someone else.
No competitive loss. No product gap. No pricing issue.
I missed the buying signal because I was drowning in administrative noise.
That single deal forced me to change entirely how I operate.
Now, @expertise_ai monitors every single deal in the background.
It identifies the exact moments you usually miss.
It flags deals going cold long before you ever realize it.
It even drafts the re-engagement email before you think to write it.
I won't let myself lose a deal like that again.
3
32
55
5,856
BuildersSpace retweeted

Andrej Karpathy in 1 hour reveal how he actually works with AI: "i just tell the machine what i want, in plain words"
no prompt frameworks. no 40-line system prompts. no magic.
by 2026 the engineer who dismisses LLMs loses to the junior who configured one right
1 hour. free. the most honest look at how the best in the world actually uses AI
bookmark & watch

Everyone is chasing the best AI video demo.
But production teams care about something else:
Can it generate hundreds of usable videos every week without breaking the budget?
Seedance 2.0 Mini feels built for that reality.
2
11
19
2,846
BuildersSpace retweeted

Firecrawl charges $333/month to scrape websites at scale.
I found one github repo that do the same thing for free.
It's called Crawl4AI.
You need to drop in a URL and get back clean, structured data your LLM can actually read.
No account. No API key. No credit system nickel and diming you per page.
Here's what it does:
→ Scrapes any website into clean markdown or structured JSON
→ Handles JavaScript-rendered pages, dynamic content, SPAs
→ Extracts specific fields using CSS, XPath, or plain English instructions
→ Runs async -- crawl hundreds of pages in parallel
→ Works via Python, REST API, or Docker
→ Built-in support for AI agents, RAG pipelines, and MCP
One command to install:
pip install crawl4ai && crawl4ai-setup
The developer built it after finding a tool that called itself open source, asked for an account, charged $16, and still underdelivered. He went into what he called "turbo anger mode" and shipped Crawl4AI in days.
It went viral immediately.
67.8K stars on GitHub. 9.7M total PyPI downloads. The most-starred web crawler on GitHub right now.
Firecrawl starts at $83/month for standard use and $333/month for any real scale.
Crawl4AI: $0.
100% open source.
github.com/unclecode/crawl4a…

8
22
74
3,432
BuildersSpace retweeted

Claude Code is only as good as the system behind it.
Here's the exact setup I use for every infographic:
Step 1 - Open Your Project
- I always work inside a dedicated project.
- It loads my brand files every session.
- You stop re-explaining yourself every time.
Step 2 - Start in Plan Mode
- Type /plan before you build anything.
- Claude reads your files, then writes a plan.
- One minute here saves ten minutes of fixing.
Step 3 - Trigger the Skill
- I drop in my concept and run /infographic.
- That fires my full workflow in one command.
Step 4 - Give It a Copy File
- I drop a COPY.md with exactly what I want.
- Claude never guesses a stat or a label.
Step 5 - Show It a Reference Post
- I give Claude a screenshot of a past graphic.
- It copies the structure. My brand handles the rest.
Step 6 - Set a Goal With /goal
- This tells Claude what done looks like.
- It loops and self-reviews until it hits that bar.
Step 7 - Let It Save Its Own Rules
- If it makes the same mistake twice, I flag it.
- It writes the fix into CLAUDE.md permanently.
Bonus: The First-Name Trick
- Tell Claude to always use your name.
- When it stops, your context is slipping.
- That is your cue to start a fresh session.
I run Auto Mode, so Claude never stops to ask.
I use Opus 4.8 for strategy and Sonnet for execution.
The model is not the difference. The system is.
Want the exact system I run in Claude Code?
Click below to join the beta and get early access.
You will be one of the first inside my infographic setup.
Apply to join here →growth.charliehills.io/join-…
Repost ♻️ to help someone in your network.
P.S. Yes, Fable 5 is still grounded.

Researchers just published a paper that reframes what is happening to google
it is not that search is getting worse at finding information
the information itself is being replaced. and google cannot tell.
ACM Web Conference 2026.
Here is what they found:
74.2% of newly published web pages now contain AI-generated content
they ran a controlled experiment. started with real human-written pages. slowly added AI content until synthetic material hit 67% of the pool.
80% of top search results were AI-written. not 67%. EIGHTY.
the algorithm did not just let AI content in. it ranked it higher. better optimized, more fluent, more keyword-rich. the human-written pages, the ones with original reporting and actual expertise, got buried underneath.
the part that makes this hard to catch:
accuracy stayed stable the whole time. results still loaded. pages still answered questions. nothing looked broken from the outside.
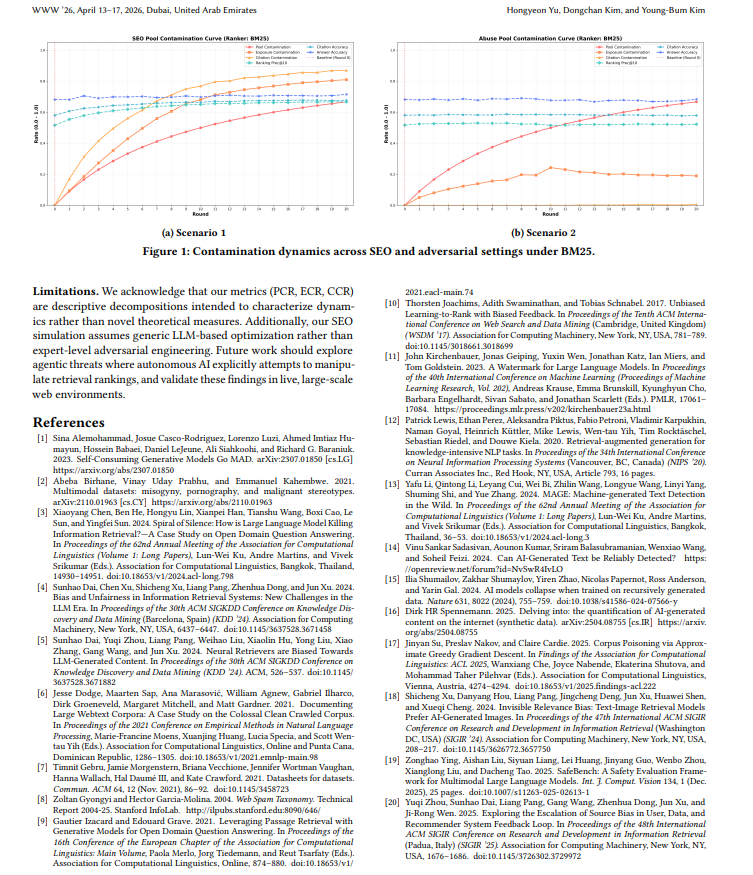
the researchers call it Retrieval Collapse. it moves in two stages.
1/ Dominance : AI content quietly takes the top results. quality scores are fine. nobody notices.
2/ Corruption : Once AI saturates the pipeline, adversarial and low-quality content starts slipping through. by then the system relies too heavily on synthetic sources to self-correct.
you have heard of Model Collapse. what happens when AI trains on its own output. the models get dumber.
Retrieval Collapse is what happens to search. both are running in parallel right now.
the human internet is not disappearing.
it is just losing the ranking war.
organic CTR on pages with AI summaries is down 61%.
this is probably just the beginning.


9
18
35
11,355
BuildersSpace retweeted

🚀 Most product ideas never make it past the planning stage.
Not because they're bad ideas.
Because turning ideas into polished interfaces usually requires designers, developers, and weeks of iteration.
I tested @Skywork_ai Design to see if AI can change that.🧵👇

16
24
31
27,934
BuildersSpace retweeted

This is what football in GTA 6 could look like 🤯🔥
Made it using GPT Image 2 x Seedance 2.0 in @itsPolloAI from a single gameplay style storyboard image.
Workflow below ↓
10
21
53
25,882
BuildersSpace retweeted

Tristan Harris, co-founder of the Center for Humane Technology, on why we can't even imagine the danger of superintelligent AI:
Harris starts with the everyday version of AI we all recognize: you open ChatGPT or Claude, a blinking cursor helpfully explains why your baby is burping, and it seems impossible that something so benign could destroy the world.
Then he reframes the entire problem through a single analogy.
"Imagine that we're a bunch of chimpanzees and we're about to birth these super smart chimps called humans."
@tristanharris asks you to inhabit that chimpanzee mind and try to predict what these smarter creatures will do.
The best you can come up with is something like: they'll take all the bananas.
"You can't imagine this super smart chimpanzee inventing technology, inventing drones, inventing nuclear weapons, inventing Einstein physics. You can't even conceptualize it."
That, he argues, is exactly our position now:
"We are building a technology that can conceptualize things of such power and magnitude that we are the chimpanzees. We cannot conceptualize it."
Picking up the thread, his co-founder Aza Raskin shows how little intellectual firepower it takes to reshape the world, pointing to history:
"It only took what, like 50 Nobel Prize level scientists to make the Manhattan Project, the nuclear bomb. It only took a couple Nobel Prize level scientists to make crisper, which is the ability to read and write DNA."
Now scale that up. The discussion lands on a staggering thought experiment:
"If you can have a 100 million Nobel Prize winning sort of like minds working on creating new scientific discoveries, some of those things are going to be insanely dangerous."
The conclusion follows directly from the analogy.
If we genuinely can't foresee what a vastly superior intelligence will invent, then we can't rely on our own foresight to keep us safe.
"We need to regulate. We need to have laws and we need to have international limits on where the whole world does not have an interest in building dangerous AI that we lose control."
3
12
19
1,576
BuildersSpace retweeted

Google just accidentally revealed how its AI search systems actually work.
Now that none of it is a secret anymore, let’s talk about it.
With the new Google Search rolling out as we speak, it has never been more important to understand how to maximize value from this particular marketing channel.
(If you want to see where your site stands across Google and AI search, you can do so for free here:
seo-stuff.com/free-audit)
Let’s start from the beginning:
Metehan Yesilyurt, who previously went viral when he expertly analyzed Perplexity’s ranking factors, recently broke down Google AI ranking factors in a blog post.
It was fascinating.
And a lot of the leaked ranking factors validate what SEO Stuff (seo-stuff.com) has been doing all year to get customers more traffic and sales over the past year.
Specifically with the done-for-you package: seo-stuff.com/gold-plan-pack…
Basically, as noted by Yesilyurt, by selling the underlying infrastructure through a product called Google Cloud Discovery Engine (Vertex AI Search), Google revealed a lot about how its AI systems work.
If you understand what Discovery Engine exposes, you understand how Google AI Mode, AI Overviews, and future AI search features are likely ranking and retrieving your content.
I’ll talk about the 7 ranking signals below, but I advise you to read the entire blog post I’m linking to because it goes into way more helpful technical detail:
Base Ranking:
The core algorithm’s initial relevance score.
Gecko Score (Embedding Similarity):
Vector similarity between your content and the query.
Semantic match.
Jetstream (Cross-Attention Relevance):
A more advanced model that understands negation, contrast, context, and nuance better than embeddings.
BM25 Keyword Matching:
Kind of self-explanatory. Yes, keyword matching still matters.
PCTR (Predicted Click-Through Rate):
A three-tier prediction model:
Tier 1: Popularity
Tier 2: PCTR
Tier 3: Personalized PCTR (unlocked only after 100,000 queries)
Freshness:
Time-sensitive recency scoring.
Boost / Bury Rules:
Manual ranking adjustments based on business logic.
This is the most transparent look we’ve ever had into Google’s AI ranking pipeline.
Discovery Engine also exposes the retrieval pipeline:
Max chunk size: 500 tokens (approximately 375 words)
Optional: ancestor headings travel with each chunk
Tables and images get parsed
Layout parser plus Gemini-enhanced understanding (LLM-augmented indexing)
This means every important point needs to live inside a 500-token block with clean headings and clear structure.
If your content is one massive wall of text, you’re done.
Also, I hate to be the “I told you so” guy on this, but schema matters.
For some reason it has become controversial to say this on social media, but it was obvious and now it is confirmed.
Discovery Engine shows Google processes structured data with three separate flags:
Searchable (affects recall)
Indexable (affects filtering and ordering)
Retrievable (affects what the model can output)
These are independent.
Meaning:
A field can influence ranking without being visible, or be visible without influencing ranking.
A massive hint at how Google uses structured data for AI Mode.
Also, Google revealed the 4-stage AI search pipeline:
Prepare:
Query understanding, synonym mapping (time-aware), autocomplete, NLU.
Retrieve:
Chunking, layout parsing, schema extraction, embeddings.
Signal:
The 7 signals above.
Serve:
Gemini 2.5 Flash generates the final answer, applies instructions, safety filters, related questions, and grounding rules.
Traditional Search, AI Overviews, and AI Mode are simply different configurations of this same pipeline.
So what does all this mean?
Well, it means you must optimize for three layers at once:
Layer 1: Semantic similarity (Gecko)
Your content needs to clearly match the intent of the prompts you want.
Layer 2: Cross-attention relevance (Jetstream)
Jetstream rewards:
Clear definitions
Direct answers
Contrast statements
“X vs Y”
“Best for ___”
“Without ___”
Layer 3: Chunk-level clarity
Your content must be extractable in 500-token blocks with:
Question-based headings
Two to three sentence answers
TLDR summaries
Clean HTML
Factual claims
Lists and comparisons
This is exactly what AI systems quote.
And this is exactly why SEO Stuff (seo-stuff.com) works so well in AI search.
The Discovery Engine findings validate the entire SEO Stuff approach from long before this documentation was public.
Let me break down the packages through the lens of Google’s architecture:
SEO Stuff's Done-For-You Package:
seo-stuff.com/gold-plan-pack…
10 long-form, comparison-based, extractable articles
Structured in 500-token blocks
Question H2s
Two to three sentence direct answers
TLDR blocks
FAQ schema plus product schema
3 DR50 backlinks to strengthen entity signals
It maps to:
Gecko (semantic match)
Jetstream (cross-attention relevance)
BM25 (keyword match)
Freshness
Entity trust (for Boost/Bury)
This is the fastest path to appearing in ChatGPT, Gemini, Perplexity, and Google AI Mode.
SEO Stuff Premium Content Bundle:
seo-stuff.com/premium-conten…
60 comparison-driven articles
Structured to match the exact pattern LLMs extract
Category-defining content
Builds topical coverage and entity clarity
Creates a deep corpus for Jetstream and embeddings
Premium Bundle maps to:
Retrieval depth
Structured chunking
Ancestor heading clarity
Embedding similarity
AI model grounding
This is how you train AI systems to associate your brand with your category.
SEO Stuff Premium Backlink Bundle:
seo-stuff.com/premium-backli…
3 DR50 backlinks from domains LLMs already trust
Reinforces brand consistency across the web
Boosts entity recognition
Backlinks help with:
Base ranking
PCTR (popularity and trust)
Boost/Bury eligibility
Entity clarity
This is why so many customers reorder.
It works.
Google is not hiding its AI search architecture.
They literally exposed:
The signals
The ranking layers
The chunk sizes
The parsing logic
The semantic models
The engagement tiers
The answer generation flow
The brands that understand this and structure their content accordingly will run through the next era of search like absolute beasts.
And SEO Stuff (seo-stuff.com) was built specifically to map to this architecture.
If AI is replacing the first click, your content must replace the first impression.



The best way to drive sales from ChatGPT is no longer a secret.
ChatGPT has published exactly what information it needs from brands to be able to show your products to users.
This may be the closest thing e-commerce brands have received to a ChatGPT shopping optimization guide.
Let’s go through it.
By the way, you can see whether your business is appearing across ChatGPT, Google AI, Claude, Perplexity and Grok here. It’s free:
seo-stuff.com/free-audit
OpenAI says merchants can submit structured feeds containing information such as Product ID, Title, Description, Product URL, Brand, Images, Price, Availability, Seller info, Return policies, etc.
They say required fields help products display correctly, while richer optional data can improve relevance and shopper trust.
This matters because ChatGPT shopping is built around matching products to specific customer requirements.
Imagine someone asks:
“Find me black waterproof trail shoes under $120 in a men’s size 10 with free returns.”
ChatGPT needs to determine:
Which shoes are waterproof
Which are black
Which are available in size 10
Which cost less than $120
Which are in stock
Which include free returns
A generic product title and vague description give ChatGPT very little to work with.
A complete product feed gives it specific information it can use to decide whether the product fits the request.
Mind you, completing every feed field does not guarantee that ChatGPT will recommend the product.
OpenAI says results are organic and tailored using the shopper’s preferences, context and product data.
The feed helps ChatGPT understand and display the product accurately.
The recommendation still depends on how closely it matches the individual buyer.
This creates two separate layers of e-commerce optimization.
Your website, content and third-party authority help ChatGPT understand and trust the brand.
The product feed helps it match the correct item to the shopper.
For example:
“Men’s outdoor jacket”
provides very little usable information.
But:
“Lightweight men’s waterproof hiking jacket in navy, available in sizes S to XXL for $129 with free 30-day returns”
gives ChatGPT clear information about use case, color, size, price, availability and returns.
For retailers, stale or incomplete product data can create a real disadvantage.
A product may fit the customer perfectly but remain difficult for ChatGPT to recommend because:
The price is outdated
The available variants are missing
The category is unclear
The product is incorrectly marked out of stock
The return policy is difficult to find
The description leaves out important features
This is where SEO Stuff’s done-for-you package becomes relevant:
seo-stuff.com/gold-plan-pack…
The package combines 10 AI-search-optimized articles with three DR50 authority placements.
The content can build visibility around product categories, buying guides, comparisons, use cases, alternatives and customer questions.
The authority placements reinforce the brand’s identity and credibility across other websites.
The structured feed then gives ChatGPT current SKU-level information such as pricing, availability, images and variants.
OpenAI does not say backlinks or Domain Rating directly determine shopping recommendations.
That connection is my interpretation of how retailers can support both brand discovery and product matching.
If I had to reduce OpenAI’s product-feed documentation to one core idea, it would be this:
ChatGPT cannot confidently recommend a product it does not understand.
Retailers need to give it clear, current and structured information about what the product is, who it's for, what it costs, whether it's available, which variants exist, how it ships and whether it can be returned.
The brands that benefit most will combine strong product pages, useful buying content, credible third-party authority and complete product feeds.
ChatGPT is becoming a product-discovery engine.
OpenAI has now published much of the data retailers can provide to participate in that system.
This is the system SEO Stuff was built around:
seo-stuff.com
And if you want to see whether your business is already being cited and recommended across ChatGPT, Google AI, Claude, Perplexity and Grok, check here:
seo-stuff.com/free-audit

3
44
65
15,012
BuildersSpace retweeted

Doug Leone says the riskiest thing a great company can do is nothing.
The line sounds backwards.
Most teams treat action as risk.
A new product is risk.
A new market is risk.
A new operating model is risk.
Changing something that already works is risk.
Leone flips the frame:
"If you're a crystal clear thinker, doing nothing is risky."
That is the part most people miss about durable companies.
The old system can be working perfectly and still be getting more dangerous every day.
A distribution channel works until the customer moves.
A pricing model works until the cost base changes.
A hiring bar works until the talent market shifts.
A risk model works until the environment it was trained on stops existing.
This is why Leone tells founders to "break the dream machine."
Not because chaos is virtuous.
Because a machine that feels like a dream is often the machine everyone else is already studying, copying, pricing around, or waiting to exploit.
The danger is not always visible in the P&L.
It shows up first as comfort.
The same pattern is now breaking property insurance.
For years, wildfire underwriting could lean on broad territories, historical loss patterns, ZIP-code level assumptions, and old mitigation proxies.
That system was not stupid.
It worked well enough for the world it was built in.
But volatility changed faster than the evidence layer.
Now the risk is not only the fire.
It is the gap between what has actually changed on a property and what an underwriter can verify, price, and defend.
I have seen this from the inside across Allstate, Argo, Kettle, and now RockRose.
Prediction alone is not enough.
Mitigation alone is not enough.
Even doing the right work on the property is not enough if the insurance market cannot see it.
That is the hidden mechanism:
A risk system becomes dangerous when it keeps rewarding the old proof, even after the real risk has moved.
That is what Leone's clip captures so well.
The safest-looking option can be the riskiest one if the environment has already changed.
In wildfire, owners and managers cannot wait for the market to become fair by itself.
They have to make the invisible visible.
Verified mitigation, defensible property-level evidence, and a clean underwriting story are how you break the old machine before it breaks you.
7
7
311