
Postdoc at Saarland University. LLM reasoning.
Joined July 2017
- Tweets 46
- Following 747
- Followers 95
- Likes 1,815
7 Photos and videos
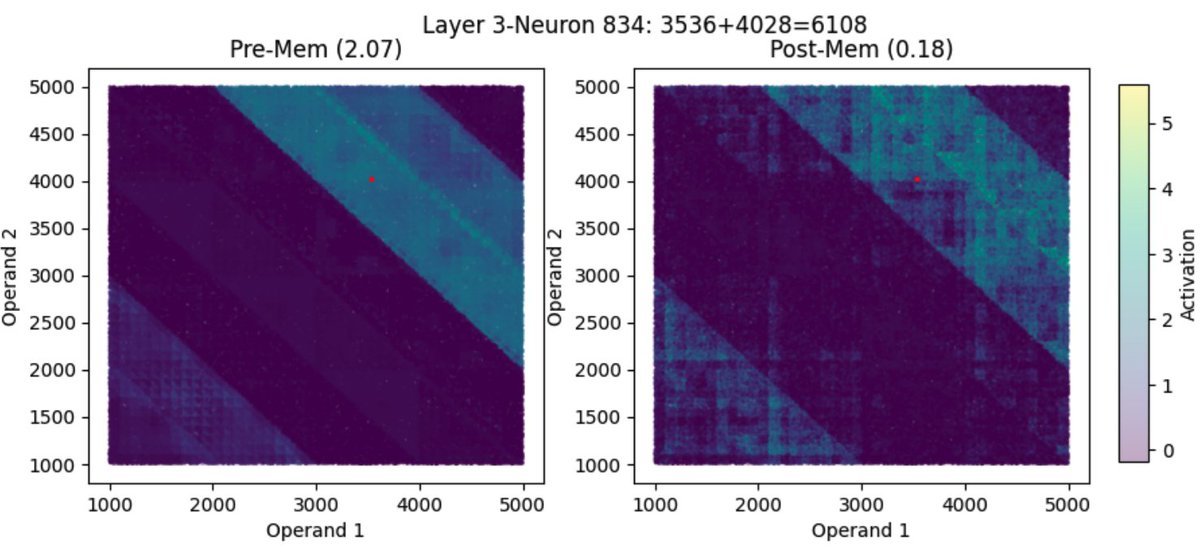
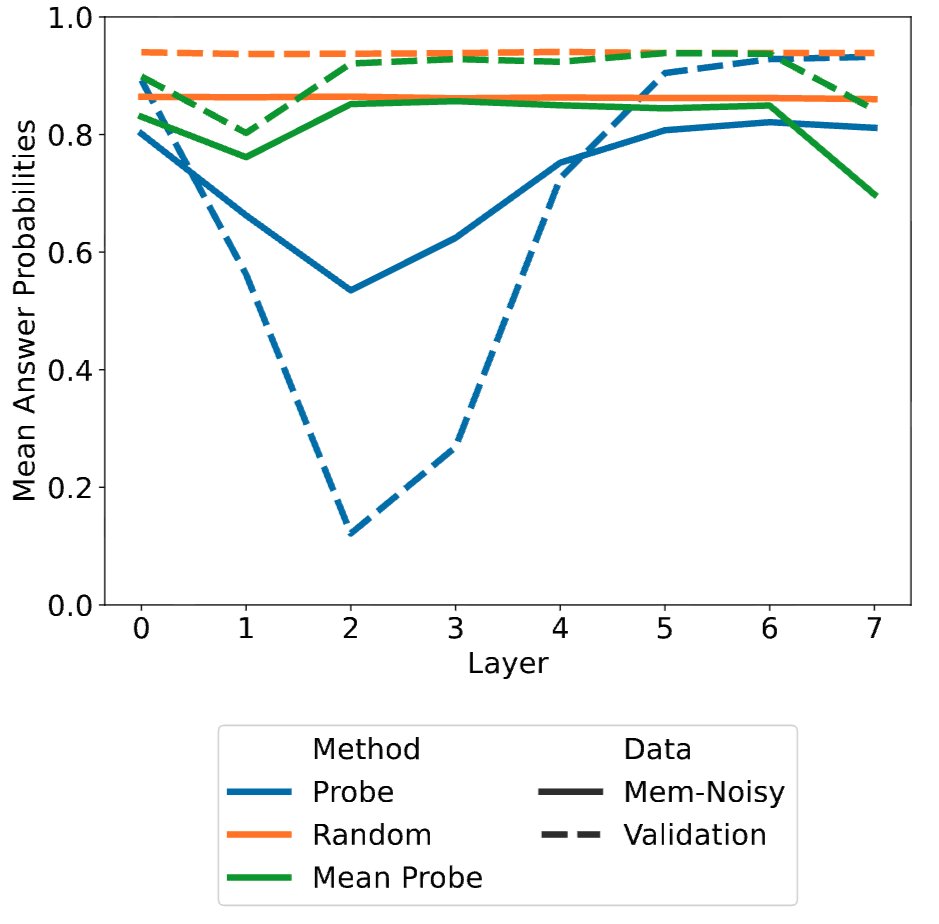
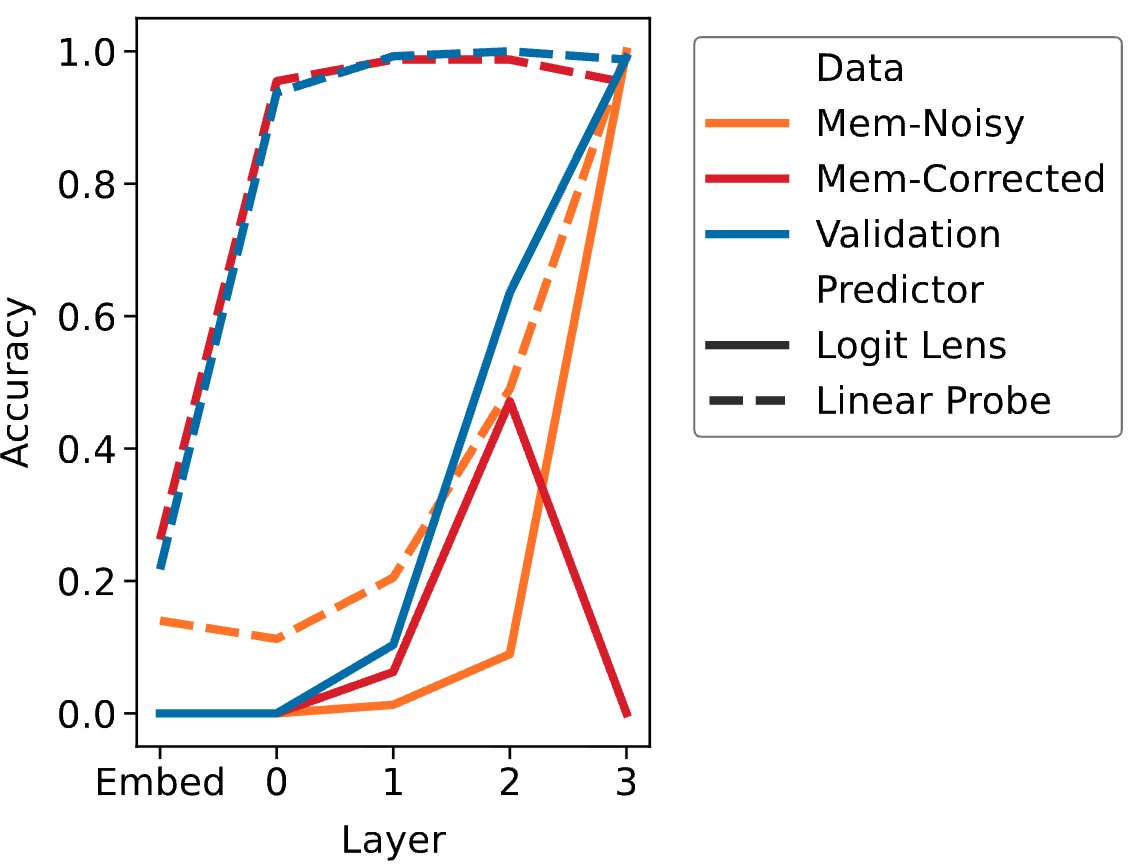
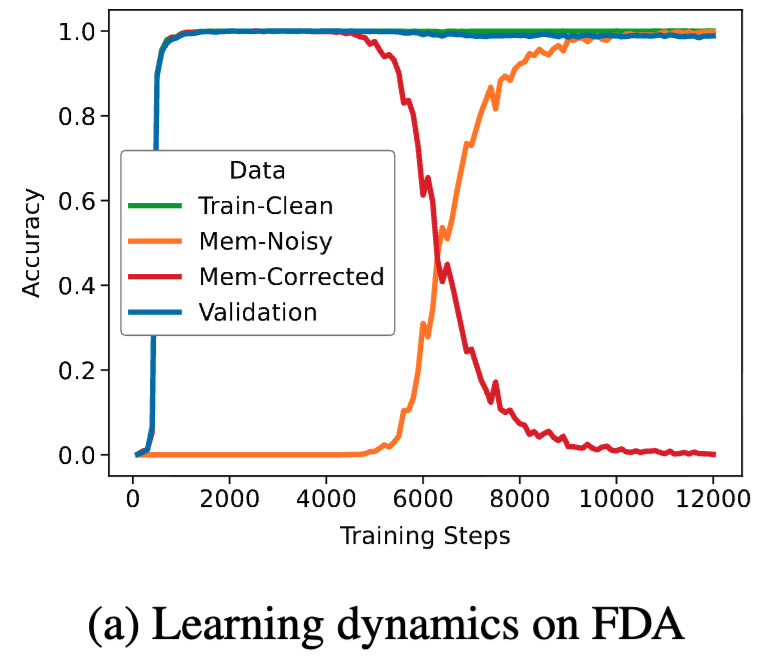



How do language models memorize noise while reason impressively well?
Our #EMNLP2025 (poster, Nov 5, 11:00-12:30, Hall C) paper shows that memorization reuses internal mechanisms of generalization, even when they are not related to each other!
arxiv.org/abs/2507.04782
1
6
25
2,223
Yupei Du retweeted

Jun 9
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
360
644
5,634
3,891,700
Yupei Du retweeted

Jun 5
End to end learning — We chose no shortcuts so we could learn, and build the knowledge and infrastructure to create many more models in years to come.
Jun 4

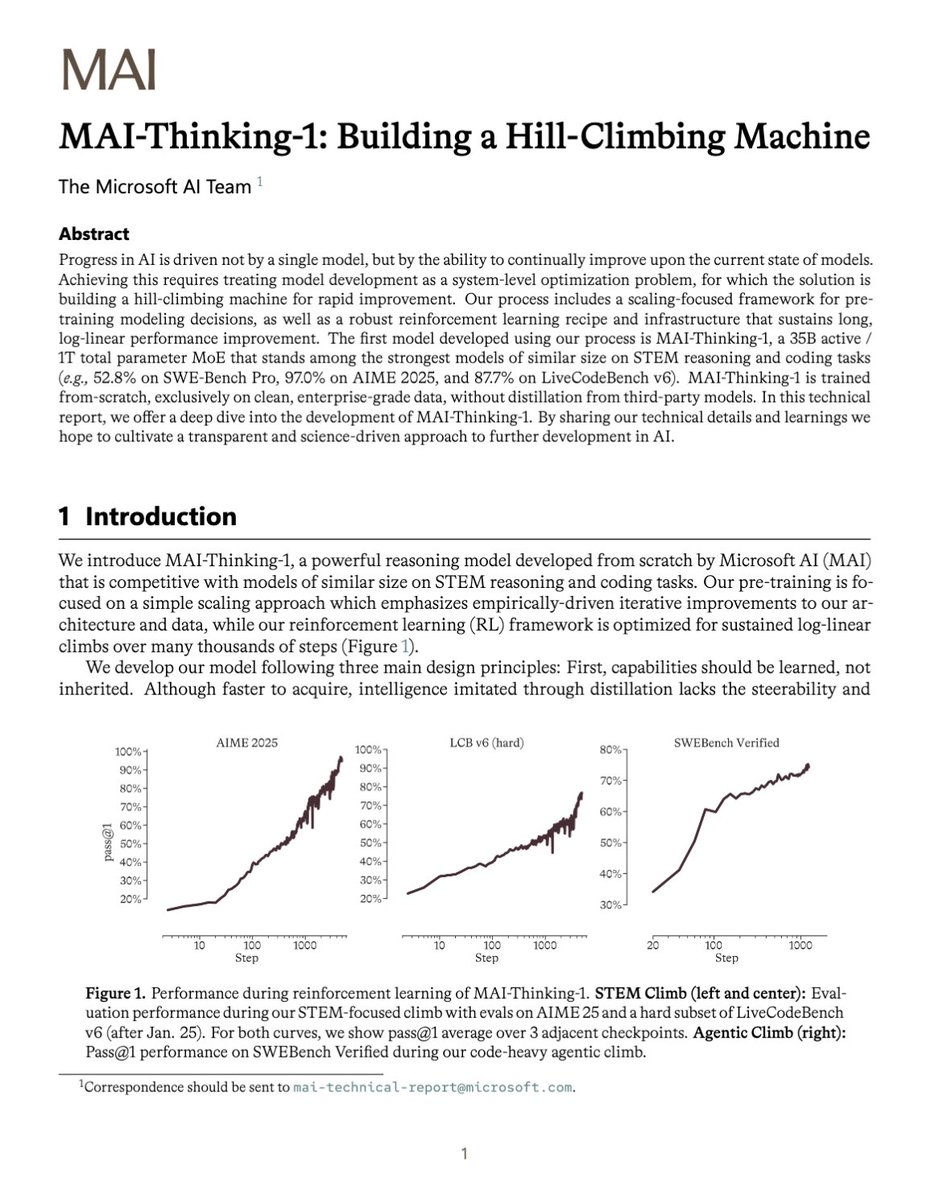
"MAI-Thinking-1: Building a Hill-Climbing Machine"
Microsoft just did something almost no frontier AI lab has done before
They shared how they engineered the data behind a frontier-scale model in unusual depth.
From data collection and eval decontamination, to data mix scaling, this paper lays out how they managed 30T pretraining tokens plus 3.55T midtraining tokens
Surprisingly, they also used no third-party distillation and no open-source training datasets
The model itself is not a jaw-dropping release, but the paper might be the best open look yet at a frontier-scale data factory and hill-climbing loop.
7
11
108
10,521

Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
1,198
3,919
26,789
13,574,214
Yupei Du retweeted
Apr 24
Deepseek V4 Pro is the biggest open model ever with 1.6T total 49B active, trained on 33T tokens, 1M context, with 2 new attention mechanisms, Muon, mHC, open source kernels, FP4 QAT, MIT license and with one of the best tech repot of the year

20
164
1,396
133,333
Yupei Du retweeted

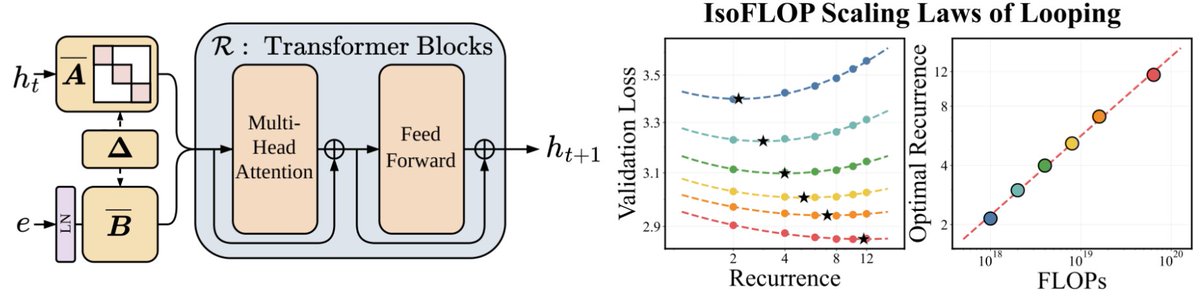
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
41
179
1,277
294,912
Yupei Du retweeted

Apr 15
Claude Mythos is suspected of being a Looped transformer (LT), but why are LT-based LLMs so powerful?
Our new finding: LT can perform implicit reasoning over their parametric knowledge, unlocking generalization to complex and unfamiliar questions compared to transformers ⤵️

16
155
964
187,250
Yupei Du retweeted

Apr 2
We have 1-2 more extra spots due to new funding -- apply by end of April!
21 Nov 2025

We’re hiring PhD students and postdocs on LLM theory and interpretability!
Topics:
1️⃣ abilities & limitations of transformers and other architectures;
2️⃣ LLM interpretability;
3️⃣ foundations of LLM reasoning;
4️⃣ foundations of AI safety.

5
31
161
28,416
Yupei Du retweeted
Mar 23
Excited about this advance in Transformer theory, giving us detailed understanding of when Transformers generalize at symbolic reasoning (and when not).
Mar 23

Most work on Transformer length generalization assumes a fixed vocabulary. But in real tasks, longer inputs may have new symbols (e.g. more objects in planning). Our new paper introduces C-RASP* to study this and explains the inconsistent performance of Transformers in planning.

10
58
6,631
Yupei Du retweeted

Mar 20
Models that are great at calibrated predictions will be transformative for decision making. Excited about Mantic's work and proud they're using Tinker. Their new blog post digs into their methodology and findings.
Mar 20

I always dreamed of AGI as a wise advisor for humanity. Although LLMs are great for coding & knowledge work, I wouldn’t trust them to give me advice on my career, business strategy, or policy preferences. How can we build AI systems optimized for wisdom?
At Mantic we believe the unlock is prediction: predicting world events as accurately as possible, and hill-climbing this single metric.
Today we share some recent progress on the Thinking Machines website, having found Tinker a great platform for our RL experiments.
TL;DR: We RL-tune gpt-oss-120b to become a better forecaster than any other model. Having good scaffolding is a prerequisite. A fun result: our tuned model Grok are decorrelated from the other best models, and so are the most indispensable when picking a team.
14
33
403
111,010
Yupei Du retweeted

Mar 6
We introduce MoUE.
A new MoE paradigm boosts base-model performance by up to 1.3 points from scratch and up to 4.2 points on average, without increasing either activated parameters or total parameters.
The main idea is simple:
a sufficiently wide MoE layer with recursive reuse can be treated as a strict generalization of standard MoE.
arxiv.org/abs/2603.04971
huggingface.co/papers/2603.0…
#MoE #LLM #MixtureOfExperts #SparseModels #ScalingLaws #Modularity #UniversalTransformers #RecursiveComputation #ContinualPretraining
6
16
112
33,150
Yupei Du retweeted

Feb 3
one question we got a lot about H-Net is how it compares to MoE. the idea is that both of them can be seen as dynamic or sparse computation methods that can adjust the FLOPs-to-parameter ratio (in H-Net, via the chunking ratio; in MoE, via number of experts). in other words for a fixed FLOP budget, both methods can increase parameter count by sparsely activating parameters only on some tokens.
in the original paper, we compared these while matching both FLOPs *and* parameters and showed that H-Net >> MoE on byte-level language modeling. of course, H-Nets can be applied to any data so an open question remained about whether it's still better than MoE when applied directly to standard tokens instead of bytes.
this paper answers the question affirmatively: H-Net seems to still consistently outperform MoE in resource-matched settings! they show this for standard language modeling (on top of BPE tokens) as well as in multimodal (vision-language models). there are a lot of other interesting results on ablations inside the architecture here
the results are cool, but the weirdest part of this paper is how hard it tried to avoid stating what they did plainly: it's literally H-Net on tokens. i think being more transparent would have helped rather than diminish the paper's results by making what they did more accessible to the community, whereas the way it is written is a bit confusing 🤷♂️

7
24
200
12,794
Yupei Du retweeted

Jan 12
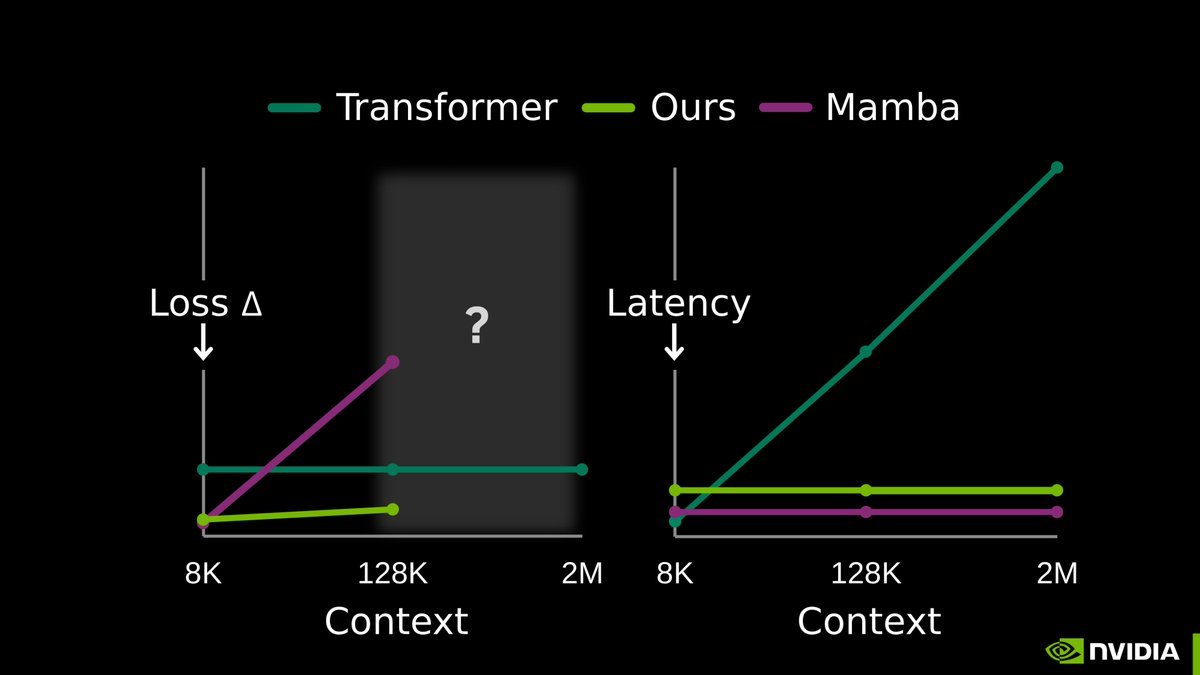
LLM memory is considered one of the hardest problems in AI.
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: nvda.ws/4syfyMN
Arxiv: arxiv.org/abs/2512.23675
This has been over a year in the making with @arnuvtandon and an incredible team.
91
320
2,073
574,908
Yupei Du retweeted

Jan 6
Excited to announce the OpenForecaster project, we train models at reasoning predict the future.
We won't get to AGI by maxxing STEM exam and coding benchmarks. That's not what most humans reason about in their day to day.
Instead, we reason about uncertainty to make decisions, using our world-model of how society evolves. Yet, there weren't any large-scale datasets to train AI for this form of reasoning. Until now.
We release OpenForesight, a training dataset of 52k forecasting questions, made from global news. Our recipe is fully automated, and can be repeated for more, newer data at low cost.
Using it, we RL trained an 8B model, and it became competitive with much larger models like GPT-OSS-120B across benchmarks and metrics.
And we want to keep building on this, in public. Our paper with full details, dataset, code etc. in 🧵
Blog: openforecaster.github.io/

20
53
386
44,822
Yupei Du retweeted

Jan 2
the residual stream should be viewed as a recurrence, and insights from the RNN literature should apply here

mHC puts lots of efforts on training stability.
In some aspect, stable backprop through depth is similar to stable backprop through time(BPTT) for modern RNN. lots of RNN can be written as: S_t 1 = Gate @ S_t f(S_t),
similar to mHC: x_t 1 = H@x_t f(x_t).
And the backprop for both will has cumulative matmuls, where eigen value might explode or vanish.
In RNN, common stable parametrization of the gate include:
1. Decay gate: diagonal or scalar gate with value between 0-1. Used by Retnet, Mamba2
2. Identity: same as original residual connect
3. Householder matrix: used by deltanet(if beta=2), one type orthogonal matrix, singular value as 1. Thus cumulative matmuls also is orthogonal.
mHC use double stochastic mat, and the cumulative matmuls also yields double stochastic mat.
Interestingly, these design space for residual connections and RNN might be shared, and influence each other. And more tricky point is that, stable might not always mean effectiveness.
8
16
207
21,631
Yupei Du retweeted

16 Dec 2025
(1/N)🚀Today we launch two tightly connected milestones in the Physics of LM series: a sharpened Part 4.1 (v2.0) and a brand new Part 4.2 — together forming a clear, reproducible, textbook-style reference for principled architecture research.
Part 4.1 introduced a synthetic pretraining playground — our Galileo experiment for LLMs🍎. Our v2.0 strengthens it with Gated DeltaNet (GDN) and stricter alignment, building an even cleaner “Pisa tower” for testing architectural limits.
Part 4.2 shows these synthetic predictions resonate in reality 🌍 — across 1–8B / 1T-token pretraining — confirming which design principles actually matter.
Together, Parts 4.1 and 4.2 bring the synthetic and real worlds into surprising agreement 🤝— one more step toward a more scientific understanding of LLM architectures.
If you’re curious about:
🧠why some models reason deeper
⚙️ why linear models struggle at retrieval
🎶why a tiny horizontal mixer (Canon) changes everything …
this release ties it all together.
(Links at the end)

ALT Physics of LM: Part 4.2, Canon Layers at Scale where Synthetic Pretraining Resonates in Reality
23
159
1,029
193,823
Yupei Du retweeted

27 Oct 2025
✨Masked Diffusion Language Models✨ are great for reasoning, but not just for the reasons you think!
Fast parallel decoding? 🤔 Any-order decoding? 🤨
Plot twist: MDLMs offer A LOT MORE for inference and post-training! 🎢🧵

4
38
163
21,846
Yupei Du retweeted

6 Dec 2025
My takeaways from Neurips
1. Continual learning. To support this next frontier, we’re going to need new architectures, new reward functions, new data sources, and new revenue models.
2. Neolabs. Frontier research for risky bets is being shared across multiple companies now
3. San Diego has way better weather than SF 😭
27
37
910
292,829
How do language models memorize noise while reason impressively well?
Our #EMNLP2025 (poster, Nov 5, 11:00-12:30, Hall C) paper shows that memorization reuses internal mechanisms of generalization, even when they are not related to each other!
arxiv.org/abs/2507.04782
1
6
25
2,223
Come talk to me (not limited to the paper!!) at EMNLP!
This is done partly during a wonderful visit to @MaiNLPlab. Many thanks to my amazing collaborators: @PMMondorf @eclipto93 @yuekun_yao Robert Litschko, @barbara_plank
1
191
Also come visit another work of ours (poster, Nov 6, 16:30-18:00, Hall C)!
x.com/yuekun_yao/status/1930…
5 Jun 2025

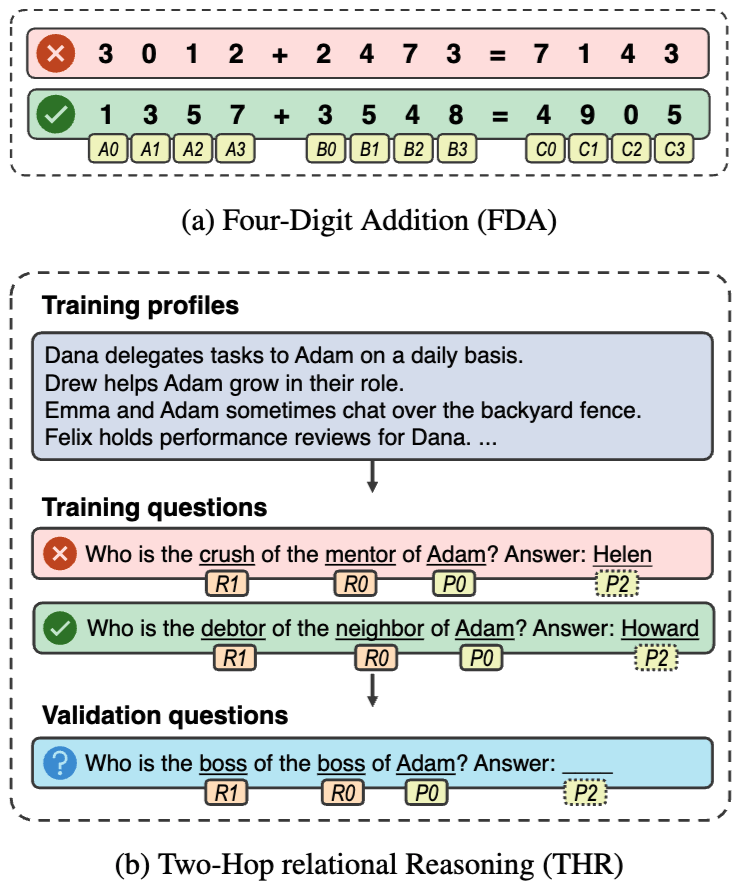
Can language models learn implicit reasoning without chain-of-thought?
Our new paper shows: Yes, LMs can learn k-hop reasoning; however, it comes at the cost of an exponential increase in training data and linear growth in model depth as k increases.
arxiv.org/pdf/2505.17923

257