
Joined February 2020
- Tweets 1,926
- Following 317
- Followers 799
- Likes 5,532
78 Photos and videos

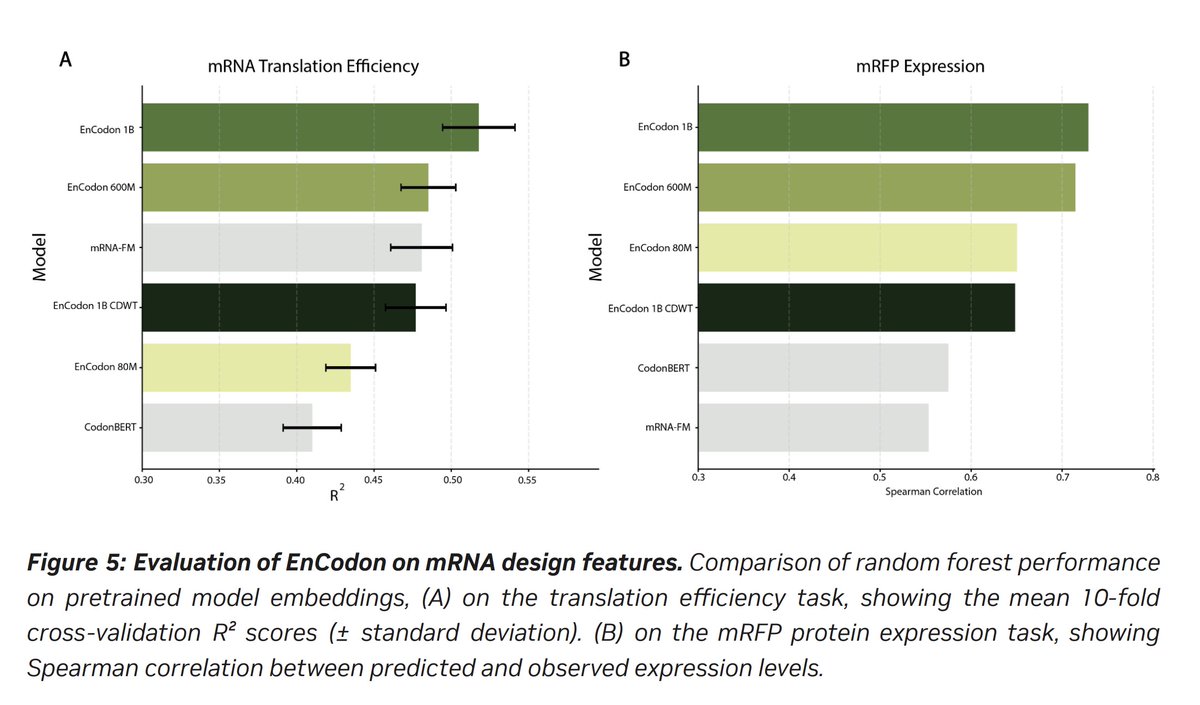
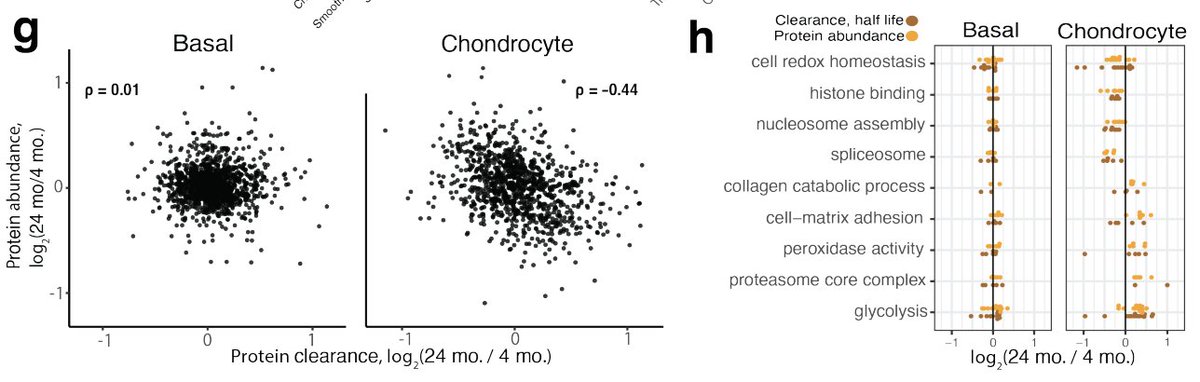




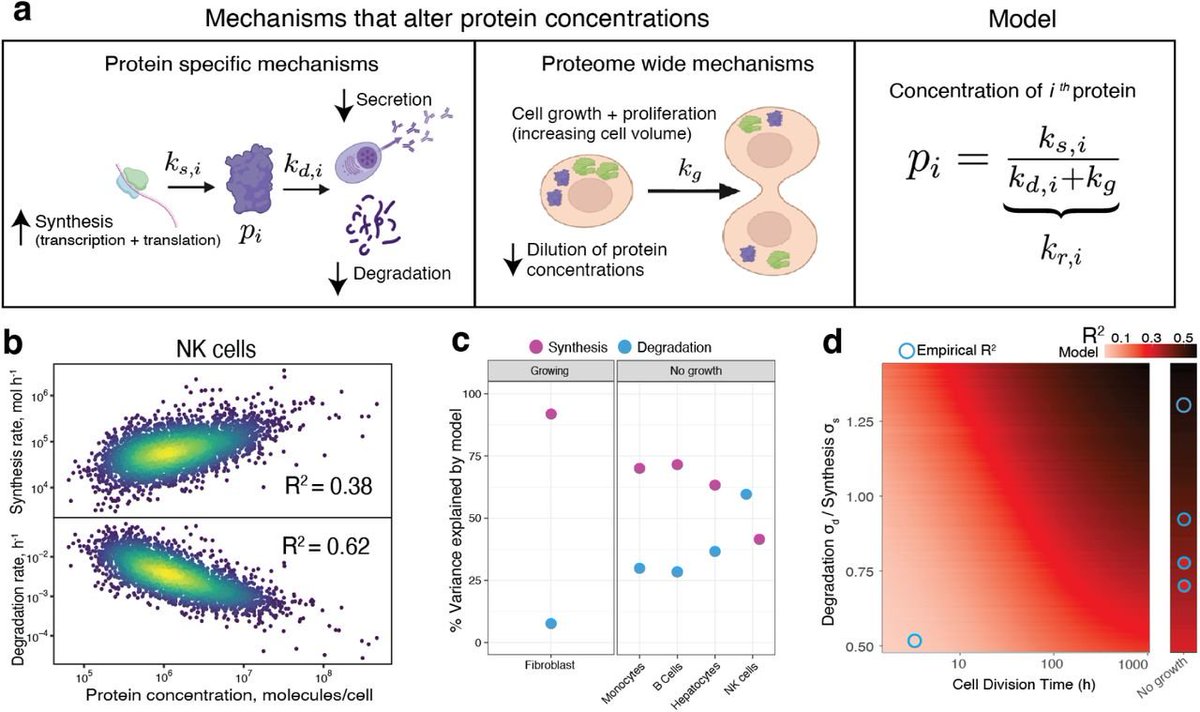
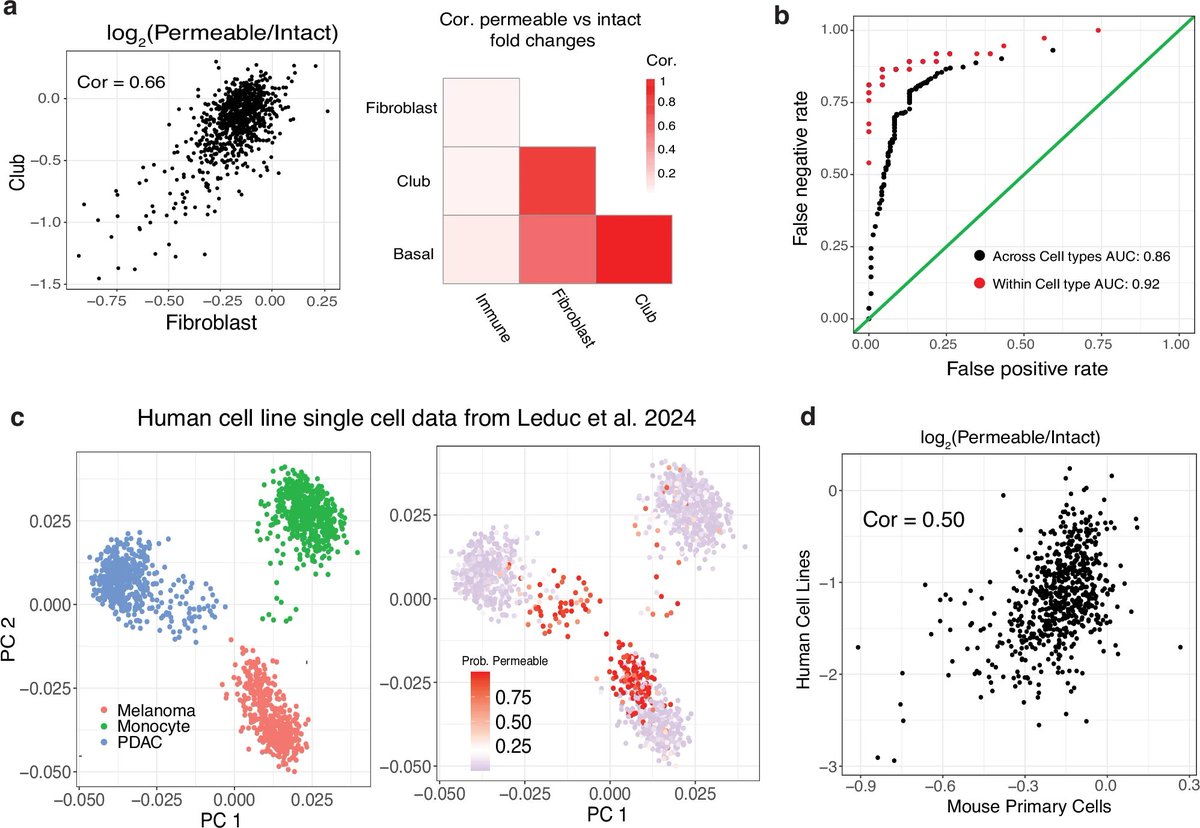


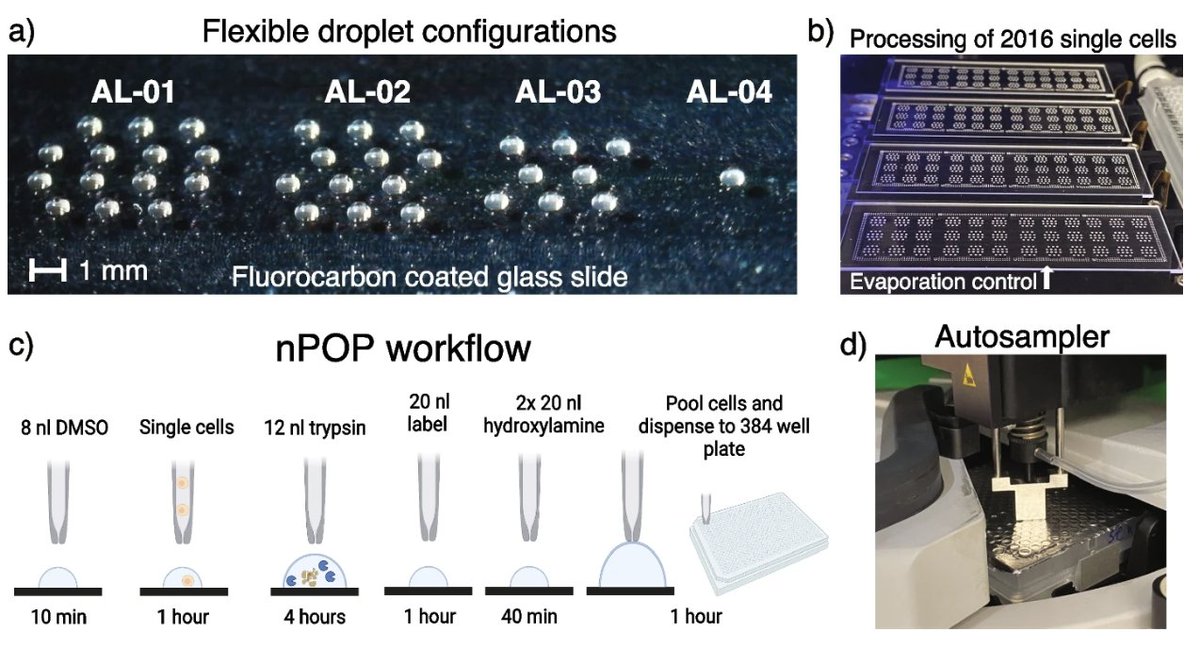
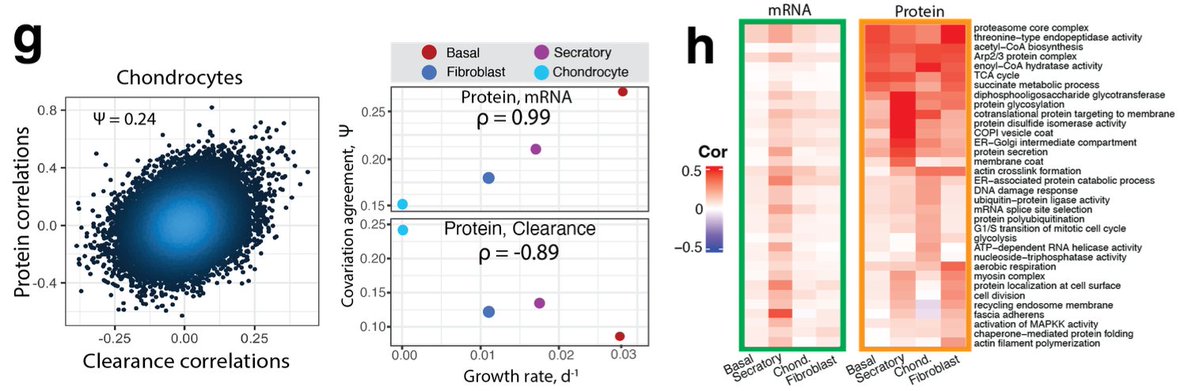
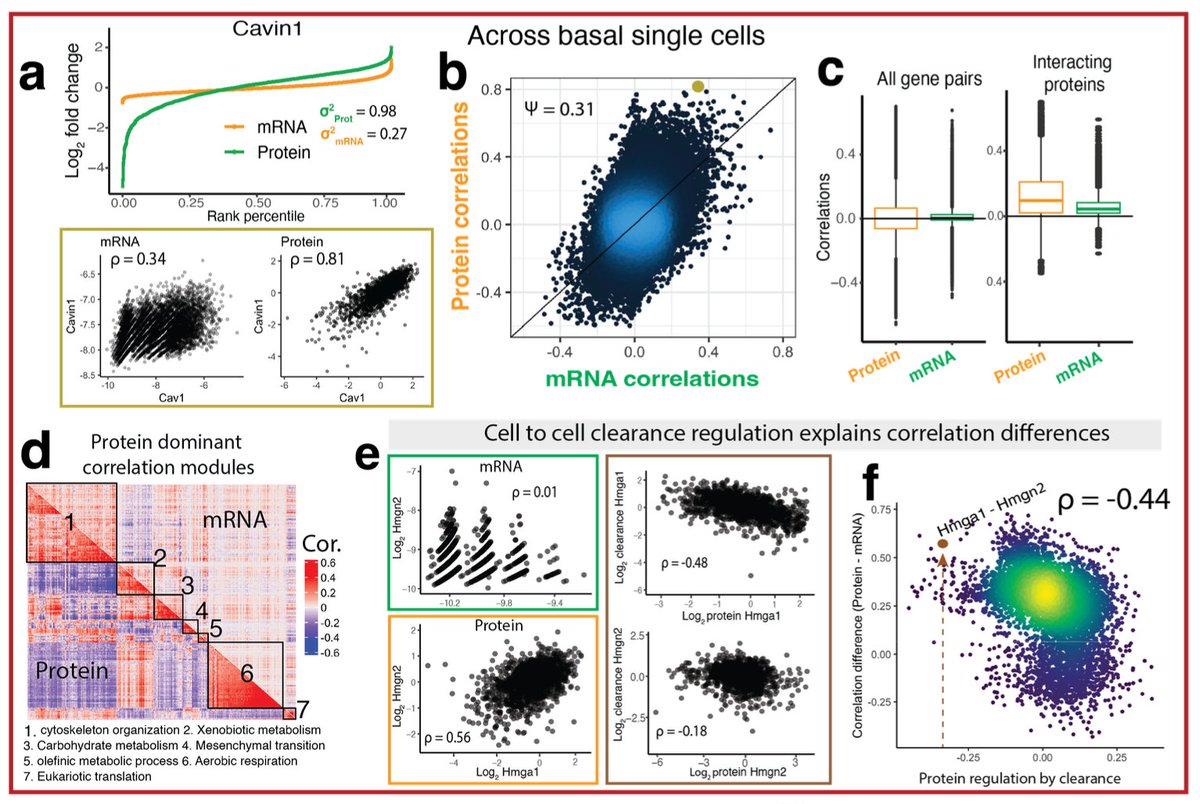
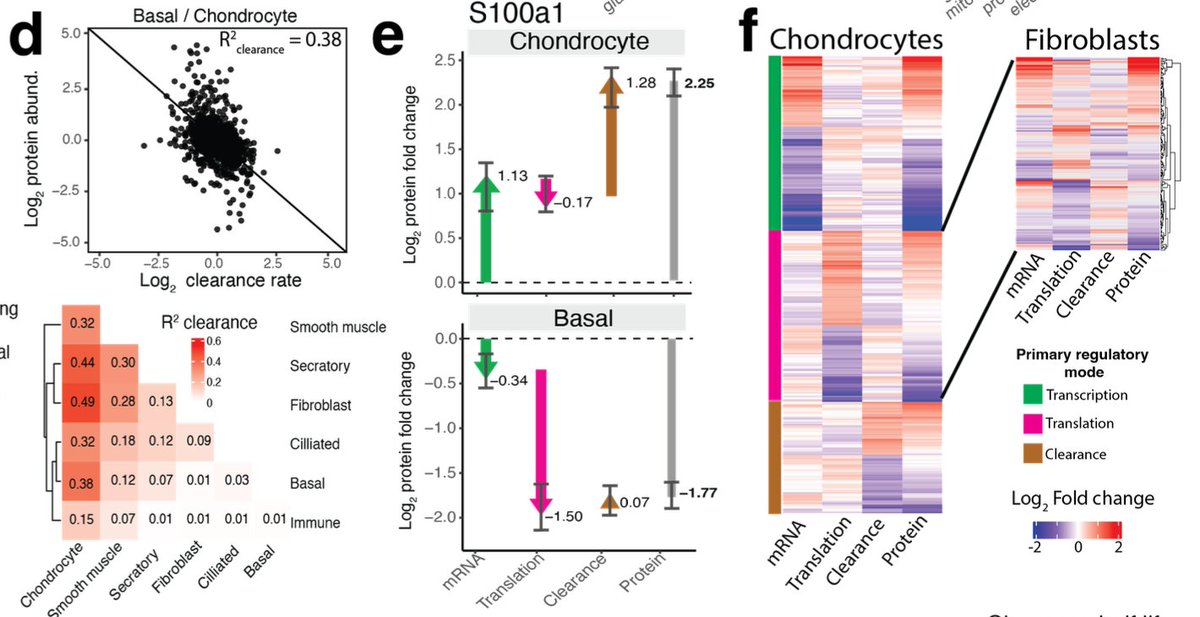
Pinned Tweet

20 Sep 2025
The big one is finally out!! In this paper, we set out to provide insight into the fundamental question;
How do the individual cells from complex tissues regulate their proteomes?
Brief summary of our findings 👇
biorxiv.org/content/10.1101/…
6
39
200
41,423

The bitterist lesson
Jun 9

No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…

3
5
67
17,095
Congrats to @slavov_n for receiving this award. Other than the amazing vision and execution that led to the development of SCP and more, I have witnessed few if any people in my scientific career able to communicate such an inspiring talk

I feel deeply honored by this recognition of research from @slavovLab, @ParallelSqTech and many collaborators and colleagues. It is very fitting to celebrate the advances in this field with the community that has contributed the most to developing these methodologies. This is recognition of just the first steps of an amazingly promising research endeavor poised to widen, deepen, and reshape our scientific understanding.


1
3
12
3,088
Andrew Leduc retweeted
I feel deeply honored by this recognition of research from @slavovLab, @ParallelSqTech and many collaborators and colleagues. It is very fitting to celebrate the advances in this field with the community that has contributed the most to developing these methodologies. This is recognition of just the first steps of an amazingly promising research endeavor poised to widen, deepen, and reshape our scientific understanding.
1
3
15
5,209
May 27
Im not sure I will ever overcome how furious I get reading reviewer comments.
You spend 3 years of your life working on something just for 3 people to skim your paper and point out a few things that were already well explained in an incredibly rude way and then reject it
9
5
86
22,957
Andrew Leduc retweeted

May 21
Longer thread later, but if you are designing small proteins or want to building a stability predictor using 1.8 million highly diverse experimental measurements… credit to @ChoYehlin and @KotaroTsuboyama !
biorxiv.org/content/10.64898…
3
26
105
8,429
Andrew Leduc retweeted

Broke: all vertebrates evolved from fish.
Woke: fish evolved from amphibi-birds.
Bespoke: Viruses evolved from nematodes.
Galaxy-brain-oke: Drosophila is a plant.
3
9
90
12,210
May 20
Its insane how overstated this is... I love using AI tools, agentic workflows blah blah, but the routine mistakes they make let alone the lack of direction they have... its clear they are nowhere near replacing even the computational work I do which is rarely cutting edge
May 20

Today we all lost our jobs.....
Three Nature papers showing that scientists in the conventional sense are obsolete
At least read the first one.... the AI replaced all things that the scientist does ....
nature.com/articles/s41586-0…

1
199
Andrew Leduc retweeted
May 18
Happy to share this in its published form! More than any project I've worked on, this was a huge team effort, so thank you so much to that team! Especially @ajrferrari nature.com/articles/s41586-0…
26 Mar 2025

Small proteins can be more complex than they look!
We know proteins fluctuate between different conformations- but how much? How does it vary protein to protein? Can highly stable domains have low stability segments? @ajrferrari experimentally tested >5,000 domains to find out!
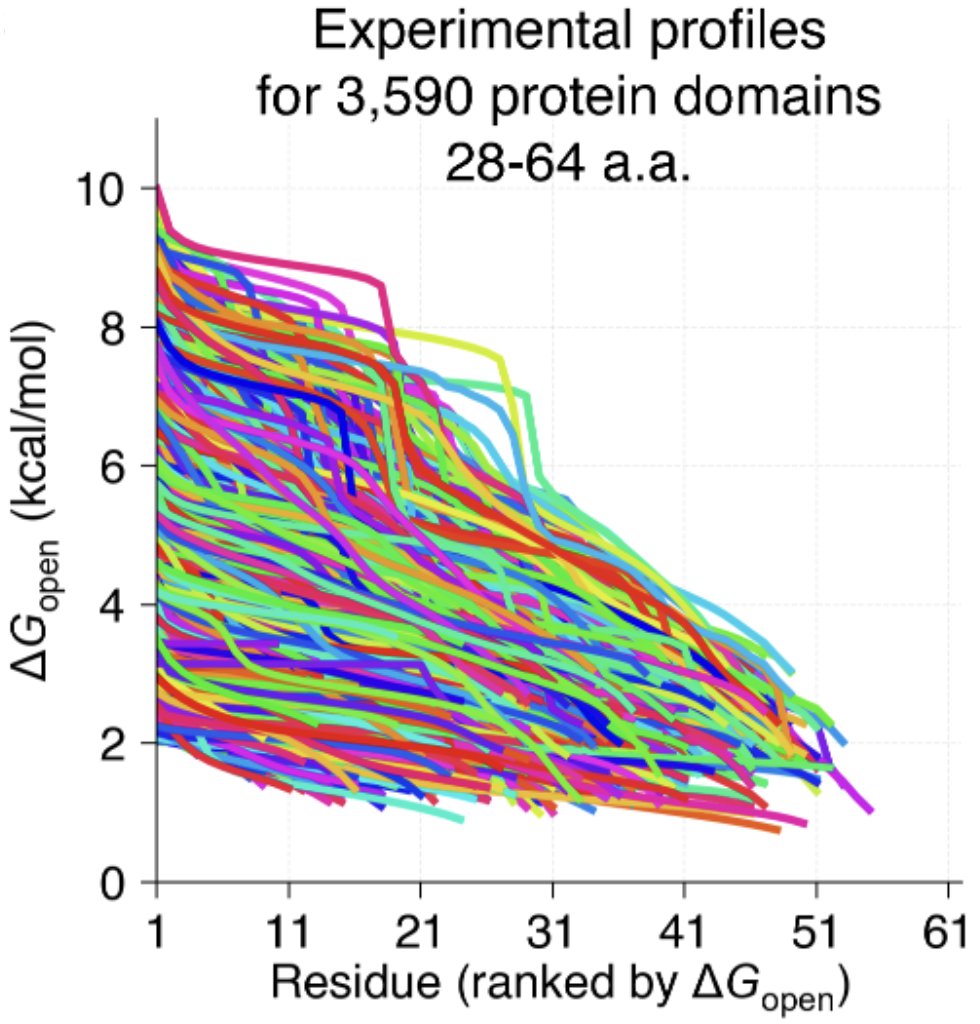
2
13
81
9,112
May 18
I will be in Palo Alto / SF area next Thursday and Friday at Stanford and Arc.
Think I have reached out to most folks I know but if interested in grabbing a coffee and talking about high throughput protein sequencing, send a message!
1
188
Its hilarious the extent to which people dont understand that mass specs actually work amazingly well right now today for protein sequencing
I think it is primarily the fault of our community in doing a poor job of applying the technology.

🐠 Everything we know about biology has been built on an incomplete picture. DNA tells us what a cell might do. Proteins tell us what it’s actually doing.
Pumpkinseed announced their $20M Series A today (led by Future Ventures and NfX) to build the platform that reads proteins directly—for the first time.
Proteomics has always faced a fundamental constraint: you can only measure what you already know to look for.
The current workhorse, mass spectrometry, requires matching protein fragments against reference databases. If a protein isn't in the database, or doesn't ionize reliably, it's invisible. Other approaches rely on fluorescent labels or antibody-based affinity methods, which introduce their own biases and blind spots.
The result is a field that has spent decades generating an increasingly detailed map of a small, well-lit corner of the proteome, while biology’s most important data layer remains hidden.
This isn't a sensitivity problem. It's a category problem. Existing tools were never designed to read proteins directly de novo. They were designed to find what researchers already suspected was there.
Pumpkinseed is built to find everything else. And proteomics is harder than most people outside the field appreciate. When we account for post-translational modifications, non-canonical amino acids, and glycan decorations, there are roughly a thousand distinct chemical monomers in the proteomic alphabet, compared to the four bases of DNA.
deSIPHR (de novo Sequencing and Identification of Proteins with High-throughput Raman spectroscopy) is Pumpkinseed's proprietary nanophotonic chip platform, fabricated with semiconducting manufacturing.
With over 100 million sensors per square centimeter, it reads proteins, known or unknown, letter by letter — amino acid by amino acid — without a reference catalog of proteins, and at high-throughput. The result is direct, high-resolution proteomic data, including post-translational modifications, non-canonical amino acids, and single-cell detail, that mass spectrometry-based approaches cannot match.
What is Raman spectroscopy? Rather than tagging or fragmenting proteins, Raman spectroscopy reads the molecular vibrations of individual molecules. Each amino acid vibrates at a characteristic frequency, producing a unique physical signature that deSIPHR detects directly. This is physics reading biology in the most literal sense.
With conventional Raman spectroscopy, only about one in ten million photons interacts with a molecule usefully, far too weak for single-molecule work. Pumpkinseed's answer is a silicon photonic chip patterned with a billion sensors per wafer. Those sensors concentrate light into volumes smaller than a single protein, amplifying Raman scattering efficiency by over 10 million-fold.
And their future ventures?
“The longer-term ambition is the virtual cell, a computational model that simulates not just how proteins fold but how they interact, respond to drugs, and behave under perturbation inside a living system. AlphaFold demonstrated what structural AI can do once a sequence is known. The gap that cannot be closed is determining the sequence itself from biological samples, particularly for proteins carrying modifications absent from existing databases. Pumpkinseed is designed to supply that input layer.
"If the Human Genome Project was the data infrastructure that enabled genomic medicine, we believe the high-resolution proteomic dataset Pumpkinseed is building could be the analogous foundation for AI-driven biological discovery," co-founder Dr. Jen Dionne says. "In our vision, the molecular signatures driving disease, aging, and ecosystem health become fully legible. Medicine shifts from reactive to proactive. Optimal healthspan moves from aspiration to achievable reality." —synbiobeta.com/read/pumpkins…
• The biology mining company: Pumpkinseed.Bio
• Today’s News: pumpkinseed.bio/news/pumpkin…
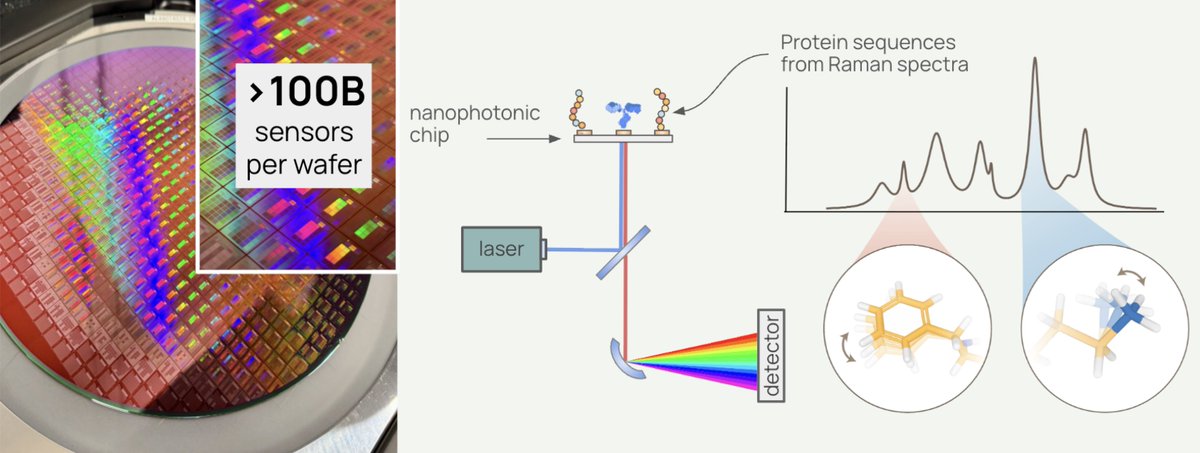
6
2
22
4,410
Andrew Leduc retweeted

It is our pleasure to announce that @slavov_n (Northeastern University, Boston) will be giving a talk at @CNIC_CARDIO this coming Monday, May 11th, at 12:00 pm in the Auditorium. We look forward to an engaging presentation on the field of single-cell proteomics.
#singlecell

3
8
1,793
We submitted a paper to cell systems, it got sent out for reviews, we got the reviews back and responded a month later.
It has been 6 months and we have had 0 correspondence from the journal. No updates of any kind despite sending a number of emails to editors. Is this normal?
2
7
1,483
Apr 28
nature.com/articles/s41596-0…
Here is one good reason!
Apr 27

I really wish I had a reason to own machines that handle picoliters and nanoliters of liquids and array them out for me very precisely and satisfying in a little grid.
Is there a way to make money doing this?
1
3
269
Andrew Leduc retweeted

Apr 26
Biological functions arise from protein interactions, which are reflected in the natural variation of proteome configurations across individual cells. Emerging single-cell proteomics methods may decode this variation and empower inference of biological mechanisms with minimal assumptions.
This presentation summarizes research projects aiming to infer protein regulatory interactions from protein covariation across single cells. Examples include the regulation of protein transport to the nucleus and cell fate determination during early development.
youtu.be/ggr3NWzP-yM?si=KjnJ…
6
26
4,153
Andrew Leduc retweeted

Apr 23
Cells are not a linear algebra equation.
Beautiful work from @Rachel_E_Savage showing that good ol' mechanistic biology is still essential in the era of virtual cells

It takes two (transcription factors) to tango
Transcription factor collaboration enables precise T cell state engineering
tinyurl.com/tcelltfs
Excited to share our preprint with @JD_Buenrostro, @cgersbach, and an incredible team of collaborators as part of @IGVFConsortium
🧵
1
12
95
12,594
Andrew Leduc retweeted

Apr 15
How does a cell learn? In our new perspective in @Nature we propose a model where the properties of the AP-1 family of transcription factors – stress-induced feedback, regulatory combinatorics & cellular memory – encode a mechanism for cellular learning. nature.com/articles/s41586-0…

6
68
225
23,152
Andrew Leduc retweeted

Apr 12
ρPCA is super useful in anytime one wants to examine differences in variance (rather than just the mean), while performing dim. reduction. Our preprint gives an example using single-cell RNA-seq: we find differentially variable genes (rather than differentially expressed). 5/
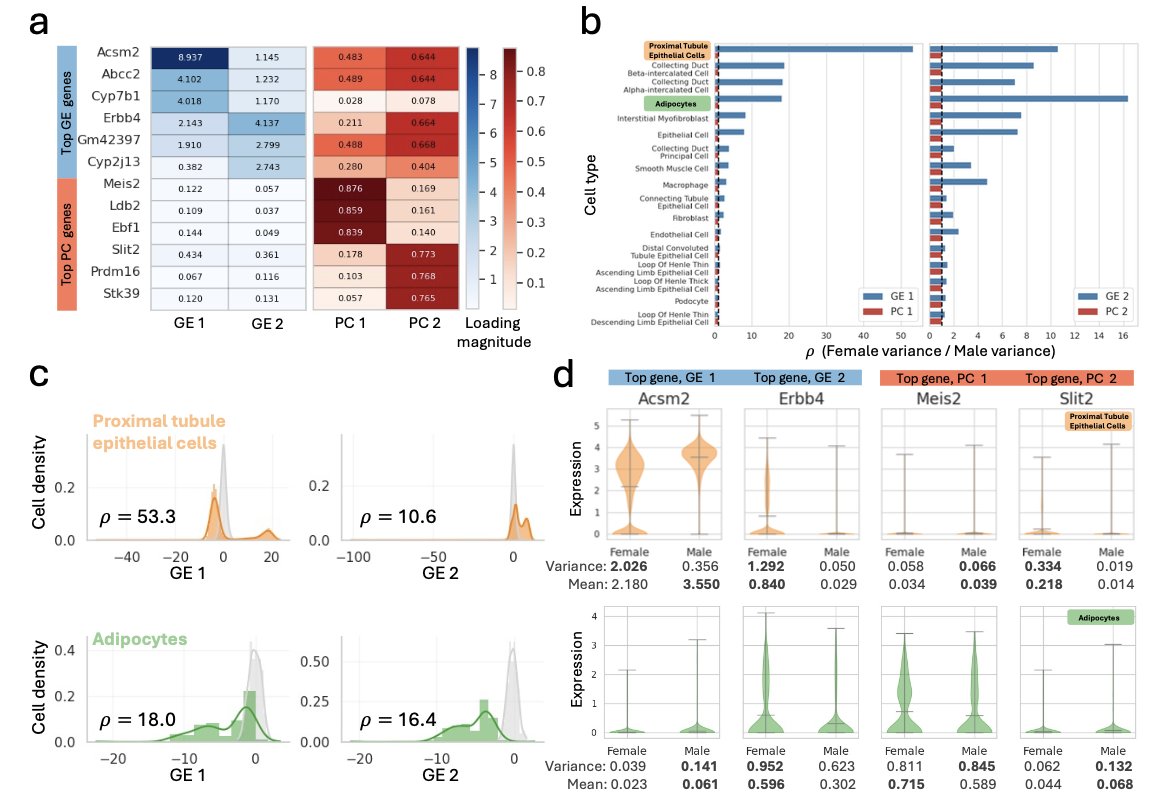
1
3
17
2,130
Andrew Leduc retweeted
Apr 12
We need more slow thinking.
More reflection. More depth.
Fewer hot takes. More long-form conversations that challenge, refine, and expand how we see the world.
Because the best ideas don’t arrive instantly, they’re built, tested, and sharpened over time.
1
5
19
973
Apr 11
The more we focus on evaluating the quality of the work and less the journal of publication, the more we can limit the consequences of poor behavior from journals/editors
Apr 1

For some, yes (including myself). I will say that I have noticed many authors who have retreated from using preprints upon first submission due to journals looking unfavorably on papers that have been up as preprints for a long time, which is sad for science.
2
196
Christ? yeah he was all about warship of earthly power right? He was the guy who said the first shall be first and the last is a LOSER right? Pretty sure we are communing with the same christ?

I’ve been writing this book for a long time, and I’m honored to finally be able to share the full story with you all. Communion is about my personal journey and how I found my way back to faith.
It will be available in June, but you can pre-order today: a.co/d/0cTpceI7

126