
Enterprise support for mission-critical open-source analytics: Druid, StarRocks, TiDB, ClickHouse & Flink. 24/7 SLA, CVE, Expertise. Global leader for Druid.
Joined September 2015
- Tweets 816
- Following 892
- Followers 962
- Likes 1,586
345 Photos and videos
















Which OLAP database has the best security model?
We compared Apache Druid, StarRocks, and cloud platforms across 5 dimensions: auth, RBAC, encryption, auditing, and network security.
Full breakdown 👇
deep.bi/blog/druid-vs-starro…
572
Following up on our earlier blog post on production-grade backups for StarRocks, this article is a hands-on guide to running full & incremental backups and safely restoring tables with starrocks-backup-and-restore.
👉deep.bi/blog/production-grad…
#StarRocks #DataEngineering
476
StarRocks is fast.
Backups at scale are not trivial.
We’re introducing starrocks-backup-and-restore – a production-grade approach to incremental, partition-level backups with full metadata tracking.
Why it matters 👇
deep.bi/blog/introducing-sta…
#StarRocks #DataEngineering #OLAP
338
Data vanished in Apache Druid after ingestion?
It might just be overshadowed.
Learn how segment versioning works how to restore older segments:
deep.bi/blog/managing-segmen…
#ApacheDruid #DataEngineering #StreamingData #RealTimeAnalytics
225
New tutorial!
Unlock real-time business insights with Apache Druid Apache Superset — connect, visualize, and explore data at scale.
👉 deep.bi/blog/real-time-busin…
#RealTimeBI #ApacheDruid #ApacheSuperset #DeepBI
1
3
221
Simplifying Druid monitoring just got easier! 🚀 Our team developed a solution using Druid, Kafka, and Grafana - no Prometheus needed. Streamline your data workflows and overcome monitoring challenges. Learn more in our latest blog post: deep.bi/blog/monitoring-drui…
#DataScience #BigData #ApacheDruid
1
3
276
📘 Learn how to integrate Apache Druid with Cube.js to implement fine-grained access control for secure multi-tenant data management with our new guide: deep.bi/blog/integrating-apa…
#DataSecurity #ApacheDruid #CubeJS #FGAC #ITSecurity #DataManagement #MultiTenancy #TechTutorial
1
202
📊Monitoring Apache Druid in Grafana: Learn how to track essential metrics like query performance, indexing, and system health with easy-to-follow steps and sample dashboards in our latest tutorial:
deep.bi/blog/monitoring-apac…
#DataAnalytics #Grafana #ApacheDruid #SystemMonitoring #TechBlog
2
149
Are you looking for a reliable open-source visualization tool for Apache Druid? 📊🔗
Then Grafana is the one to consider. Check out our comprehensive step-by-step tutorial on integrating with Grafana: 👉 deep.bi/blog/integrating-gra…
Discover how to create informative dashboards and easily gain deeper insights into your data.
#DataVisualization #Grafana #ApacheDruid #BigData #DataAnalytics #OpenSource #TechTutorial #DataScience
1
124
🔐Enhance the security of your #ApacheDruid deployment with Basic Role-Based Access Control (#RBAC). Learn how to implement RBAC in this comprehensive tutorial: deep.bi/blog/implementing-ba…. Follow us for updates & stay tuned for more insights on optimizing your Apache Druid setup. #DataSecurity #ApacheDruidTutorial
2
128
#ApacheDruid for #AI? Watch our talk at #DruidSummit about our open-source Spark Druid Connector that we've built to help data scientist make use of @druidio data. Dec 6, register for free! @implydata
2
5
Deep.BI retweeted

27 Jan 2021
In this #flinkforward talk, Michal Ciesielczyk from @_DeepBI discusses how their team built a data pipeline with @ApacheFlink for use cases such as fraud detection, A/B test control, content scoring, and user engagement modelling.
👀📺: bit.ly/2KPqGVL

5
17
Make sure to get in touch with us, @AhmadEldefrawy or @sebastianzontek if you'd like to learn more!
If you miss the meetup make sure to check out DataOps Polska's YouTube channel for the upload.
15 Sep 2020

Make sure to join DataOps Poland's meetup in a couple of hours to learn how Apache #Flink, #Druid & #Cassandra are being used at @_DeepBI for Real-time Stream Analytics and Scoring!
meetup.com/DataOps-Polska/ev…
#apacheflink #apachedruid #ApacheSpark #mongodb #tensorflow
1

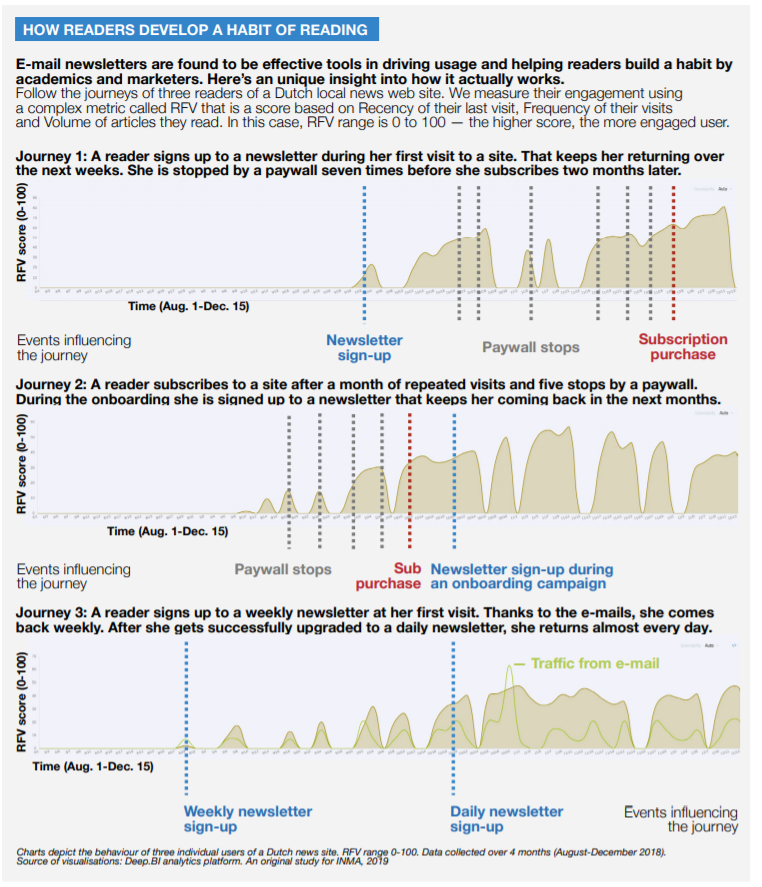
.@_DeepBI insight: The most predictive machine learning algorithm was the time since the first visit ever by a reader, or the tenure, measured by days and then translated into a loyalty score. ow.ly/RfFM50Aqb6c @g_piechota
4
6
Deep.BI retweeted

6 Jul 2020
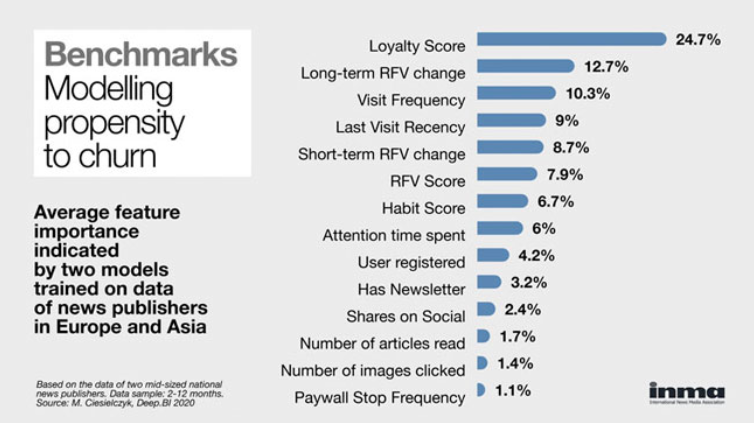
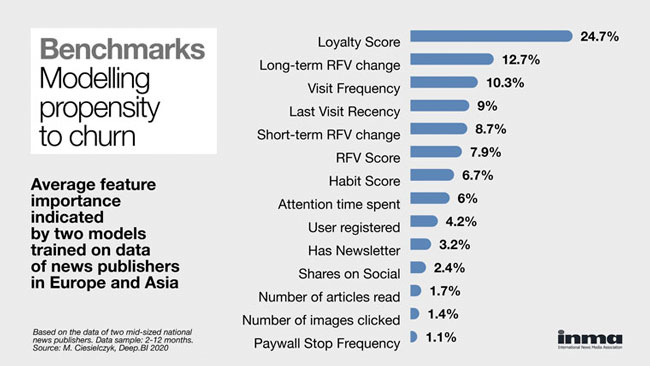
A reader's Loyalty Score is the biggest determining factor of that reader's propensity to churn according to @_DeepBI, followed by long-term RFV (recency, frequency, volume) change and visit frequency. Get in touch to find out more! #churn #retention #subscriptions
6 Jul 2020

What can AI teach us about behaviours leading to churn? inma.org/blogs/reader-revenu…
1
2
Deep.BI retweeted
4 Jul 2020
.@Jaguar, @LandRover and @BMW all launch subscription services for their vehicles, citing extra features their customers can enjoy. Some early signs showing that people do NOT like this approach, more to be seen in the future. #subscriptions
autoblog.com/2020/07/03/jagu…
1
3
Deep.BI retweeted
30 Jun 2020
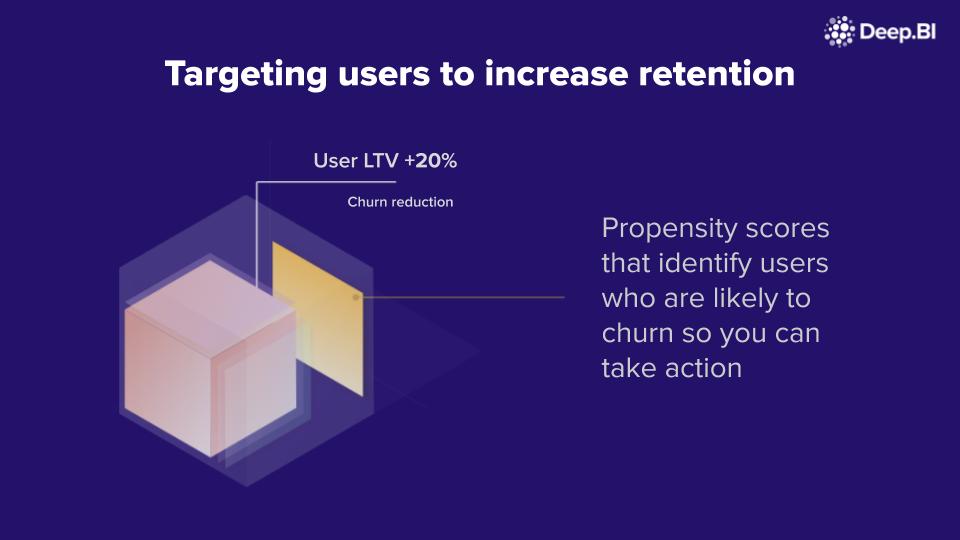
Make sure to join us in 30 mins at @INMAorg's Digital Subscriber Retention Master Class today organized by @g_piechota where our Head of AI Engineering Michał will be presenting how #publishers can use data and #AI to build models which predict and prevent #churn! #subscriptions
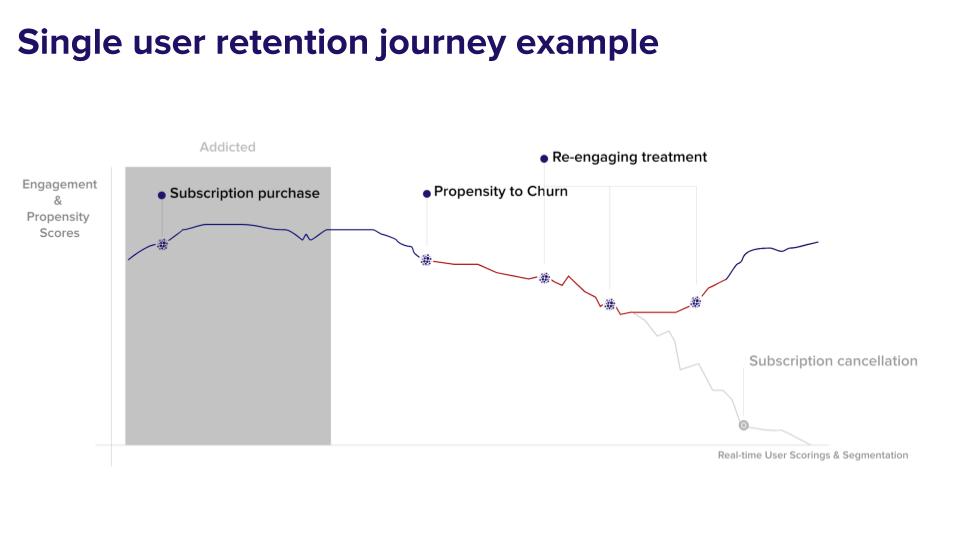
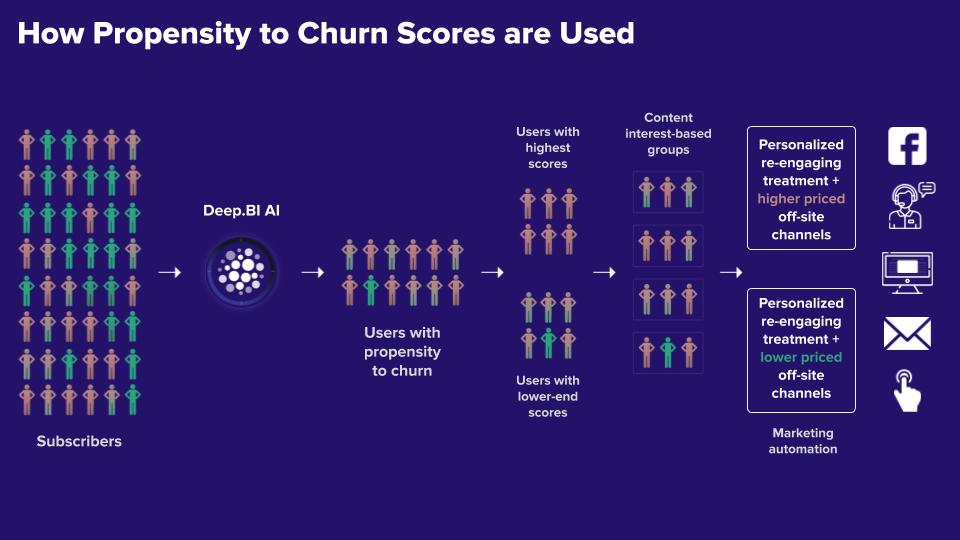
2
4
Targeted paywalls stop readers selected with advanced analytics techniques, such as data mining, statistics, modelling, and machine learning. ow.ly/7cEU50zXkEt @_DeepBI @g_piechota

5
5
Two experiments carried by mid-sized publishers in Europe and in Asia show the promise of propensity models when applied to paywall targeting. ow.ly/Ignv50zXkEi @_DeepBI @g_piechota
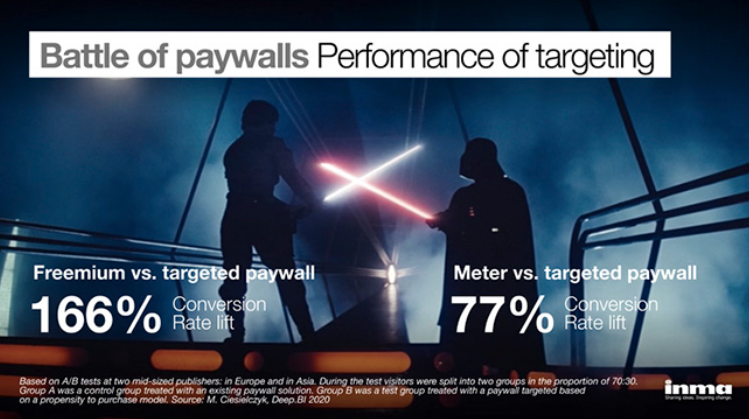
2
5
Being a registered user to a news site is found to be universally the most predictive feature indicated by five propensity to buy models. ow.ly/UMP350zXkEW @_DeepBI @g_piechota
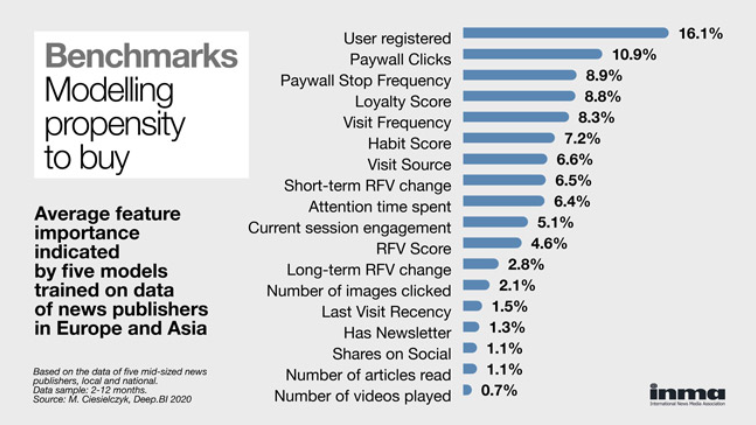
7
6