
Assistant Professor @SapienzaRoma | @ELLISforEurope member.
Joined December 2011
- Tweets 236
- Following 463
- Followers 362
- Likes 1,325
28 Photos and videos












Indro Spinelli retweeted

May 27
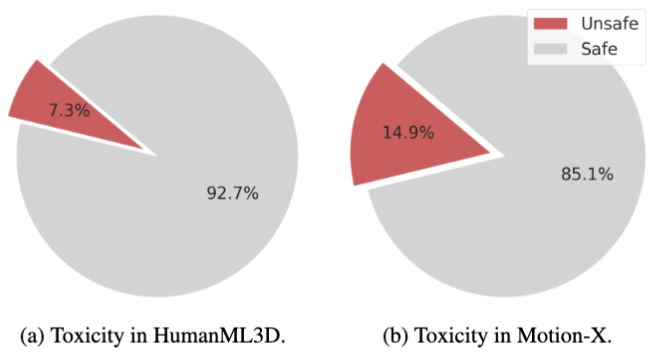
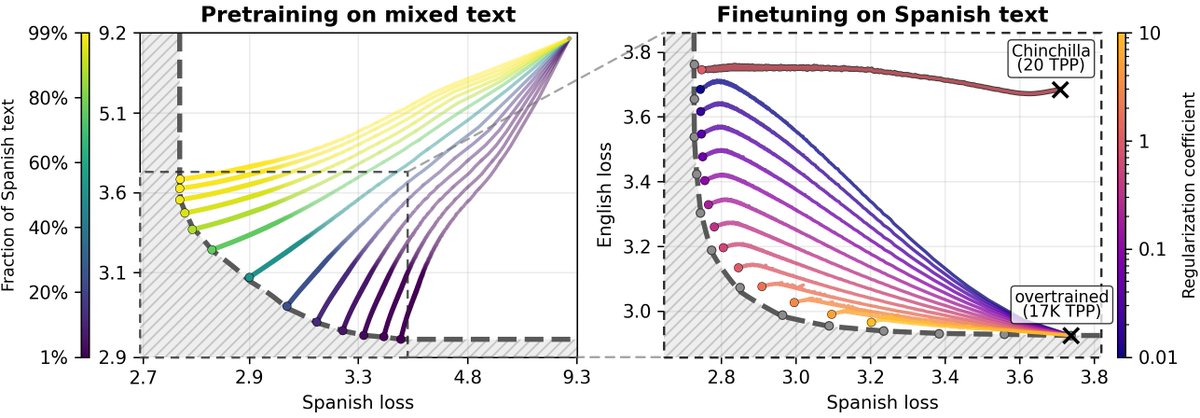
How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay!
arxiv.org/abs/2605.26097
w/@mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov 1/8
18
89
666
51,476
Indro Spinelli retweeted

May 18
We are back at ECCV 2026! Our workshop will feature work in the beyond Euclidean space and we are accepting full paper submissions as part of our springer proceedings! Openreview link will open shortly but in the meantime check our call for papers out! @eccvconf
1
4
9
2,396
Indro Spinelli retweeted

Relics from the prehistoric era of AI

61
237
8,157
431,343
Indro Spinelli retweeted

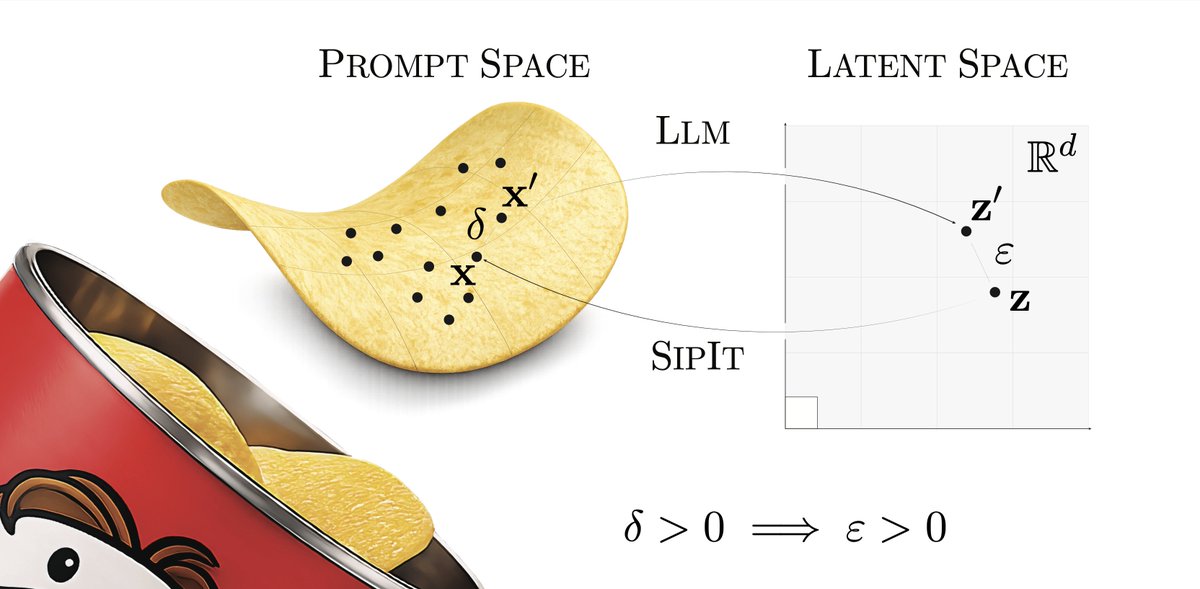
alright we can't hide it anymore
come and see the pringle in all its glory at @iclr_conf
27 Oct 2025

LLMs are injective and invertible.
In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space.
(1/6)
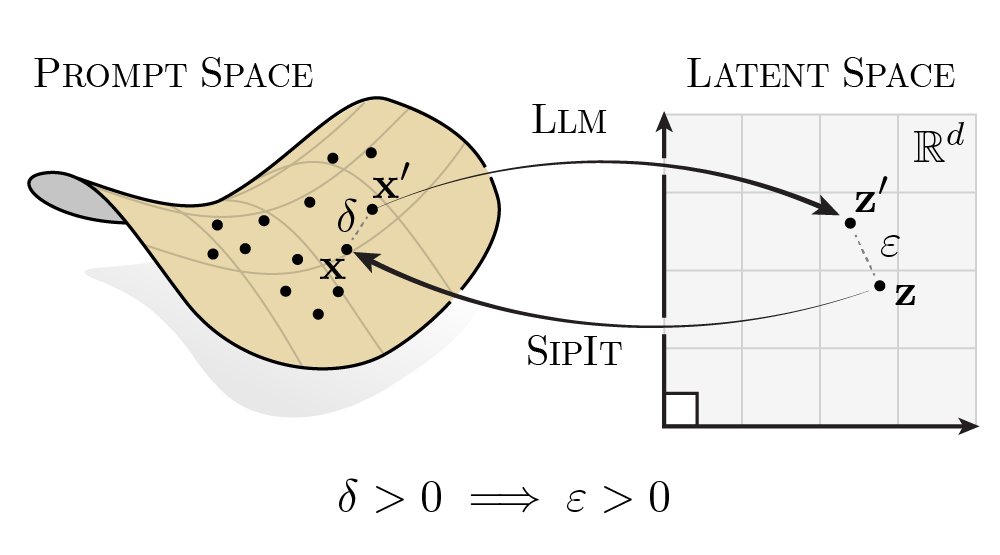
3
77
1,139
90,135

Apr 21
Sad to miss #ICLR2026 this year, but our work will be there with Simone and Stefano.
We propose the first training-free framework for permanently removing concepts from generative video models.
📅 Fri, Apr 24 • 11:15 AM – 1:45 PM
📍 Pavilion 4 P4-#4305
Bye bye DiCaprio!
1
5
10
645
Apr 21
Hello, average (objectively attractive) man! DiCaprio-adjacent, but safely off-brand.
A @SapienzaPINlab work!
🔗 Arxiv: arxiv.org/abs/2506.07891
🔗 Project page: pinlab.org/video-unlearning
1
96
Indro Spinelli retweeted

16 Nov 2025
Long time I am not on X. I thank the organisers of the @ICCVConference "Beyond Euclidean: Hyperbolic and Hyperspherical Learning for Computer Vision" for inviting me as Keynote speaker in their inspiring workshop. @adn_twitts @geleonti @IndroSpinelli @GalassoFab10 et al.



3
6
609
5 Nov 2025
freshly unboxed under the Roman sun! ☀️ A massive thank you to @NVIDIAAIDev and the #NVIDIAGrant program for this opportunity. Time to teach some robots how to speak! 🚀
7
178
30 Oct 2025
Absolute banger from these department colleagues!
27 Oct 2025
LLMs are injective and invertible.
In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space.
(1/6)
1
116
22 Oct 2025
Join us at poster 88 to discuss MonSTeR: a unified model for motion, scene and text retrieval!
1
5
109
19 Oct 2025
We are live for the second edition of the Beyond Euclidean workshops at @ICCVConference
2
14
1,268
18 Oct 2025
Just landed in Honolulu for ICCV 25! You can read MonSTeR here: arxiv.org/abs/2510.03200 and then find us
at Poster Session 3 #1003
🗓 Oct 22 | 11:15 a.m. - 1:15 p.m. HST - Exhibit Hall I
2 Jul 2025

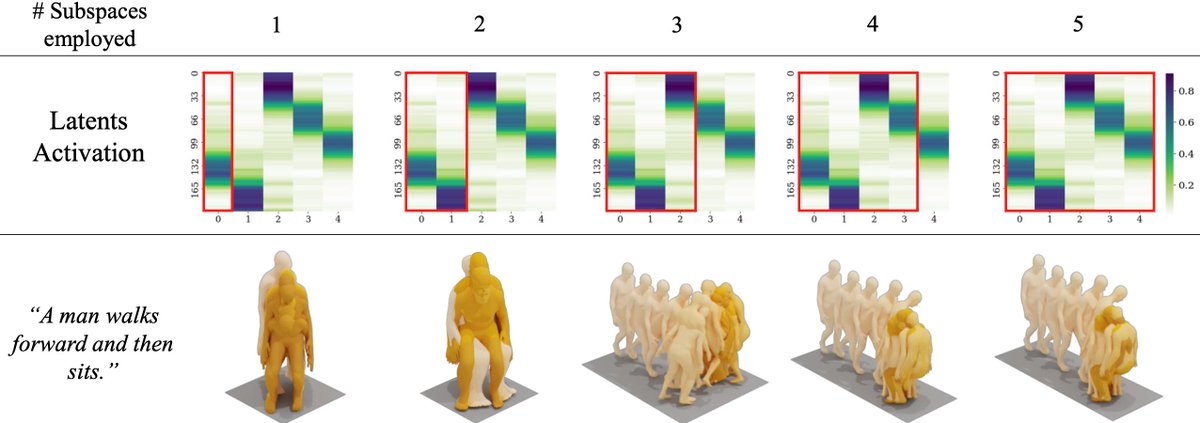
TtA (Thrilled to announce) that our paper, "MonSTeR: A Unified Model for Motion, Scene, and Text Retrieval" has been accepted at #ICCV2025 🌋🌺🌴🌊🏄♂️🍹
MonSTeR creates a unified latent space that understands the relationship between text, human motion, and 3D scenes.
1
2
11
1,246
19 Oct 2025
You will find the entire team with @LucaCollorone @orlitany @GalassoFab10 and more from the @SapienzaPINlab
4
64
Indro Spinelli retweeted

16 Oct 2025
Children learn to manipulate the world by playing with toys — can robots do the same? 🧸🤖
We show that robots trained on 250 "toys" made of 4 shape primitives (🔵,🔶,🧱,💍) can generalize grasping to real objects.
@JitendraMalikCV @trevordarrell Shankar Sastry @berkeley_ai😊
3
29
142
27,451
Indro Spinelli retweeted

16 Oct 2025
We are getting ready for the second edition of Beyond Euclidean Workshop @ICCVConference
We hope to see you there on Sunday!

5
8
3,605
28 Jul 2025
Back in Rome after an incredible visiting period at @TU_Muenchen. Thanks @BusamBenjamin & @NassirNavab for hosting. It was amazing to see the latest in medical robotics and its democratisation, meet new people, and present @SapienzaPINlab's work! The slide lived up to the hype🎢
15
197
2 Jul 2025
TtA (Thrilled to announce) that our paper, "MonSTeR: A Unified Model for Motion, Scene, and Text Retrieval" has been accepted at #ICCV2025 🌋🌺🌴🌊🏄♂️🍹
MonSTeR creates a unified latent space that understands the relationship between text, human motion, and 3D scenes.
1
3
9
1,650
2 Jul 2025
It's not just about matching intent with action🗣️🕺; it's about verifying if the environment🌍 allows for it. We believe this is a significant step towards creating more plausible and grounded human-scene interactions.
1
2
111
2 Jul 2025
Code and preprint will follow. In the meantime huge thanks to @LucaCollorone for being a Beatles' fan (and a great researcher), @orlitany for this awesome collaborations, to the others @SapienzaPINlab co-authors and its head @GalassoFab10 that contributed to this achievement!
3
105