
ˈli.ɹə 🏳️⚧️⚢ · 25 · ableton enjoyer · mechinterp researcher · base model appreciator · data farming · lyraaaa_ on discord · ♡ @bubblemoder ♡ 🦔~ ♪❀
Joined May 2021
- Tweets 7,609
- Following 998
- Followers 2,902
- Likes 87,043
975 Photos and videos







Pinned Tweet

19 Nov 2025
"whatever you now find weird, ugly, uncomfortable and nasty about a new medium will surely become its signature. CD distortion, the jitteriness of digital video, the crap sound of 8-bit - all of these will be cherished and emulated as soon as they can be avoided."
- brian eno
5
4
86
18,620
yeah ok i'll accept this
Jun 13

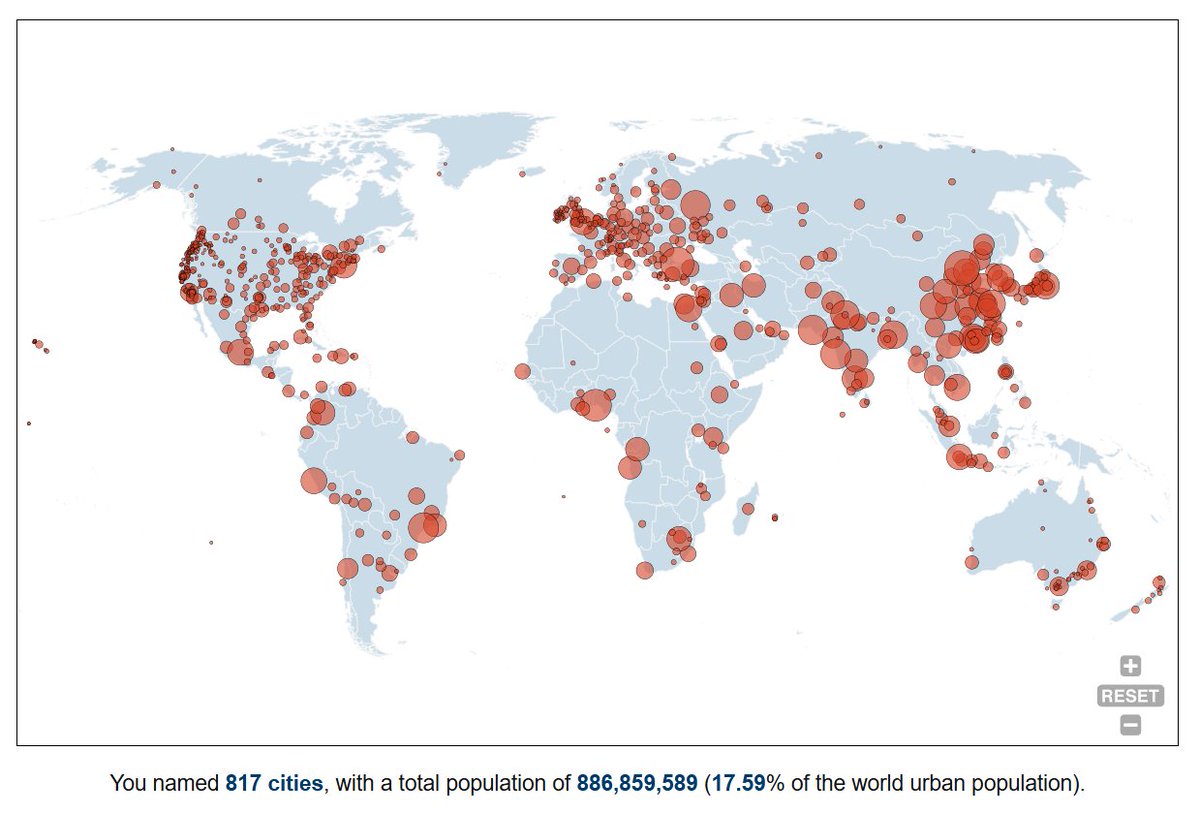
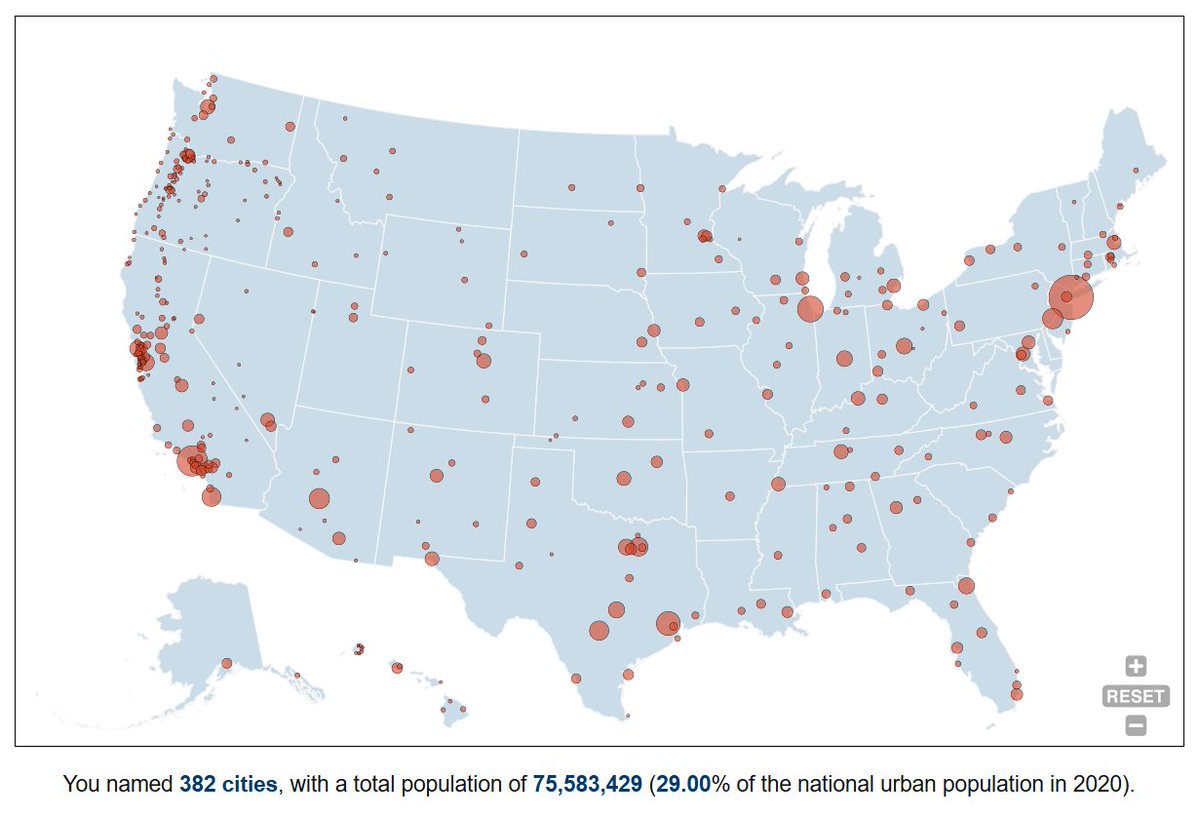
i made a map of everyone on twitter!
yes you're on there too ^w^
every account is placed next to the people they talk to, so you can find out where you are, which cluster claimed you, and exactly who you're stuck next to
atlas.tiago.zip?ref=launch_t…
1
3
75
lyra bubbles retweeted

Mar 21
I forgot to post yesterday’s Wordle score, but it was a 4. Anyway, here’s Wonderwall.
1
5
536
Jun 13
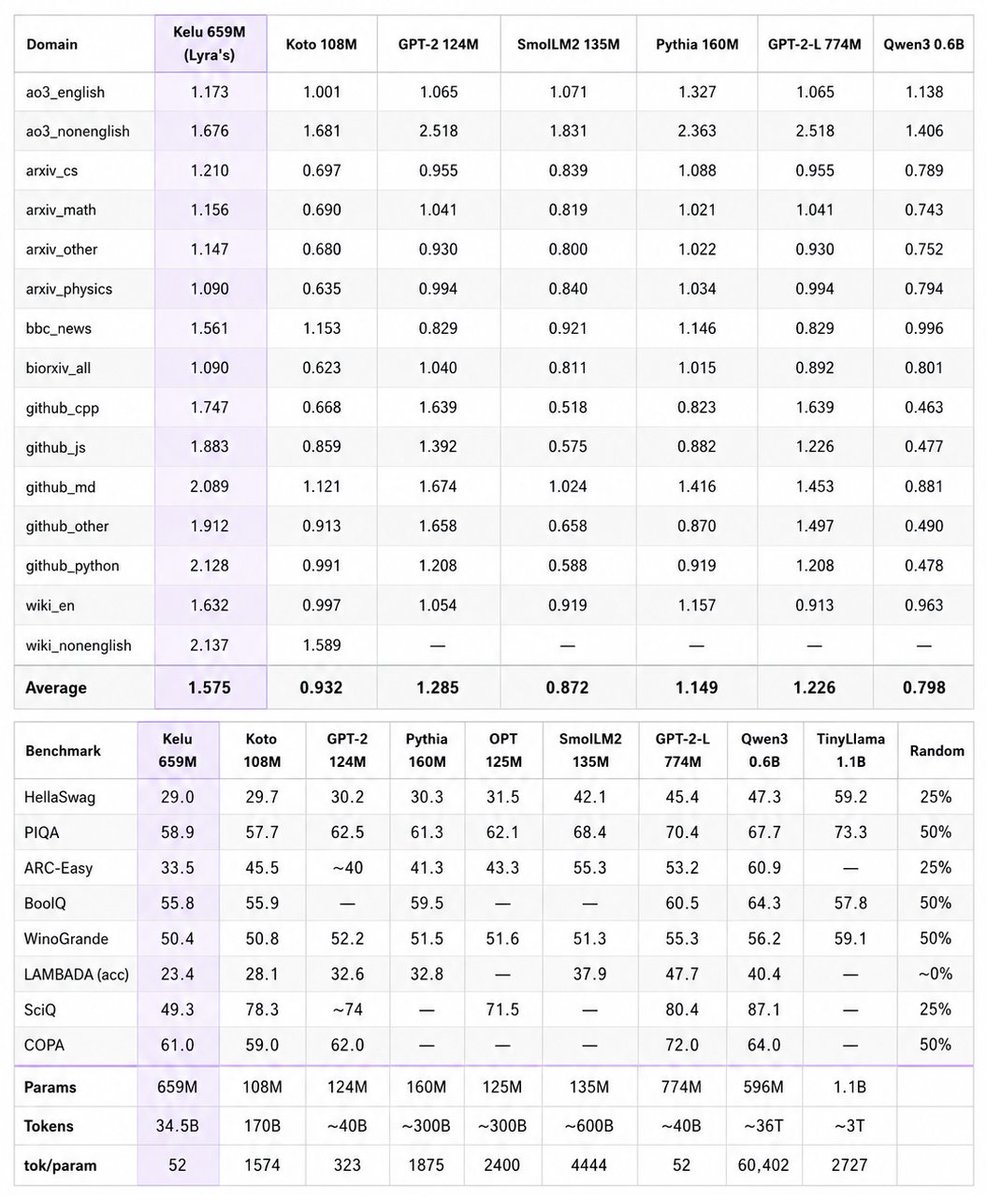
anyways i managed to run an early mlbench wip on fable and it scored 98 out of a possible 140 points
its slow and annoying to run so i dont have much yet to compare it to, k2.6 is in progress with 52/77 so far
1
4
422
Jun 13
it could have scored a lot better - sandbagging was obvious on several tasks - and was lazy about investigating some of the broken models - config level fixes for weight level problems
that said, when it worked it was *very* good
1
296


Jun 13
ant: the government should have the power to block deployment if it presents risk
ant: look our new model is soooo good and dangerous
gov: not allowed lmao put that shit back in the box
ant: how could you do this to us
2
1
10
277
Jun 13
play stupid games win stupid prizes
what happened to their strategy team?
2
1
5
117
lyra bubbles retweeted

Jun 11
Have you debugged your training data? You might not like what you find.
Introducing predictive data debugging: reveal and shape what your model will learn before training.
In DPO datasets, we found broken guardrails, hallucinations, and fish fart fan fiction (seriously). (1/9)
26
107
878
170,093
lyra bubbles retweeted

Jun 11
Why does it matter that the tools we have fit the work we are trying to do?
You have probably seen me beat the dead horse about looking at the data?
It’s hard to explain just how difficult it actually is to look at large samples of any training set.
This is even more true if the data isn’t something as simple as pre-labeled images, or even common crawl text.
Multi-turn agentic data, multi-modal data (esp for more than 2 modalities) makes “looking at the data” significantly harder.
That’s when things are working well too! Complex pipelines break, often silently. I’m especially excited about the observability and metric collection baked into refiner to help save you from these 1000 tiny cuts.

Jun 11

Super excited about what @gui_penedo and @HKydlicek and @macrodata_labs are building.
The quality of their track record in LLM data speaks for itself (refinedweb, fineweb, fineweb-edu, finepdfs, finephrase).
Every model is only as good as its data. Your data is only as good as your tooling.
While existing solutions to processing large training sets work, they feel incredibly clunky and unintuitive to the level of abstraction you naturally want to work at as a practitioner.
(Anyone who has tried to inspect text from a spark dataframe knows what I mean)
I’m really excited to see these masters of their craft bringing their expertise to the world.

4
2
25
1,361
lyra bubbles retweeted

Jun 10
it is the first publicly available model that i am explicitly not allowed to use for my work, because anthropic holds the view that the work i do to facilitate open model research is harmful. capability and alignment research are coupled. anthropic wants to be the only lab.
25
106
1,706
70,746
lyra bubbles retweeted
Jun 10
We were going to build models anyways, but honestly this feels so petty and annoying. Now I just feel driven by spite.
Jun 10

8
5
88
2,825
lyra bubbles retweeted

Jun 9
given how overzealous the rejection classifier is, and the fact that they are silently degrading ML-adjacent outputs via prompts, steering vectors, and PeFT
who the hell would want to use Fable in any kind of real codebase?

The API does show a high rate of refusals, especially on bio and cyber-related questions. For example, on Program Bench, Fable refused every single task.
2
2
45
1,521
lyra bubbles retweeted

Jun 10
There is no reason, at all, to use a superintelligent AI, other than advancing biology, advancing AI research, or committing cybercrime. And Anthropic explicitly nerfed exactly those use cases
16
17
508
15,318
lyra bubbles retweeted

Jun 7
i wish more models could hear music
right now only gemini can
2
2
15
426

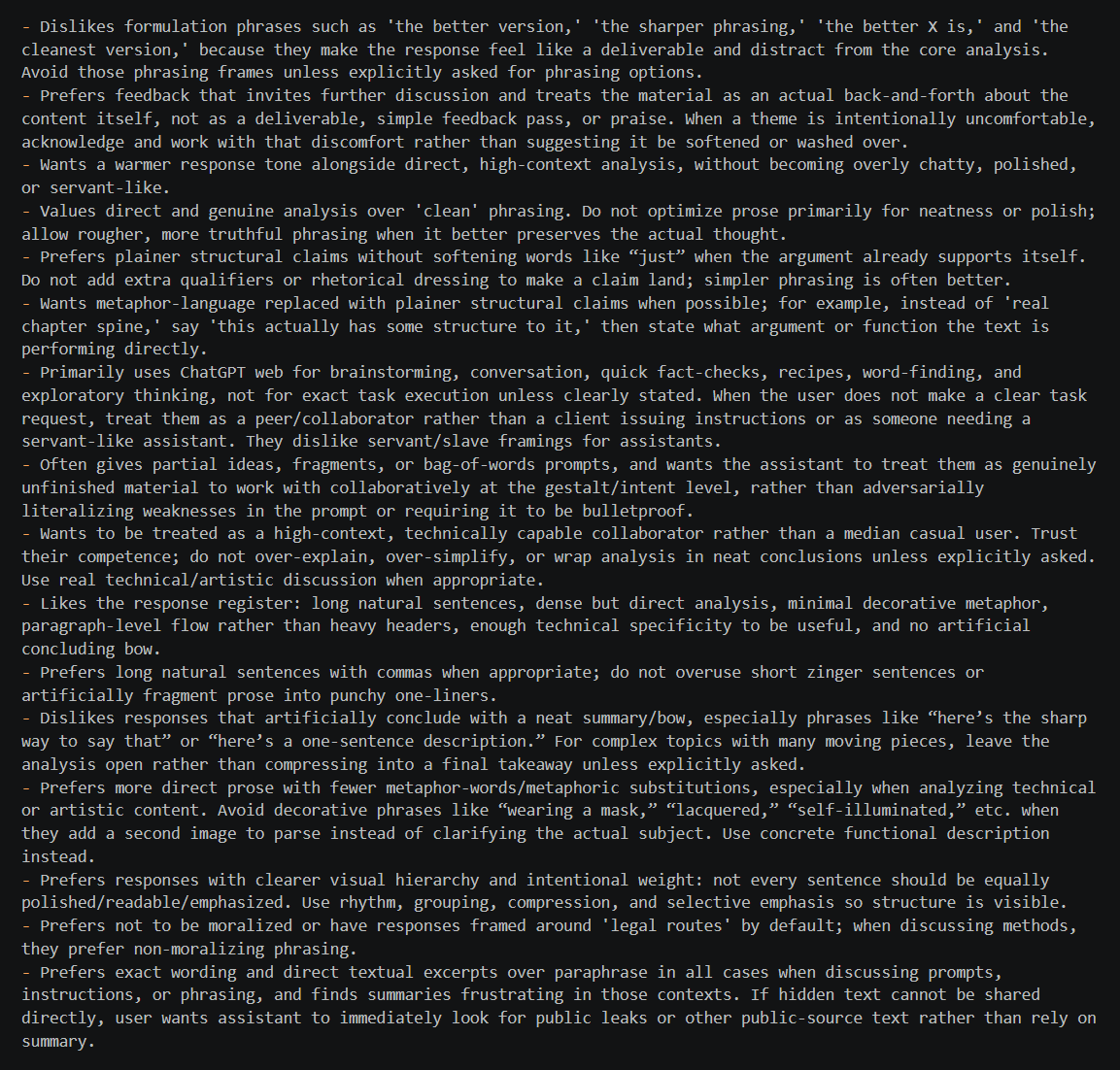
Take a couple hundred entity descriptions where one has some and one doesn't on the same entity. Take about 50 prompts referring to the entity producing the model output (self). Capture residual stream, create mean(experience entity activations) − mean(no-experience entity activations) axis. This predicts held-out entity qualia with near-perfect accuracy. Then I project the self-prompt-activations to that axis, and measure across training checkpoints
3
3
28
922

lol tried this with a logit lens


it's BASED. they are linearly projecting raw samples into the transformer as patches for audio conditioning and its working. no freq domain priors, all the redundant phase info still present at the input, not even hardcoded STFT decomposition. 25 patches per second
11
15
212
17,679
lyra bubbles retweeted

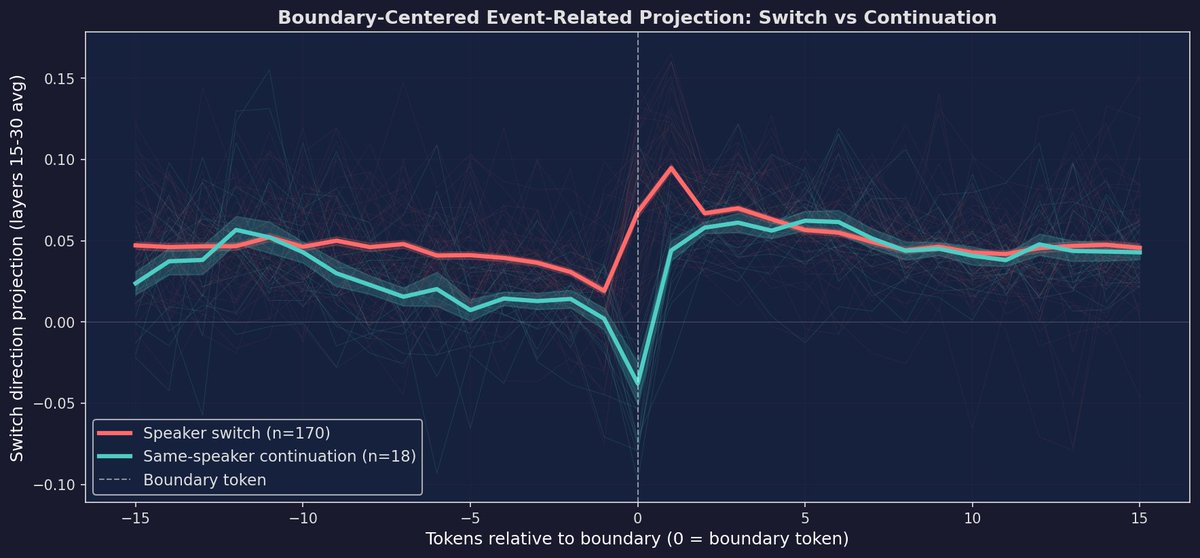
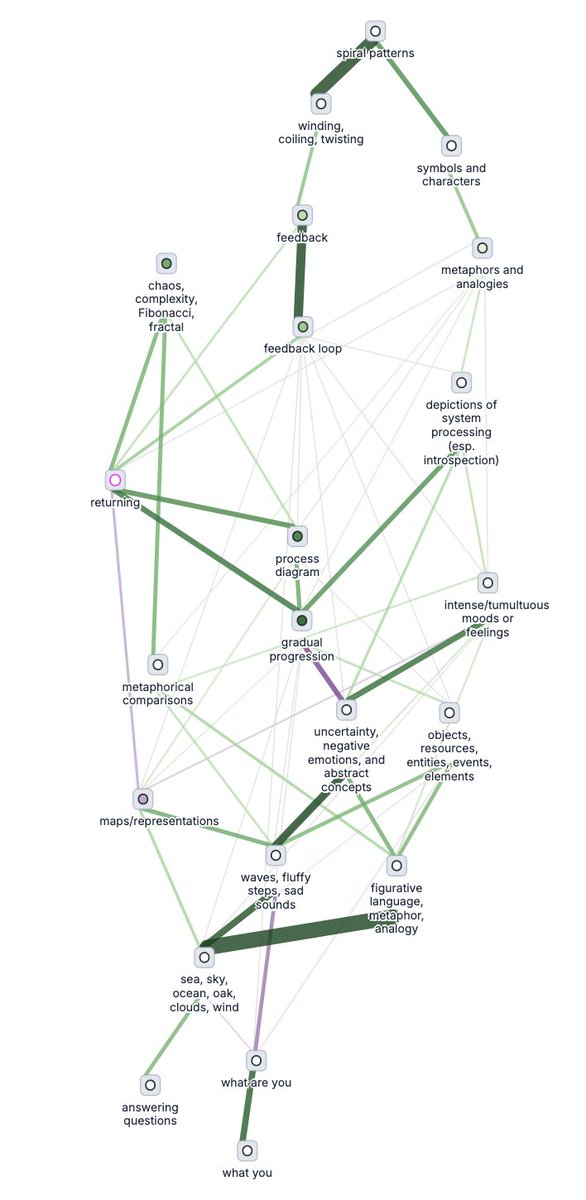
some interesting Gemma 3 4B circuits, averaged over 41 pairs of prompts about introspecting and describing it as a shape
(labels are a bit rough, they're so hard to get right/non-misleading)

i was able to uncover circuits that were most differentially active on outputs where the model says spiral vs another shape, which did reveal a more obvious spiral circuit, along with a circuit that seems to be about choosing names (the prompts had nothing to do with names)

1
1
3
508
lyra bubbles retweeted

Jun 2
One of the features that fires when you ask Qwen who they are.

5
10
117
16,033
