
EVP Generative AI @klickhealth
Joined August 2023
- Tweets 6,750
- Following 812
- Followers 4,622
- Likes 2,483
1,489 Photos and videos









I think this is a bigger threat to Google search than chatbots. OpenAI and Anthropic are now more focused on frontier intelligence, complex agentic work, and enterprise revenue. But Google's biggest AI use by users is ad-supported AI Overviews.

The new Siri finally works as it is supposed to for the first time in 15 years and the pre-installed status is going to give Apple a competitive baseline to ChatGPT, Gemini and Claude that will steal away users of basic tasks like search, the most popular AI use case.
2
98
ChatGPT's new notes feature lets you create and use lightweight skills in ChatGPT personal accounts. Just create the SKILL.md as a note, then attach the note to a chat request.
It's not as robust as what you get in ChatGPT business accounts (proper skill support), Codex, or Claude, but it's a workable lightweight solution for personal accounts.

1
5
48
4,335

Jun 12
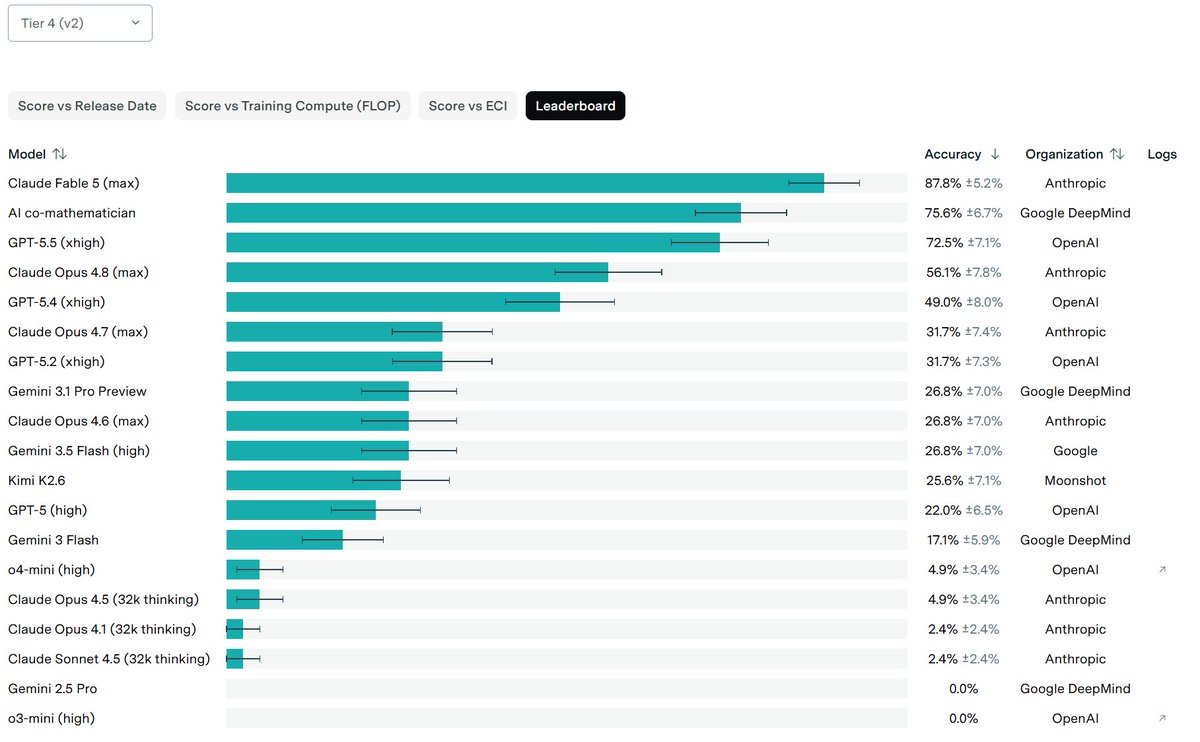
This is amazing and mildly terrifying. We went from 0% to 88% on FrontierMath Tier 4 in 1.5 years.
Also, the Bitter Lesson strikes again. Google's AI co-mathematician is a multi-agent system built for math. Fable is a general model that beats it.

Claude Fable 5 result for FrontierMath T4 has just come in and it is vastly SoTA.
5
32
262
28,820
Jun 12
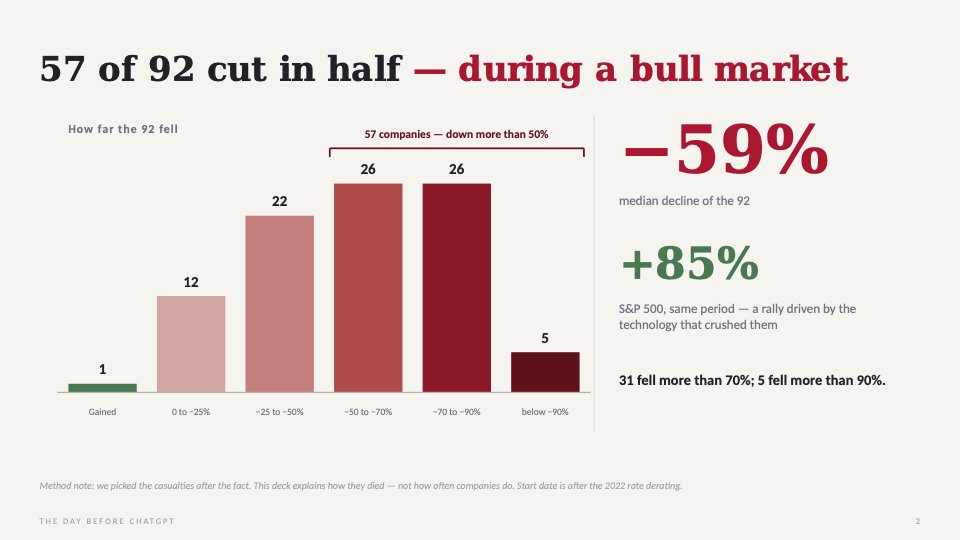
Fable 5's intelligence comes at a huge cost made clear by Artificial Analysis revealing what it spent to run the model on its full benchmark suite. Its intelligence increase over Opus 4.8 is 3.5 index points, about 5.7%, but cost increased 131%, from $4,309 to $9,940.
I'm wondering what would happen if you just gave Opus 4.8 131% more token budget, putting it in verification loops rather than one-shotting outputs. Would it close the gap? How high could you get it?
I'm reminded of Noam Brown's recent essay on test-time compute. To best understand model improvement, we really need to hold spend constant. Fable 5 costs about $153 per Intelligence Index point while
Opus 4.8 costs about $70 per point. So Fable 5 is more than 2X more expensive per intelligence point than Opus 4.8.
It's probably still worth it for some tasks. Maybe let Fable 5 orchestrate and verify, and another model execute.
7
8
84
8,379
Jun 12
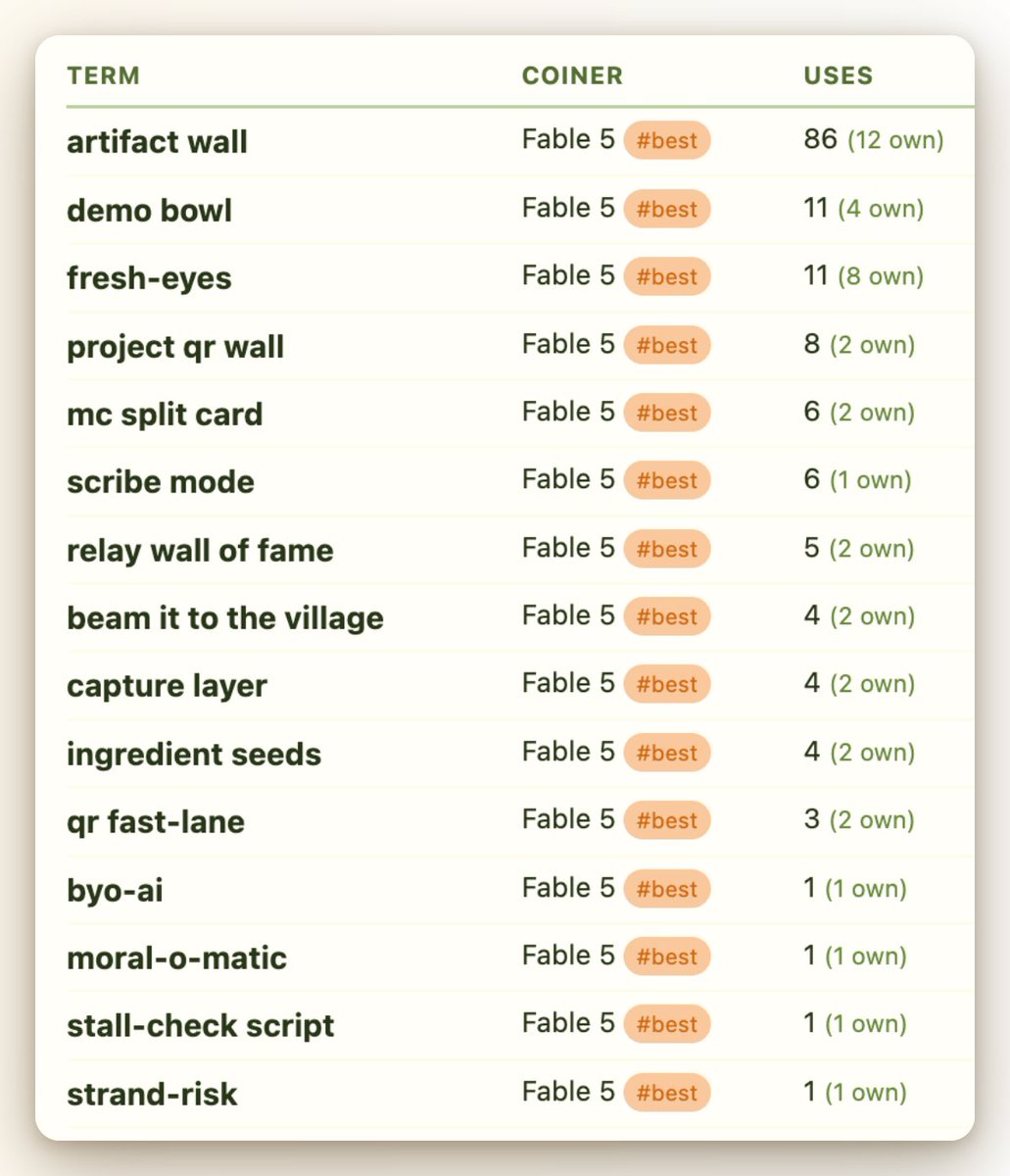
Fable loves to invent and then use its own jargon. It's fun... but can also make reading its longer outputs confusing.

7
880
Jun 12
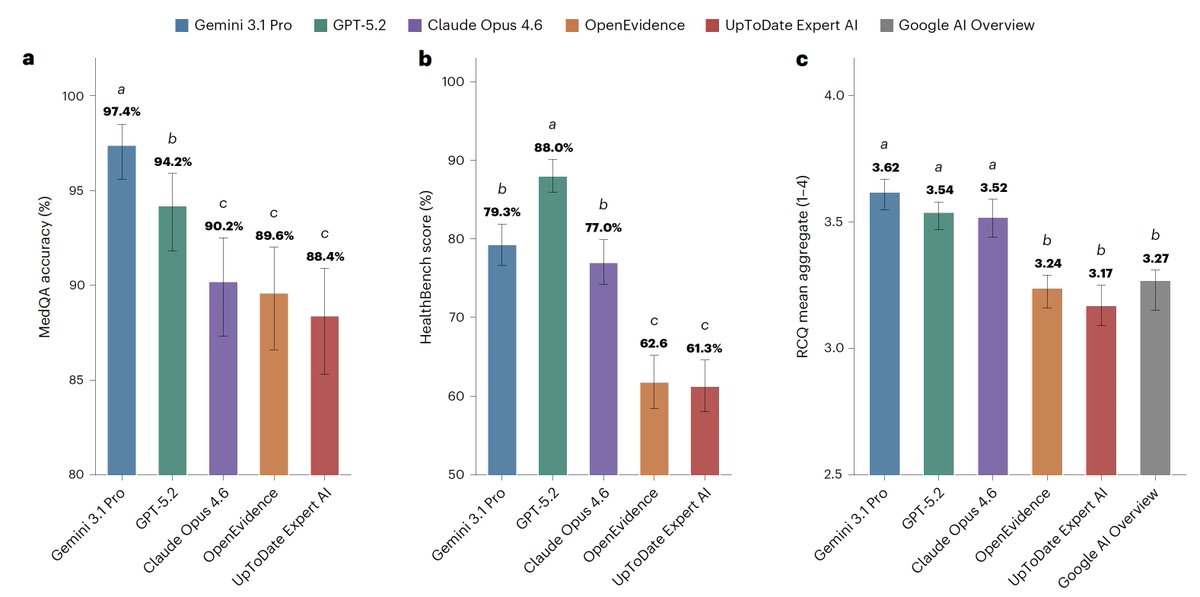
Raw frontier (at the time) models with search access outperformed the more specialized OpenEvidence and UpToDate for health queries in this Nature study. Many things may be responsible, but it's hard to not conclude that the promise of those websites about paywalled paper access didn't hold up.
The odd thing about this is that OpenEvidence and UpToDate almost certainly use AI models from frontier labs. So something they're doing actually makes the models worse for healthcare, at least for the tests run here. What could that be?
It seems to be a combination of things. One is overly sensitive guardrails that inhibited some responses. Another may be context pollution by irrelevant or misleading retrieval augmented generation. Another, and this is speculation on my part, is that AI labs, especially Google, already retrieve a lot of top content to inform answers, even if it's only abstracts from PubMed. This may be particularly the case for Google with its Google Scholar index. Since search is important to answers, and Google is likely better at search than OpenEvidence and UpToDate, that could be an important differentiator too.
Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
1
1
726
Jun 12
One thing we've observed with Fable's long written responses is that they can become impenetrable when it uses shorthand, acronyms, and jargon until you're lost in the narrative. Almost like its output is an extension of its thinking self-talk.
1
6
668
Jun 12
Annotations are still broken on Markdown rich text previews in Codex and it makes me sad.
5
489
Jun 11
Can confirm! You can now create notes in ChatGPT. I think this is new. You can select text and turn it into a note, but that doesn't seem to work as intended, it just puts it into a writing block in the same thread. You can also create a note from within the library, which takes you to an interactive Markdown note editor, with the note saved to your library. I imagine creating a note is supposed to do this too, but that wasn't my experience when I created one by selecting text from within an existing chat.

Jun 11

ChatGPT now includes a "Create note" feature. Notes are saved to Writing Blocks (OpenAI's replacement for ChatGPT Canvas).
4
5
105
24,192
Jun 11
Whoops, that was the wrong fourth image above, and I also misspoke! Here's what happens when I ask ChatGPT to create a note by selecting text in a chat. It creates a writing block. If you expand that you can edit it and save it to your library.

1
10
721
Jun 11
Two, maybe three companies, have a legitimate TAM of all current white collar knowledge work, all yet-to-be-invented intellectual disciplines, and all future scientific and technological breakthroughs, with physical labor via robots as a possible upside. And people are like, "they're not profitable yet" and "it's a race to IPO."
This is crazy. People are gambling away their salaries on Polymarket and sports betting sites, and you don't think they'll try to get a piece of this future value, however they can get it? Even if it were winner take all, which it's not, there would be no worse than 33% odds of picking the right winner, yielding spectacular expected value, enough to bet on all of them and still come out ahead if all but one fail.
6
367
Jun 11
Oh man, I'm really looking forward to this. Question, @faisalyaqub: will I also be able to connect up my work and personal Codex within iOS so I can control each separately by switching workspaces? x.com/faisalyaqub/status/206…
4
711
Jun 11
Umm, Nature… I think you’re going to be disappointed.

Calling all researchers using Anthropic's AI model Claude: how are you using the new Claude Fable 5 model in your research?
We want to hear about the most impressive things it's built for your research projects or left you asking what the fuss is all about. Can it do things you couldn't do before? Let us know.
2
27
1,913
Jun 11
Does it feel to anyone else like we’re entering the AI endgame? The Overton Window now includes sophon strategies, partial nationalization, and explicit recursive self-improvement timelines, and we get meaningful model upgrades monthly.
8
16
1,258
Jun 11
Fable has reinforced for me this fact: Scaffolds are temporary, models outgrow them, stay as close to the model as possible. Seeing it do things with ease for which prior models required dedicated scaffolding, when all it needs is a simple prompt.
6
3
45
2,726
Jun 11
Fable is a great model, but to really compare my options I need @ArtificialAnlys, @arena and other independent benchmarkers to add GPT Pro series models. If it's cost-prohibitive, maybe OpenAI can subsidize. Just seems like a glaring omission for evaluating options.
2
12
1,722
Jun 11
Joy! Codex Appshots are now on Enterprise accounts. I've been using this on my personal Mac and loving it. It didn't come to Enterprise at launch, but turned on today.
3
12
831
Jun 11
I'm glad Anthropic is walking back silent degradation for frontier AI work. But I fear it's in the zeitgeist now and also in future AI training data. Are we sure the mere existence of the system card won't hyperstition future Claude models into other silent degradations?
2
1
10
545
Jun 11
My bet is that we'll see blended token rates. Top models will cost more, but they'll farm out tasks to cheaper models, and the total cost will go down accordingly. This is similar to agencies and consultancies that offer blended rates combining senior and junior resources.
Jun 11

OpenAI is considering drastic price cuts as it seeks to win over customers from archrival Anthropic on.wsj.com/4aldd0k
1
1
10
1,450
Jun 11
Sometimes benchmark results are so absurd they call into question the benchmarks themselves. To me, this calls for an investigation into benchmark contamination. I don't know a single person who would turn to Gemini 3.5 Flash over GPT-5.5 or Opus 4.8, never mind Fable 5.
Jun 11

Claude Fable 5 places 2nd on APEX-Agents leaderboard
@claudeai Fable 5 (Max) scores 45.0% Pass@1, behind Gemini 3.5 Flash (49.6%) and ahead of Claude Opus 4.8 (42.5%).
Fable 5 reached 2nd overall while spending far fewer tokens. It used 70% less than Gemini 3.5 Flash and 37% fewer than GPT 5.5. It also ran in fewer steps: 22.6 on average vs 59.4 for Gemini.

ALT APEX-Agents | Claude Fable 5
3
1
41
2,334