
Cogito, ergo sum
Joined June 2011
- Tweets 5,368
- Following 296
- Followers 1,747
- Likes 3,006
617 Photos and videos








白菜炒馒头 retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,415
575,375


May 2
这玩意看来不分国界

1
115
Apr 30
IMHO, this verbatim C-to-Rust translation is a mistake; it should be approached from the perspective of the program's topology, which, unfortunately, is often incomplete or even incorrect.
Apr 28

Little shoutout to my classic blog post on this very question:
kirancodes.me/posts/log-sins…
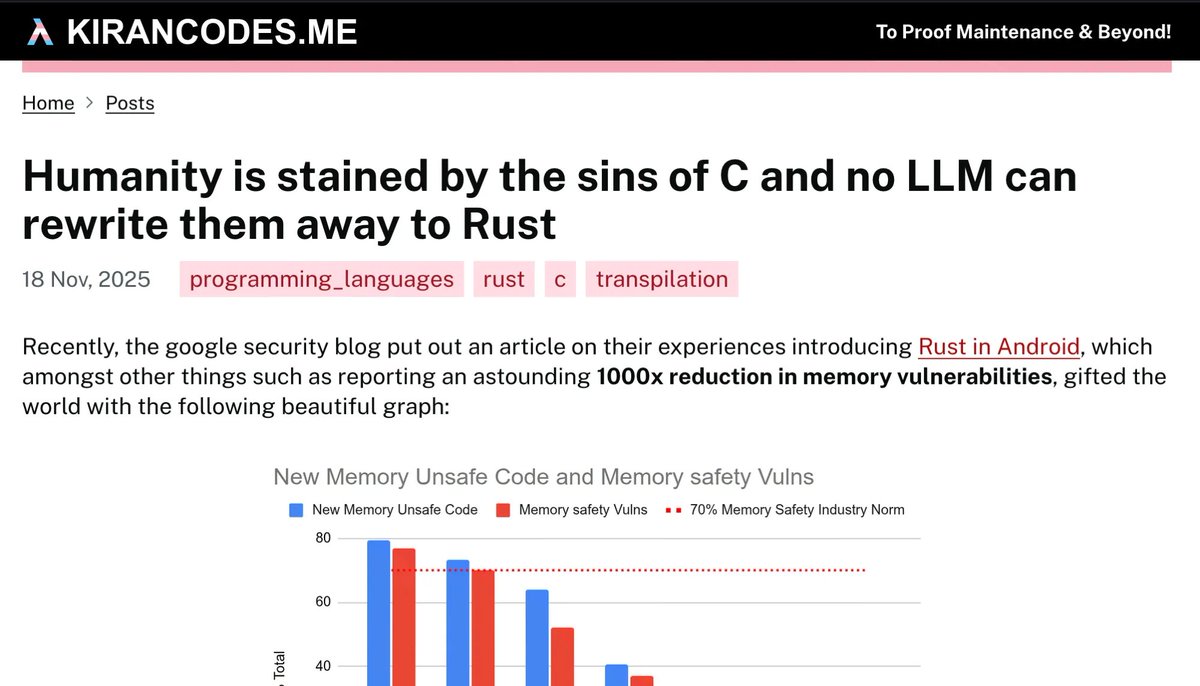
ALT Screenshot of a blog post I've written with the title Humanity is stained by the sins of C and no LLM can rewrite them away to Rust
146
Apr 29
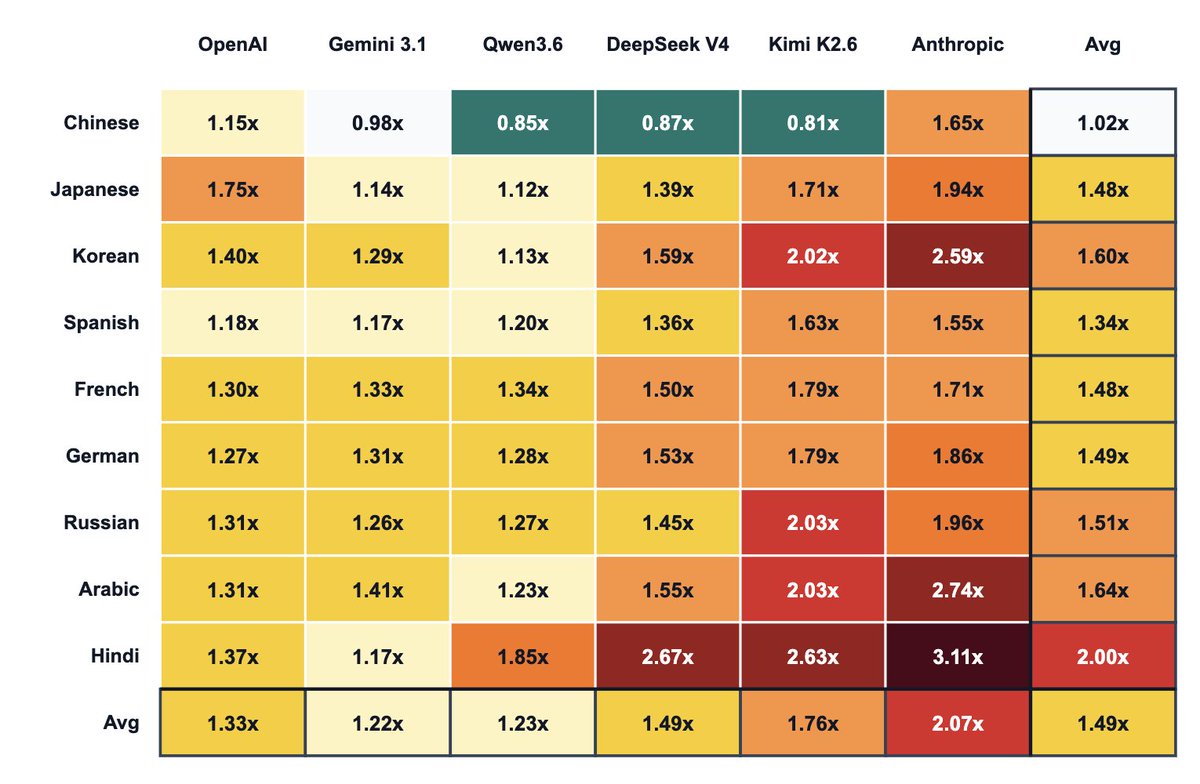
Interesting! Gemini is more friendly toward Chinese than others, especially Anthropic.
Apr 28

Follow-up on non-English token-inefficiency with more model-language pairs:
- Chinese is cheaper than English on major Chinese models
- Gemini and Qwen provide least non-English tax
- Anthropic has the highest tax by far; Kimi is next
- Hindi is the worst-covered language here, despite its massive speaker base
1
155
白菜炒馒头 retweeted

Apr 18
Dario is wrong.
He knows absolutely nothing about the effects of technological revolutions on the labor market.
Don't listen to him, Sam, Yoshua, Geoff, or me on this topic.
Listen to economists who have spent their career studying this, like @Ph_Aghion , @erikbryn , @DAcemogluMIT , @amcafee , @davidautor

Anthropic CEO Dario Amodei: “50% of all tech jobs, entry-level lawyers, consultants, and finance professionals will be completely wiped out within 1–5 years.”
1,214
2,752
21,293
4,074,642
Apr 18
For currying, there is no need using a number; for functional, there is no need using a function. Currying(with only one variable) is equal to Functional.
67

见证历史了。
Apr 9

이게 사실인지, 사실이라면 어떤 조치가 있었는지 알아봐야겠습니다.
우리가 문제삼는 위안부 강제, 유태인 학살이나 전시 살해는 다를 바가 없습니다.
3
3
35
52,124
Mar 17
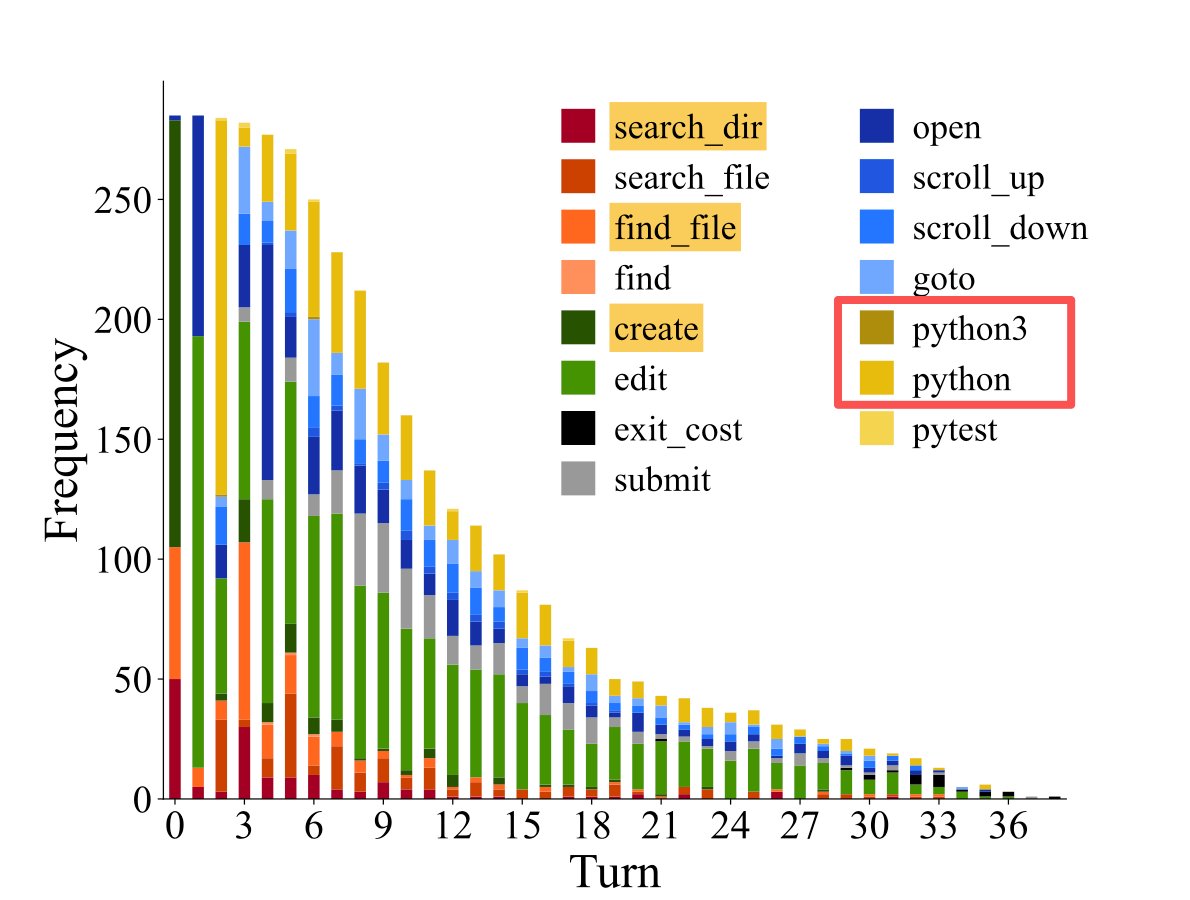
I wonder how many tokens are wasted due to the python version nightmare?!
158
Mar 17
feeling proved!
Mar 16

🤯BREAKING: Alibaba just proved that AI Coding isn't taking your job, it's just writing the legacy code that will keep you employed fixing it for the next decade. 🤣
Passing a coding test once is easy. Maintaining that code for 8 months without it exploding? Apparently, it’s nearly impossible for AI.
Alibaba tested 18 AI agents on 100 real codebases over 233-day cycles. They didn't just look for "quick fixes"—they looked for long-term survival.
The results were a bloodbath:
75% of models broke previously working code during maintenance.
Only Claude Opus 4.5/4.6 maintained a >50% zero-regression rate.
Every other model accumulated technical debt that compounded until the codebase collapsed.
We’ve been using "snapshot" benchmarks like HumanEval that only ask "Does it work right now?"
The new SWE-CI benchmark asks: "Does it still work after 8 months of evolution?"
Most AI agents are "Quick-Fix Artists." They write brittle code that passes tests today but becomes a maintenance nightmare tomorrow. They aren't building software; they're building a house of cards.
The narrative just got honest: Most models can write code. Almost none can maintain it.

136
Mar 16
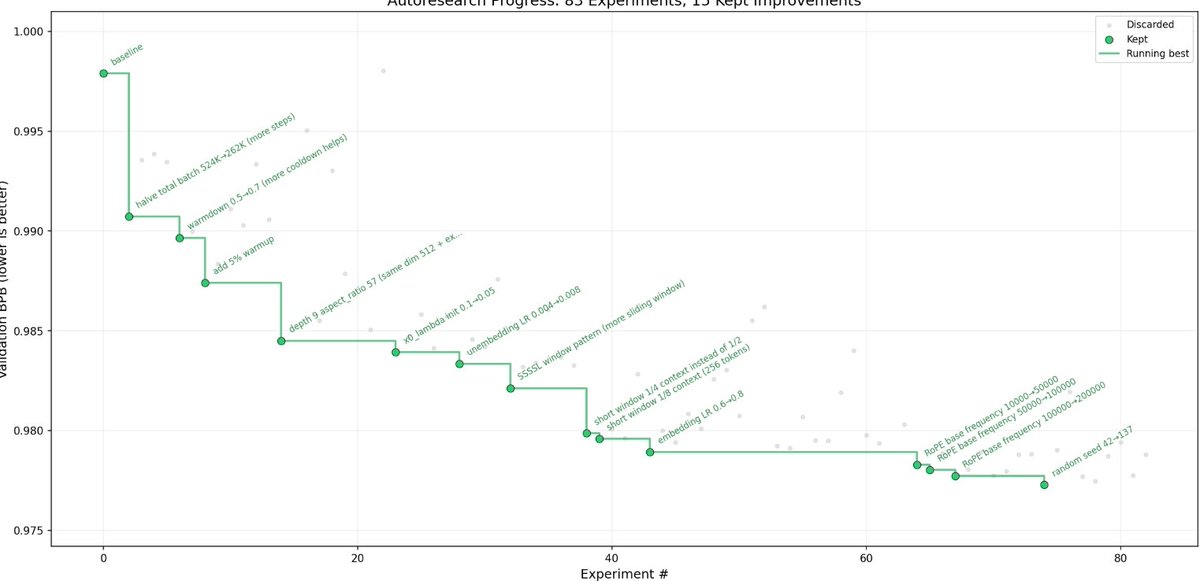
A small experiment with #autoresearch, in 30 hours it tried nearly 80 times, find 17 improvements and the loss dropped nearly 77%, which equals to 5 days work of a middle-level researcher.
CONS: 1. only works on single GPU 2. only supports one metric
1
267
Feb 28
说几个跟业界不一样的结论, 春节全假期高强度“人机结对编程”实战,深入实践下来, 谨慎地说, 目前还远称不上范式转移, 但耗时分布发生了剧烈左移. 有了大模型最耗时的不是编码, 或者说有大模型之前最耗时也不在编码. 不过之前是在编码中思考和深化设计, 现在是将这个过程从编码中独立出来了.#sumscale
3
1
257
Feb 28
3、常识, 大模型依然缺少常识, 比如 AI 科技新闻不先去 x.com 扒拉, 某些名人有自己博客的也不首先采纳参考, 这都是没有常识. 要想用好大模型需要基于信息世界抽取慢变量构建常识数据库, 这也是一种对 agent 提供服务.
1
89
Feb 28
4、两个成本, 时间成本与 token 成本. 无限的时间和无限的 tokens, 能大力出奇迹.
无论如何, 这都是一次巨大的进步, 尤其在开发一些“陌生但成熟”的系统的时候.
1
63