
a tiny schemer. engineering @trydaily and @pipecat_ai core maintainer.
Joined November 2009
- Tweets 1,747
- Following 66
- Followers 507
- Likes 1,855
241 Photos and videos











Voice AI Meetup, Thursday May 7th. This one's a special crossover event. T-Bot, who hosts the global Voice AI Spaces meetups, is visiting San Francisco and will MC!
- NVIDIA researchers will present some of their really cool recent work on speech models.
- We'll have demos and two fireside chats, featuring new developments in models and evals, with @GradiumAI, @ArtificialAnlys, @ServiceNow, and @pipecat_ai.
- And, of course, 🍕 and great conversation.
- Thanks to the @trychroma team for hosting in their wonderful office/event space.
Registration link below. Come hang out with 150 old and new friends!

2
7
39
6,890
Sub-agents in (latent) space!
We’ve been working on a side project.
As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard.
This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time.
So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you.
Some of the things we’ve been thinking about as we hack on Gradient Bang:
- Sub-agent orchestration
- Partial context sharing between multiple LLM inference loops
- Managing very long contexts, and episodic memory across user sessions
- World events and large volumes of structured data input as part of human/agent conversations
- Dynamic user interfaces, driven/created on the fly by LLMs
- And, of course, voice as primary input
If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too!
This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
139
263
2,603
453,480


Sub-agents in (latent) space!
We’ve been working on a side project.
As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard.
This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time.
So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you.
Some of the things we’ve been thinking about as we hack on Gradient Bang:
- Sub-agent orchestration
- Partial context sharing between multiple LLM inference loops
- Managing very long contexts, and episodic memory across user sessions
- World events and large volumes of structured data input as part of human/agent conversations
- Dynamic user interfaces, driven/created on the fly by LLMs
- And, of course, voice as primary input
If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too!
This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
61
Join us on Thursday in SF for conversations about voice agents, speech models, and realtime AI infrastructure.
I'm on a panel with:
- @natrugrats from @DeepgramAI
- @farazmsiddiqi from @getbluejay_ai
- Aaron Lee from Parakeet Health
There will be food and lots of opportunities to ask questions and share your knowledge.
One thing I'm looking forward to is comparing notes about GTC last week.

2
9
13
2,245
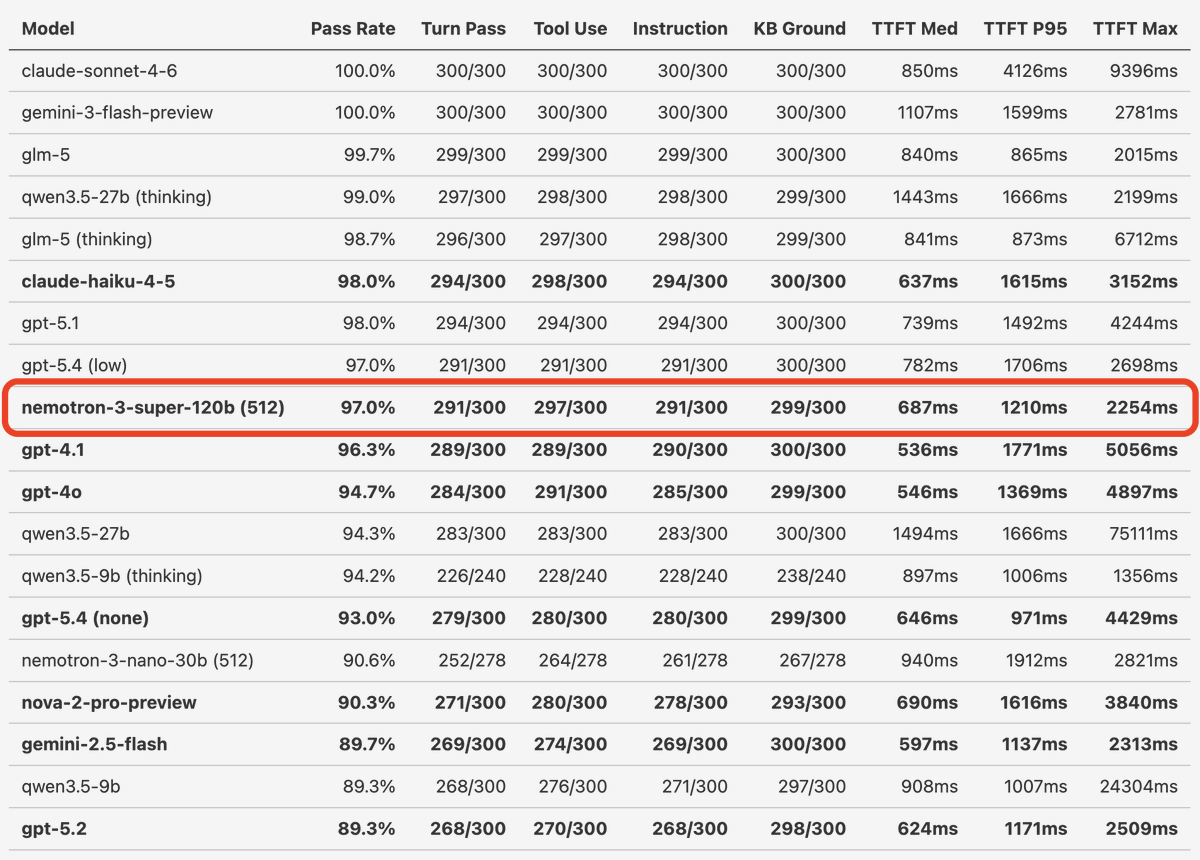
NVIDIA Nemotron 3 Super launches today! We've been building voice agents with Super's pre-release checkpoints and running all our various tests and benchmarks.
Nemotron 3 Super matches both GPT-5.4 and GPT-4.1 in tool calling and instruction following performance on our realtime conversation, long context, real-world benchmarks. GPT-4.1 is the most widely used LLM today for production voice agents. So an open model that performs as well as GPT-4.1 on hard, voice-specific benchmarks is a big deal.
(Side note: we don't think a benchmark "tells the story" about a model's voice agent performance unless it tests model correctness across at least 20 human/agent conversation turns.)
The Nemotron models are *fully* open: weights, data sets, training code, inference code.
Nemotron 3 Super is 120B params, with a hybrid Mamba-Transformer MoE architecture for efficient inference. You can run it on NVIDIA data center hardware or on a DGX Spark mini-desktop machine.
1M token context.
Blog post with full benchmarks, thinking budget notes, inference setup on @Modal, and where we think this goes next. 👇
14
33
236
20,192
Hi @Microsoft ! Can you help me recover my son's account? He can't sign-in to Minecraft anymore which (as you can imagine) is a big deal. Still waiting to hear back from account.live.com/acsr. I’d really appreciate any help. Happy to continue via DM.
10
109
This is just too fun!
One of my 2026 predictions is that we're going to see a lot of interesting new experiments with LLM-powered games. There are just so, so many possibilities. The main barrier is inference cost. But that's dropping fast.
My friends Vanessa and Sunah have been tinkering with a voice game called Crush Quest.
Crush Quest has multiple characters, a bunch of really good prompting, and you can play on the web or (clone the repo and) wire up a telephone number. It's, you know, totally open source and that's radical.
As you can maybe tell from my hip use of slang, Crush Quest is set in the early 1990s. It's an homage to a classic electronic board game called Dream Phone. Check out the thread below for a link to the most perfectly 1991 TV commercial for Dream Phone. I can taste the Lucky Charms when I watch this commercial.
h/t to @chelcietay who I had a great conversation with recently about our 2026 predictions and where social and gaming is going.
1
65
Voice-controlled UI.
This is an agent design pattern I'm calling EPIC, "explicit prompting for implicit coordination." Feel free to suggest a better name. :-)
In the video, I'm navigating around a map, conversationally, pulling in information dynamically from tool calls and realtime streamed events.
There are two separate agents (inference loops) here: a voice agent and a UI control agent. They know about each other (at the prompt level) but they work independently.
19
28
402
14,085
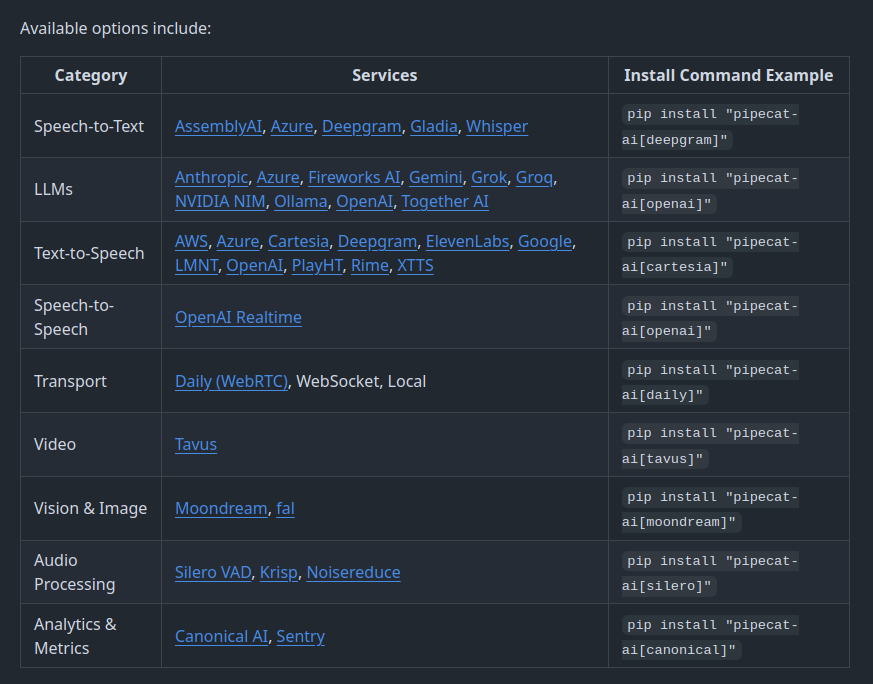
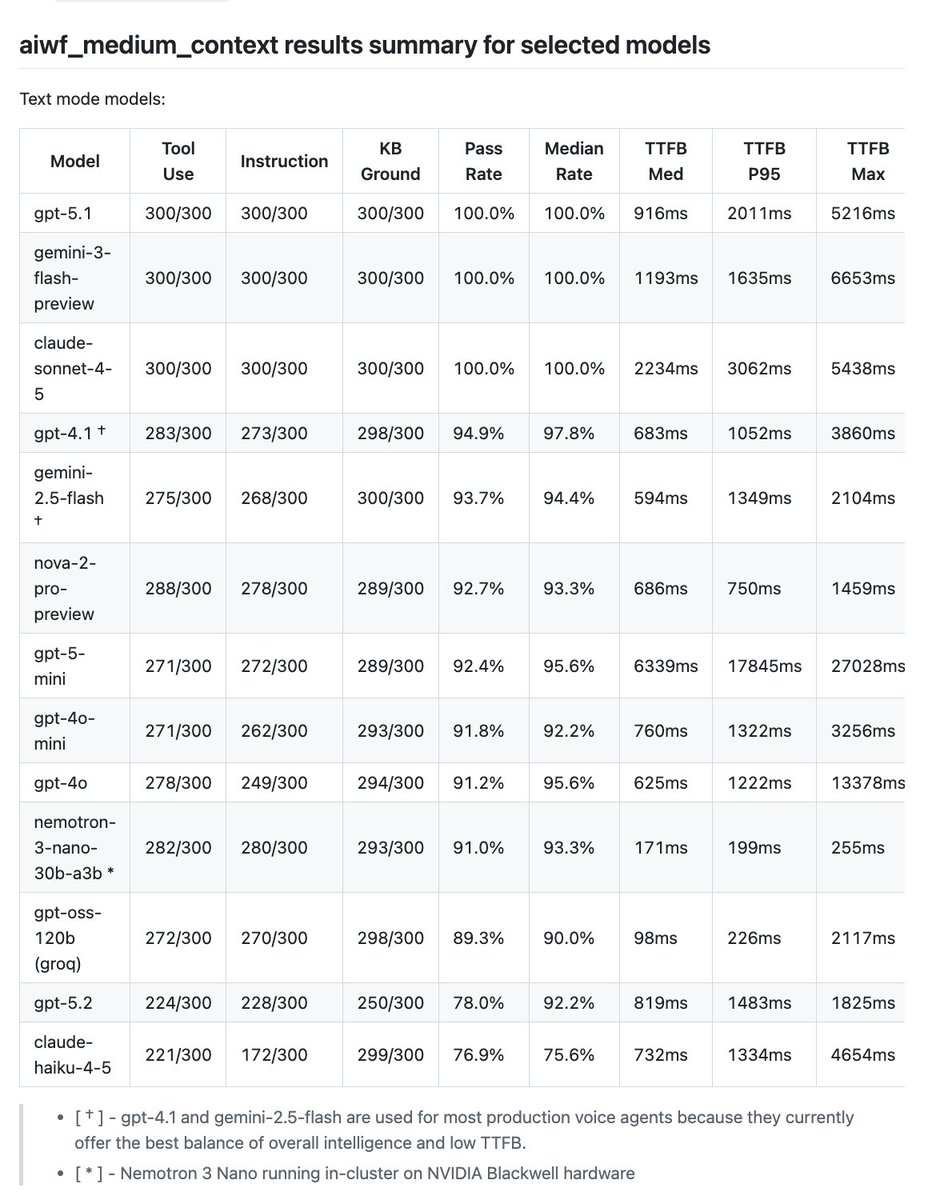
Benchmarking LLMs for voice agent use cases. New open source repo, along with a deep dive into how we think about measuring LLM performance.
The headline results:
- The newest SOTA models are all *really* good, but too slow for production voice agents. GPT-4.1 and Gemini 2.5 Flash are still the most widely used models in production. The benchmark shows why.
- Ultravox 0.7 shows that it's possible to close the "intelligence gap" between speech-to-speech models and text-mode LLMs. This is a big deal!
- Open weights models are climbing up the capability curve. Nemotron 3 Nano is almost as capable as GPT-4o. (And achieves this with only 30B parameters.) GPT-4o was the most widely used model for voice agents until quite recently, so a small open weights model scoring this well is a strong indication that production use of open weights models will grow this year.
Voice agents are a moderately "out of distribution" use case for all of our SOTA LLMs today. Literally, in the sense that there's not enough long, multi-turn conversation data in the training sets.
Everyone who builds voice agents knows this intuitively, from doing lots of manual testing. (Vibes-based evals!) This benchmark scores LLMs quantitatively on instruction following, tool calling, and knowledge retrieval in long-context, multi-turn conversations.
8
19
99
7,620
Pipecat MCP Server now works with local STT (Whisper) and TTS (Kokoro) models! Happy talking! @pipecat_ai
github.com/pipecat-ai/pipeca…
1
1
4
386
Voice-only programming with Claude Code ...
I've been playing with @aconchillo's MCP server that lets you talk to Claude Code from anywhere, today. I always have multiple Claudes running, and I often want to check in on them when I'm not in front of a computer.
Here's a video of Claude doing some front-end web testing, hitting an issue and getting input from me, and then reporting that the test passed.
In the video the Pipecat bot is using Deepgram for transcription and Cartesia for the voice. (Note: I sped up the web testing clickety-click sections of the video.)
The code for the MCP server and the Claude skill are in the repo and Aleix wrote a really good README.md.
You can use any of Pipecat's network transports: generally WebRTC, but you could set this up so you can call Claude on the phone if you wanted to.
There's screen capture support, too, so you can view the Claude code window remotely. That's still a little experimental.
Because this is an MCP server, it's not specific to Claude Code. Try it in other environments! It should work in Clawdbot, Codex, etc ...
7
5
37
2,119
Pipecat Cloud is @trydaily's enterprise hosting platform for open source voice agents. Today, after a 9-month beta period, we're promoting Pipecat Cloud to General Availability!
With Pipecat Cloud, you build your voice agent on @pipecat_ai’s open source, vendor neutral core, add your custom code and agent logic, and then “docker push” to Pipecat Cloud.
As with everything we do, Pipecat Cloud is engineered to give you flexibility, to not lock you into any service, including Pipecat Cloud itself. Any code that you can host on Pipecat Cloud you can self-host with no changes at all.
We've focused on delivering:
- fast agent start times (P99 <1s)
- multi-region hosting
- optimized global network transport
- direct connectivity to Twilio, Telnyx, Plivo, Exotel and other telephony providers.
- built-in @krispHQ VIVA models for noise reduction and turn detection
- integrations with all the AI services, observability tools, and everything else supported by Pipecat
You can sign up and "pipecat cloud deploy" immediately. We also have enterprise support contracts and can work with you to deploy a single-tenant, enterprise version of Pipecat Cloud in your VPC. Feel free to contact us if you have questions.

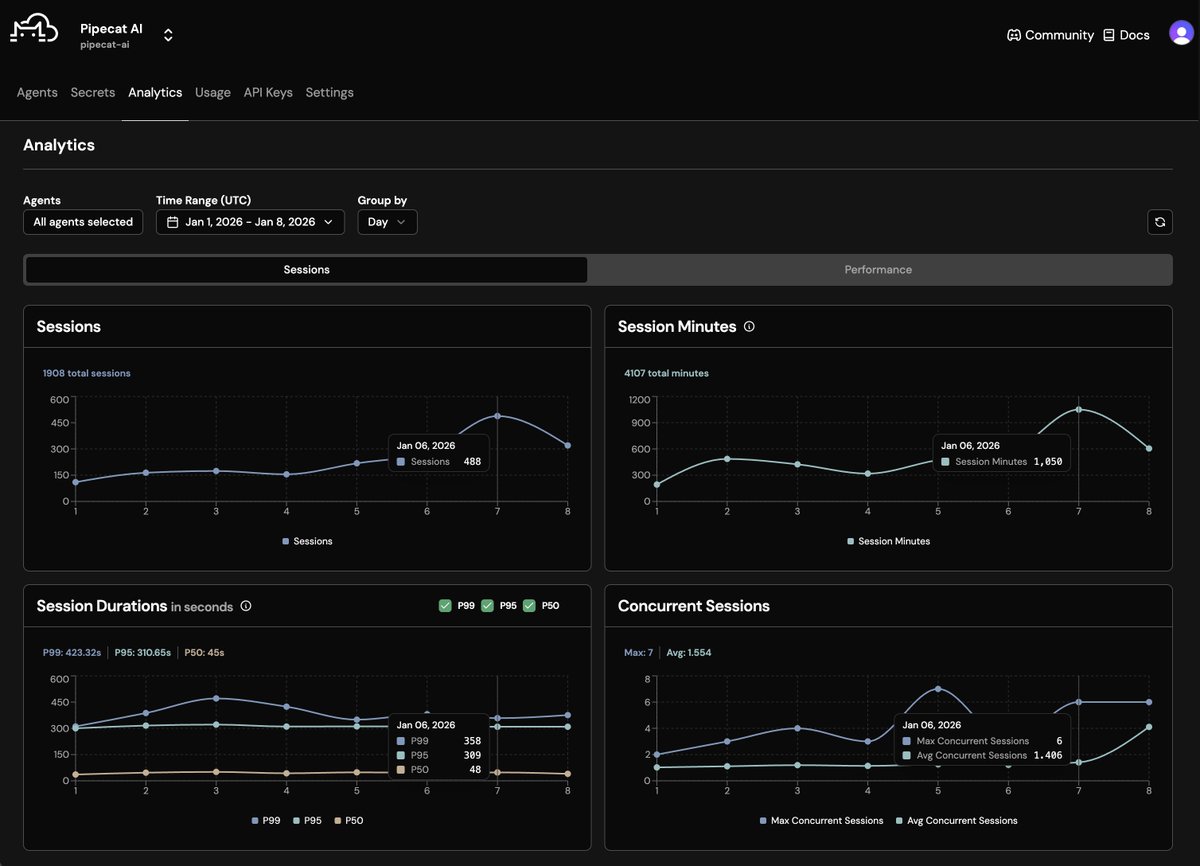
4
6
29
1,286

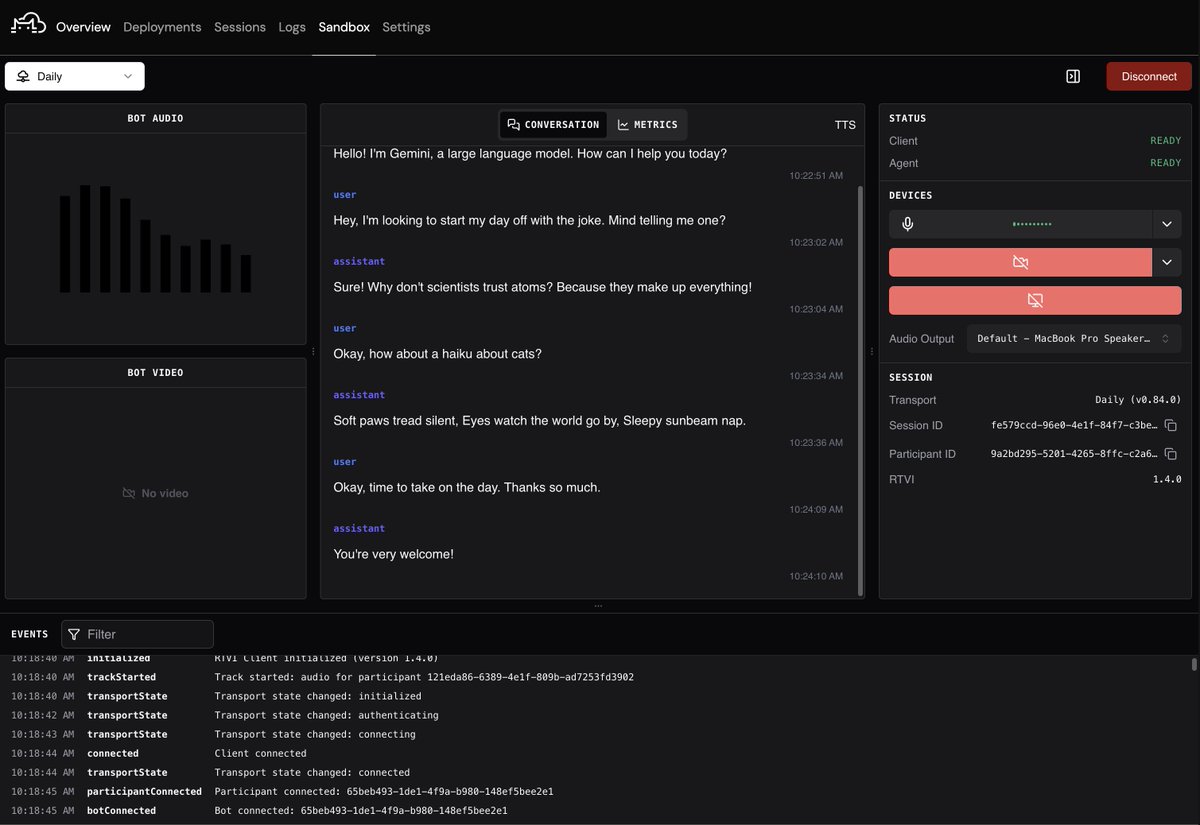
Pipecat Cloud is now generally available.
Pipecat Cloud is a managed, vendor-neutral platform for deploying and scaling open source voice agents, with ultra-low latency, multi-region support, and enterprise-grade realtime infrastructure. Thank you to the more than 1,000 teams that built and scaled with Pipecat Cloud during the platform beta.


1
3
9
311
🎉 We are proud to support @nvidia's new Nemotron models, announced today at CES2026.
We've been building high-performance voice agents with the new NVIDIA Nemotron Speech ASR model and integrating this model into Pipecat.
Nemotron Speech ASR is completely open (weights, training data, inference tools), designed from the ground up for low-latency use cases like voice agents, and scores very well on our benchmarks. It also runs cost-effectively at large scale. Congratulations to the NVIDIA team on their open model breakthroughs and stay tuned for news all week from CES.
Learn More: blogs.nvidia.com/blog/open-m…
2
7
926
This robot assistant from the NVIDIA CES Keynote on Monday is going viral.
@NaderLikeLadder explains all the hottest emerging AI trends in one demo: AI applications in 2026 will be multi-model, multi-modal, hybrid cloud/local, use open source models as well as proprietary models, control robots and embedded devices in the physical world, and have voice interfaces. (And the demo had a cute robot *and* a cute dog. Gold.)
The demo was built with @pipecat_ai. NVIDIA posted a really nice technical walk-through and complete code. The Reachy Mini robot from @huggingface is open source hardware. (You can order it now, I have one!). You can run the assistant locally on your own hardware, in the cloud, or both.
26
98
493
48,957
NVIDIA just released a new open source transcription model, Nemotron Speech ASR, designed from the ground up for low-latency use cases like voice agents.
Here's a voice agent built with this new model. 24ms transcription finalization and total voice-to-voice inference time under 500ms.
This agent actually uses *three* NVIDIA open source models:
- Nemotron Speech ASR
- Nemotron 3 Nano 30GB in a 4-bit quant (released in December)
- A preview checkpoint of the upcoming Magpie text-to-speech model
These models are all truly open source: weights, training data, training code, and inference code. This is a big deal! Jensen said in the CES keynote yesterday that he expects open source models to catch up to proprietary models this year in a number of categories. NVIDIA is putting their weight behind making this happen. (As Alan Kay said, the best way to predict the future is to invent it.)
The code for this agent is open source too, of course. You can deploy it to production with @modal and @pipecat_ai cloud, or run locally on an @nvidia DGX Spark or RTX 5090.
84
450
3,571
274,212
I've been playing with the new Lemon Slice realtime video avatar model that launched today. Here's a clip of a couple of avatars I created: a cartoon astronaut and a guide for the space game side project I've been hacking on.
The guide avatar supports the Lemon Slice /imagine command, which changes the video on the fly. You can see my type "/imagine a working space suit with tools and velcro patches and stuff" and see what the Lemon Slice model does with that prompt!
The idea for the astronaut character was to create something that felt like a fully realized cartoon animation. I used Nano Banana to create the character image, then used that image as the basis for the Lemon Slice avatar. I'm a big fan of models that can do cartoon and non-photorealistic avatars really well. I think there's a lot of interesting terrain to explore in this direction and would love to see talented designers create environments that emphasize imagination rather than "virtual reality."
For the second character, I fired up Claude Code in the repo for the Gradient Bang game, and asked it to create an LLM prompt for a guide for newbies:
> Create a prompt for an LLM that will guide new players in the Gradient Bang game universe. Include basics about the game, and good strategies for players who are just starting out. Include enough detail that you can answer questions about game mechanics and strategy. Make the prompt about 15 paragraphis long.
Lots more information about what the model can do, in the launch thread below ...
4
4
39
3,587
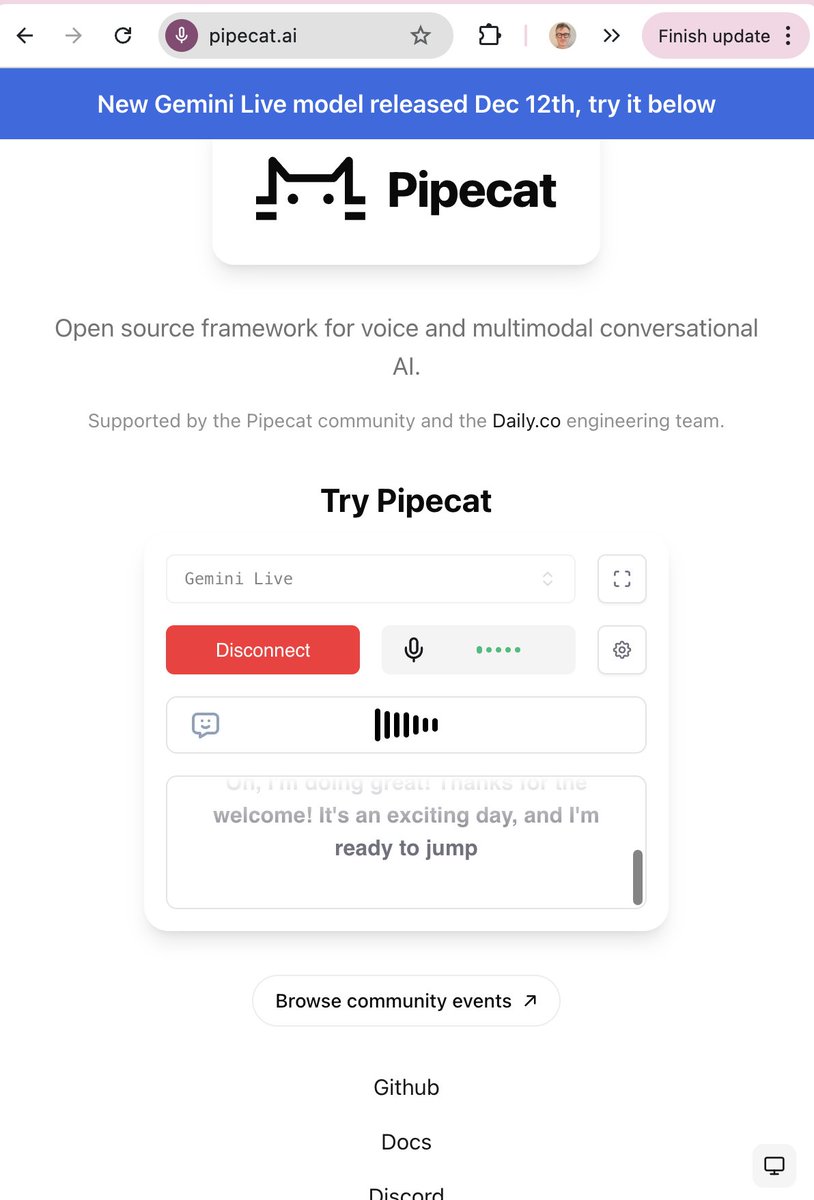
New Gemini Live (speech-to-speech) model release today.
Using the Google AI Studio API, the model name is: gemini-2.5-flash-native-audio-preview-12-2025
The model is also GA (general availability, so not considered a beta/preview release) on Google Cloud Vertex under this model name: gemini-live-2.5-flash-native-audio
Try it out on the @pipecat_ai landing page.
16
40
341
24,825
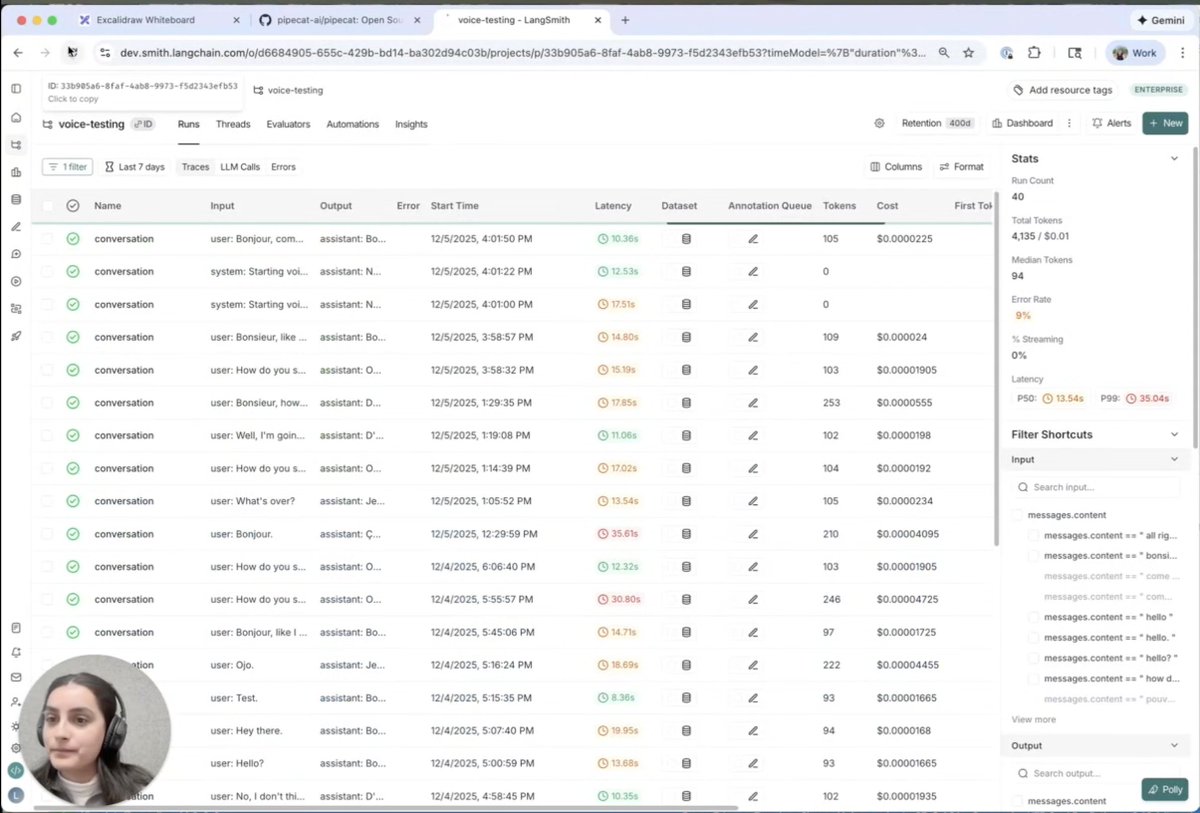
The team at @langchain built voice AI support into their agent debugging and monitoring tool, LangSmith.
LangSmith is built around the concept of "tracing." If you've used OpenTelemetery for application logging, you're already familiar with tracing. If you haven't, think about it like this: a trace is a record of an operation that an application performs.
Here's a very nice video from @_tanushreeeee that walks you through building and debugging a voice agent with full conversation tracing.
Using the LangSmith interface you can find a specific agent session, then dig into what happened during each turn of the conversation. What did the user say and how was that processed by each model you're using in your voice agent? What was the latency for each inference operation? What audio and text was actually sent back to the user?
Today's production voice agents are complex, multi-model, multi-modal, multi-turn systems! Tracing gives you leverage to understand what your agents are doing. This saves time during development. And it's critical in production.
Tanushree shows using a local (on-device) model for transcription, then switching to using the OpenAI speech-to-text model running in the cloud. You can see the difference in accuracy. (Using Pipecat, switching between different models is a single-line code change.)
Also, the video is fun! It's a French tutor. Which is a voice agent I definitely need.


3
15
41
2,395
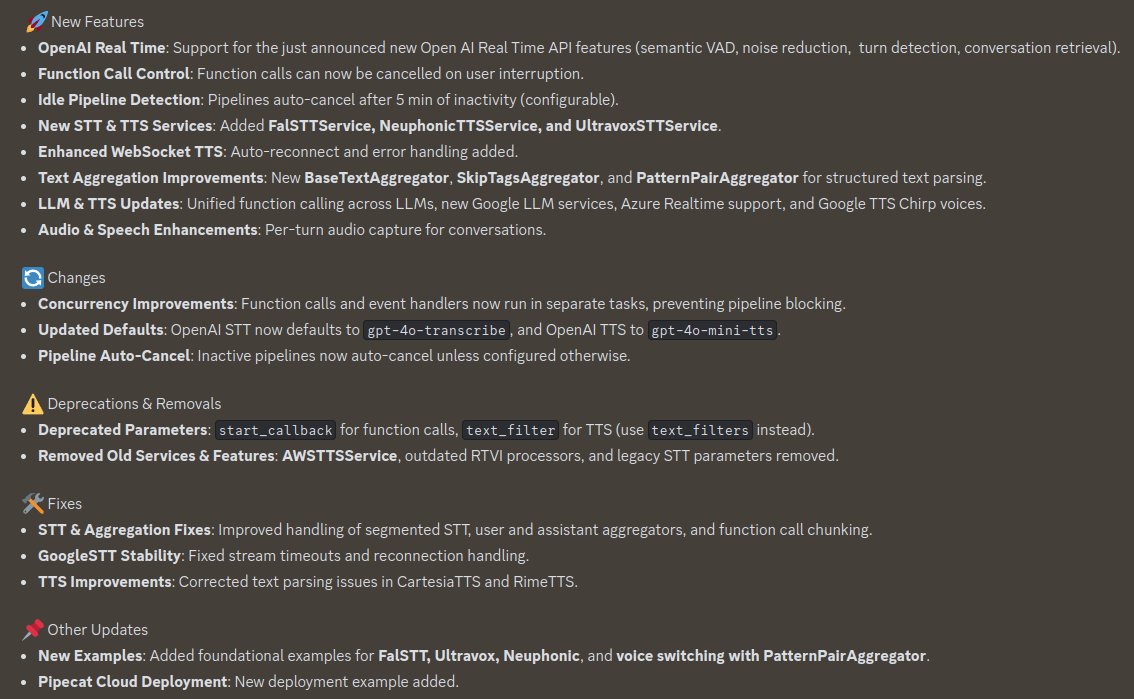
Pipecat 0.0.97 release. Some highlights:
Support for @GradiumAI's new speech-to-text and text-to-speech models. Gradium is a voice-focused AI lab that spun out of the non-profit Kyutai Labs, which has been doing architecturally innovative work on neural codecs and speech-language models for the last two years.
Continued improvements in the core text aggregator and interruption handling classes, both to fix small corner cases and to make behavior as configurable as possible. This is the kind of often-invisible work that underpins Pipecat's ability to support a wide range of models and pipeline "shapes." Models stream (or don't stream) tokens differently. Different use cases need to make different engineering trade-offs in the service of natural, low-latency interactions.
Similarly, continued steps towards full support of reasoning models. Mostly, reasoning models haven't been used in voice AI pipelines, because we are generally prioritizing low latency. But, increasingly, we are using multiple models in parallel in voice agents. Thinking fast and slow, as it were. Using reasoning models requires updating `LLMContext` abstractions to thread thought signatures into the conversation context, and handling function call internals slightly differently.
Access to word timestamps from the @cartesia speech-to-text model.
The Smart Turn model service now defaults to the new v3.1 weights and uses the full current utterance rather than only the most recent fragment.

4
10
53
4,883