
Joined February 2009
- Tweets 630
- Following 996
- Followers 547
- Likes 5,039
18 Photos and videos






Pinned Tweet

22 Oct 2025
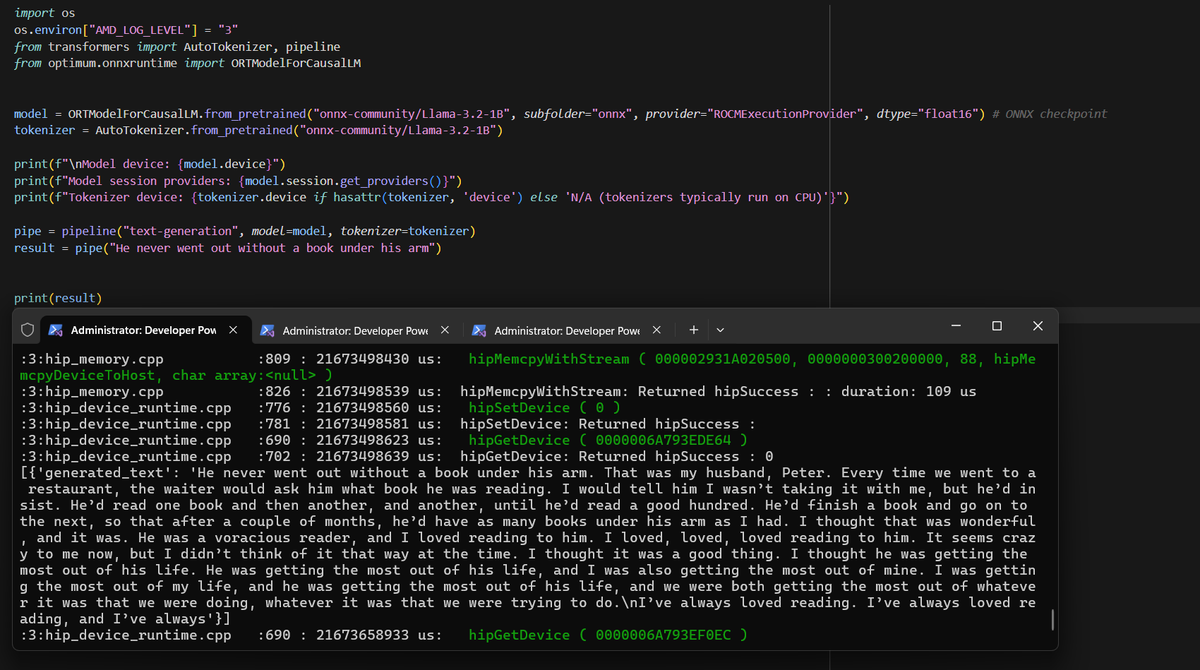
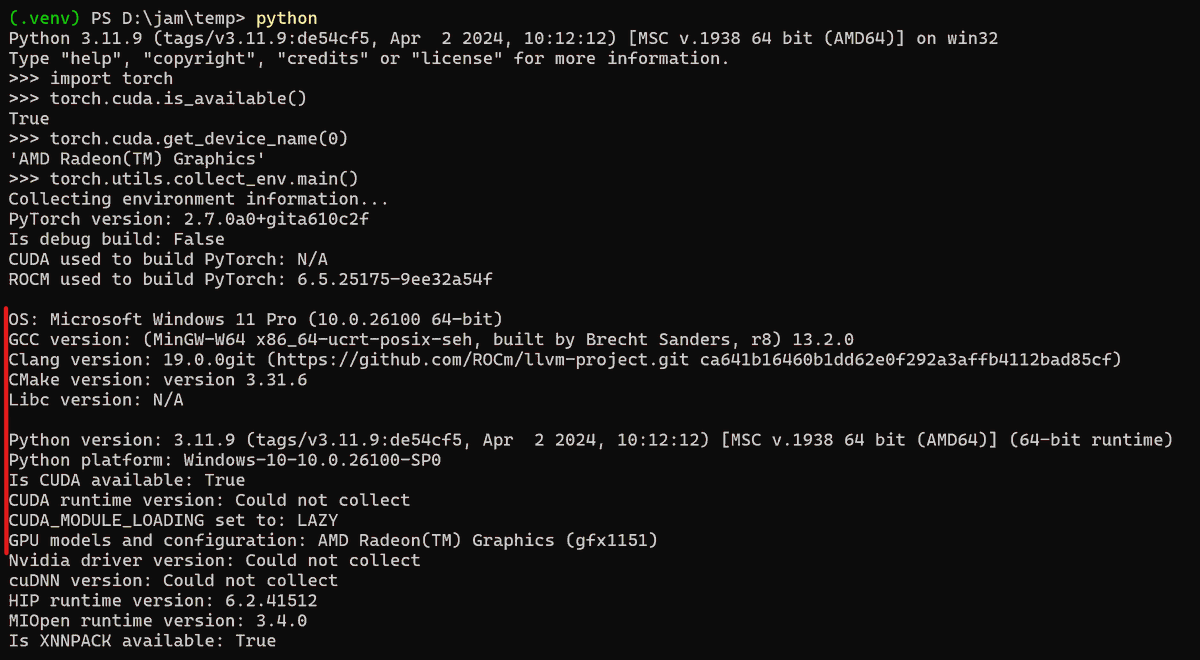
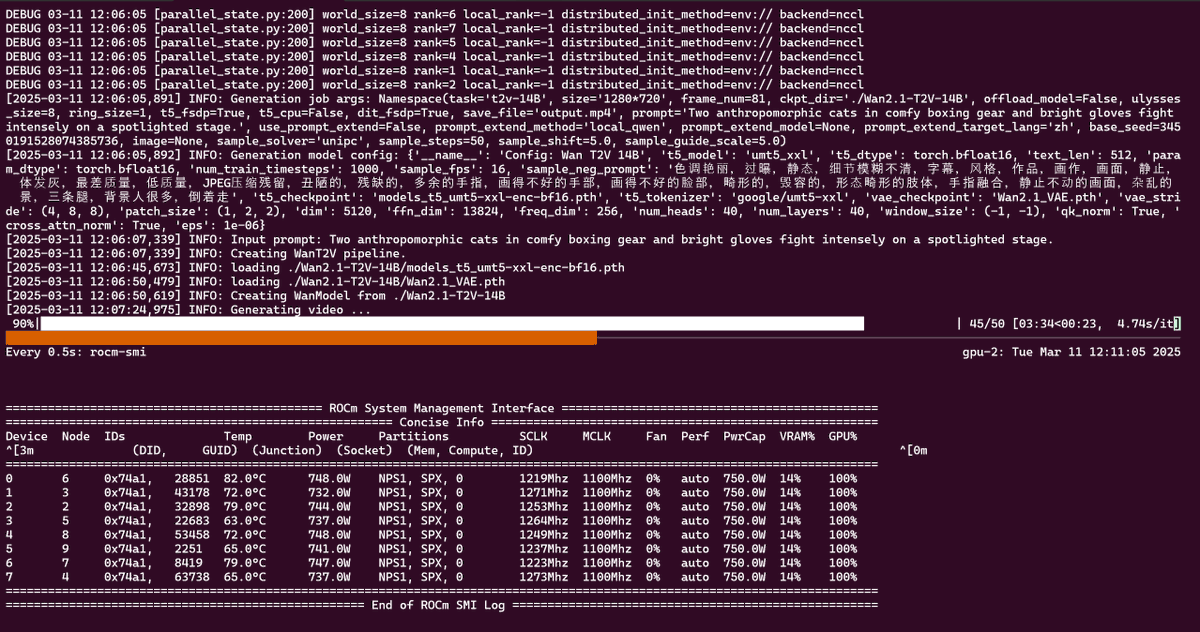
Super happy to see this :) all those late nights fixing and getting ROCm PyTorch running on Strix Halo with @scottttw
on TheRock have finally paid off 🥲 x.com/AnushElangovan/status/…
It's now ready and widely available. This is just the beginning, and we're just getting started!
22 Oct 2025

Local [Superintelligence Supercomputing] Signed by @LisaSu 💻 🚀🚀🚀
Ryzen AI Max PRO 395 (Strix Halo) with ROCm
* runs GPT-OSS locally
* runs Battlefied 6 like a desktop
* 16x Zen5 cores for builds
@sama @gdb Sarah As promised please tag me if you run into any issues 🤙

3
710

Generative AI gives answers. Agentic AI executes work but it needs more than just fast answers.
That shift changes the infrastructure equation. As agents scale, customers need CPU-rich infrastructure that can support more orchestration, retrieval, APIs, databases, caches, containers, VMs and workflows at rack scale.
That is where AMD EPYC processors are built to deliver the highest performing CPUs for the next era of AI: bit.ly/4ef992W

9
26
225
38,971
Aaryaman "Jam" Vasishta retweeted

192GB Unified Memory: @AMD Ryzen AI Max 400 Series supports models that are too big for N1X silicon

19
21
208
25,850
AMD Ryzen AI Max is available now.
16 cores. 32 threads. 40 compute units. 50 TOPS NPU. Up to 128GB unified memory.
Built on x86, it brings breakthrough local AI performance to the enterprise and developer workflows teams already use. No translation layer, no performance penalty, no workflow disruption.

64
118
1,016
153,425
Aaryaman "Jam" Vasishta retweeted

May 29
🚀🚀🚀

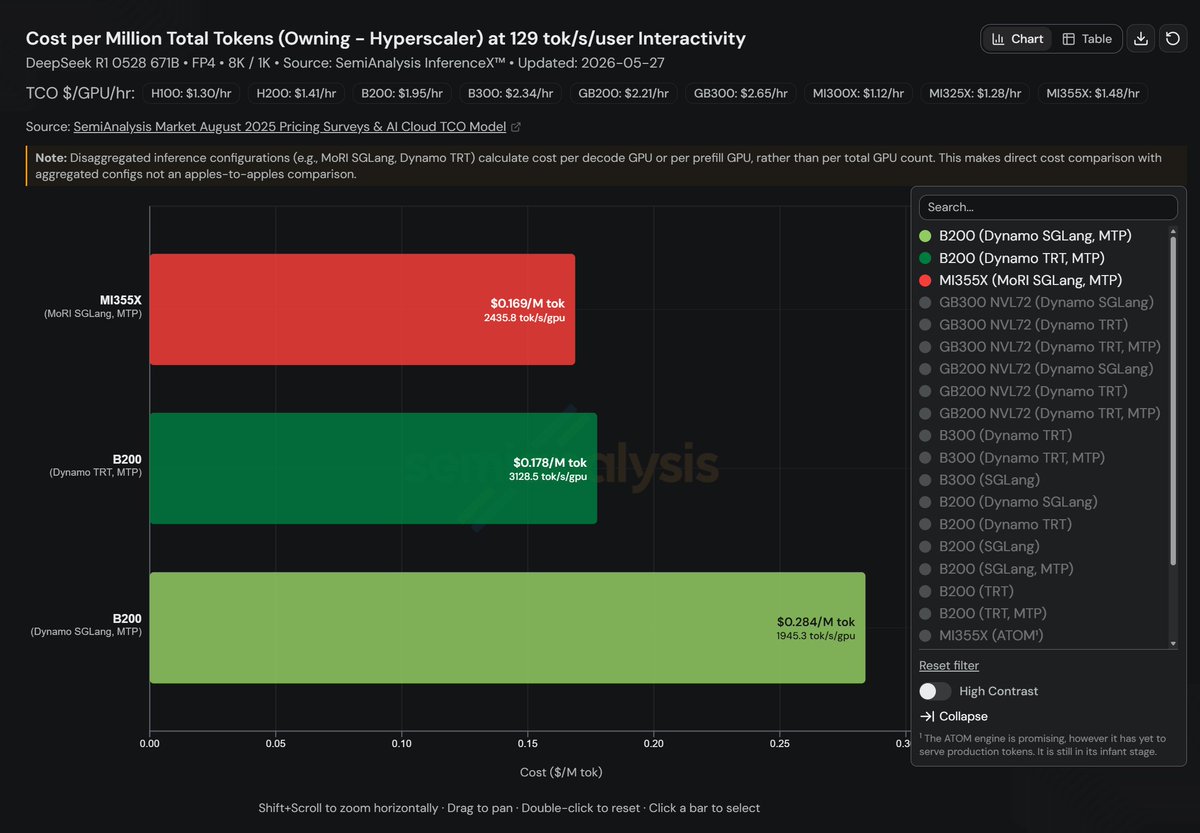
🚀 New blog: Win on TCO: How AMD Instinct™ MI355X Achieves Cost-Competitive Distributed Inference Through SGLang with MoRI
AMD Instinct™ MI355X beats B200 on TCO for DeepSeek-R1 disaggregated inference, with 5% lower cost than B200 TRT-LLM, and 1.25× higher throughput/GPU than B200 SGLang.
Together with @AMD, we achieved competitive TCO through full-stack optimizations:
1. MoRI quantized all-to-all (FP4 dispatch FP8 combine): 2.56× bandwidth reduction
2. MoRI-IO KV cache backend: ~10% higher throughput than Mooncake
3. Two-Batch Overlap with SDMA: zero-compute-overhead async transfers
4. AITER GEMM FlyDSL FusedMoE: tuned kernels for TP & DP EP on MI355X
5. Specv2 MTP on ROCm: delivers 4% total token throughput and -3.6% TPOT
6. CPU streaming: 20% output throughput, -16% TPOT at 2,048 concurrency
Results live on @SemiAnalysis_ InferenceX dashboard.
2
5
68
5,472

Aaryaman "Jam" Vasishta retweeted
Apr 30
Open is a Philosophy !!! Speed is the moat

“Open is more than a license to us. It’s a philosophy.”
That approach is showing up in the real world, with ROCm powering 8 of the top 10 AI labs.
@AnushElangovan at AMD #AIDevDay.

1
5
57
3,481
Glad to have helped with one of those upcoming playbooks :)
Introducing AMD AI Playbooks, your shortcut to building AI on AMD.
Step-by-step guides to help you run real AI workloads, customize them for your environment, and get up and running faster.
New playbooks drop every month.
Start building: amd.com/en/developer/resourc…

106
Aaryaman "Jam" Vasishta retweeted
Apr 29
Tell us how we can make ROCm better. We are listening and we will grind it down.

Build commands shared here reddit.com/r/ROCm/comments/1… much simpler than before.
34
4
108
9,270
Aaryaman "Jam" Vasishta retweeted
Apr 28
7.13 has multi-arch packaging so you can pull only the arch you need at runtime -- get the benefits of native ISA targets but also don't need the bloat (or jit to a lower level ISA).

CANN toolkit (ala cuda-toolkit, rocm) clocks in at 3.6GB of disk install. That's a lot for a single arch toolkit. Makes AMD's bloated ROCm looks like a lightweight.

1
3
35
4,220
Aaryaman "Jam" Vasishta retweeted
Apr 18
The challenge has now concluded. Please tag me here if you have eligible submissions by EOD 4/20.
Apr 16

@AnushElangovan Has this challenge concluded? If it's still ongoing, how many prizes remain?
2
2
8
2,717
Aaryaman "Jam" Vasishta retweeted

Mar 3
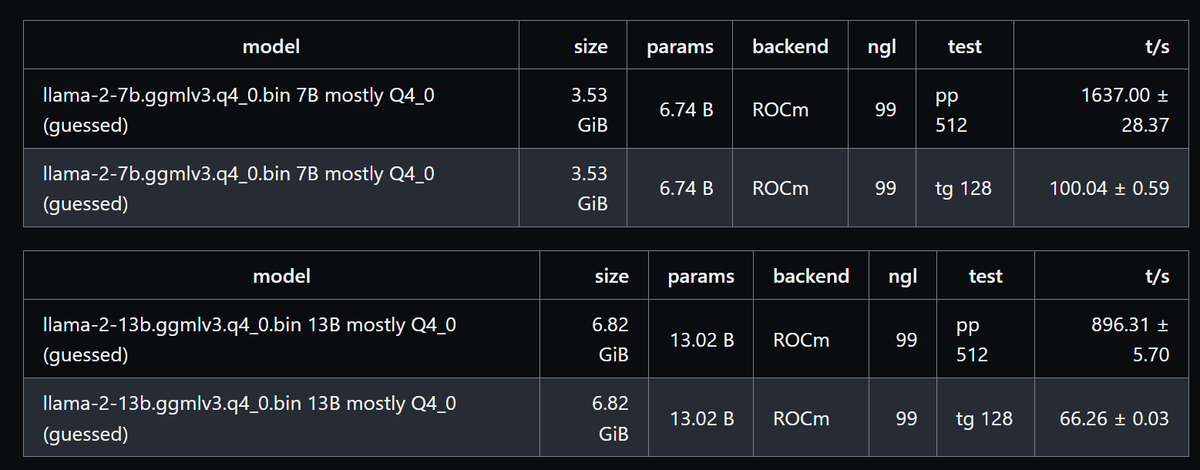
And now it's documented. For people serious about performance, this is a real AMD advantage. Thanks @AnushElangovan for pushing this through! Code is here: github.com/ROCm/rocm-systems…
4
14
363
33,949
Aaryaman "Jam" Vasishta retweeted
Feb 17
BS. Right on target for H2 2026.
Feb 16

SemiAnalysis:
Engineering samples and low-volume production of $AMD's first rack-scale MI455X system will begin in H2 2026. Due to manufacturing delays, mass production ramp, and the first production tokens generated on the MI455X will not occur until Q2 2027

26
29
416
67,837
Aaryaman "Jam" Vasishta retweeted
Feb 17
Speed is the moat.
MI455X is both fast, and is the fastest I have seen in execution for bringup of a complex GPU platform. MI455X is right on target for shipments in 2H2026 - Irrespective of what @SemiAnalysis_ says - rev your engines because speed is coming.
39
59
577
219,383
Aaryaman "Jam" Vasishta retweeted
Feb 14
The pace of OSS models suddenly seems to be picking up. We got you covered Day 0 on AMD GPUs

✅ Day 0 support of MiniMax-2.5 on AMD GPU
2 MI300X GPUs are all you need, instead of 4 Hopper GPUs, to run it in full context.
uv pip install vllm --extra-index-url lnkd.in/gJdnn3kJ
VLLM_ROCM_USE_AITER=1 vllm serve MiniMaxAI/MiniMax-M2.5 \
--tensor-parallel-size 2 \
--tool-call-parser minimax_m2 \
--reasoning-parser minimax_m2_append_think \
--enable-auto-tool-choice \
--trust-remote-code

2
3
73
7,011

I wrote a new blog post on Triton bespoke layouts — the traditional blocked / shared / MMA layout mechanisms still widely used inside the Triton compiler and now exposed via Gluon for more intuitive control.
This builds on my earlier posts on linear layouts, and together they aim to provide a fairly complete mental model of how Triton represents and reasons about layouts.
lei.chat/posts/triton-bespok…
1
24
186
15,867
Aaryaman "Jam" Vasishta retweeted
ROCm 7.2 Perf improvements.. Keep the feedback coming and we will keep pushing..
reddit.com/r/ROCm/comments/1…
2
10
71
4,730
Aaryaman "Jam" Vasishta retweeted
Jan 22
The future of GPU programming is agentic.
reddit.com/r/AMD_Stock/comme…
23
55
386
196,206
It’s 2026. One of my goals this year is to more consistently write down what I learnt working on GPU software—compilers, runtimes, and performance—so others can benefit (and yes, future AI training material too!).
I publish these notes at lei.chat/.
Many folks have told me they found them useful, so I’m trying to do this more often than once a year. 🙂
5
19
179
25,410
Aaryaman "Jam" Vasishta retweeted
Jan 7
loving the density and the double wide

9
10
345
18,806