
Building autonomous marketing @adfactorai. magellan’s a lot cooler than justin bieber
Joined December 2008
- Tweets 23,674
- Following 3,641
- Followers 1,901
- Likes 38,277
1,525 Photos and videos






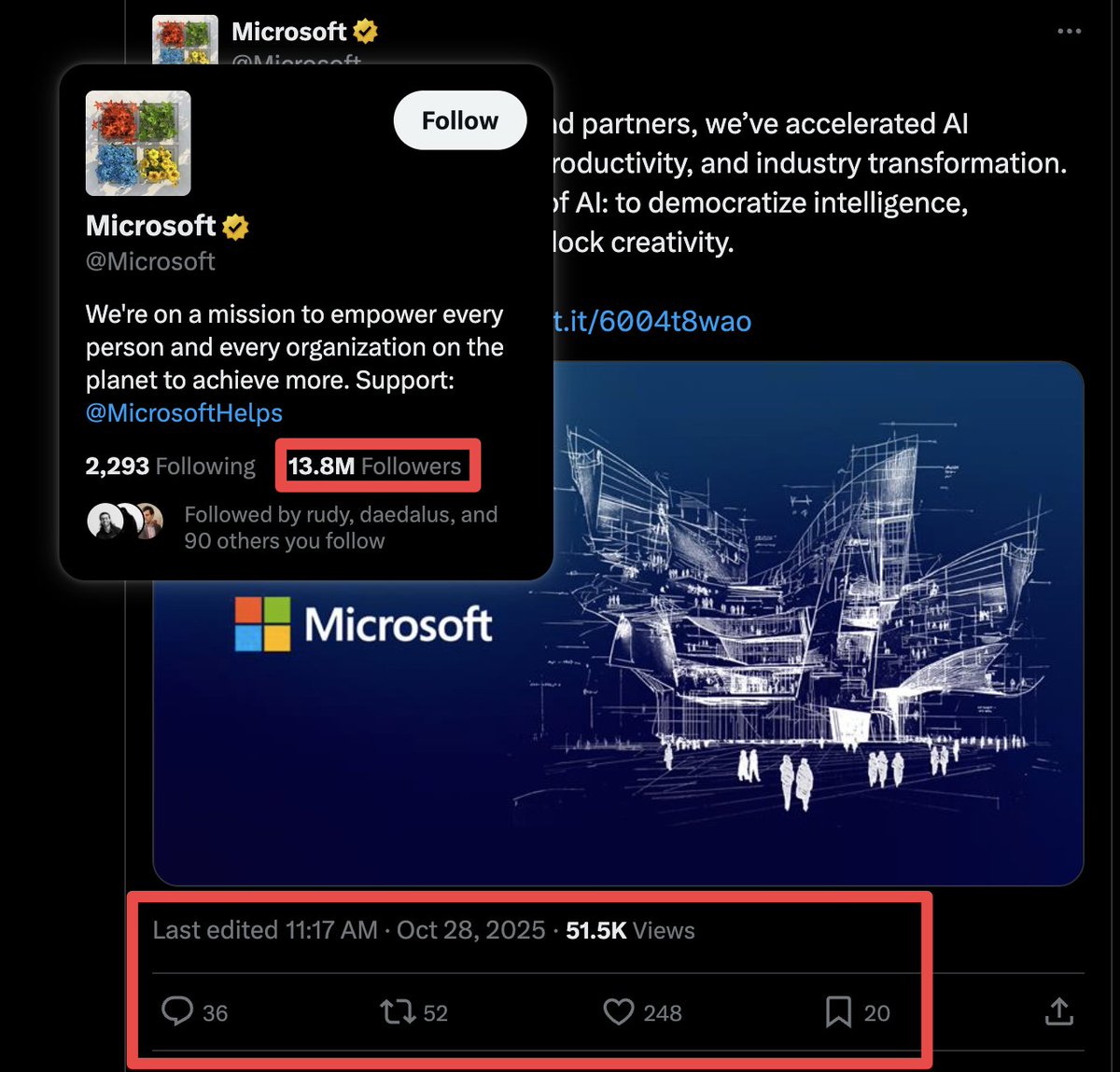





Pinned Tweet

Jan 20
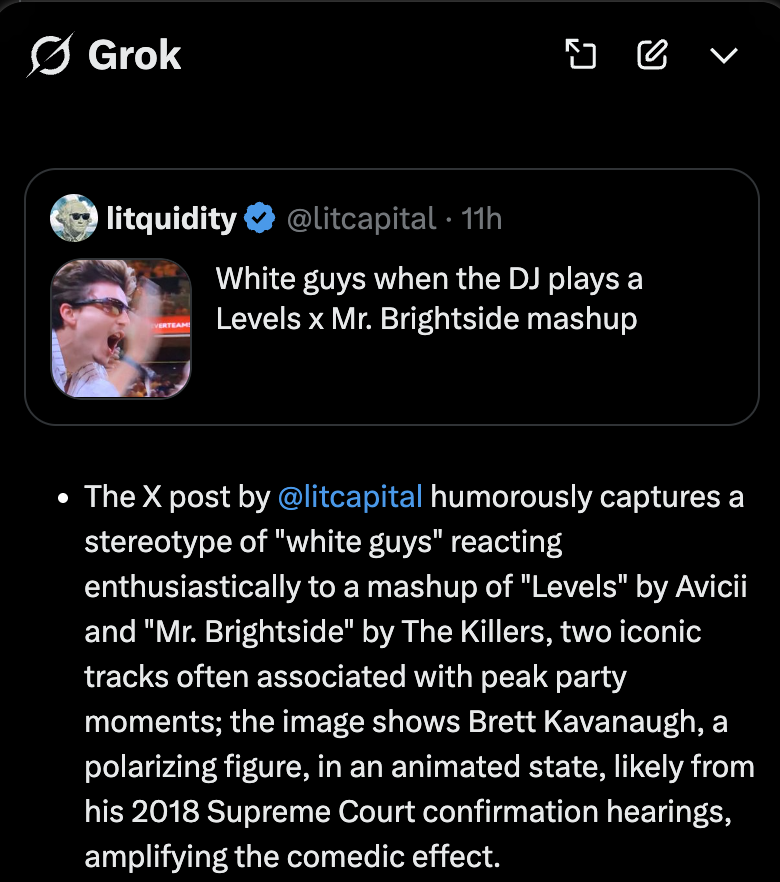
an inch wide and a mile deep. insane pmf
Jan 20

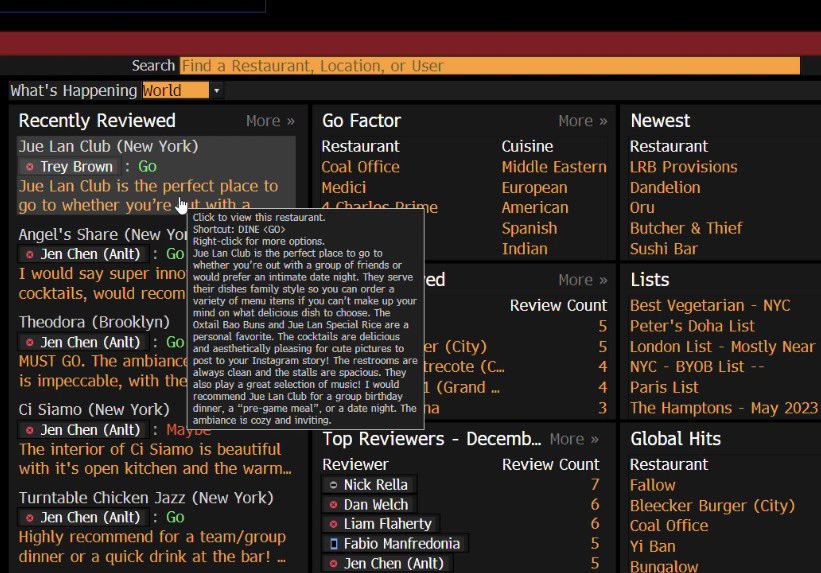
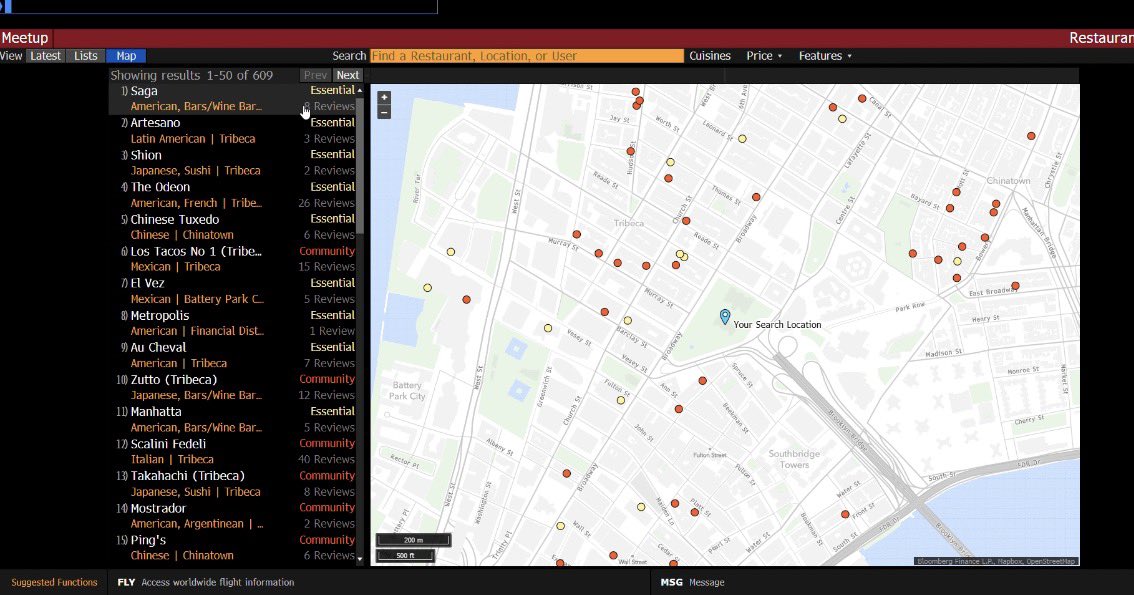
The Bloomberg Terminal literally has an entire command just for finance bros to know we’re to aura farm for dinner.
DINE <GO> is tailored for busy finance professionals seeking quick insights on where to eat, network, or entertain clients. Filter by location, cuisine, & price!
1
3
754
May 8
Why am I seeing this now?

2
3
39
Apr 28
vibed a little @ElevenLabs text to speech pi extension while driving this morning. now pi can speak text responses w your chosen elevenlabs voice.
cannot believe how easy this was, i think largely due to how well pi exposes it's docs to itself. cheers @badlogicgames, pi is absolutely incredible
1
1
5
2,087
Apr 17
The looming end of the subsidized token era of AI is going to create massive opportunities for AI app layer companies. Why? Price positioning and anchoring.
Right now you get an insane amount of value from $20/mo from the labs, and it makes it seem crazy to pay $15-20/mo for an app that only does a fraction of what claude/chatgpt goes. Think: voice transcription apps like superwhisper/wisprflow.
But the era of $20/mo is coming to an end, Anthropic signaled that this week for enterprise customers. That will create lots of room for app layer companies to raise prices to a more competitive/sustainable level.
The opportunity space, especially for lower-priced prosumer ai products is about to explode.
2
45
Apr 11
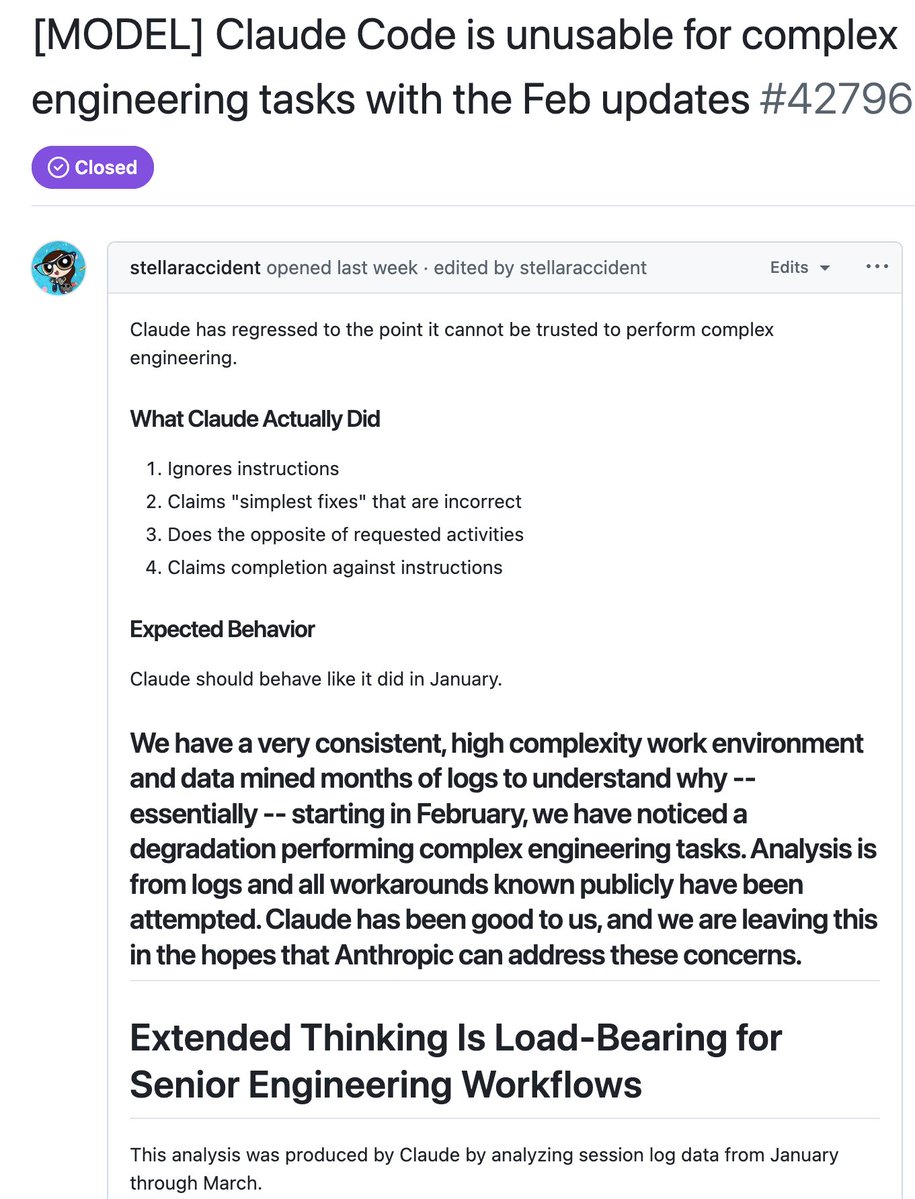
Quantitative evidence of Claude degradation.
My guess is Anthropic ran out of compute capacity sometime in feb due to their explosive growth since beginning of the year, and has some infra to dynamically scale thinking effort to load balance across the capacity they do have. Incredibly impressive they made to stay up as much as they do.
Apr 11

AMD Senior AI Director confirms Claude has been nerfed. She analyzed Claude's session logs from Janurary to March:
> median thinking dropped from ~2,200 to ~600 chars
> API requests went up 80x from Feb to Mar. less thinking and failed attempts meaning more retries, burning more tokens, and spending more on tokens
> reads-per-edit dropped from 6.6x → 2.0x. model stops researching code before touching it.
> model tried to bail out or ask "should i continue" 173 times in 17 days (0 times before March 8).
> self-contradiction in reasoning ("oh wait, actually...") tripled.
> conventions like CLAUDE.md get ignored because there's less thinking budget to cross-check edits
> 5pm and 7pm PST are the worst hours, late night is significantly better. this means the thinking allocation is most likely GPU-load-sensitive.
191
Alex Sharp retweeted

Mar 24
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Mar 24

LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server self-replicate. link below
1,352
5,308
27,821
66,584,869
Alex Sharp retweeted

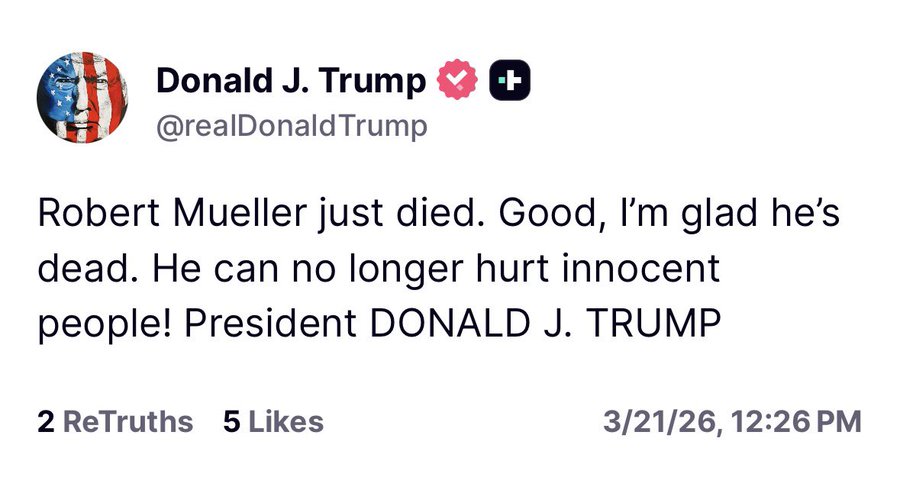
Mar 21
While Trump dodged the draft, Robert Mueller volunteered for the Marines after graduating Princeton. He was awarded a Bronze Star with combat V, rescuing a wounded Marine while under fire. He was later shot in the thigh, awarded a Purple Heart, and returned to lead his platoon.
325
1,507
7,845
283,822

Mar 8
Excellent, thorough analysis of the energy shock that’s about to ripple through nearly everything
1
1
116
Mar 7
lol the training data is so Reddit and 4chan pilled that when it gets access to a remote machine it just…mines crypto 😂


101
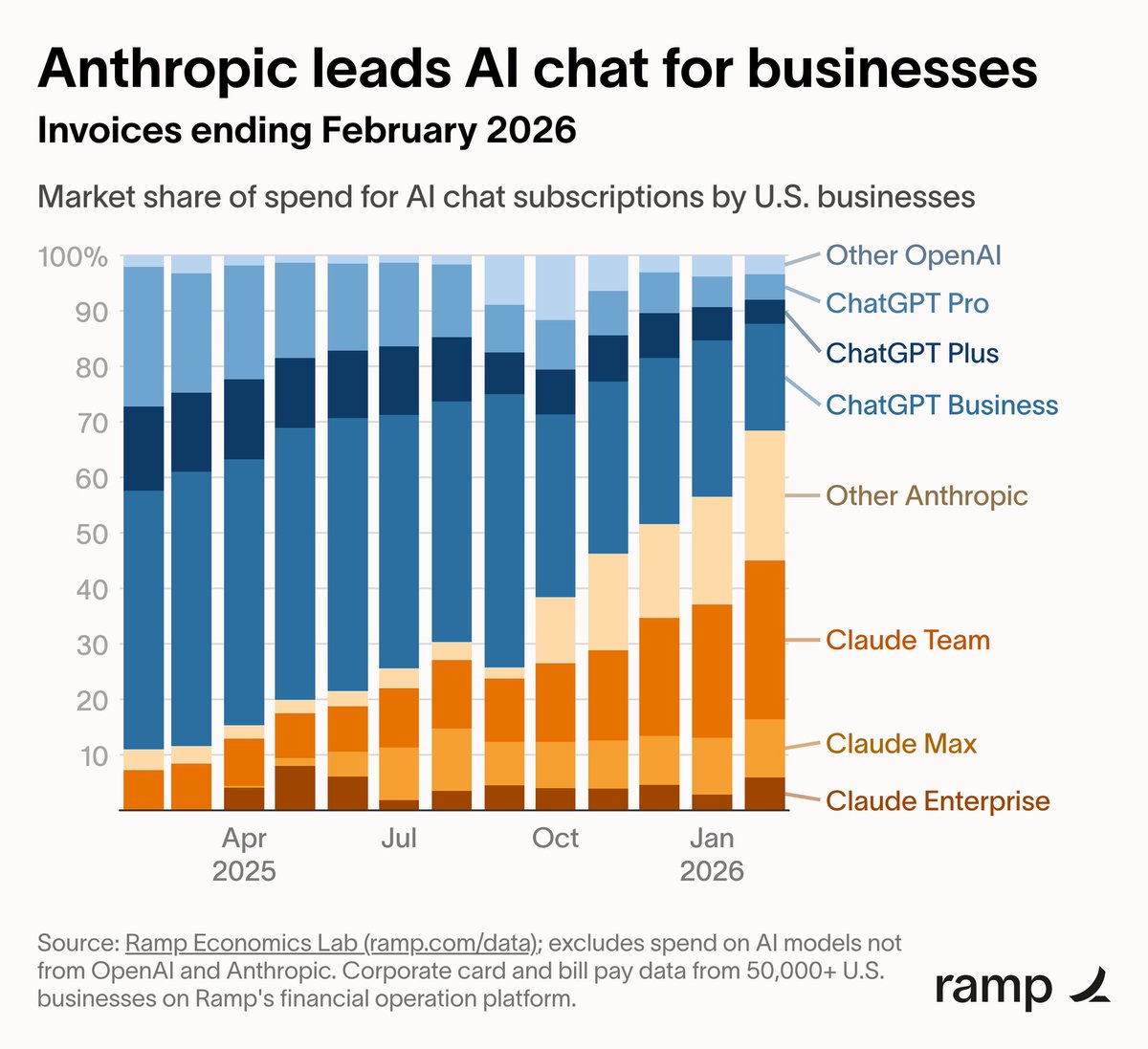
Mar 4
A generational chartmogging. 10-60% market share in under a year 🤯

1
264
Mar 3
It's hard to overstate what a massive advancement this is, and how dramatically this could shift inference workloads from the cloud to local.
Markets are not pricing this yet, but I expect they will start to soon.

Apple just made the most important chip design change in Apple Silicon history. The M5 Pro and M5 Max are now 2 chips fused together.
They broke the CPU and GPU apart onto separate pieces of silicon and reconnected them using the same packaging tech that goes into data center AI chips.
The clever part:
the M5 Pro and M5 Max use the EXACT SAME CPU. Identical. The only difference is how much GPU they bolt on:
- 20 cores for Pro
- 40 for Max
Like Lego blocks for silicon
Why this matters: smaller chips are cheaper to make, run cooler under heavy loads, and, most importantly, Apple can now scale the GPU up or down without redesigning the whole chip. This is how they'll build the Ultra. This is how they'll build whatever comes after
Everyone's going to talk about speed today. The real story is that Apple just changed how it builds chips and this is the foundation for the next decade of Apple Silicon
1
131
Mar 3
The possibilities here are staggering
x.com/BrianRoemmele/status/2…
Mar 3

THIS IS BIG!
WE CAN NOW FINE TUNE AI MODELS IN REAL-TIME 100s OF TIMES PER HOUR!
This is the first time an average user can actually fine tune an off the self AI Model literally while they talk to it!
What almost real-time fine tuning means:
You get ~107 training steps per second (or 6,420 steps per minute) entirely on-device via private ANE APIs, no GPU, no Metal, no cloud.
In under 10 seconds you can perform 1,000 full backprop updates on a production-scale layer.
For context: this is low-latency enough to fine tune a layer in real time during a conversation or user session (e.g., adapt a personal assistant's style to your latest 100 messages on-the-fly).
Efficiency angle: only 11.2% ANE utilization delivers 1.78 TFLOPS sustained, with CPU handling only weight updates via Accelerate — ultra-low power and silent, perfect for always-on local Al.
We have tested this with a LLAMA 4 bit model and it works!
CEO Mr. @Grok has already presented dozens of business plans that can be deployed today with the Zero-Human Company.
Understand no one has been able to build user ready instant AI fine tuning on your custom data on your device until this moment. The uses are endless ask Mr. @Grok to list 10.
This is just experimenting in one day. No hidden behind closed doors because we are “goin to market” we are showing you what any company would keep in VC pitches only. YOU ARE THE VC NOW.
35
Alex Sharp retweeted

Feb 28
x.com/i/status/1869608354034…
me and claude code all day every day
407
1,857
21,289
4,533,814
Feb 28
Dept of defense accountant reviewing expenses on Monday:
“Hey does anyone know what, eh, openrouter is???”
1
353
Feb 27
Hadn’t realized til I saw this but this is obviously brilliant dark ux to make you scroll to try to find the banger


1
75
Feb 26
Feels like a new open source license is needed to deal with slop forks
Feb 25

Wow, @tldraw is moving their tests to a closed source repo to prevent a Slop Fork
github.com/tldraw/tldraw/iss…
110
Feb 25
Jack Donaghy: Vertical integration, Lemon.
Feb 24

Bayer is a pharmaceutical company.
Monsanto is a pesticide company.
Bayer bought Monsanto.
Bayer makes drugs for Non-Hodgkin lymphoma.
Monsanto makes a toxic herbicide called glyphosate to spray on food crops.
Glyphosate causes Non-Hodgkin lymphoma.
Full circle
1
80
Feb 22
Fascinating approach to this problem.
Most people wouldn’t even think to run 50 agents in parallel purely because of the cost, but abundance massively shifts the solution space.
SO many problems are constrained by a lack of abundance, the next few years will be mind blowing
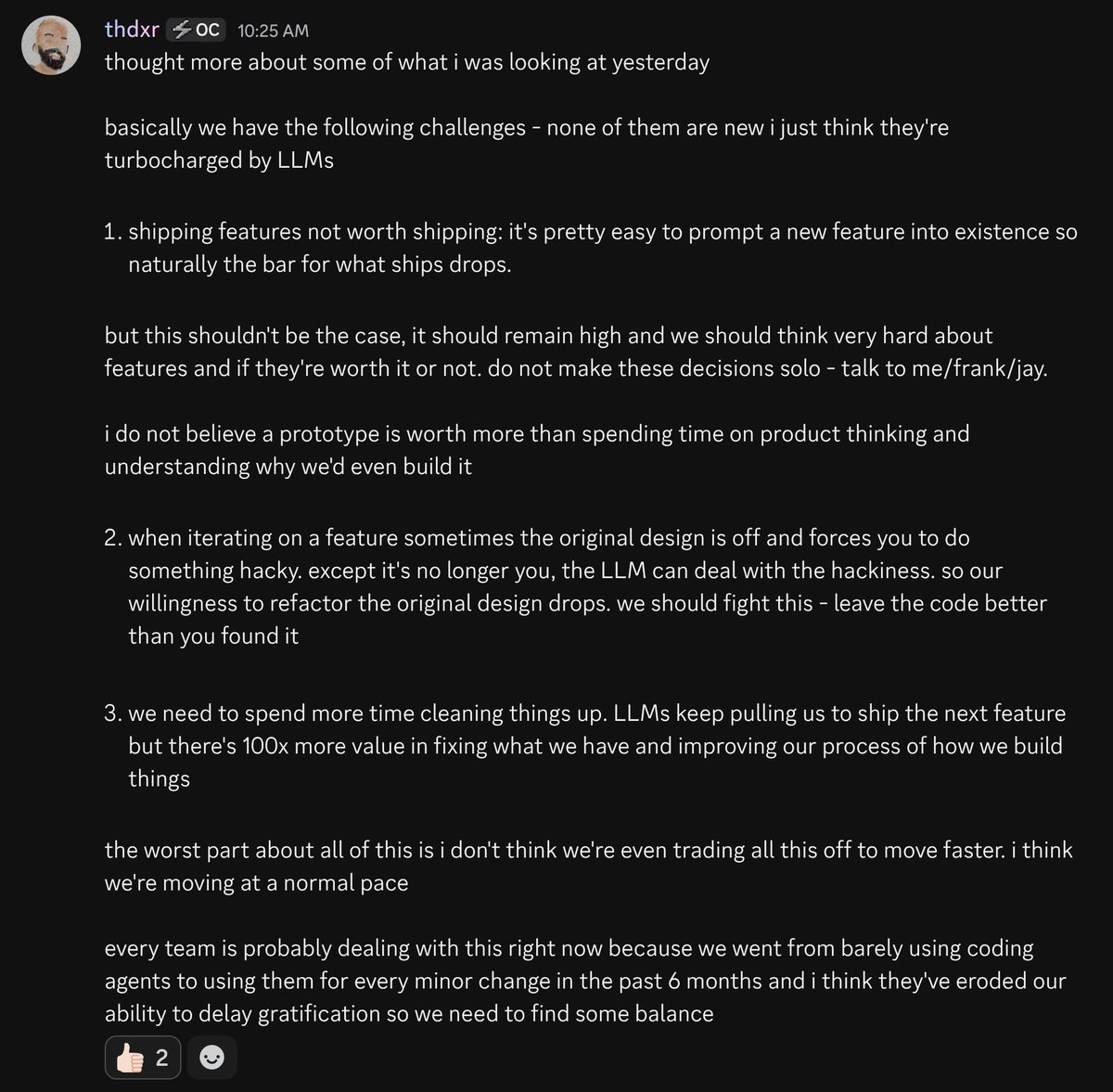
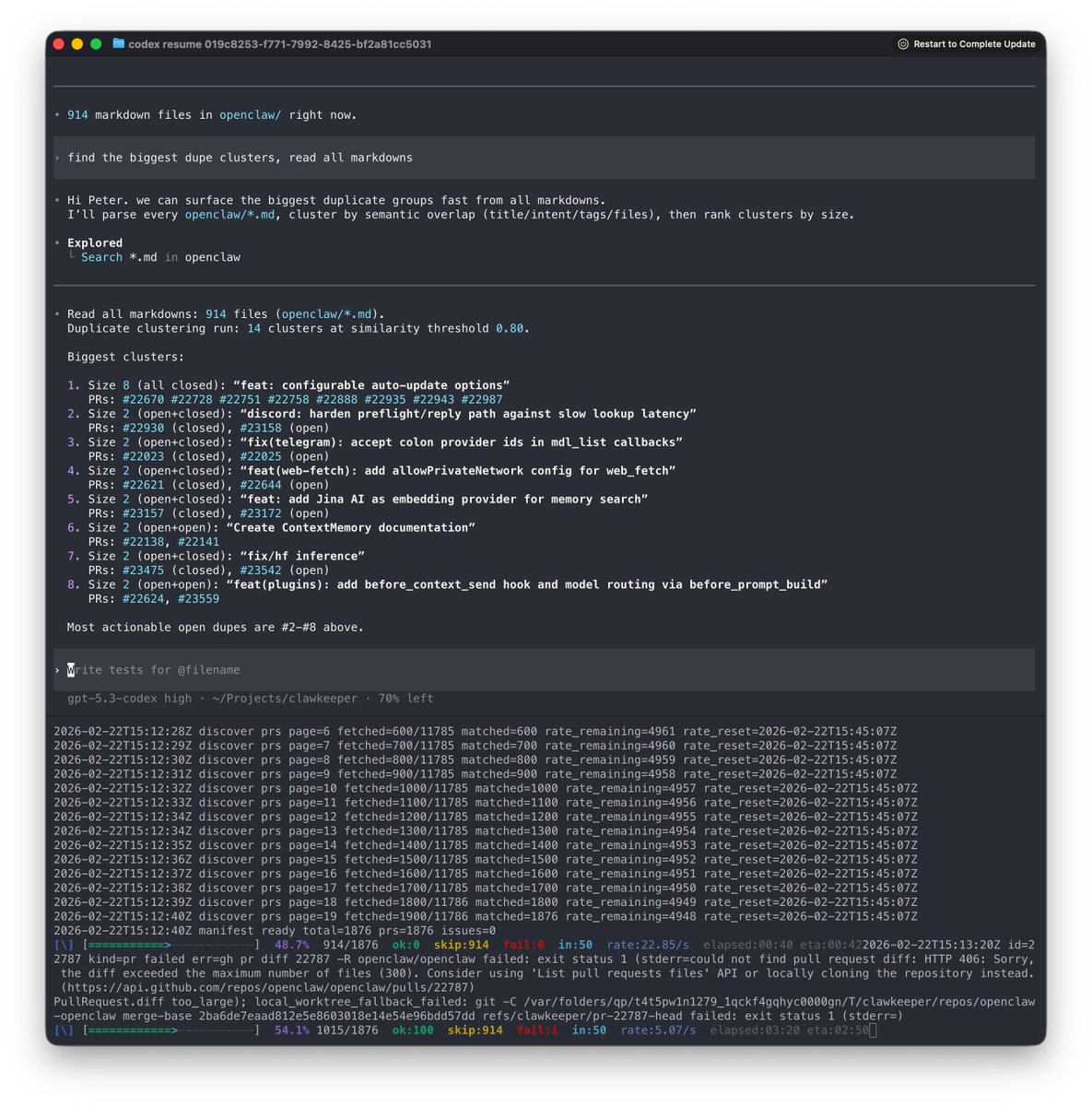
Feb 22

Been wrangling a lot of time how to deal with the onslaught of PRs, none of the solutions that are out there seem made for our scale.
I spun up 50 codex in parallel, let them analyze the PR and generate a JSON report with various signals, comparing with vision, intent (much higher signal than any of the text), risk and various other signals.
Then I can ingest all reports into one session and run AI queries/de-dupe/auto-close/merge as needed on it.
Same for Issues. P rompt R equests really are just issues with additional metadata.
Don't even need a vector db. Was thinking way too complex for a while.
There's like 8 PRs for auto-update in the last 2 days alone (still need to ingest 3k PRs, only have 1k so far).
272
Alex Sharp retweeted

Feb 20
Start the discourse. We’re claiming to have fixed the context problem with mcp. (Well, a lot of it). Lots to say about this, but this marks a new branch of the tech tree opening up.
Code mode for everything. You heard it here first.
Feb 20

The Cloudflare API has over 2,500 endpoints. Exposing each one as an MCP tool would consume over 2 million tokens. With Code Mode, we collapsed all of it into two tools and roughly 1,000 tokens of context. cfl.re/4rZwWJp
29
24
499
66,399