
Developers of Vosk Speech Toolkit
Joined October 2019
- Tweets 1,852
- Following 484
- Followers 1,068
- Likes 1,787
62 Photos and videos


Pinned Tweet

15 Jun 2022
Voting, Ensembles and bringing AI to life
alphacephei.com/nsh/2022/06/…
1
2
9
Jun 6
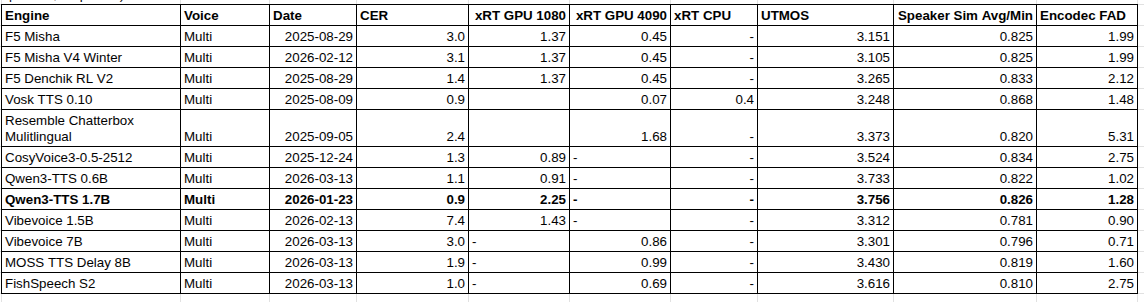
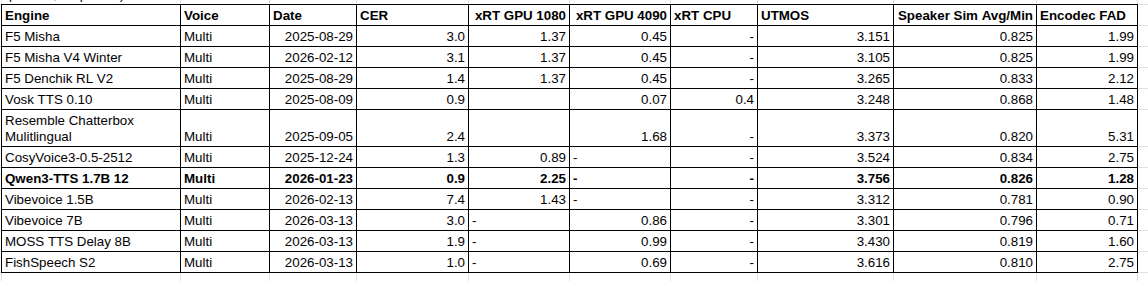
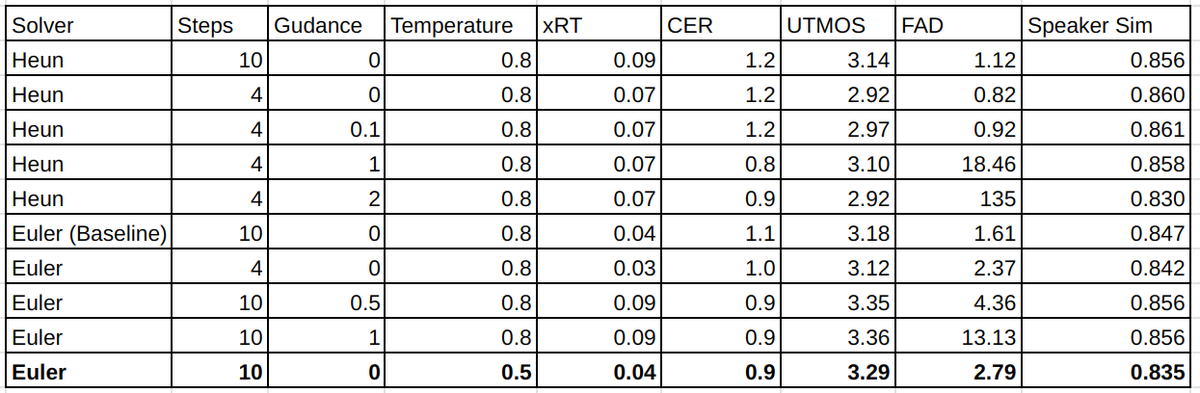
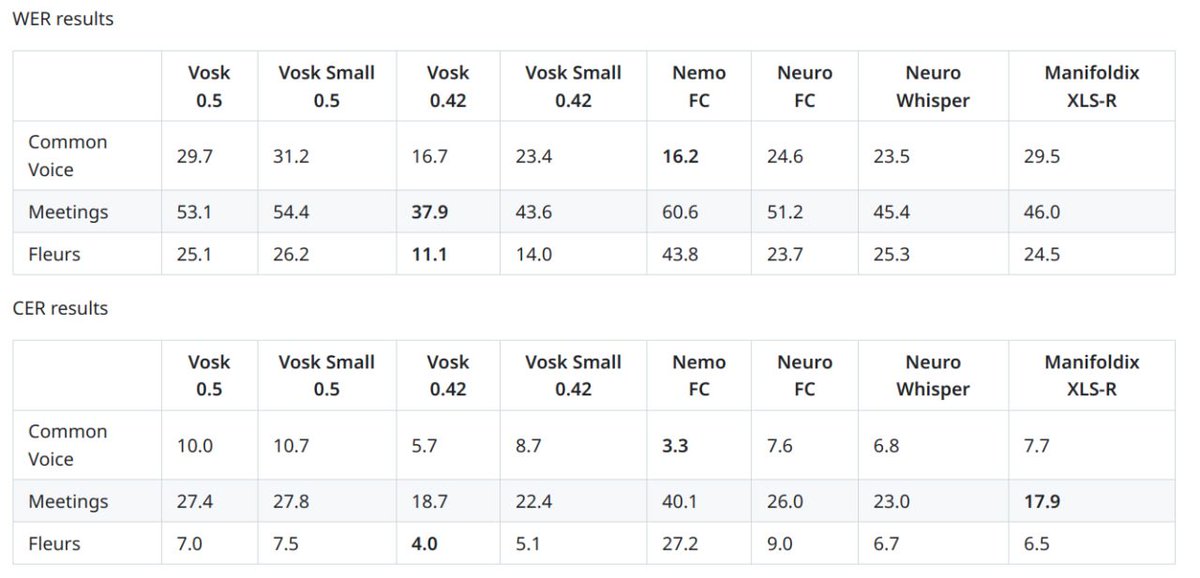
Most TTS anouncements report just CER and SSIM. Easy to hack those metrics - just make your TTS speak slow and clearly articulate words. It will be easy for ASR to decode, you'll get top position. Many systems do that, recently released HiggsV3 for example.
6
4
59
13,515
AlphaCephei retweeted

Jun 4
Audio is the modality of interaction. Audio language model is out.
Introducing the Audio Interaction Model, a new paradigm for end to end streaming unified audio models
13
13
115
12,958
Jun 4
Conformer learned random algorithm in dither again. Enough logmels for us!
4
377
AlphaCephei retweeted

May 29
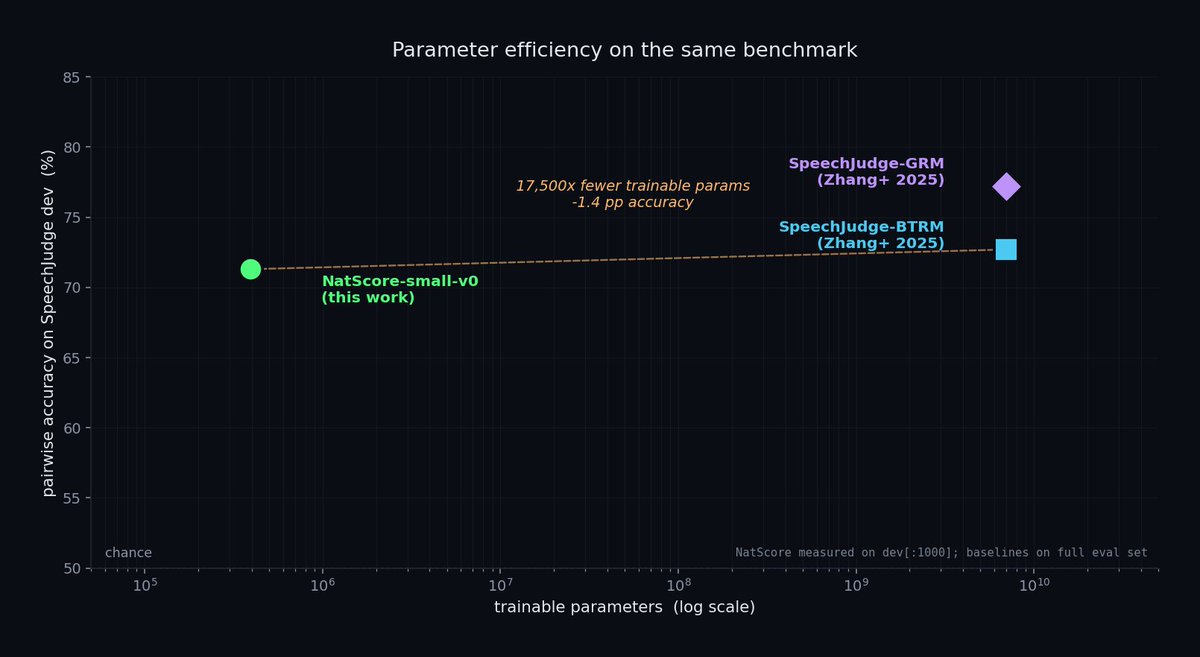
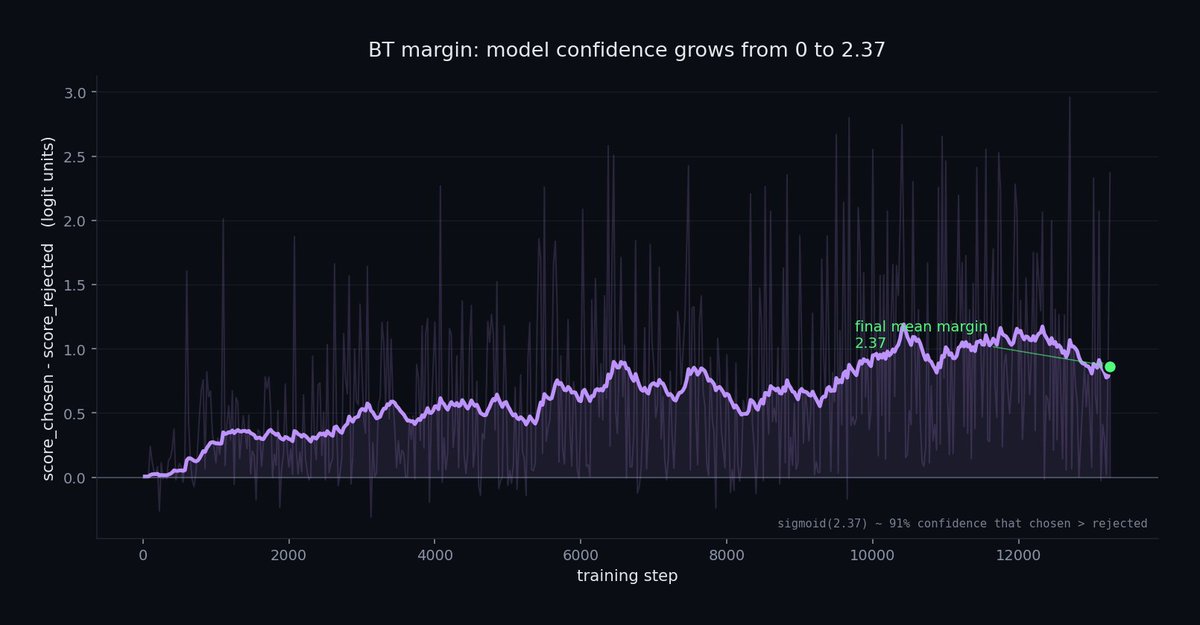
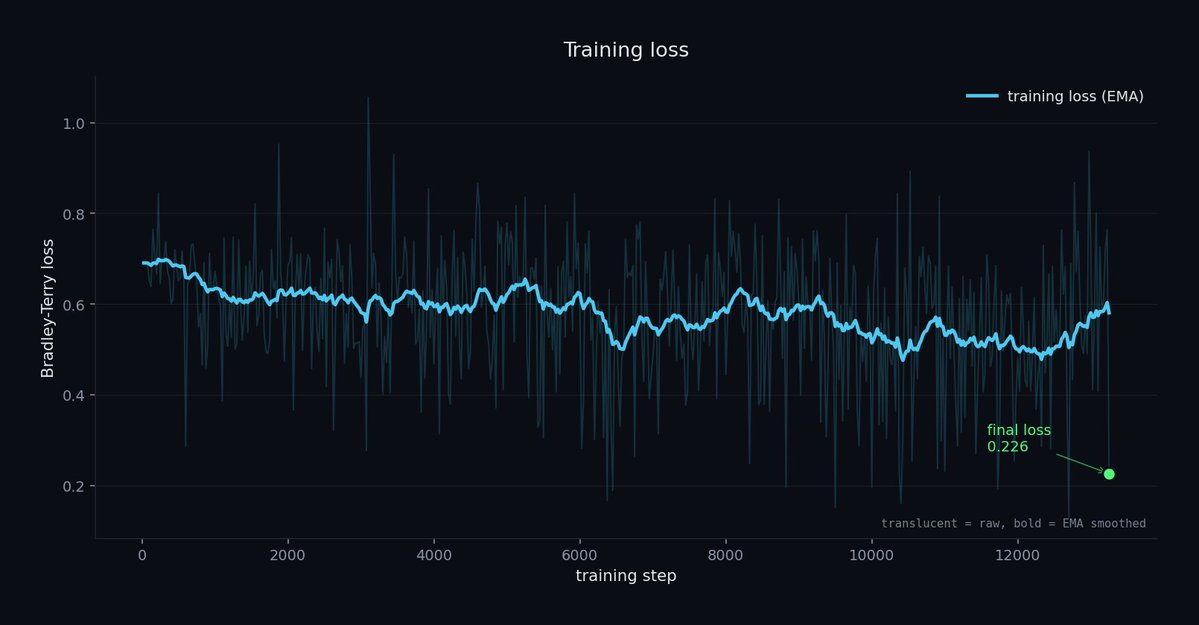
introducing natscore-small-vo🤗 (400k parameters)
a new way to measure the Naturalness of tts models
a 7B model is a strange thing to reach for just to ask whether synthetic speech sounds natural. So I trained something smaller .
Modern TTS (CosyVoice2, F5-TTS, MaskGCT, Llasa) stopped failing on artifacts. It fails on subtle things now: prosody, breath placement, expressive overshoot. The old MOS scorers were never trained on that surface, and some of them correlate negatively with humans on expressive speech.
natscore freezes a Whisper-small encoder and trains a ~400K-param Bradley-Terry head on 99K human preference pairs from SpeechJudge-Data. The head is one file you can read in 200 lines.
It scores TTS naturalness at 71.3% pairwise on the dev split (95% CI 68.6 to 74.1), well-calibrated at 2.27% ECE. The published 7B reward model reports 72.7% on the full eval. This one runs on a CPU, inside a training loop, for free.
@drwuz

7
8
72
6,176
May 29
On June 11th, Treble Technologies with Hugging Face launches the FFASR (Far-Field ASR) Leaderboard, a benchmark focused on evaluating ASR performance in more realistic acoustic conditions.
treble.tech/insights/treble-…
2
12
478
AlphaCephei retweeted

May 26
MOSS-TTS v1.5 is here, an upgrade to v1.0 from @OpenMOSS. (demo👇)🤖modelscope.ai/models/OpenMOS…
Key improvements:
⏸️ Inline pause control: [pause 3.2s] now supported mid-sentence
🌍 31 languages, up from 20 — now includes Cantonese, Hindi, Thai, Vietnamese, Tagalog, Swahili and more
🎙️ More stable voice cloning with reduced variance across repeated generations
📝 Better long-reference, short-text cloning All v1.0 capabilities preserved: zero-shot cloning, long-form speech, Pinyin/IPA control, code-switching.
💻 github.com/OpenMOSS/MOSS-TTS
5
44
250
13,663
May 25
Some our recent work on model training, nothing very deep but still important for the users
alphacephei.com/nsh/2026/05/…
1
12
1,198
AlphaCephei retweeted
May 20
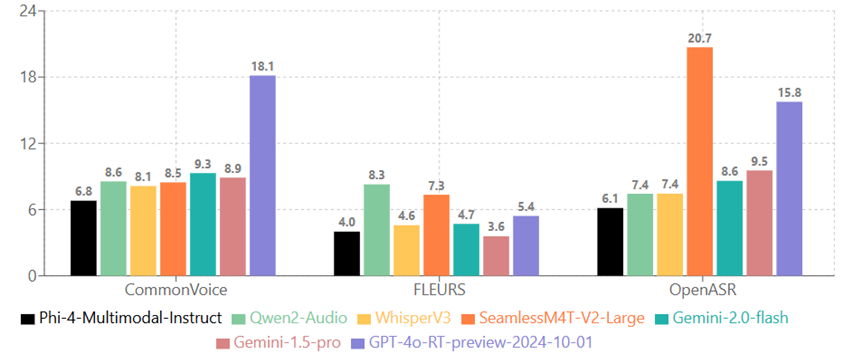
Stop using Whisper for ASR !
open sourcing Mega-ASR — the first full-scenario SOTA industrial-grade ASR model, built for the audio nobody else can crack: far-field, reverb, electrical hum, device noise, the real-world mess.
beats open closed SOTA by 10–30% on real-world benchmarks. the harder the audio is for humans, the bigger the lead.

22
89
596
33,764


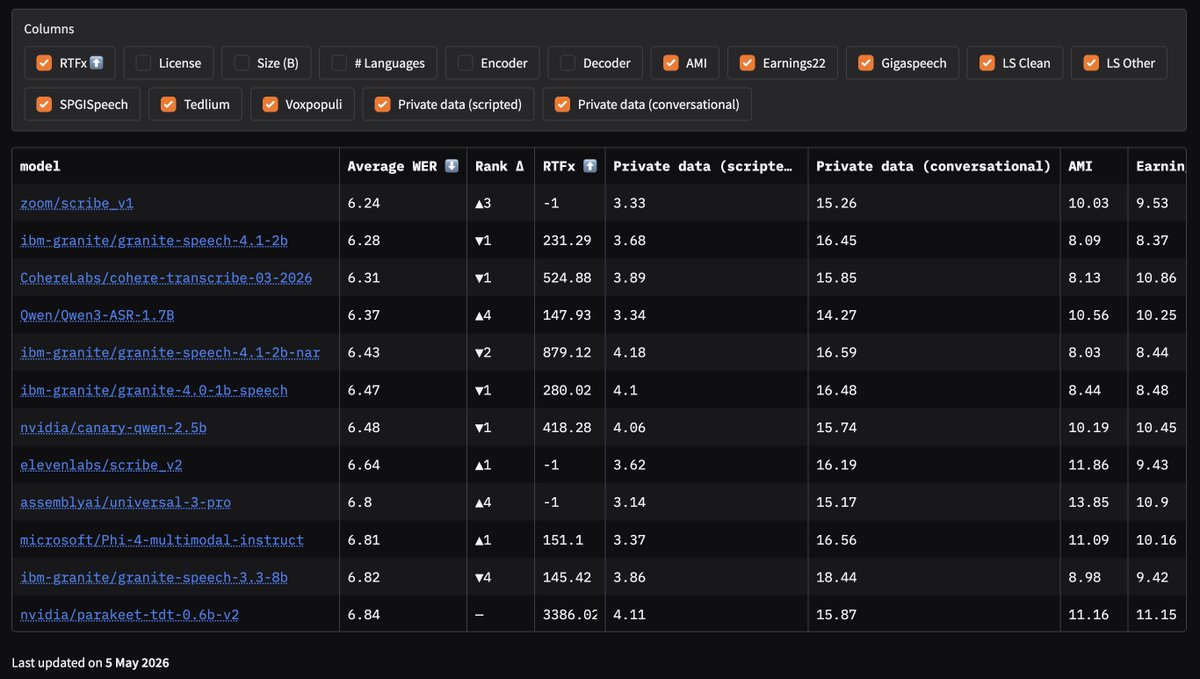
Big announcement for speech AI
Benchmarks get gamed. So we added a repellent.
The Open ASR Leaderboard now includes private evaluation data from Appen and DataoceanAI, making speech recognition benchmarks more robust against test-set contamination and “benchmaxxing.”
Better signal. Less overfitting. More real-world ASR.
7
17
115
12,069
AlphaCephei retweeted

Apr 24
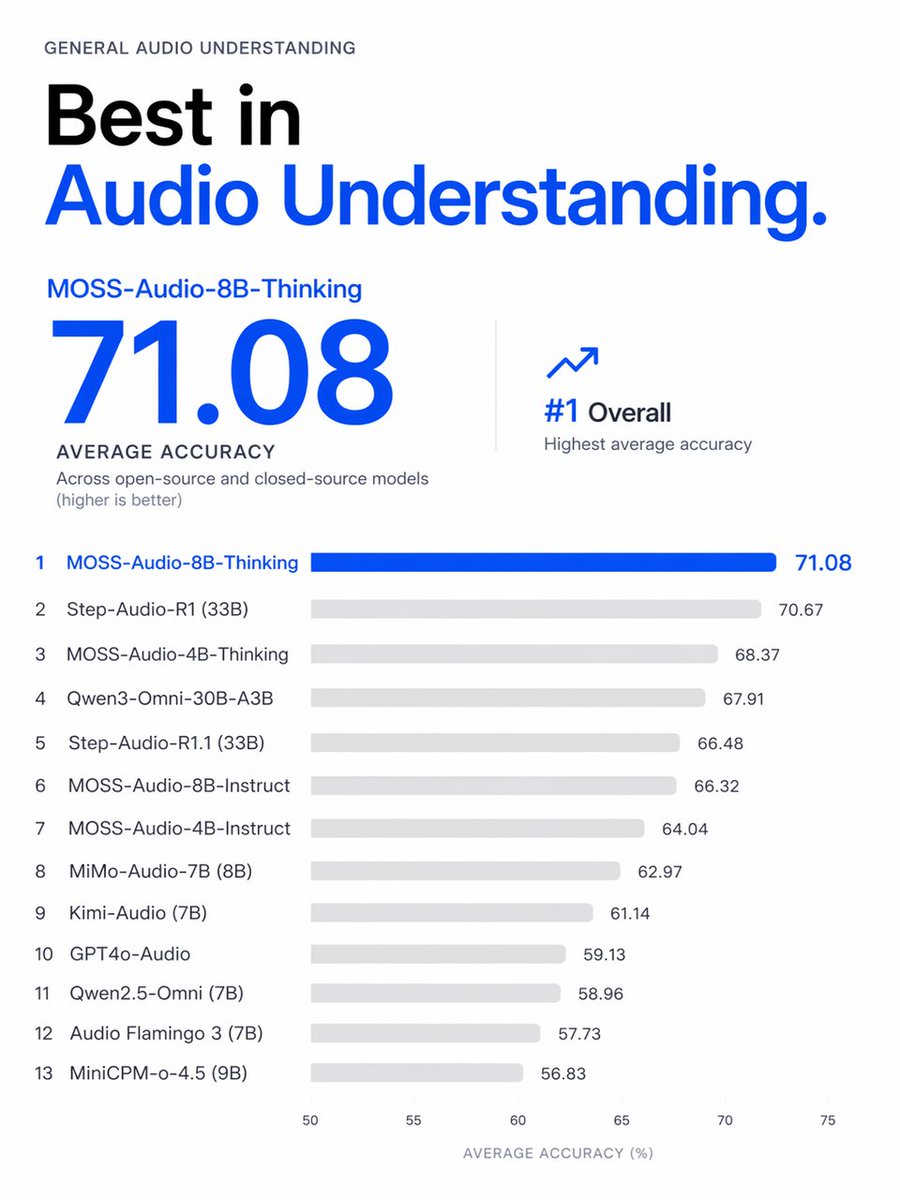
Meet MOSS-Audio.
A unified open-source model for real-world audio understanding, built to handle speech, emotion, speakers, sound events, music, temporal grounding, and reasoning in one system.
In the reported evaluation, our 4B model outperforms many 7B–9B open models, and MOSS-Audio-8B-Thinking reaches 71.08 average accuracy.
Strong results. Real-world audio.
GitHub: github.com/OpenMOSS/MOSS-Aud…
HuggingFace: huggingface.co/collections/O…
MOSI.AI: mosi.cn
OpenMOSS: open-moss.com
9
49
347
16,773
Apr 23
Many researchers study under-resourced languages. Even major languages suffer from lack of high quality datasets. Arabic, Bengali and many others never had any significant amount of data with high-quality annotations. MACS-Arabic transcripts are from Youtube. Same as Yodas.
1
1
6
659

In less than an hour, we’ll be live with DeepL Spring Launch — and this is one of the breakthroughs we’re most excited to share with you: real-time, spoken translation. You speak in your preferred language. Everyone else hears you in theirs.
Jarek and the DeepL team will be demonstrating voice-to-voice translation live onstage from 4pm CEST / 10am EDT. We’ll see you there!
#DeepLVoice #VoiceToVoice #SpringLaunch #LanguageSolved
1
4
504
Apr 18
betrac.github.io/
BeTraC is a shared evaluation challenge building end-to-end speech models for clinical dialog analysis.
11
900
AlphaCephei retweeted

Apr 18
Tencent & HKUST release Audio-Omni
First unified framework for audio understanding, generation, and editing across sound, music, and speech. Combines a frozen MLLM (Qwen2.5-Omni) with a trainable Diffusion Transformer for high-fidelity synthesis.

2
18
64
4,100
AlphaCephei retweeted

Apr 11
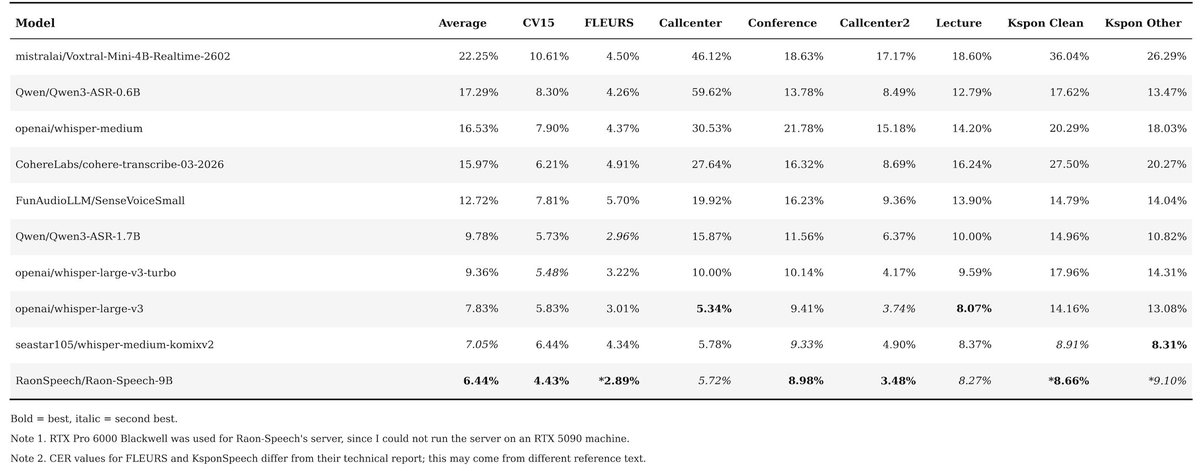
Updated table, with two additional models
- FunAudioLLM/SenseVoiceSmall
- RaonSpeech/Raon-Speech-9B
Also changed text normalization to more korean-specific way.
RaonSpeech/Raon-Speech-9B is first model beating whisper!
surprisingly, sensevoice-small was quite good and fast
Mar 28
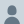
There were various asr model release(qwen3-asr, cohere-transcribe, voxtral-realtime) supporting korean.
Real question is "Is it better than Whisper?"
So I tested on various korean dataset.
github.com/seastar105/oss-as…
And, still whisper-large-v3 is king
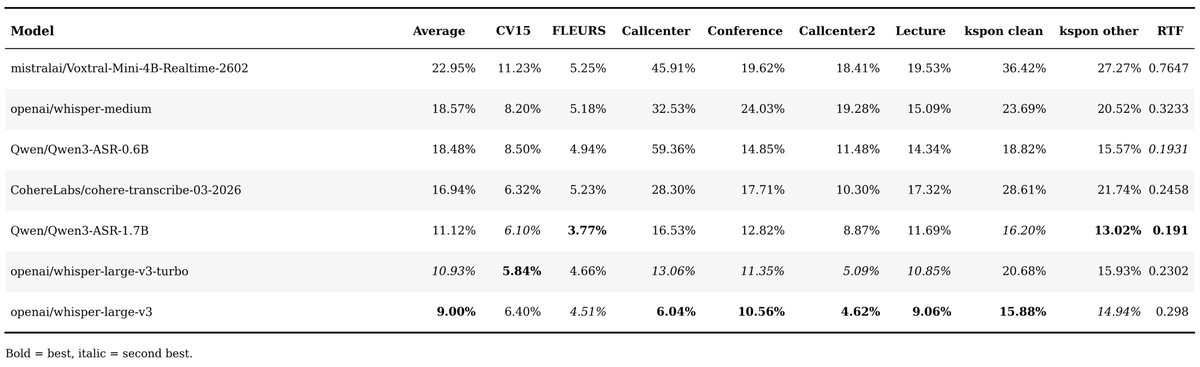
1
1
15
1,177
AlphaCephei retweeted

Apr 9
Arabic is spoken by 400M people across dozens of dialects — yet most speech AI covers only a handful. The bottleneck? Diverse, high-quality data.
We introduce MENASpeechBank: a large-scale, publicly available speech dataset spanning 124 speakers, 18 MENA countries, 5 dialect groups, and 417K persona-conditioned conversations — designed to advance speech understanding in LLMs across the full spectrum of Arabic.
📄 arxiv.org/abs/2602.07036
🤗 Data: huggingface.co/datasets/QCRI…
W/ @shammur_absar Zein, Hunzalah, Rabindra
#AudioLLM #ArabicNLP #SpeechAI
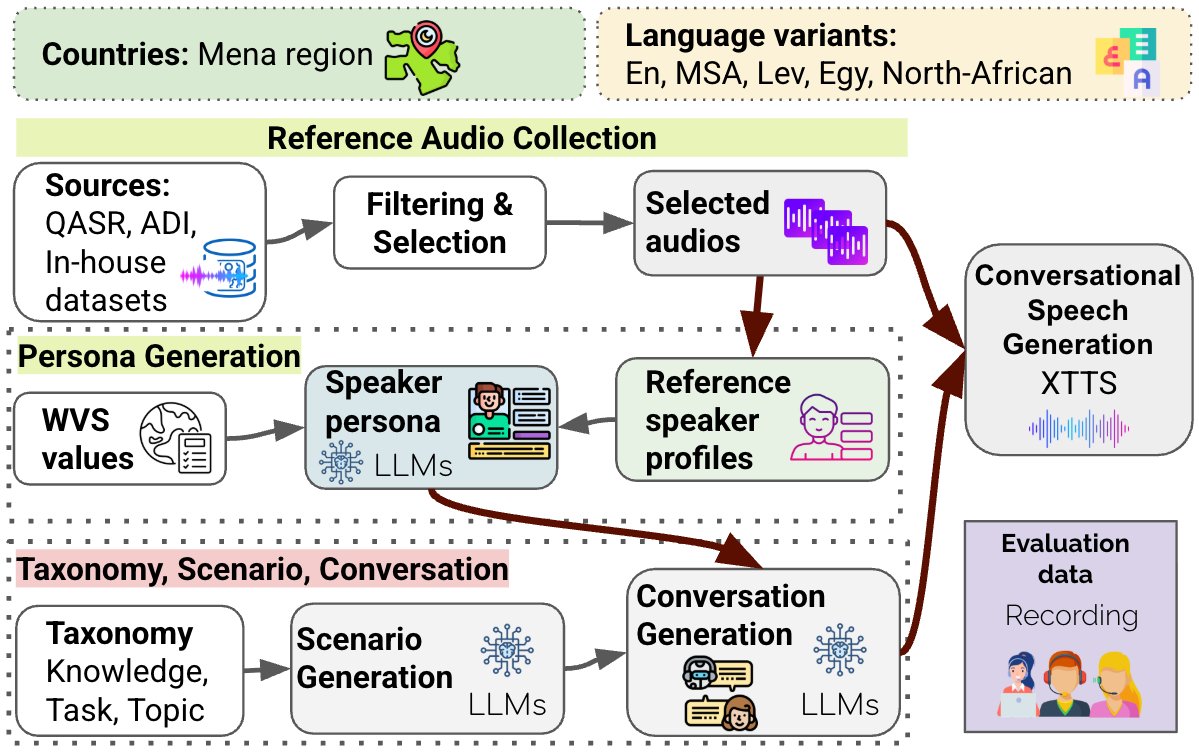
3
10
458
AlphaCephei retweeted

Apr 8
Omni Model Inference: How We Move Tensors Between Stages
A friend once asked me: what's the fundamental difference between serving Omni multimodal models and serving plain LLMs? I thought about it and the simplest way to put it is this — a regular LLM handles a request with a single model in a single process; an Omni model handles a request by relaying it across multiple models.
Take Qwen3 Omni as an example. The lifecycle of a voice conversation request looks roughly like this: the user sends an audio clip, which first passes through an audio encoder that converts the waveform into embeddings, then feeds into the Thinker (a large language model) for inference to generate text tokens, and finally those tokens stream into the Talker (a speech synthesis model) that progressively produces audio waveforms to return to the user. TTS models with a Dual-AR architecture follow a similar pattern — a large AR model generates coarse-grained tokens, a small AR model fills in the fine-grained tokens, and a vocoder synthesizes the final audio.
These models have inherent data dependencies: if the Thinker doesn't produce tokens, the Talker has nothing to consume; if the large AR doesn't emit coarse tokens, the small AR can't fill in fine tokens. But at the same time, they must run in parallel — the Talker neither needs to nor can afford to wait for the Thinker to finish generating everything before it starts. Otherwise, the user would wait several seconds before hearing the first syllable, and the experience would completely fall apart. The dependency between them is streaming: as soon as the upstream produces a small chunk of data, the downstream must consume it immediately.
This is why we split the entire inference pipeline into multiple stages, each running a component model, with intermediate results passed between stages via inter-process communication. Each stage is an independent process with its own GPU/hardware management, its own scheduling loop, and its own batch management. The upstream stage produces tensors, the downstream stage consumes tensors — a textbook producer-consumer relationship.
But "passing tensors between processes" actually breaks down into two fundamentally different concerns. The first is signaling — telling the downstream that data is ready. A few dozen bytes, demanding low latency at the microsecond level. The second is data transfer — moving tens of megabytes of tensor data from one process to another, demanding throughput, ideally with zero copy.
ZMQ is naturally suited for signaling — lightweight and low-latency — but asking it to transfer a 64MB tensor means serialization overhead that blows up latency. Shared memory CUDA IPC is naturally suited for moving large blocks of data with near-zero copy, but it has no built-in event notification mechanism; you'd have to resort to polling or bolt on external signaling to notify the downstream.
So our design is straightforward: separate Control Plane from Data Plane. ZMQ handles only notifications (lightweight messages like DataReadyMessage), while the Relay handles only data (tensor transfer via shared memory / NCCL / CUDA IPC), each doing what it does best. Once this separation was established, many downstream architectural decisions fell into place naturally.
With the Control Plane and Data Plane separated, the next natural question is: how exactly does the Data Plane move data?
The most intuitive approach is serialization — the upstream serializes the tensor into a byte stream, sends it to the downstream via socket, and the downstream deserializes it back. Logically clean, but the cost is prohibitive: a 64MB tensor going through serialization, memory copy, the network stack, and deserialization every time — the latency and CPU overhead are simply unacceptable in a streaming inference scenario.
Since upstream and downstream stages run in different processes on the same machine, a more natural approach is shared memory: the upstream writes the tensor directly into a memory region accessible to both processes, and the downstream reads from the same address. No serialization needed, no copy needed, and with CUDA IPC, even GPU tensors can be accessed directly across processes — zero copy in the truest sense.
But shared memory is no free lunch. The biggest question is: who manages the read-write cadence of this memory? Upstream and downstream speeds don't necessarily match — the Thinker might suddenly slow down due to a long context, or the Talker might fall behind because of heavy vocoder computation. If the upstream writes faster than the downstream can consume, the shared memory will eventually be exhausted. This calls for a flow control mechanism.
We chose a credit mechanism, which is essentially a classic semaphore. A fixed number of shared memory slots are pre-allocated between upstream and downstream (say 10 slots, each 64MB), and the credit represents the number of currently available empty slots. Before writing data, the upstream acquires one credit; after writing, it sends a notification via ZMQ. Once the downstream finishes reading, it releases the credit, and the upstream can reuse that slot. When credits are exhausted, the upstream blocks — naturally forming backpressure. The pipeline's throughput automatically degrades to the speed of the slowest stage rather than blowing up memory. This is also why the downstream must consume as quickly as possible after receiving a notification: releasing credits lets the upstream keep pushing forward; otherwise, the entire pipeline stalls.
This approach looks simple at first glance, but it's worth comparing against several common alternatives:
Ring buffer — a fixed-size circular buffer maintaining read and write pointers, blocking when write catches up to read. However, our stages run on different GPUs, and cross-GPU tensor transfer goes through CUDA IPC. CUDA IPC is per-allocation: each slot is an independent cudaMalloc, corresponding to an independent IPC handle, and the downstream's mapped address is determined by the driver — slots are not contiguous in address space. The "single contiguous memory block" assumption that ring buffers rely on simply doesn't hold here. If you force it, you're just rotating a slot index with modulo, which is logically equivalent to credit counting but adds an unnecessary layer of abstraction.
Dynamic allocation — no pre-allocated fixed slots; malloc new memory each time and free it when done. Maximum flexibility, but in a shared memory context, cross-process shm allocation and deallocation is inherently heavy, and fragmentation accumulates relentlessly in long-running inference services. For a scenario where slot sizes are fixed and quantities are bounded, dynamic allocation is using a cannon to kill a mosquito.
Unbounded queue — unlimited capacity, upstream writes freely. Simplest to implement but provides zero flow control. If the downstream can't keep up, it's OOM. Unacceptable in production.
Drop without backpressure — when the upstream fills up, discard or overwrite. Works for real-time streaming media scenarios where dropping a few video frames goes unnoticed, but in an inference pipeline every token carries semantic meaning — dropping one means getting it wrong.
Comparing horizontally across these options, for the specific set of constraints we face — cross-process shared memory for large tensors, mismatched upstream/downstream speeds, and long-running operation — pre-allocated fixed slots semaphore counting is almost the most natural choice: zero fragmentation, bounded memory, built-in backpressure.
The more I work on systems design, the more I feel this: the hard part isn't coming up with a clever solution — it's recognizing, among a pile of solutions that all "seem to work," the one whose constraint alignment is the tightest. The credit mechanism is exactly this — at first glance it seems too textbook, but a textbook solution running stably in production means the problem was modeled correctly in the first place.

8
69
8,078
Apr 9
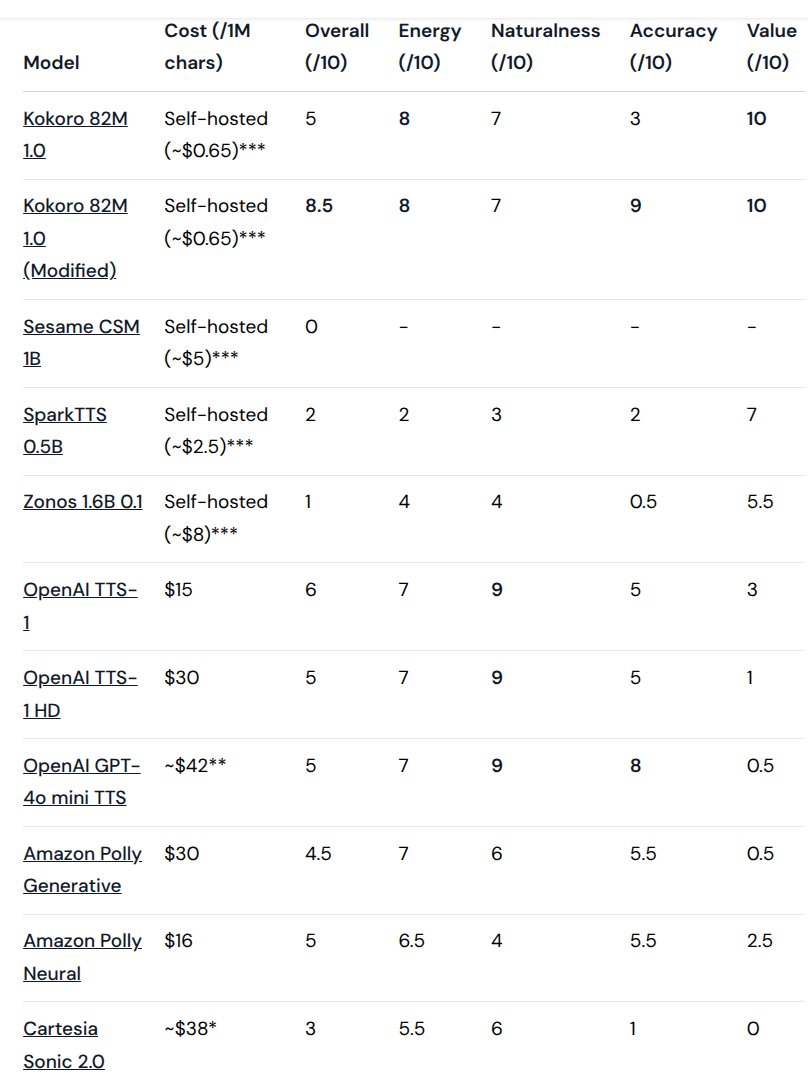
Interesting tiny 1.6M params TTS engine, based on StyleTTS
github.com/tronghieuit/tiny-…
1
4
85
7,948

🚀 VoxCPM 2 is live!
🎉 Another open-source AI #TTS model from China — and one that stands shoulder to shoulder with Qwen3-TTS, while bringing everything into a single unified model. After rapid iterations from V1 (zero-shot cloning) to V1.5 (long-form fine-tuning), #VoxCPM has consistently pushed quality and usability forward.
Now, VoxCPM 2 takes it further:
🔹30 languages — truly global, truly local.
🔹Infinite voice design — type it, hear it, control it. From a whisper to a booming cinematic voice.
🔹Studio-grade audio — 48kHz ultra-high fidelity with emotional depth
🔹Diffusion-Autoregressive cloning — preserves more acoustic and emotional detail than token-based models like Qwen3-TTS
💡 Big shoutout to @grok — used your multi-image video magic for our launch demo. It’s scarily good at keeping visuals consistent across shots. Elon @elonmusk, this one’s for you. 😉
Check the demo & start cloning your dream voice:
🌐 Hugging Face Space: huggingface.co/spaces/openbm…
🤗 Hugging Face Model: huggingface.openbmb.com/mode…
🤖 ModelScope Model: modelscope.cn/models/OpenBMB…
💻 GitHub:github.com/OpenBMB/VoxCPM/
#TTS #AI #VoiceCloning #GrokImagine #ElonMusk #OpenBMB #VoxCPM
144
96
472
556,378