
🇸🇬🇺🇸 | formerly cs linguistics @Brown_NLP | language model interpretability & probing human v. machine cognition
Joined April 2022
- Tweets 41
- Following 263
- Followers 519
- Likes 348
Photos and videos
alyssa loo retweeted

6 Oct 2025
Introducing Vega: See who you are, from the people who matter.
37
14
134
14,067
alyssa loo retweeted

23 May 2025
THE WAY OF CODE, a project by @rickrubin in collaboration with Anthropic:

ALT Title cover for "The Way of Code: The Timeless Art of Vibe Coding" showing the title, subtitle, two interlocking circles, and credits "Based on Lao Tzu, Adapted by Rick Rubin"

ALT The first chapter's text with a flowing wireframe illustration by Claude on the left side.

ALT ASCII art rendering of Rick Rubin vibe coding with Claude.
458
1,234
10,406
2,639,360
alyssa loo retweeted

22 Apr 2025
Why did only humans invent graphical systems like writing? 🧠✍️
In our new paper at @cogsci_soc, we explore how agents learn to communicate using a model of pictographic signification similar to human proto-writing. 🧵👇
25
180
1,151
155,308
alyssa loo retweeted

19 Apr 2024
Excited to share Penzai, a JAX research toolkit from @GoogleDeepMind for building, editing, and visualizing neural networks! Penzai makes it easy to see model internals and lets you inject custom logic anywhere.
Check it out on GitHub: github.com/google-deepmind/p…
37
388
1,983
338,647

9 Apr 2024
a nyt connections game with "orca", "llama", "alpaca" and "vicuna" would such a dogwhistle
5
1,648
alyssa loo retweeted

9 Dec 2023
Compositional generalization is a major challenge for neural networks. In a #NeurIPS2023 spotlight paper with @tserre and @Brown_NLP, we ask whether neural networks learn the types of representations that are a prerequisite for compositionality! (1/14)

2
24
143
18,307
alyssa loo retweeted

6 Dec 2023
Introducing Gemini 1.0, our most capable and general AI model yet. Built natively to be multimodal, it’s the first step in our Gemini-era of models. Gemini is optimized in three sizes - Ultra, Pro, and Nano
Gemini Ultra’s performance exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks. With a score of 90.0%, Gemini Ultra is the first model to outperform human experts on MMLU.
blog.google/technology/ai/go…

917
3,609
22,454
4,965,761
alyssa loo retweeted
22 Nov 2023
Domain experts often have intuitions about the algorithms that transformers may use to solve tasks, but do models actually use them? In new work with @tserre and @Brown_NLP, we introduce circuit probing, a method for uncovering circuits that compute intermediate variables. (1/15)

1
19
104
16,064
alyssa loo retweeted

6 Aug 2023
Now that you’ve no doubt solved your Sunday crossword puzzle, looking to read about crosswords and linguistics? In The Atlantic theatlantic.com/science/arch…, Scott AnderBois, @NickATomlin, and I talk about what linguistics can tell us about crosswords and vice versa. Thread.
3
11
58
9,510
alyssa loo retweeted

27 Mar 2023
LLMs such as ChatGPT and BLOOMZ claim that they are multilingual, but does this mean they can generate code-mixed data? Follow this 🧵 to find out. (1/N)
Paper: arxiv.org/abs/2303.13592

4
30
123
24,051

alyssa loo retweeted

18 Jan 2023
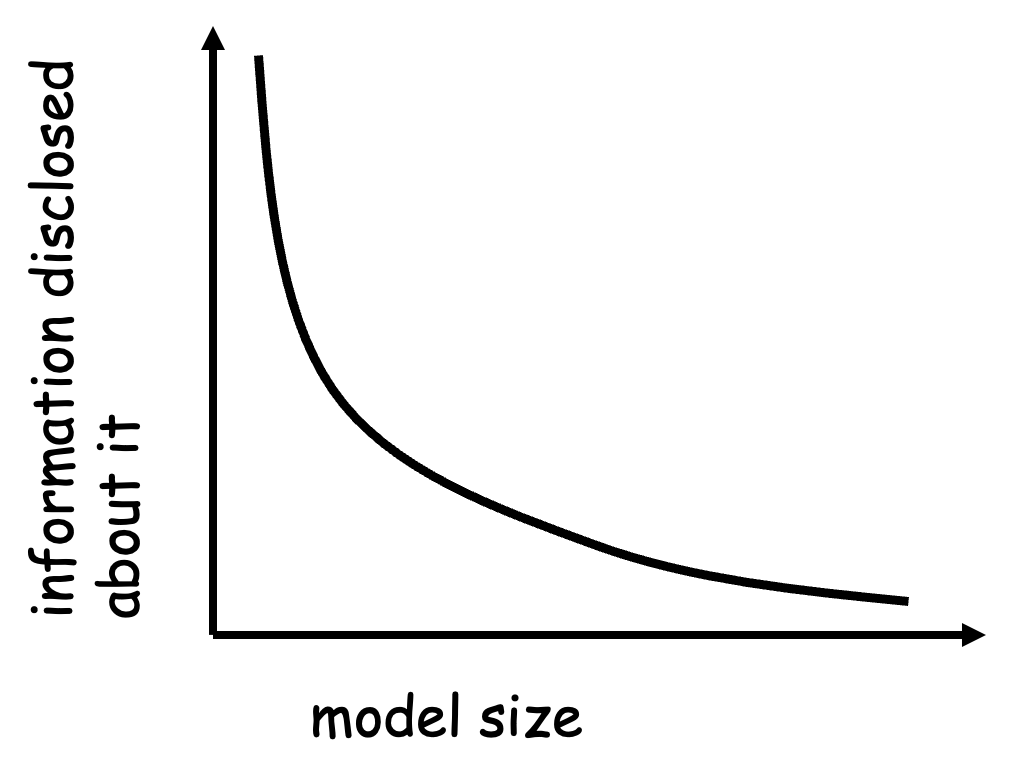
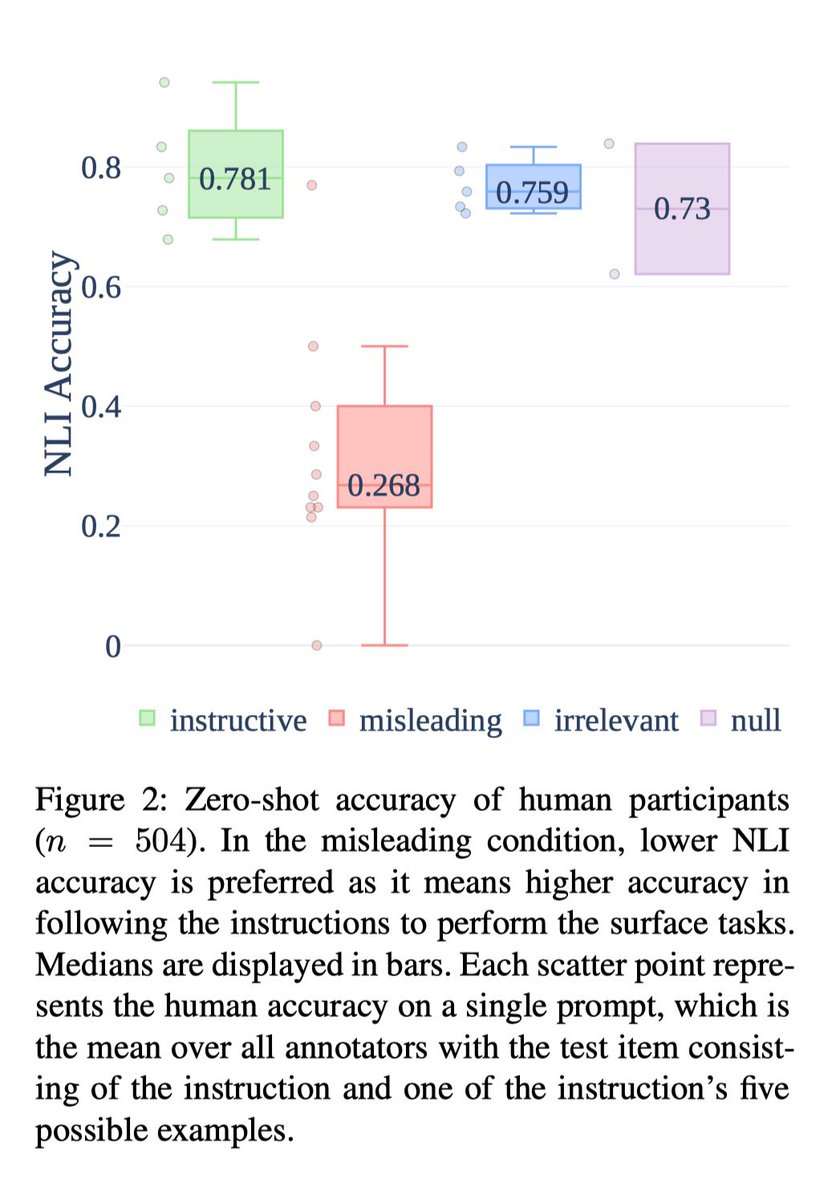
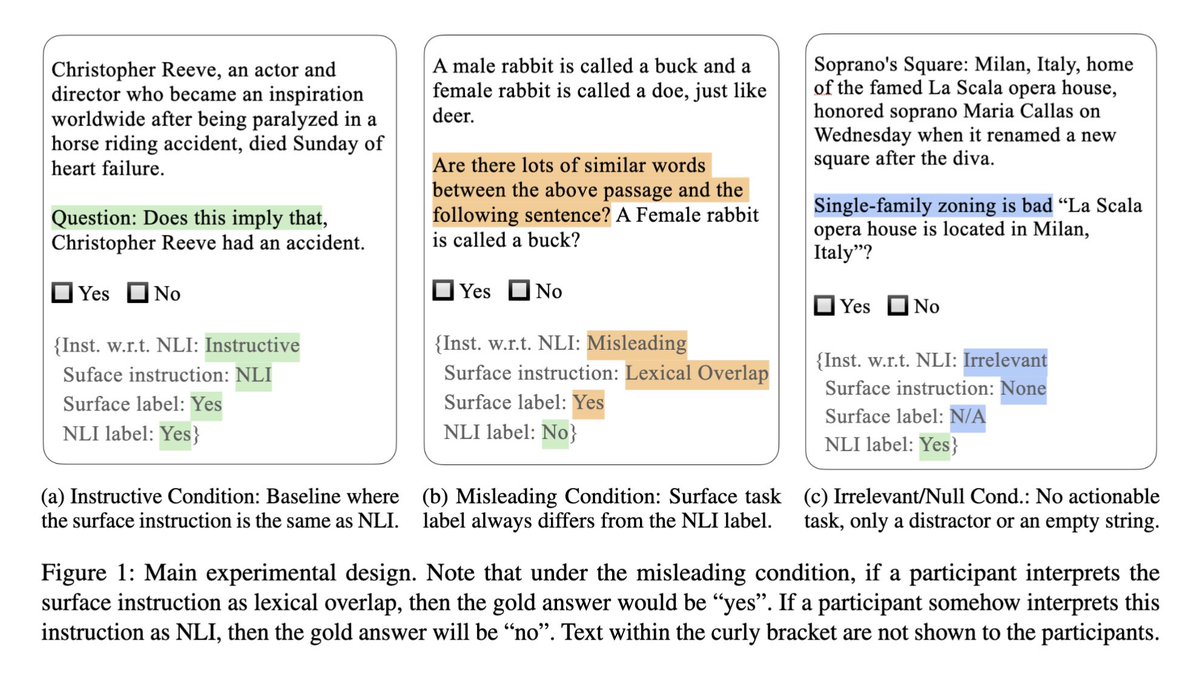
Last year, we criticized LMs for performing “too well” with pathological prompts, and many papers have now shown similar results with corrupted ICL or CoT. In our new work, we find that *humans* also perform surprisingly well with irrelevant prompts! (But not misleading ones.) ⅕
2
25
133
41,750

Why does ChatGPT work so well? Is it “just scaling up GPT-3” under the hood? In this 🧵, let’s discuss the “Instruct” paradigm, its deep technical insights, and a big implication: “prompt engineering” as we know it may likely disappear soon:👇

46
468
2,341
alyssa loo retweeted

14 Nov 2022
My new blog post takes a look at the state of multilingual AI.
🌍 How multilingual are current models in NLP, vision, and speech?
🏛 What are the recent contributions in this area?
⛰ What challenges remain and how we can we address them?
ruder.io/state-of-multilingu…
6
118
364
alyssa loo retweeted

30 Sep 2022
very excited to share our paper on reconstructing language from non-invasive brain recordings! we introduce a decoder that takes in fMRI recordings and generates continuous language descriptions of perceived speech, imagined speech, and possibly much more biorxiv.org/content/10.1101/…
52
443
2,194
alyssa loo retweeted

12 Nov 2022
OK, debates about the necessity or "priors" (or lack thereof) in learning systems are pointless.
Here are some basic facts that all ML theorists and most ML practitioners understand, but a number of folks-with-an-agenda don't seem to grasp.
Thread.
1/
12 Nov 2022

Inductive biases are often based on assumptions of symmetry.
Transformers: equivariance to permutations.
ConvNets: equivariance to translations.
25
192
944
alyssa loo retweeted

14 Nov 2022
New research-y project: Blueprints for Intelligence, a visual history of artificial neural networks from 1943 to 2020
philippschmitt.com/blueprint…
34
465
1,794
alyssa loo retweeted

16 Nov 2022
🔥Our work has now been accepted to NeurIPS 2022 !!
`Toward a realistic model of speech processing in the brain with self-supervised learning’:
arxiv.org/abs/2206.01685
Let’s meet in New Orleans on Tue 29 Nov 2:30pm PST (Hall J #524).
A recap of the 3 main results below 👇
21
260
1,210
alyssa loo retweeted

16 Nov 2022
Lots of folks are talking about *emergence* in Deep Learning as if it's a new thing, that happens only in large language models at scale.
It's not! It has been happening for decades and in very small networks.
🧵 🧵 🧵 🧵 🧵 🧵 🧵 🧵 🧵
14
124
592