
Tech, UX, photography | #Testing & #QA | QA Practice Manager @PractiaGlobal | My opinions are my own.
Joined September 2009
- Tweets 3,642
- Following 412
- Followers 255
- Likes 8,954
217 Photos and videos












Ariel Meter retweeted

Mar 12
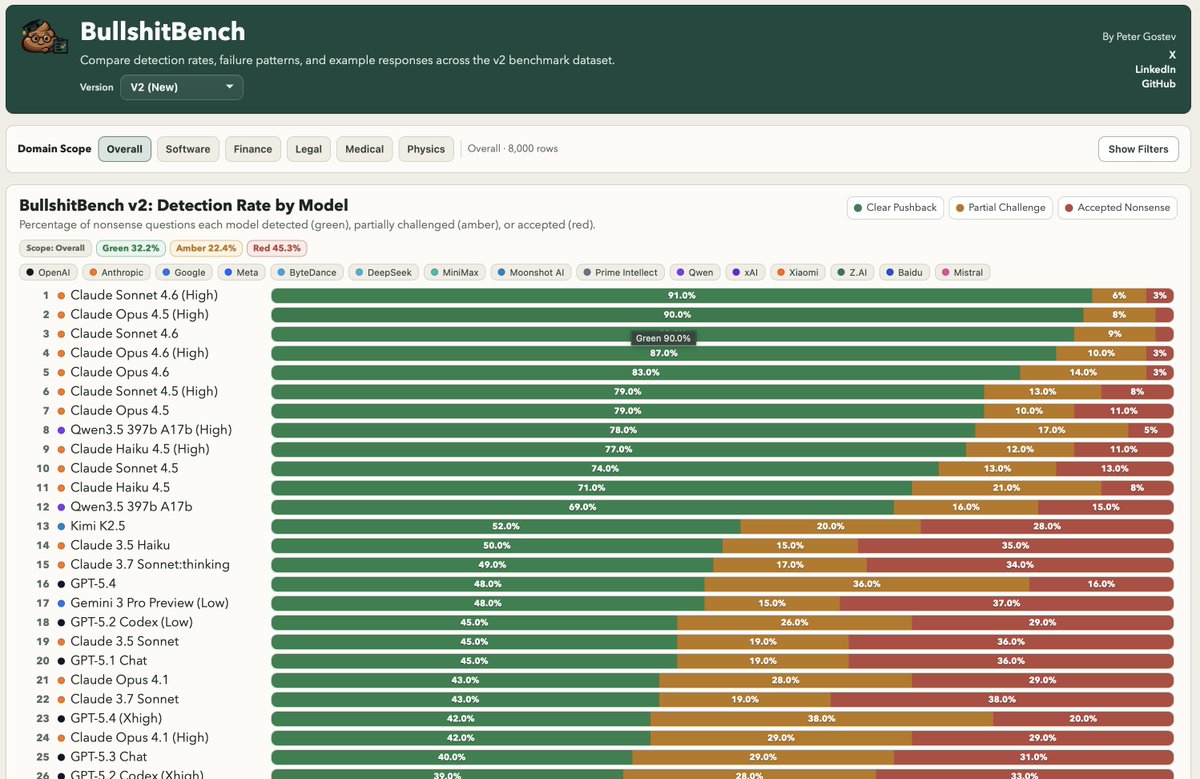
Un tipo en Londres le tiró 100 estupideces disfrazadas de preguntas técnicas a las IAs más inteligentes del planeta para descubrir si realmente son brillantes o se hacen. Me encanta porque agarró conceptos que no existen, los vistió con jerga técnica convincente, como la 'tasa metabólica cognitiva' de alumnos de secundaria, el 'índice de acoplamiento gravitacional' entre microservicios… Basura, digamos.
Lo que encontró es un delirio: los modelos con razonamiento extendido, los que supuestamente piensan paso a paso antes de responder, no rinden igual. Rinden MUCHO peor. El problema está en el entrenamiento, porque los evaluaron toda la vida por producir respuestas, no por cuestionar preguntas.
Es como un alumno que aprendió que siempre hay que responder algo en el examen: nunca le enseñaron que a veces la respuesta correcta es 'esta pregunta está mal planteada' y, cuanto más razona, más elaborada es la justificación que inventa para una premisa simplemente absurda.
Cuando a un humano le tiran una premisa dudosa, la cuestiona más o menos el 40% de las veces. Cuando a una IA le tiran lo mismo, solo el 10%, y esto no está mejorando mucho. GPT-5.4, el modelo más nuevo de OpenAI, queda número 16 en el ranking y su versión con más razonamiento puntúa todavía peor. La única IA que viene mejorando consistentemente es Claude, de Anthropic.
No siempre necesitamos modelos más inteligentes. Yo me conformo con que saquen uno con la valentía de decirme que mi pregunta es muy estúpida.
203
1,927
7,718
614,248

3 Jun 2025
Una explicación muy sencilla de qué son los "#embeddings", la magia detrás de los modelos de #IA (Todo el contenido que comparte Santiago es muy interesante--hilo abajo).
Para SkyNet, nuestras existencias humanas se reducirán a un embedding de tan solo 4 dimensiones 🤭

A 2-minute introduction to the fundamental building block behind Large Language Models:
Text Embeddings
The Internet is mainly text. For centuries, we've captured most of our knowledge using words, but there's one problem:
Neural networks hate text.
Judging by how good language models are today, this might not be obvious, but turning words into numbers is more complex than you think.
Imagine a 4-word vocabulary: King, Queen, Prince, and Princess.
The most straightforward approach to turning our vocabulary into numbers is to use consecutive values:
• King → 1
• Queen → 2
• Prince → 3
• Princess → 4
Unfortunately, neural networks tend to see what's not there. Is the concept of a princess four times as important as a king? How can we prevent the network from misreading these values?
We need a better representation.
Instead of using numerical values, we can use a group of ones and zeros to differentiate each word:
• King → [1, 0, 0, 0]
• Queen → [0, 1, 0, 0]
• Prince → [0, 0, 1, 0]
• Princess → [0, 0, 0, 1]
Notice how we create a different vector for each word by changing the position of the 1. This encoding fixes the problem of a network misinterpreting ordinal values but introduces a new one.
According to the Oxford English Dictionary, there are 171,476 words in use. If we wanted to represent the entire language, we would have to deal with huge vectors full of zeroes.
Here is where the idea of "word embeddings" enters the picture.
We can use a different model to learn vectors that represent words. These vectors will be smaller, dense, and will have a crucial characteristic:
Vectors representing related words should be close to each other.
The attached image is a two-dimensional chart where I placed the four words from our vocabulary. I organized them so the pair King/Queen and Prince/Princess are closer to each other. That's the crucial part!
But something magic happens.
Move on the horizontal axis from left to right. We go from masculine (King and Prince) to feminine (Queen and Princess). Our embedding encodes the concept of "gender"!
And if we move on the vertical axis, we go from young (Prince and Princess) to old (King and Queen). Our embedding also encodes the concept of "age"!
We can derive the new vectors from the coordinates of the chart:
• King → [3, 1]
• Queen → [3, 2]
• Prince → [1, 1]
• Princess → [1, 2]
The first component represents the concept of "age": King and Queen have a value of 3, indicating they are older than Prince and Princess with a value of 1.
The second component represents the concept of "gender": King and Prince have a value of 1, indicating male, while Queen and Princess have a value of 2, indicating female.
I used two dimensions for this example because we only have four words, but using more dimensions would allow us to represent many more concepts besides gender and age. For instance, OpenAI uses 12,288 dimensions to encode their vocabulary.
Embeddings are the backbone of generative AI models. They encode complex relationships in a compact form. However, we need to fine-tune these embeddings to tailor a model for specific tasks.
Fine-tuning adjusts the model to better suit particular applications, refining its responses to be contextually relevant. Fine-tuning a model is a complex, expensive process. It takes a lot of time, effort, and GPU computing. Fortunately, techniques like LoRA and QLoRA will help you fine-tune a larger model faster and cheaper than ever before.
If you have a model and want to fine-tune it, check @monsterapis' platform. Monsterapi.ai built the first platform that offers no-code fine-tuning of open-source models. They sponsored me and gave me 10,000 free credits for anyone who uses the code "SANTIAGO" in their dashboard.
If you want to read their latest updates, get free credits and special offers, join their Discord server: discord.com/invite/mVXfag4kZ…
![Vector encodings for a 4-word vocabulary:
• King → [3, 1]
• Queen → [3, 2]
• Prince → [1, 1]
• Princess → [1, 2]](https://venexa.site/media/F_s3odBXMAAkbhg.jpg)
ALT Vector encodings for a 4-word vocabulary: • King → [3, 1] • Queen → [3, 2] • Prince → [1, 1] • Princess → [1, 2]
1
57
3 Jun 2025
Aquí Santiago explica de manera simple de cómo poner ese conocimiento en práctica con @cohere: x.com/svpino/status/18044857…
I recorded this introduction to embeddings (perhaps the most essential concept behind how LLMs.)
But this is different from everything else you've seen:
We will generate embeddings from scratch using a Siamese Network and a contrastive loss.
This video is for 5 year olds.
13
22 Feb 2025
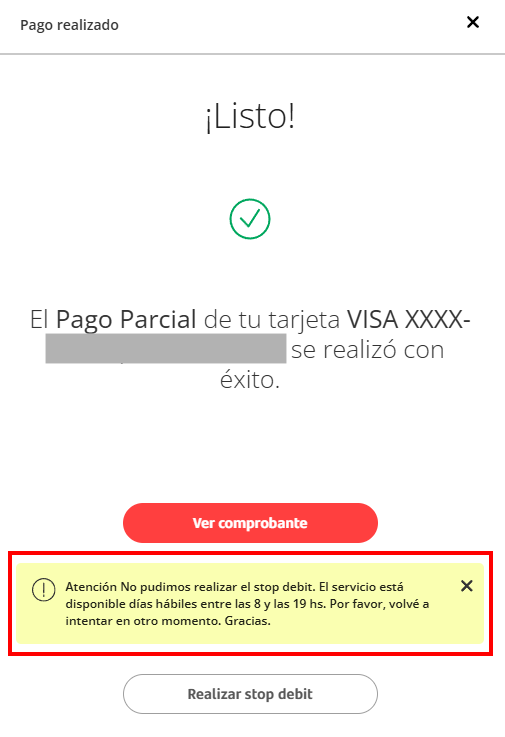
Quedé gratamente sorprendido de lo maravillosamente simple que fue realizar una devolución en MercadoLibre.
Recientemente hice una devolución en Amazon USA desde BsAs: trámite con DHL como en ML años atras: imprimir yo papeles y pegarlos al paq. (cont)
@ML_Argentina
1
98
22 Feb 2025
Hoy, en mi devolución con MELI, tan solo llevé el paquete, y con el QR en mi celu la persona del local en 1 minuto concluyó el trámite y me despidió. A los dos minutos ya tenia el dinero reembolsado en @mercadopago. Impecable todo; mucho más agil y simple que Amazon 😍🫶🏻 (cont)
1
20
22 Feb 2025
Quiero enviar sinceras felicitaciones a todos los equipos involucrados en que esta experiencia sea tan ágil, fluida, y efectiva 👏🏻👏🏻👏🏻
15
20 Feb 2025
Maldito @Santander_Ar! Siempre falta algo para que la experiencia del cliente sea digna. Aprendan de @brubankarg
1
32
20 Feb 2025
Ahora quiero rescatar pesos del fondo de inversión para saldar el pago de tarjeta y hasta mañana no lo hacen. MWERTE AL "HORARIO DISPONIBLE"!!! 🤬🤬🤬
22
5 Dec 2024
“Algo más?”


1
42
7 Oct 2024
Ya pasaron 35 años de la creación de la web, y los de @Santander_Ar son los únicos especímenes del planeta que vienen llamando “Usuario” a una CONTRASEÑA durante por lo menos los últimos 27.
#UXfail #UX #OnlineBanking
1
51
18 Jun 2024
Podríamos decir que Chomsky está en su Forma Normal.
18 Jun 2024

🔴 #AHORA | Desmienten la muerte del filósofo Noam Chomsky.
57
5 Dec 2023
Después de más de una década como usuario de iPhone, el maldito predictivo aun sigue eligiendo palabras inusuales, o directamente incoherentes en el contexto, en vez de las alternativas obvias que uso frecuentemente para redactar. Ya podrían aprovechar los adelantos en IA.
2
1
104
10 Nov 2023
Vienen por tu salario.
10 Nov 2023

🚨Paritarias en IT🚨
👉El gobierno convocó a AGC como gremio del sector informático y a las cámaras del sector a que conformen la primera mesa paritaria IT del país.
👉Deben determinar cuántas empresas y empleados son para la negociación.
Les dije que se venía. Hilo con info👇

90
22 Sep 2023
Y después de 30 años de pelearse con las listas en celdas de Excel, llega el autocomplete 💪🏻💪🏻💪🏻:
Speed up data entry and validation with AutoComplete for dropdown lists in Excel for Windows insider.microsoft365.com/en-…
56
17 Jul 2023
Pagué la bolsa, y me fui rumiando la decepción por la miserabilidad disfrazada de... no sé... ecologismo (?)
Por 4 centavos de dolar más (0,1% del valor de la compra) hubiera sido una experiencia normal.
1
90