
Joined January 2012
- Tweets 9,447
- Following 1,037
- Followers 47,966
- Likes 11,126
218 Photos and videos












Andreas Mueller retweeted

25 Mar 2025
📢 We are excited to announce "#FMSD: 1st Workshop on Foundation Models for Structured Data" has been accepted to #ICML 2025! Call for Papers: icml-structured-fm-workshop.…

3
13
24
7,674
Andreas Mueller retweeted

7 May 2025
Open protocols like A2A and MCP are key to enabling the agentic web. With A2A support coming to Copilot Studio and Foundry, customers can build agentic systems that interoperate by design.
7 May 2025

We are entering a new era in business where agents will not only act independently but also work together as a team. To bring this vision to life, open protocols like Model Context Protocol (MCP) and Agent2Agent (A2A) are essential for agent interoperability.
I am excited to announce that Copilot Studio and Azure AI Foundry will support A2A, building on the MCP support we announced earlier this spring. We have also joined the A2A working group on GitHub to help shape the spec and tooling.
This is a significant step forward and I can’t wait to see how it will transform the way we work. Find out more here: microsoft.com/en-us/microsof…
83
207
1,471
243,537

11 Feb 2025
New preprint arxiv.org/abs/2502.05392
Open Challenges in Time Series Anomaly Detection: An Industry Perspective
This is a vision paper about what I think it missing from current research in time series anomaly detection, and how it could align better with practical applications.
4
3
11
2,083
Andreas Mueller retweeted

3 Jan 2025
is that "agentic" enough🤣

73
176
1,996
150,106


Andreas Mueller retweeted

8 Jan 2025
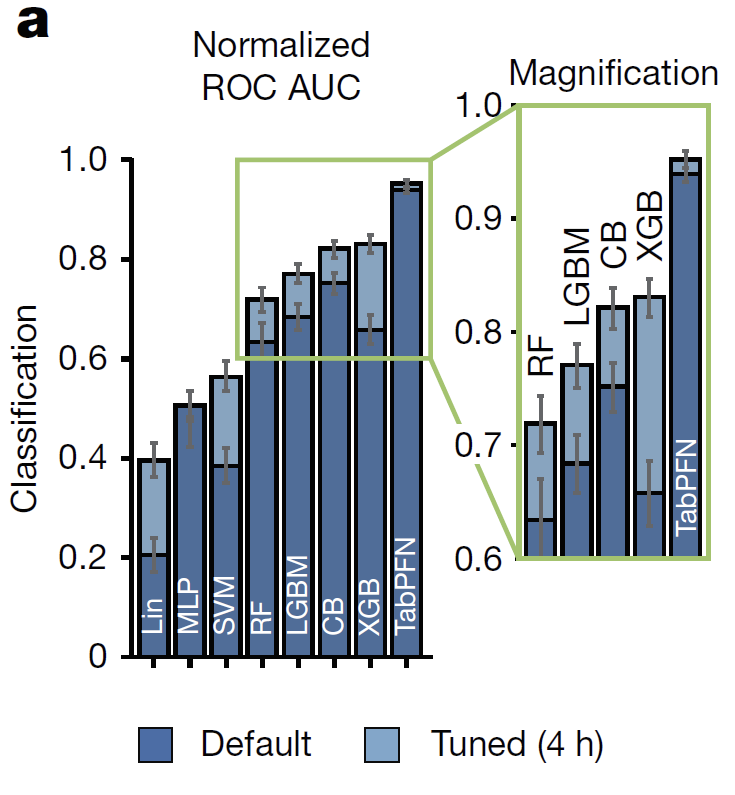
The data science revolution is getting closer. TabPFN v2 is published in Nature: nature.com/articles/s41586-0… On tabular classification with up to 10k data points & 500 features, in 2.8s TabPFN on average outperforms all other methods, even when tuning them for up to 4 hours🧵1/19
35
243
1,365
263,666
Andreas Mueller retweeted

20 Dec 2024
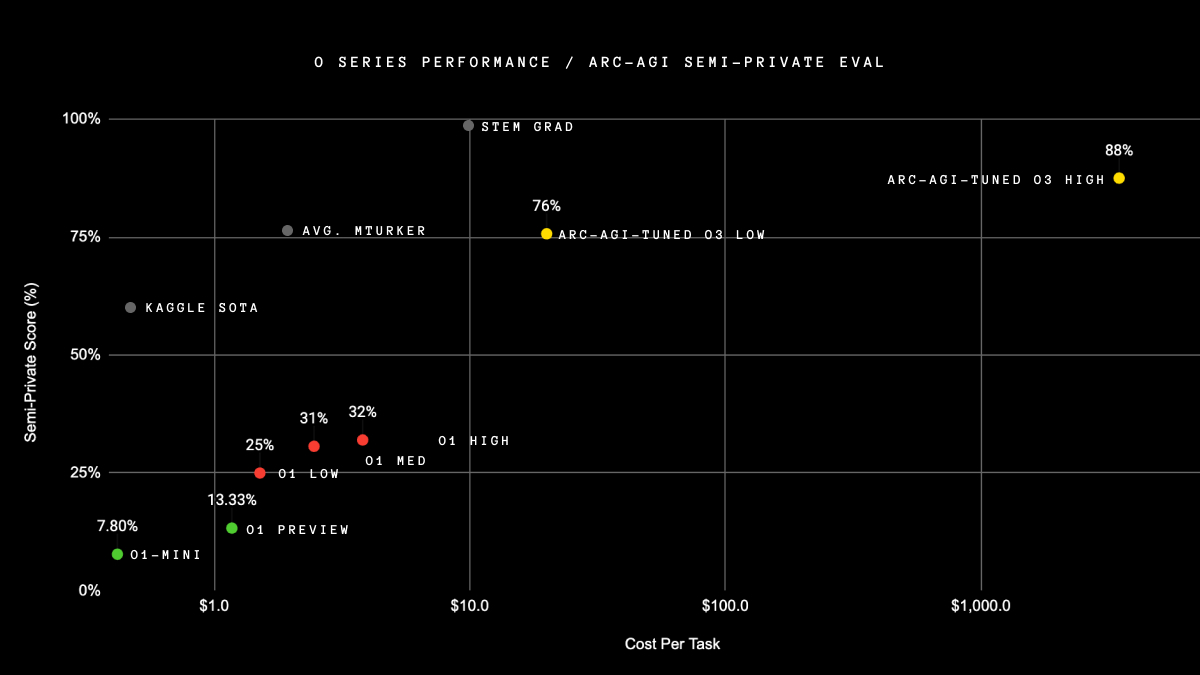
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute -- these capabilities are new territory and they demand serious scientific attention.
202
1,563
8,640
2,226,697
Andreas Mueller retweeted

20 Sep 2024
Congrats to my friends at @Microsoft on getting Python in Excel to GA!
techcommunity.microsoft.com/…
1
5
52
5,693
15 Aug 2024
I'm pretty frustrated with the current review process in ML (both from an author, reviewer and meta-reviewer perspective). There's possible solutions or at least experiments and changes, but I feel like business as usual is no longer feasible.
3
1
22
3,317
15 Aug 2024
There's a great overview of challenges and proposals here: Great summary here: NeurIPS 2023 Tutorial (cmu.edu) (check slides and doc). If you agree that something needs to change, I'd suggest talking to a PC member or conference organizer.
1
1
7
2,528
Andreas Mueller retweeted

19 Jul 2024
Wondering how humans should be involved in designing #AutoML solutions 🤔? Check out our #ICML2024 paper: "Position: A Call to Action for a Human-Centered AutoML Paradigm"! 📄✨ proceedings.mlr.press/v235/l…
Drop by at our poster on Thu, Jul 25 at 11:30 AM in Hall C 4-9 #2003 📅
1/3
7
4
12
2,330

We are proud to release the first major version of DuckDB, v1.0.0, codenamed "Snow Duck".
This version is a culmination of almost six years of research and development. Today we are shipping an innovative database system with a backwards-compatible storage format.
Check out our announcement blog post: duckdb.org/2024/06/03/announ…

25
271
985
123,368
Andreas Mueller retweeted

14 May 2024
Columnar file formats like Parquet/ORC are ubiquitous. Our VLDB paper with @XinyuZeng218 @huanchenzhang @wesmckinn studies their internals.
TLDR: They're not optimized for modern hardware. Something new is needed.
Paper: vldb.org/pvldb/vol17/p148-ze…
Code: github.com/XinyuZeng/Evaluat…
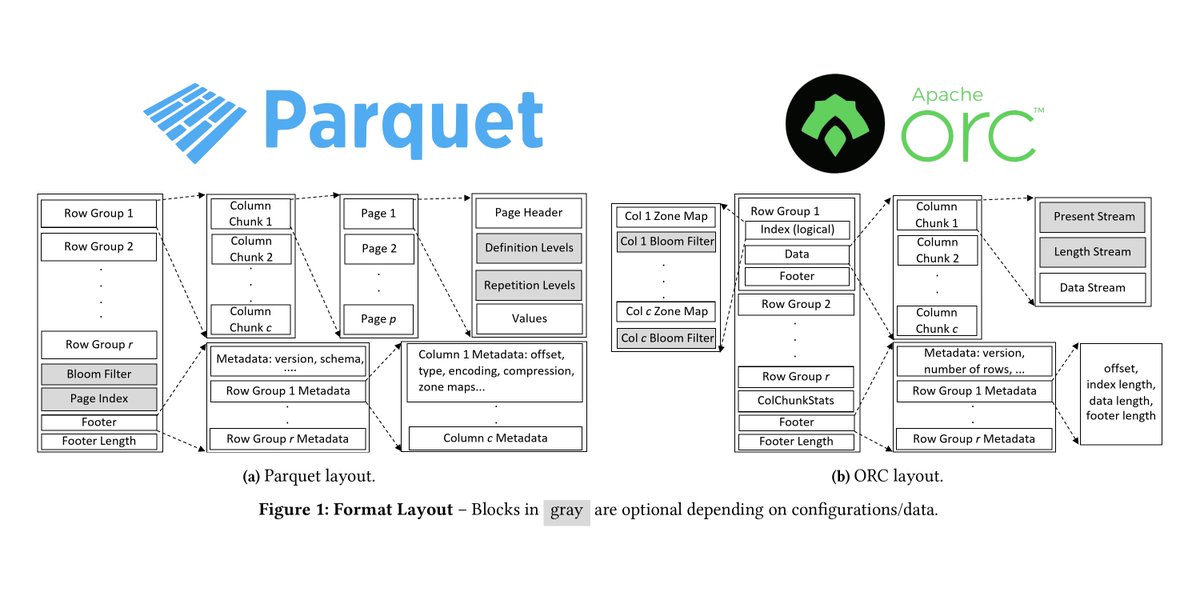
ALT Architecture diagrams of the Parquet ORC file formats.
11
149
742
95,661
Andreas Mueller retweeted

13 May 2024
Not only is this the best model in the world, but it's available for free in ChatGPT, which has never before been the case for a frontier model.
26
61
884
135,206
Andreas Mueller retweeted
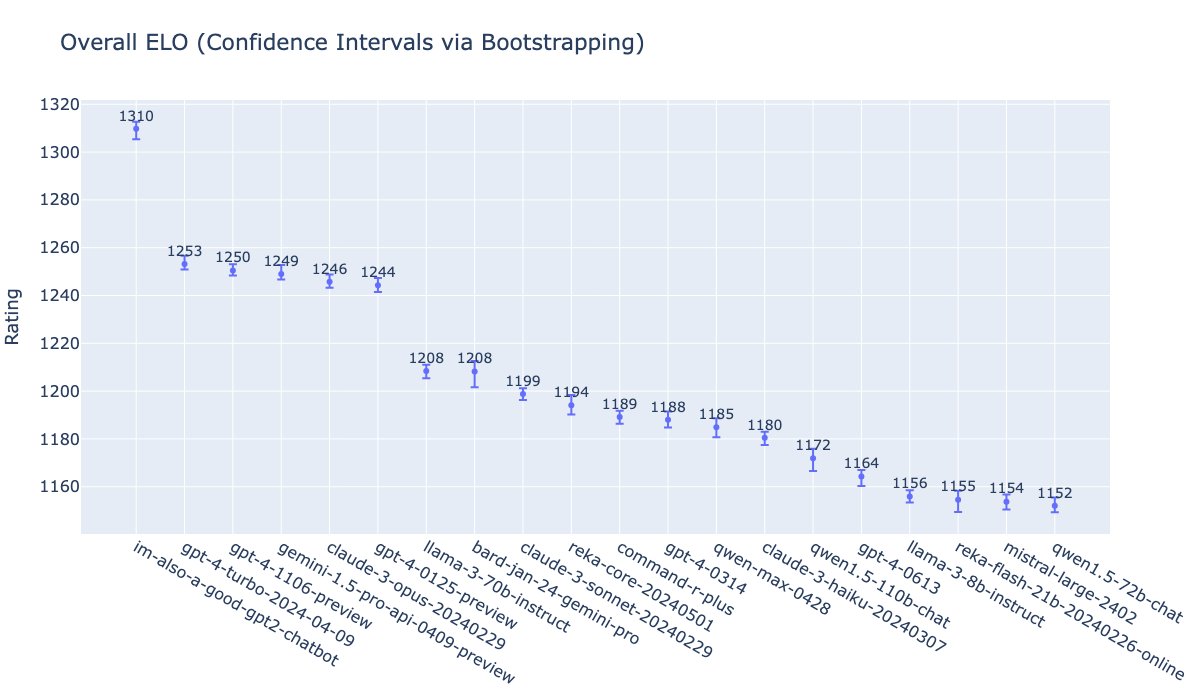
13 May 2024
GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing.
176
833
4,454
3,258,545
Andreas Mueller retweeted

18 Apr 2024
Congrats to @AIatMeta on Llama 3 release!! 🎉
ai.meta.com/blog/meta-llama-…
Notes:
Releasing 8B and 70B (both base and finetuned) models, strong-performing in their model class (but we'll see when the rankings come in @ @lmsysorg :))
400B is still training, but already encroaching GPT-4 territory (e.g. 84.8 MMLU vs. 86.5 4Turbo).
Tokenizer: number of tokens was 4X'd from 32K (Llama 2) -> 128K (Llama 3). With more tokens you can compress sequences more in length, cites 15% fewer tokens, and see better downstream performance.
Architecture: no major changes from the Llama 2. In Llama 2 only the bigger models used Grouped Query Attention (GQA), but now all models do, including the smallest 8B model. This is a parameter sharing scheme for the keys/values in the Attention, which reduces the size of the KV cache during inference. This is a good, welcome, complexity reducing fix and optimization.
Sequence length: the maximum number of tokens in the context window was bumped up to 8192 from 4096 (Llama 2) and 2048 (Llama 1). This bump is welcome, but quite small w.r.t. modern standards (e.g. GPT-4 is 128K) and I think many people were hoping for more on this axis. May come as a finetune later (?).
Training data. Llama 2 was trained on 2 trillion tokens, Llama 3 was bumped to 15T training dataset, including a lot of attention that went to quality, 4X more code tokens, and 5% non-en tokens over 30 languages. (5% is fairly low w.r.t. non-en:en mix, so certainly this is a mostly English model, but it's quite nice that it is > 0).
Scaling laws. Very notably, 15T is a very very large dataset to train with for a model as "small" as 8B parameters, and this is not normally done and is new and very welcome. The Chinchilla "compute optimal" point for an 8B model would be train it for ~200B tokens. (if you were only interested to get the most "bang-for-the-buck" w.r.t. model performance at that size). So this is training ~75X beyond that point, which is unusual but personally, I think extremely welcome. Because we all get a very capable model that is very small, easy to work with and inference. Meta mentions that even at this point, the model doesn't seem to be "converging" in a standard sense. In other words, the LLMs we work with all the time are significantly undertrained by a factor of maybe 100-1000X or more, nowhere near their point of convergence. Actually, I really hope people carry forward the trend and start training and releasing even more long-trained, even smaller models.
Systems. Llama 3 is cited as trained with 16K GPUs at observed throughput of 400 TFLOPS. It's not mentioned but I'm assuming these are H100s at fp16, which clock in at 1,979 TFLOPS in NVIDIA marketing materials. But we all know their tiny asterisk (*with sparsity) is doing a lot of work, and really you want to divide this number by 2 to get the real TFLOPS of ~990. Why is sparsity counting as FLOPS? Anyway, focus Andrej. So 400/990 ~= 40% utilization, not too bad at all across that many GPUs! A lot of really solid engineering is required to get here at that scale.
TLDR: Super welcome, Llama 3 is a very capable looking model release from Meta. Sticking to fundamentals, spending a lot of quality time on solid systems and data work, exploring the limits of long-training models. Also very excited for the 400B model, which could be the first GPT-4 grade open source release. I think many people will ask for more context length.
Personal ask: I think I'm not alone to say that I'd also love much smaller models than 8B, for educational work, and for (unit) testing, and maybe for embedded applications etc. Ideally at ~100M and ~1B scale.
Talk to it at meta.ai
Integration with github.com/pytorch/torchtune
134
989
7,613
885,866
Andreas Mueller retweeted

18 Apr 2024
🥁 Llama3 is out 🥁
8B and 70B models available today.
8k context length.
Trained with 15 trillion tokens on a custom-built 24k GPU cluster.
Great performance on various benchmarks, with Llam3-8B doing better than Llama2-70B in some cases.
More versions are coming over the next few months.
llama.meta.com/llama3/

204
1,106
6,966
572,412

We often get questions around why @VoltronData supports the Ibis project -- we've answered them here!
TL;DR: open standards are critical for the composable data ecosystem and tightly coupling Python dataframes to execution engines is bad for everyone
ibis-project.org/posts/why-v…
1
9
24
6,112
Andreas Mueller retweeted

2 Feb 2024
The rumors are true! I started a(nother) blog. sympathetic.ink/
The first post is an adaption of my talk, recalling the pas 10 years of building open source standards and the lessons learned along the way. sympathetic.ink/2024/01/24/T…
2
8
62
15,051
Andreas Mueller retweeted
12 Jan 2024
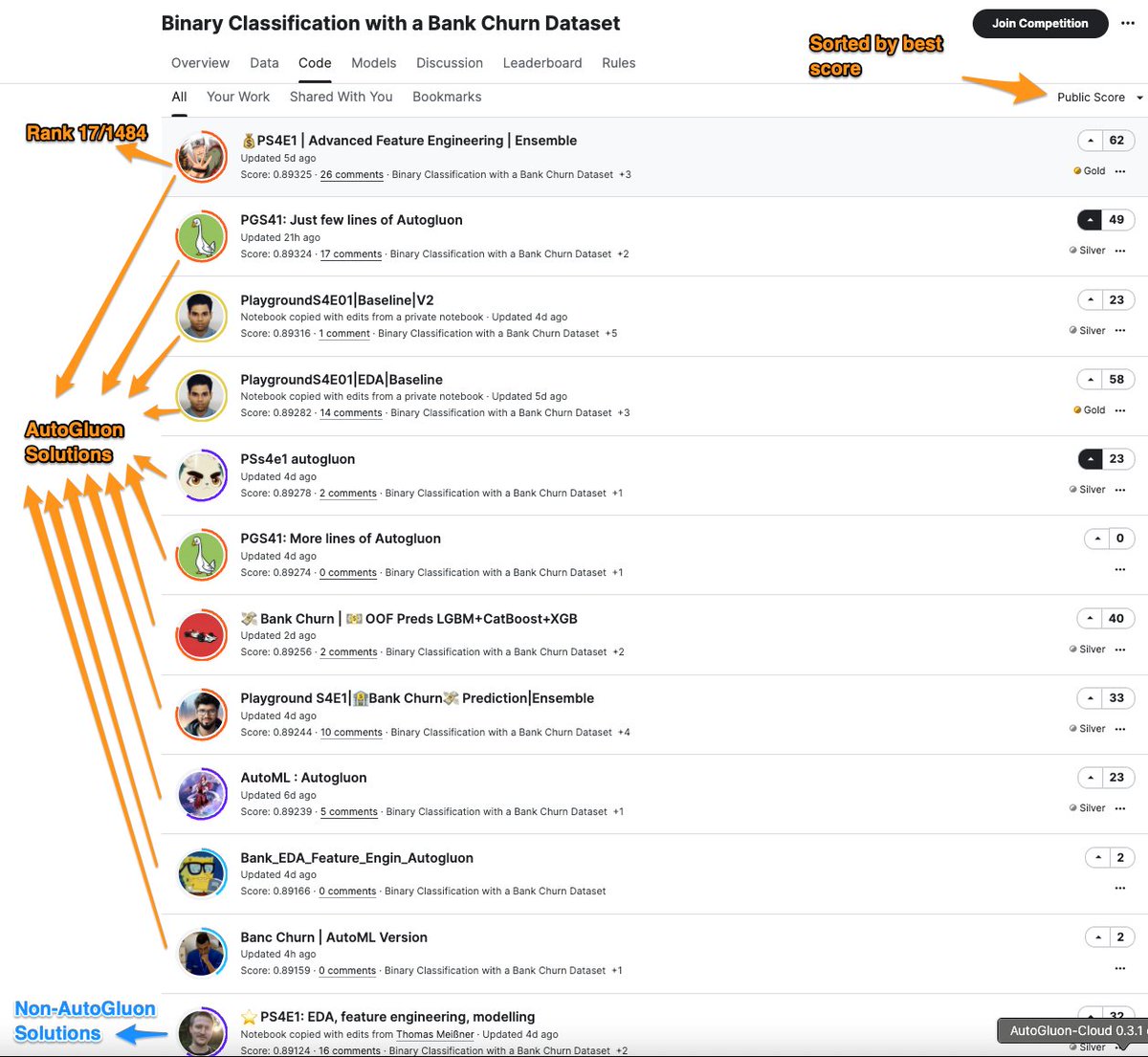
Kaggle's (@Kaggle) latest competition's top 11 highest scoring notebooks all use 🚀@AutoGluon AutoML🚀 to achieve their strong performance!
When I said that AutoGluon 1.0 was the largest jump in the state-of-the-art in 4 years, I meant it.
Competition: kaggle.com/competitions/play…
9
51
7,151