
Co-founder & CTO @ParallelDots - Leading AI platform for retail execution monitoring for Fortune 500 brands. Previously built @DentistryAI.IIT Kharagpur
Joined April 2009
- Tweets 4,317
- Following 1,129
- Followers 938
- Likes 3,789
77 Photos and videos












Pinned Tweet

Got featured in @ZeeNews Trusted leaders to look out for in 2026 zeenews.india.com/consumer-c…
1
30
Great to see @ParallelDots featured among Brands to Watch in 2026 by @htTweets.
Building ShelfWatch from India to serve Fortune 500 consumer brands in 50 countries has been one heck of a ride. The best is ahead. 🙏
tech.hindustantimes.com/bran…
20
AI's two-country race just became three.
cnbc.com/2026/04/24/cohere-a…
23
ANKIT NARAYAN SINGH ⚡️ retweeted

How To Stop Feature Creep And Prioritize Product Value hubs.li/Q04czVLR0 from @kedkorte @ankitnarayan1 @zentrumhub @bhivanov @uttam_alld @iamsalimg and more
1
1
75
This is exactly the kind of work that makes AI practical for enterprises. When inference gets 5x cheaper at the edge with zero accuracy loss, every enterprise gets unlimited budget to experiment!
Mar 25

I implemented Google's TurboQuant paper (ICLR 2026) in llama.cpp with Metal kernels for Apple Silicon.
4.9× KV cache compression. Working end-to-end on M5 Max with Qwen 3.5 35B MoE and Qwopus v2 27B.
Speed needs work (unoptimized shader), compression target met.
Repo: github.com/TheTom/turboquant…
**Note**: as you'll see from the git when I saw "I" it's in conjunction with claudecode and codex. Just lots of steering and babysitting.
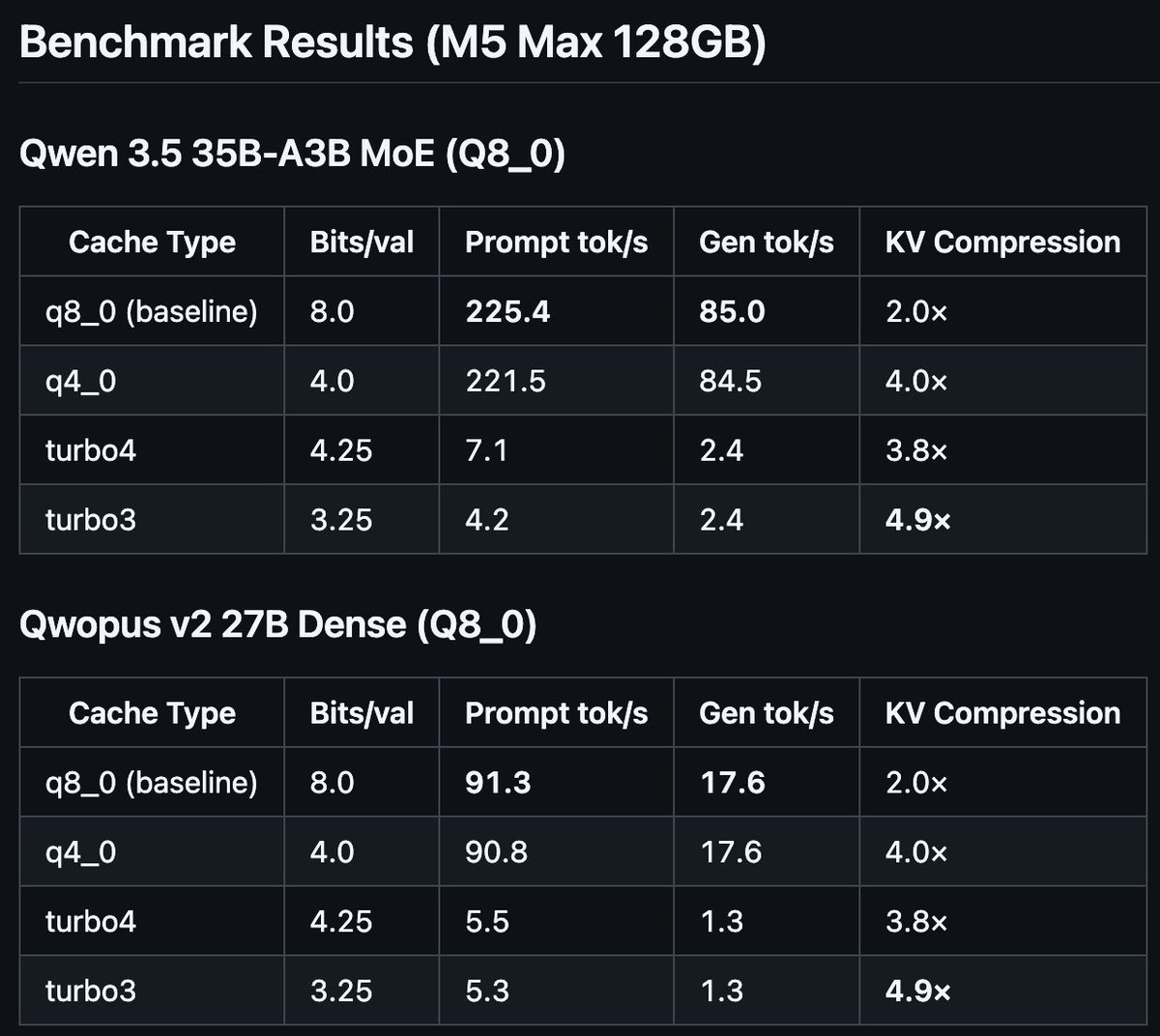
54
ANKIT NARAYAN SINGH ⚡️ retweeted

Mar 25
I implemented Google's TurboQuant paper (ICLR 2026) in llama.cpp with Metal kernels for Apple Silicon.
4.9× KV cache compression. Working end-to-end on M5 Max with Qwen 3.5 35B MoE and Qwopus v2 27B.
Speed needs work (unoptimized shader), compression target met.
Repo: github.com/TheTom/turboquant…
**Note**: as you'll see from the git when I saw "I" it's in conjunction with claudecode and codex. Just lots of steering and babysitting.
26
46
385
120,392
Sparse MoE is quietly becoming the architecture that makes enterprise AI agents economically viable. At ParallelDots we're seeing this firsthand where the inference cost curve is what unlocks real-world retail AI at scale, not just benchmark scores!
Apr 2

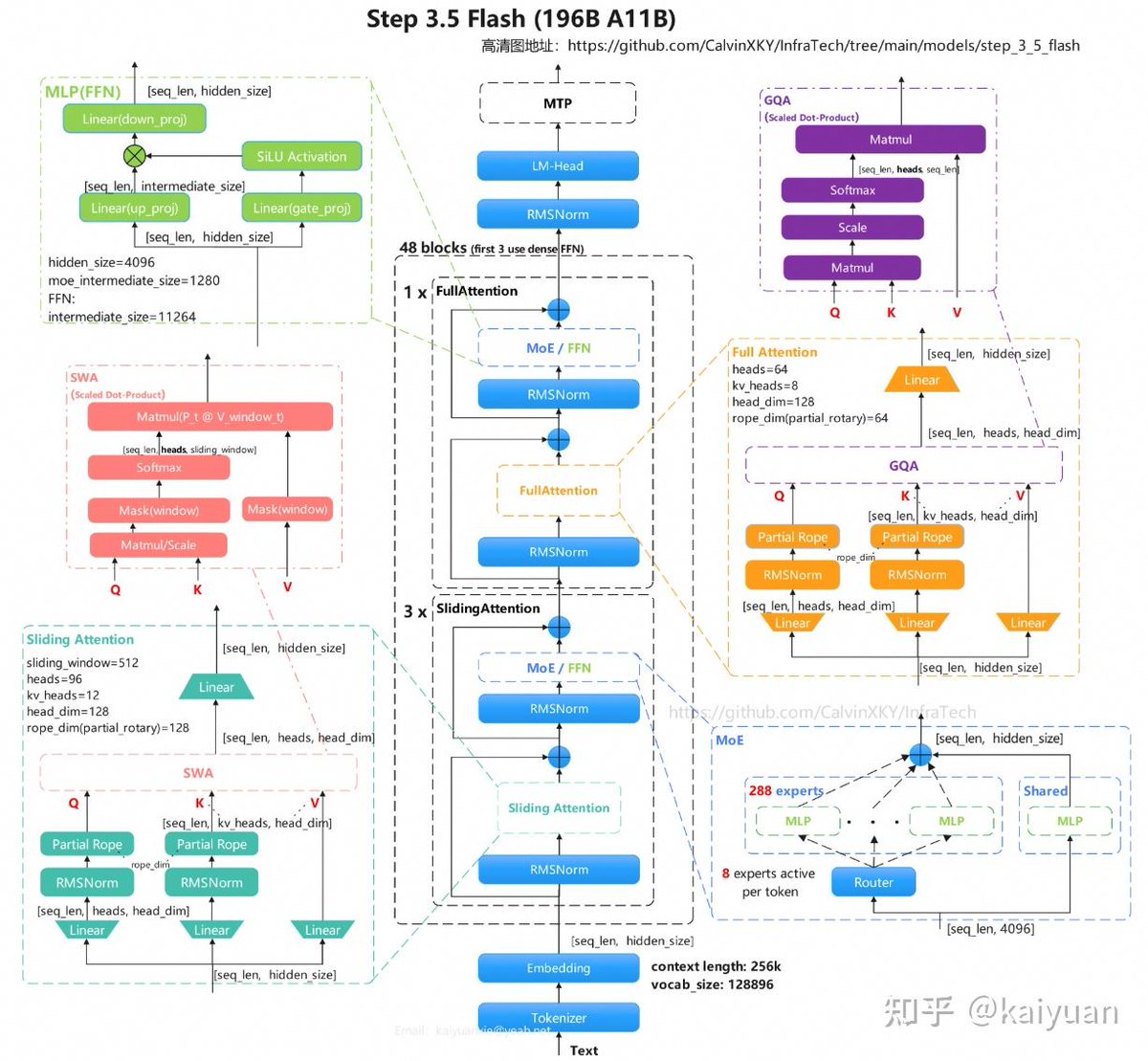
🧵As 2026 unfolds, sparse MoE models are emerging as the new backbone for high-throughput inference and Agent workloads. Step 3.5 Flash from StepFun @StepFun_ai stands out with its efficient attention mixture design.
Here’s a technical deep dive from Zhihu contributor kaiyuan 👇
🤖 Model Overview
• Open-source MoE LLM built for high-throughput inference & Agent scenarios
• Matches or exceeds leading models in reasoning, coding, and Agent benchmarks
• Delivers speed-quality balance via sparse MoE routing Multi-Token Prediction (MTP)
📐 Core Architecture
• Backbone: Transformer MoE | Total params: ~196B | Active params: 11B/token
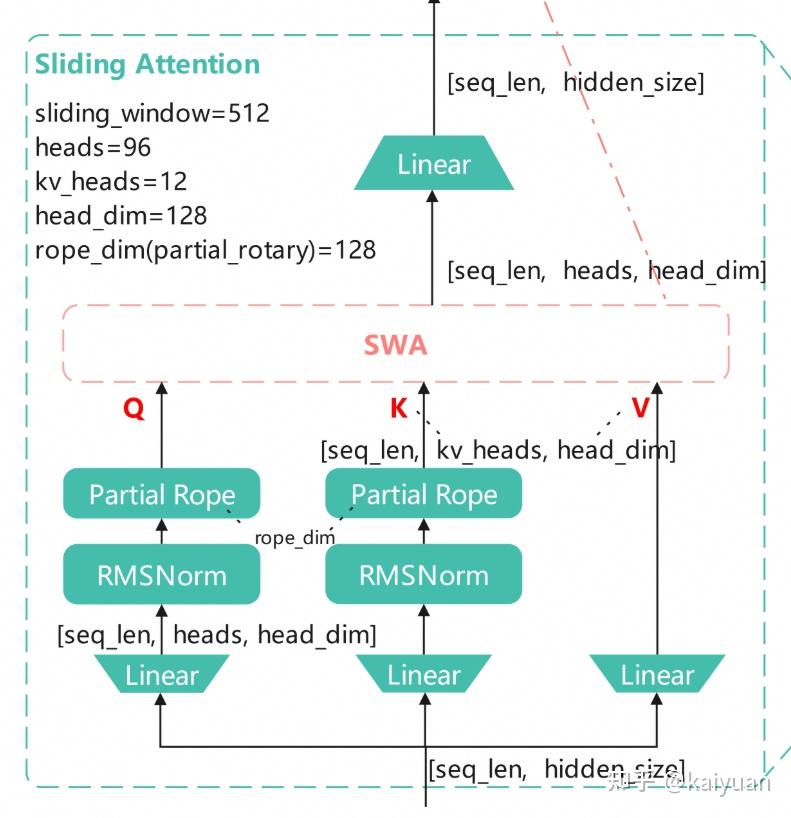
• Attention mix: GQA Sliding Window Attention (SWA) Full Attention
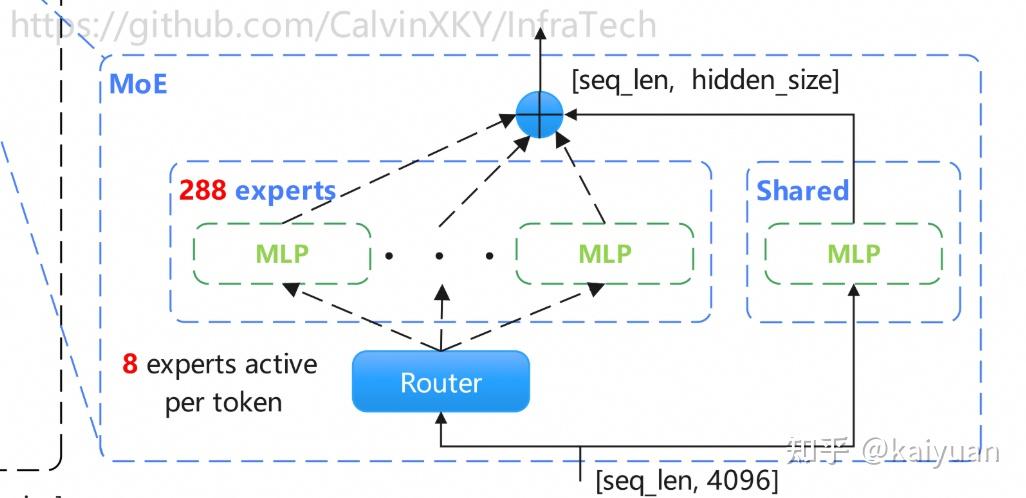
• Routing: 288 experts | Top-8 activation per token
• Context window: 256K (262144 max sequence length)
⚙️ Key Configs (config.json)
• Layers: 45 | Hidden dim: 4096 | Attention heads: 64
• Sliding window: 512 | Max sequence length: 256K
✨ Standout Features
• Sparse MoE Routing: 288 experts with Top-8 selection → cuts compute without losing capacity
• Dual Attention Mechanism: SWA for efficient local modeling (512-window) Full Attention for global context
• MTP Acceleration: Faster decoding for real-world interactive throughput
✅ Final Takeaway
Step 3.5 Flash proves that sparse MoE architectures can deliver enterprise-grade performance for long-context, high-throughput applications without proportional resource growth.
#AI #Engineering #Tech #LLM #Agent #StepFun
🔗 Full article(CN):zhuanlan.zhihu.com/p/2021161…
51

Three weeks ago I shared that Claude had shocked Prof. Donald Knuth by finding an odd-m construction for his open Hamiltonian decomposition problem in about an hour of guided exploration. Prof. Knuth titled the paper Claude’s Cycles.
The story didn't end there.
The updated paper shows the story got much bigger. For the base case m=3, there are exactly 11,502 Hamiltonian cycles. Of those, 996 generalize to all odd-m, and Prof. Knuth shows there are exactly 760 valid “Claude-like” decompositions in that family.
The even case, which Claude couldn’t finish, was then cracked by Dr. Ho Boon Suan using GPT-5.4 Pro to produce a 14-page proof for all even m≥8, with computational checks up to m=2000.
Soon after, Dr. Keston Aquino-Michaels used GPT Claude together to find simpler constructions for both odd and even m, by using the multi-agent workflow.
Dr. Kim Morrison also formalized Knuth’s proof of Claude’s odd-case construction in Lean.
So yes: the problem now appears fully resolved in the updated paper’s ecosystem of human AI proof assistant work!
We went from one AI solving one problem to a full mathematical ecosystem (multiple AI systems, multiple humans, formal verification) running in parallel on a problem that stumped experts for weeks.
We are living in very interesting times indeed.
Paper (updated): www-cs-faculty.stanford.edu/…



Prof. Donald Knuth opened his new paper with "Shock! Shock!"
Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming.
He named the paper "Claude's Cycles."
31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days."
The man who wrote the bible of computer science just said that. In a paper named after an AI.
Paper: cs.stanford.edu/~knuth/paper…

41
262
1,454
176,811
This is huge if it works as promised!!
Mar 24
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
46
ANKIT NARAYAN SINGH ⚡️ retweeted

Mar 22
The human traits AI can’t replicate and why they are worth developing…
By @ForbesTechCncl expert panel from @alloyautomation @ankitnarayan1 @createdbyjannn and more…
forbes.com/councils/forbeste…
@BetaMoroney @Nicochan33 @enilev @mvollmer1 @mikeflache @antgrasso @FrRonconi @ramonvidall @baski_LA @AkwyZ @Khulood_Almani @sijlalhussain @PawlowskiMario @pierrepinna @sonu_monika @mvollmer1 @sallyeaves @NevilleGaunt @Corix_JC @enricomolinari @Shi4Tech @wcrpaul @RagusoSergio @RLDI_Lamy @NigelTozer @EstelaMandela @JagersbergKnut @DrFerdowsi @PerBBerggreen @sir4K_zen @AmitChampaneri1 @FmFrancoise @HLStockenstrom @ILoveBooks786 @Hana_ElSayyed @CurieuxExplorer @HaroldSinnott @SegundoConnect @pchamard @trudydarwin

2
17
31
708
ANKIT NARAYAN SINGH ⚡️ retweeted
The Human Traits Ai Cant Replicate And Why Theyre Worth Developing hubs.li/Q046_npc0 from @alloyautomation @ankitnarayan1 @createdbyjannn and more
1
2
93
ANKIT NARAYAN SINGH ⚡️ retweeted
Five Valuable Engineering Skills For The AI-First World (Before Research Catches Up) hubs.li/Q046DRXc0 Written by @ankitnarayan1 of @paralleldots
1
2
83
Just got featured in the Most Promising Leaders To Watch in 2026: Redefining Leadership for a Changing World bombaytimes.com/lifestyle/vi…
@bombaytimes
1
47
ANKIT NARAYAN SINGH ⚡️ retweeted

Dhruv Bajpai, @Accenture ; Ankit Narayan Singh, @ParallelDots ; Sandeep Jabbal, @shoppersstop ; Praveen Govindu, Delloite & Vikraman Sridharan, @Lenskart_com , offered insights into "The Phygital Renaissance: Architecting India's "Intelligence-First" Retail Ecosystem"

1
1
1
71
ANKIT NARAYAN SINGH ⚡️ retweeted

Jan 25
This is an excellent piece on how to think about Forward Deployed Engineers (FDEs) for enterprise AI startups. My favorite part is right at the end -
“Linear services scale by adding bodies. Exponential services scale by adding capability. Both have FDEs. Only one is building something that compounds.
If the product isn’t improving, you don’t have forward deployed engineers.”

8
16
144
35,493
ANKIT NARAYAN SINGH ⚡️ retweeted

Jan 15
Introducing Adam, the first AI mechanical engineer
98
222
2,538
423,042

It's not enough to build software with AI, you need to be a 10x AI software engineer.
All the best teams are parallelizing their AI software use and churning out 25-50 meaningful commits / engineer / day.
The Claude Code best practices guide is an absolute goldmine of tips

90
132
2,159
301,831
ANKIT NARAYAN SINGH ⚡️ retweeted

17 Nov 2024
Meet Ankit Narayan Singh, co-founder and CTO of ParallelDots, sharing his vision for the future of image recognition solutions and insights into ParallelDots’ innovative journey, reshaping the FMCG and retail landscape with cutting-edge technology.
#JioGenNext
1
1
130

While there are 1000s of angels and endless startups, there hasn’t been an easy way for either to discover each other, we at @Dzerovc thought of taking a jab at it. We created angelinvestorsinIndia.com a repository of angels in India, so founders could reach out to them
2
9
36
3,346
ANKIT NARAYAN SINGH ⚡️ retweeted

1 Mar 2024
I have got requests from a lot of first-time/second time founders looking for Co-founders.
I have been connecting them over Whatsapp. Some have moved from a dating phase to final team formation.
I do have a decent pipeline of people who are starting up first or second time.
How about a meet-up for Co-Founder dating?
If this post gets 50 RTs/Quotes, we will do this in mid of March.
RT for Good Karma!
@santoshpanda @bimleshgundurao @SanketPanda10
1 Mar 2024

"building the next big thing... also looking for someone to build a future with"
15
42
87
30,001