
Joined June 2008
- Tweets 537
- Following 257
- Followers 254
- Likes 68
13 Photos and videos





Anoj Pillai retweeted

Jan 26
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual autocomplete coding and 20% agents in November to 80% agent coding and 20% edits touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
1,639
5,579
40,695
7,794,918
Anoj Pillai retweeted

Jan 5
At our Bay Area DSPy meetup, @lateinteraction delivered an incredible talk about the philosophy of DSPy, why it matters, and treating AI engineering as an actual engineering discipline.
Can't recommend this one enough: youtube.com/watch?v=I77yLzAG…
5
15
99
26,287

10 Nov 2025
Microsoft Research’s AsyncThink: LLMs self-organize via RL for concurrent reasoning! Outshines sequential (single-threaded, high latency) & parallel (independent traces aggregation, 28% slower) paradigms.
Beats ’em on benchmarks: 89% acc on countdown (vs 69% parallel/71% seq), 73% on AMC math ( 0.5% w/ lower lat). Zero-shot Sudoku gen: 89% (vs 84% parallel). arxiv.org/abs/2510.26658 #AI #LLM #AgenticAI
46
Anoj Pillai retweeted

9 Nov 2025
1/16
You've seen it in movies: a lone genius AI solves everything in seconds.
But in reality, even the smartest person (or AI) hits a wall.
A new paper from Microsoft Research suggests the next leap in AI isn't about being a lone genius. It's about learning to be a world-class project manager. 🤯
THREAD 👇
Today, most AIs "think" in one of two ways:
1️⃣ Sequential Thinking: Like one person solving a math problem step-by-step. It's logical, but can be painfully slow for complex tasks. (Think: Chain-of-Thought)
2️⃣ Parallel Thinking: Like hiring 5 consultants, giving them the same problem, and having them work in total isolation. You then pick the most popular answer (majority vote).
Better, but still inefficient and with zero collaboration.
The big problem? The 'parallel' method is bottlenecked by the slowest consultant, and they can't help each other out mid-way.
What if one finds a crucial clue that could help everyone else? Too bad. This is a huge limitation.
This is where the new paper, "The Era of Agentic Organization," comes in. They introduce a new paradigm: Asynchronous Thinking (AsyncThink).
And it's a total game-changer.
Imagine an AI that learns to act like an elite Project Manager. Let's call it the 'Organizer.'
When it gets a complex problem, it doesn't try to solve it all at once.
Instead, the Organizer breaks the problem down. It then 'Forks' sub-tasks to a team of 'Worker' AIs.
(These are all instances of the same model, just playing different roles).
🧠 (Organizer)
...↳ 🍴 <FORK-1> to 👨💻 (Worker 1)
...↳ 🍴 <FORK-2> to 👨💻 (Worker 2)
The Workers start crunching on their sub-tasks concurrently.
But here's the magic: The Organizer doesn't just wait. It can continue its own thinking, and 'Join' a Worker's results whenever they're ready, integrating their findings on the fly.
This means if Worker 1 finds a key piece of the puzzle, the Organizer can integrate that knowledge immediately and use it to guide its own work or even assign a new, more informed task to Worker 2.
It's real-time, dynamic collaboration. Not just parallel work.
So, how do you teach an AI to be a good manager? You can't just write rules for every situation.
You have to make it want to be efficient. And that's where things get really clever.
The researchers used Reinforcement Learning. They built a reward system that didn't just reward correct answers.
It also gave the AI a 'Concurrency Reward' for keeping its team of workers as busy and parallel as possible.
It literally learned to hate downtime.
The AI developed its own strategies for organizing work to maximize this reward.
The result? On math reasoning problems, it was 28% faster than the old parallel method while being MORE accurate.
But here's the mind-blowing part.
They trained the AI on a number puzzle. Then, with ZERO new training, they gave it a 4x4 Sudoku puzzle.
It used its learned 'manager' skills to organize a team and solve it. It learned the abstract skill of collaboration itself.
This changes how we should think about AI progress.
From now on, the question isn't just "Is the AI smarter?" but "How well can the AI organize intelligence?"
It's a shift from brute-force computation to elegant coordination.
Think about what this means. We can build AI systems that tackle problems too complex for a single mind.
Drug discovery, climate modeling, complex engineering... problems that require a team of specialists, all working in concert.
This isn't just about making AI faster. It's about giving AI the foundational skill for collective intelligence. We're witnessing the first steps of AI learning to build an organization.
The future of AI isn't a single super-brain. It's a super-team.

46
135
740
49,981
Anoj Pillai retweeted

7 Nov 2025
Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI
@GoogleAI
ALT An abstract digital illustration of a brain overlaid with complex data visualizations and sound wave.
132
794
4,703
1,428,685
Anoj Pillai retweeted

5 Nov 2025
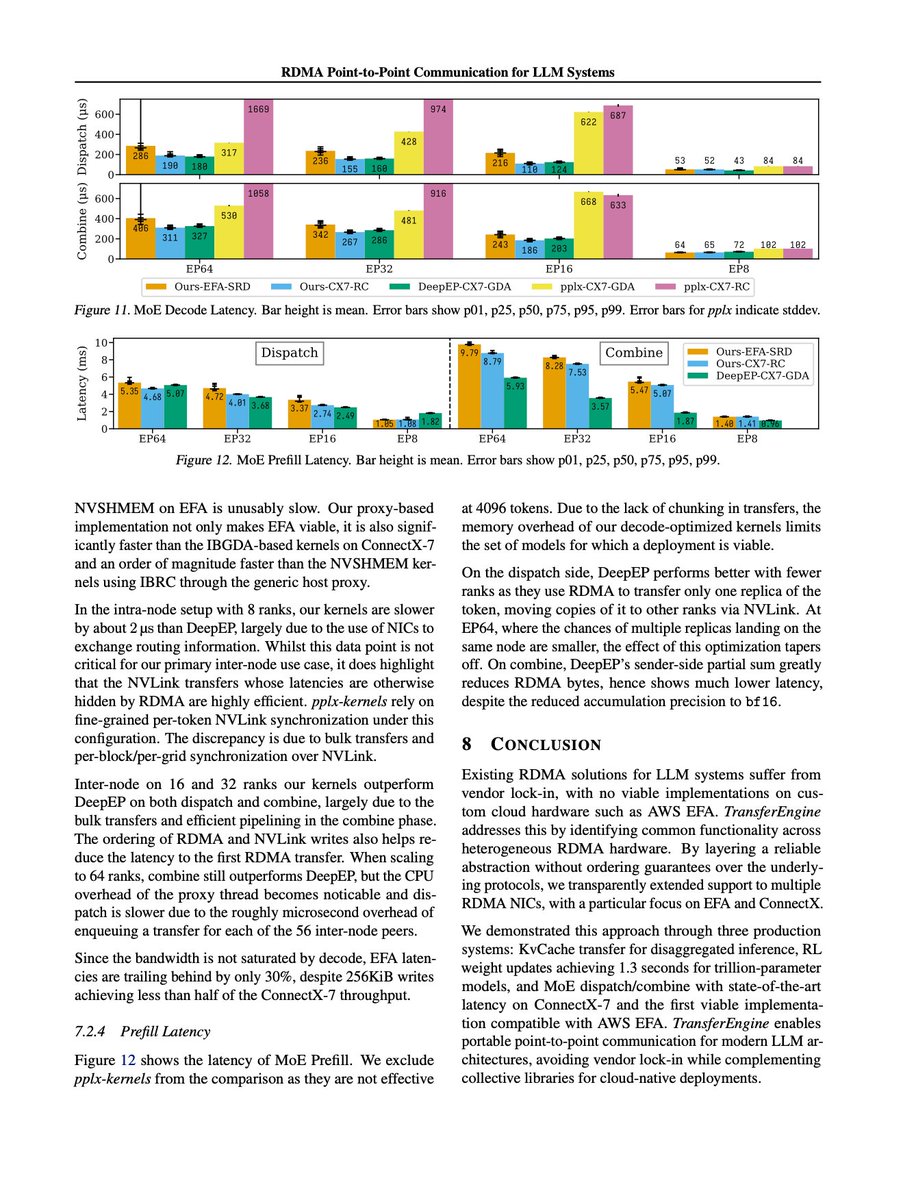
BREAKING: Perplexity’s first research paper broke a major limit in LLM scaling
NVIDIA and AWS are excited about it. No one’s reported this yet.
What I found most useful:
→ Enables trillion-parameter serving on AWS (previously not feasible)
→ Faster than DeepSeek’s DeepEP, a top benchmark
→ Minimal API surface, yet handles complex multi-node workloads
→ Fully portable across clouds

56
151
1,085
105,234
Anoj Pillai retweeted

1 Nov 2025
Stop Prompting LLMs.
Start Programming LLMs.
Introducing DSPy by Stanford NLP.
This is why you need to learn it:

17
125
1,007
69,476

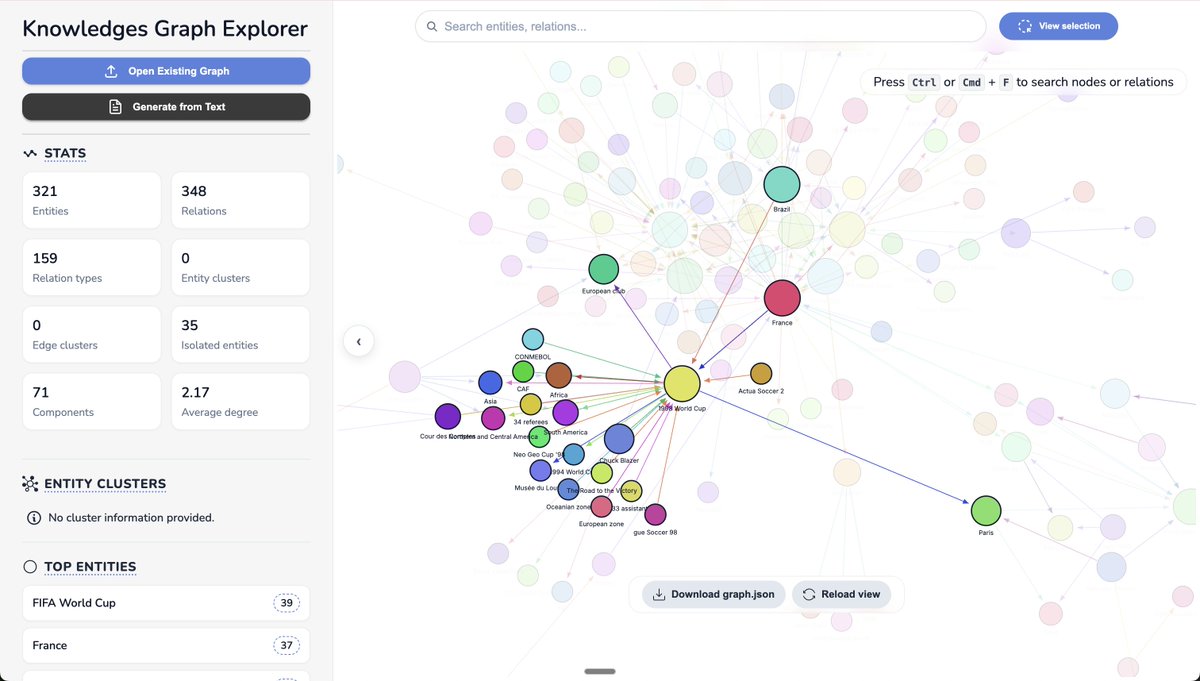
KGGen now has a way to visually navigate generated knowledge graphs:
with @stai_research
1
7
22
7,154
Anoj Pillai retweeted

20 Oct 2025
New work!
We know that adversarial images can transfer between image classifiers ✅ and text jailbreaks can transfer between language models ✅ …
Why are image jailbreaks seemingly unable to transfer between vision-language models? ❌
We might know why… 🧵

7
10
67
21,767
Anoj Pillai retweeted

30 Oct 2025
Autoregressive language models learn to compress data by mapping sequences to high-dimensional representations and decoding one token at a time.
The quality of compression, as defined by the ability to predict the next token given a prompt, progressively improves (as measured by negative log-likelihood) during training. We find that complexity of the representation manifold however, evolves non-mononitically in distinct phases across pretraining and post-training.
Excited to share our #NeurIPS2025 📄 led by our amazing undergrad @melody_zixuan where we study the complexity dynamics of LLMs, and how distinct phases relate to specific behaviors. 🧵👇

4
25
97
28,115
Anoj Pillai retweeted
20 Oct 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
20 Oct 2025

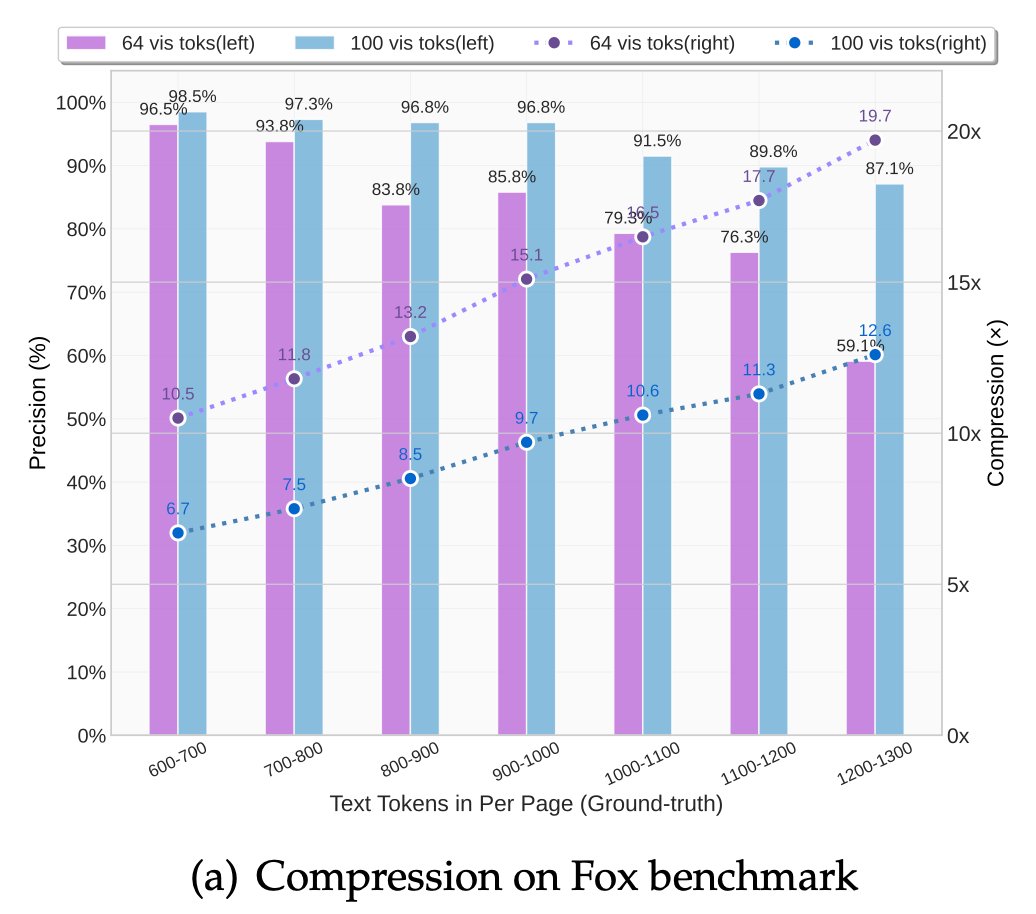
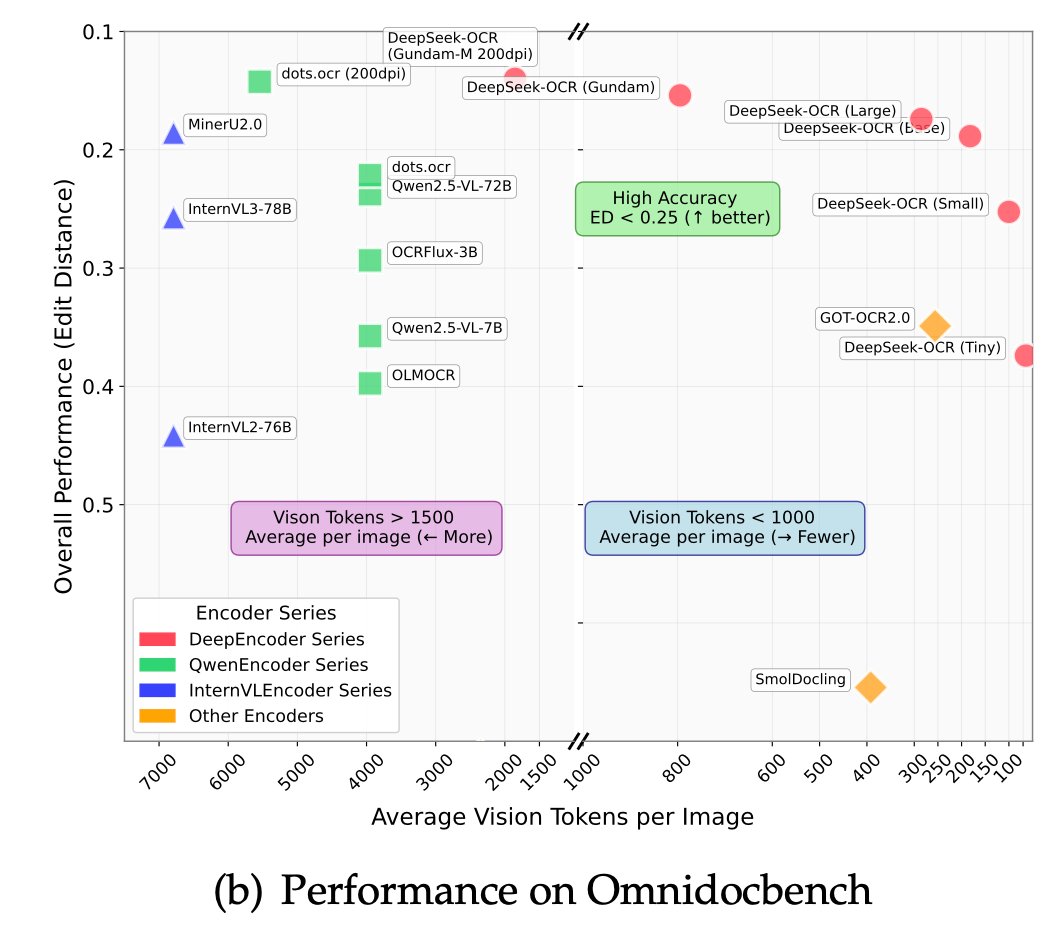
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 github.com/deepseek-ai/DeepS…
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning

558
1,558
13,277
3,329,877
6 Apr 2024
We transform into a team through collaboration, evolve into a force with unified thought, and ascend to a revolution when our dreams align
84
20 Apr 2023
Introducing the Universal Ledger by The Universal Ledger link.medium.com/hfP6i0UO9yb
130

Live demonstration of #AI Edge Platform for mobile robots by @icuro_ai at the @intel Innovation Summit 2022, San Jose.
#ArtificialIntelligence #semiconductor #Warehouse #retailers #computervision #deeplearning #MachineLearning #innovation #robotics #technology
4
2
1 Oct 2022
Tesla is deploying WiFi Hotspots at superchargers powered by Starlink
2
14 Mar 2022
In a historic milestone, Azure Quantum demonstrates formerly elusive physics needed to build scalable topological qubits news.microsoft.com/innovatio…
11 Mar 2022
µTransfer: A technique for hyperparameter tuning of enormous neural networks microsoft.com/en-us/research…
9 Feb 2022
SEC Chairman Gary Gensler embarks on ambitious regulatory agenda with 50 rule changes targeting PEs and hedge funds for greater transparency on fees and performance. Anyone sees a potent set of opportunities for Regtech Platforms cnb.cx/3ooBQkZ