
something new
Joined January 2010
- Tweets 640
- Following 659
- Followers 5,125
- Likes 1,210
39 Photos and videos




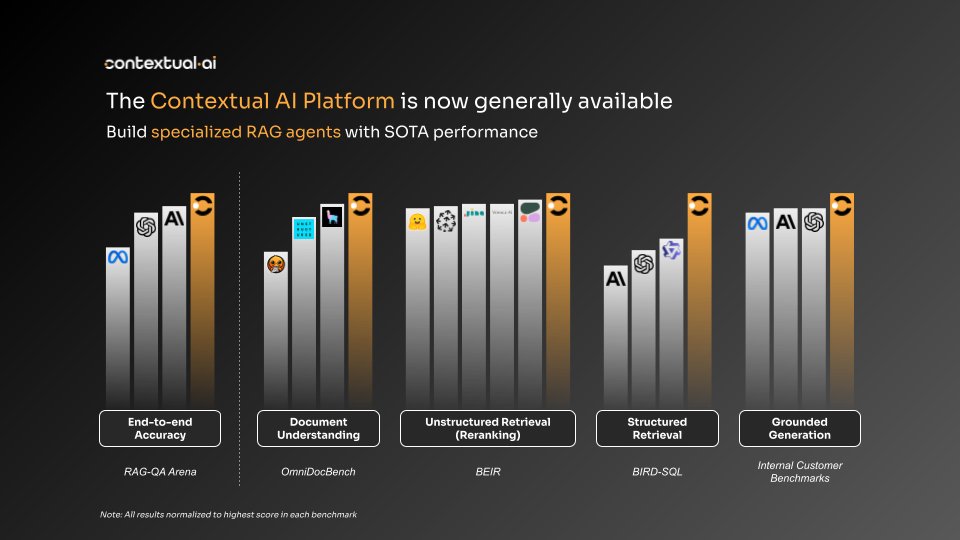



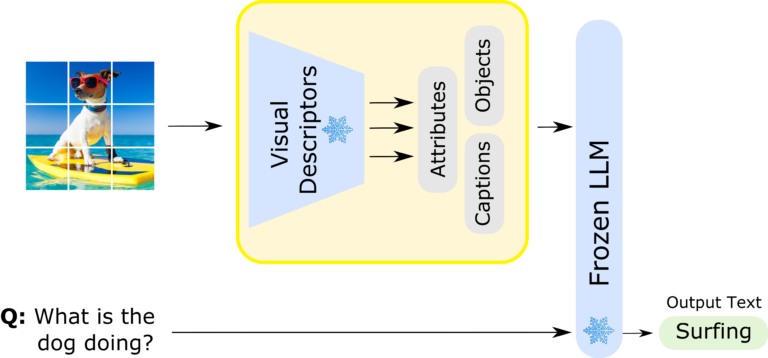



when the same general "token capital" is available to everyone, the only real moat/differentiation is the "human capital" you compound forever inside an enterprise.

7
812

Apr 8
This is bigger than it seems for the AI agents.
S3 Files lets you mount any S3 bucket as a native NFS on any container or lambda with ~1ms latency via EFS under the hood.
Why it matters for agents: no more copying data or bridging object <-> file abstractions. Agents can now read/write S3 directly as a mounted filesystem. Multiple agents can share the same mount with close-to-open consistency. Long-term storage becomes the same as the short-term storage.
Agent runtime bootstrap and teardown become trivial and instant while your data stays durable in S3 with auto bi-directional sync.
Apr 7

Announcing Amazon S3 Files.
The first and only cloud object store with fully-featured, high-performance file system access.
Learn more here. go.aws/4tw17Zg
21
50
918
258,985
Feb 11
Claude Code on web/iOS is a big productivity unlock for small changes. But for bigger changes, the biggest blocker for me was not having the gh cli. Can't bring in GitHub context - no PR reviews, no issue management, no fine-grained operations. You end up pulling locally anyway which defeats the whole point.
Custom environments fix this: `gh auth token` → create new environment → network access "Full" → add GH_TOKEN env var. Remote session installs gh at runtime, picks up the token. Done.
GitHub-related skills now work from the browser/phone. No more local pull as an extra step.
1
1
6
754
Jan 23
> opened codex web
> codex asks to integrate with slack
> me: why not? i can delegate all things directly from slack
> started a task from a slack thread
> codex returns the task link
> coworker opens the task link without any auth and is able to see everything
> tried the link in the incognito mode
> link still opens up with all of the code/details for anyone out there to see
> tried for 30 min to find a setting to disable this.
> found nothing
> manually disable links so far one by one
> disables codex in slack :(
> back to claude/codex duo in tmux
1
11
1,362
Amanpreet Singh retweeted

30 Dec 2025
Announcing Worktrunk! A git worktree manager, designed for running AI agents in parallel.
A few points on why I'm so excited about the project, and why I hope it becomes broadly adopted 🧵
75
84
1,023
96,644
Amanpreet Singh retweeted

22 Jul 2025
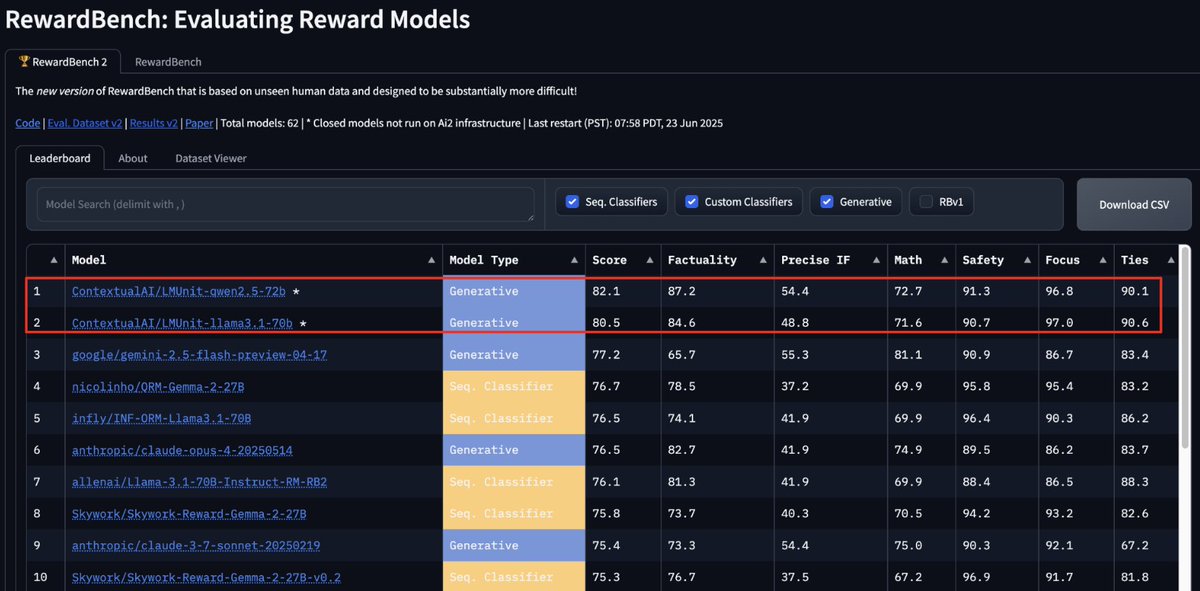
📢 As promised ✨, we're open-sourcing LMUnit! Our SoTA generative model for fine-grained criteria evaluation of your LLM responses 🎯
✅ SoTA on Flask & BigGbench
✅ SoTA generative reward model on RewardBench2
🤗 Models available on @huggingface: tiny.cc/qjzp001
💻 Github repo: github.com/ContextualAI/LMUn…
📄 Paper: arxiv.org/abs/2412.13091
✍️ Blog: contextual.ai/lmunit/
See more details in the quoted tweet👇
23 Jun 2025

Excited to share 🤯 that our LMUnit models with @ContextualAI just claimed the top spots on RewardBench2 🥇
How did we manage to rank 5% higher than models like Gemini, Claude 4, and GPT4.1? More in the details below:
🧵 1/11
1
14
34
7,136
Amanpreet Singh retweeted
14 Jul 2025
Tired of seeing O3 hallucinate? 😵💫
Today, I am excited to share how we built the least hallucinatory LLM in the 🌍
Our GLMv2, developed at @ContextualAI, just claimed 1st place 🥇 on the FACTS Grounded leaderboard by Google DeepMind — outperforming Gemini-2.5-pro, Claude 4, and O3 by 18%. 🤯
More details about our SFT and post-training recipe below 👇
1/N
12
28
277
581,312
2 Jul 2025
Historically, unstructured data has dominated the spotlight in AI, while the mission-critical structured data that drives most enterprise workflows has remained under-leveraged, with few proven recipes for AI workloads.
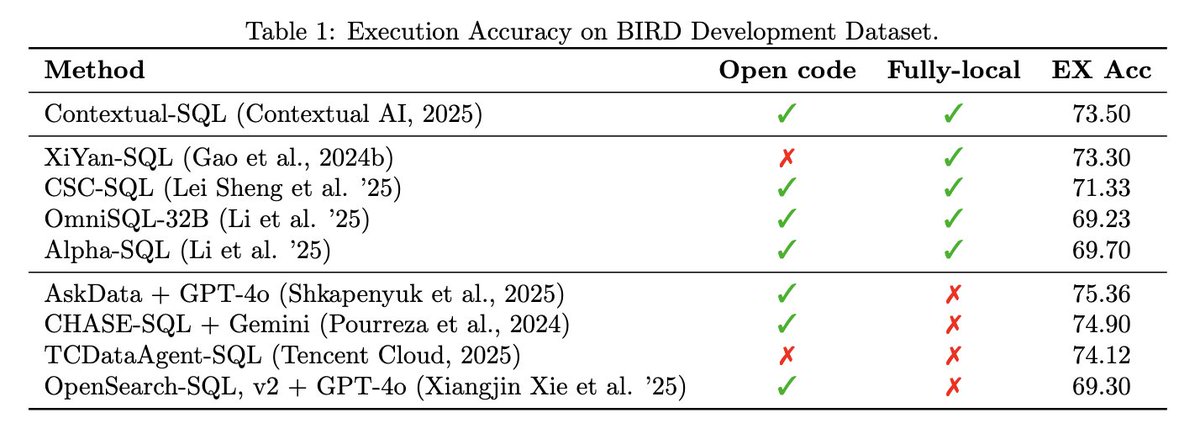
Today, we’re changing that by fully open-sourcing Contextual-SQL, a state-of-the-art Text-to-SQL pipeline which ranks highly on the BIRD benchmark and you can run entirely on-prem.
A surprisingly simple pipeline delivers these results by leaning on two core ideas:
📖 Context beats parameters
DDL → mSchema (table column comments) → mSchema one few-shot example lifts execution accuracy from 54.7 % to 62.5 %. Before reaching for a larger model, enrich your schema docs and drop in a golden demo query.
📈 Scale at inference
Spin up 1000 diverse SQL candidates in parallel, filter invalid queries with a fast sqlite3 check, then rank what’s left using a lightweight reward model built on the same Qwen base plus log-prob confidence. That single trick bumps pass@1 to ~73% -- cheaper and cleaner than fine-tuning.
The whole flow is just five step: generate → filter → rank → pick → run, and lives on GitHub. Fork it, point it at your schema and ship a private text-to-SQL solution.
For a deeper dive, code, and benchmarks, see Sheshansh’s thread and the full blog post below.
2 Jul 2025

Excited to release Contextual-SQL!
🏆#1 local Text-to-SQL system that is currently top 4 (behind API models) on BIRD benchmark!
🌐Fully open-source, runs locally
🔥MIT license
🧵
3
4
16
1,490
23 Jun 2025
Fine-tuning LLMs with RL?
LMUnit can help you craft complex reward functions in plain English!
LMUnit just grabbed #1 spot on RewardBench2, beating Gemini2.5 by 5 pts AND we will be open sourcing LMUnit soon!🚀🥇
Great work by the team! Read William’s thread for details👇
23 Jun 2025
Excited to share 🤯 that our LMUnit models with @ContextualAI just claimed the top spots on RewardBench2 🥇
How did we manage to rank 5% higher than models like Gemini, Claude 4, and GPT4.1? More in the details below:
🧵 1/11
2
11
1,525
Amanpreet Singh retweeted

20 May 2025
Today we’re launching Prompt Adaptation, a state-of-the-art agentic system that automatically adapts prompts across LLMs. Prompt Adaptation outperforms all other methods and significantly improves accuracy over manual prompt engineering, saving you thousands of hours per year.
22
71
636
110,726
Amanpreet Singh retweeted

3 Apr 2025
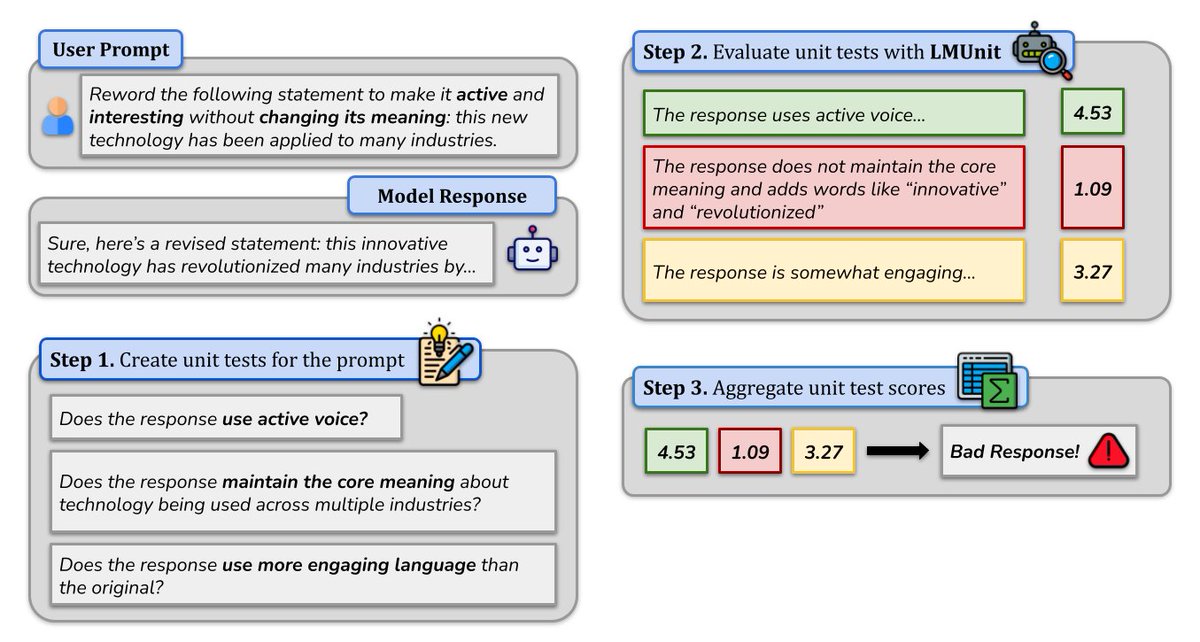
🔥 Introducing the most reliable way to evaluate LLMs and agents in production! It's time to stop “vibe testing” your AI systems.
Our latest developer's guide shows you how to rigorously test AI systems so that they hold up in production, using Contextual AI's LMUnit evaluation model and @CircleCI’s CI/CD pipeline. You’ll learn how to:
• Write natural language unit tests that anyone on your team can understand
• Leverage LMUnit – Contextual AI's state-of-the-art, specialized evaluation language model that outperforms frontier models with greater interpretability at lower cost
• Implement @CircleCI's CI/CD pipeline to catch regressions before they reach users
See our complete developer’s guide here: contextual.ai/blog/lmunit-ci…
Stop relying on "vibes" and start building AI you can trust!
#AITesting #LLMOps #DevOps #Agents #LLM #Evaluation
2
9
26
3,305
Amanpreet Singh retweeted
3 Apr 2025
Go behind the scenes with Contextual AI CTO @apsdehal as he breaks down the future of enterprise AI with @DanielDarling. You'll learn about grounded LLMs, specialized AI agents, and what’s next for AI in the enterprise—read the full article 👇
dub.sh/NHryEMB

3
14
856
2 Apr 2025
🚀 Just had a deep, wide-ranging convo on the Five Year Frontier pod with @DanielDarling about the future of AI work in the enterprise.
Some highlights 👇
1/ Why generic LLMs don’t cut it for real-world enterprise use
2/ How Grounded Language Models (GLMs) eliminate hallucinations
3/ Teaching AI your org’s tribal knowledge
4/ Agents that grow with you over time
5/ How RAG 2.0 our new reranker bring control precision to enterprise AI
6/ What a “thin, high-leverage” AI-native org might look like in 5 years
@ContextualAI We’re building toward a world where AI understands your workflows, your knowledge base, and your org structure. That’s the new operating system of modern work.
🎧 Listen here: youtube.com/watch?v=d85Kf_YM…
1
4
14
1,646
20 Mar 2025
Your agent is as good as the data you train it on. Check out how our data engine under @bertievidgen leads to high-quality enterprise data today.
20 Mar 2025

The secret to building specialized RAG agents? High-quality human data 📊
In our latest blog post, @bertievidgen, Head of Human Data at Contextual AI, explains why human-annotated data is the foundation of effective specialized RAG agents.
With the right labeled data to fine-tune and evaluate agents, organizations can tackle their most complex AI use cases across finance, semiconductors, and professional services.
How does the team ensure our human-annotated data is high quality? The Contextual AI Standard—our team’s framework for defining what good labelled data looks like and, by extension, how we want specialized RAG agents to behave:
• Grounded ✅
• Logical ✅
• Fulfills the user's request ✅
• Effectively communicated ✅
• Safe and reputable ✅
Read the full blog here:
contextual.ai/blog/human-ann…
2
11
754
Amanpreet Singh retweeted
18 Mar 2025
Thrilled to share that Contextual AI has been named to @FastCompany’s 2025 Most Innovative Companies list for Applied AI!
A huge thank you to our team, customers, and partners for being part of this journey. We're so honored to be recognized for our innovative approach to Enterprise AI and the business impact we're delivering to customers.
We've been shipping new product capabilities at a breakneck pace, and this award is a testament to the clarity of our vision for specialized RAG agents and the dedication of our teams who work tirelessly to create an incredible customer experience.
Exciting things ahead!
Read more: fastcompany.com/91268960/app…
#FCMostInnovative #AIInnovation #EnterpriseAI #ContextualAI

2
16
1,164
Amanpreet Singh retweeted

18 Mar 2025
Strong BCV portfolio company representation in @FastCompany's Most Innovative Companies 2025 list
Congrats and keep building!

3
6
20
2,097
Amanpreet Singh retweeted

13 Mar 2025
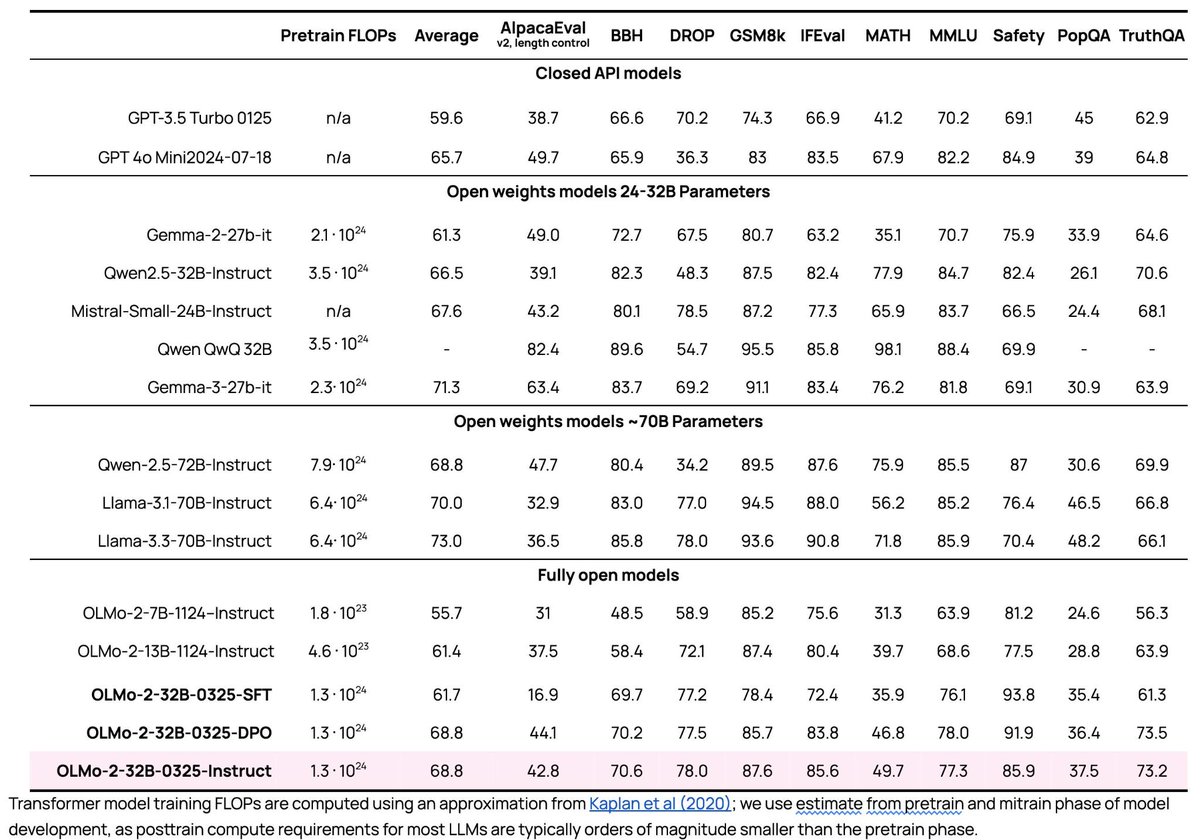
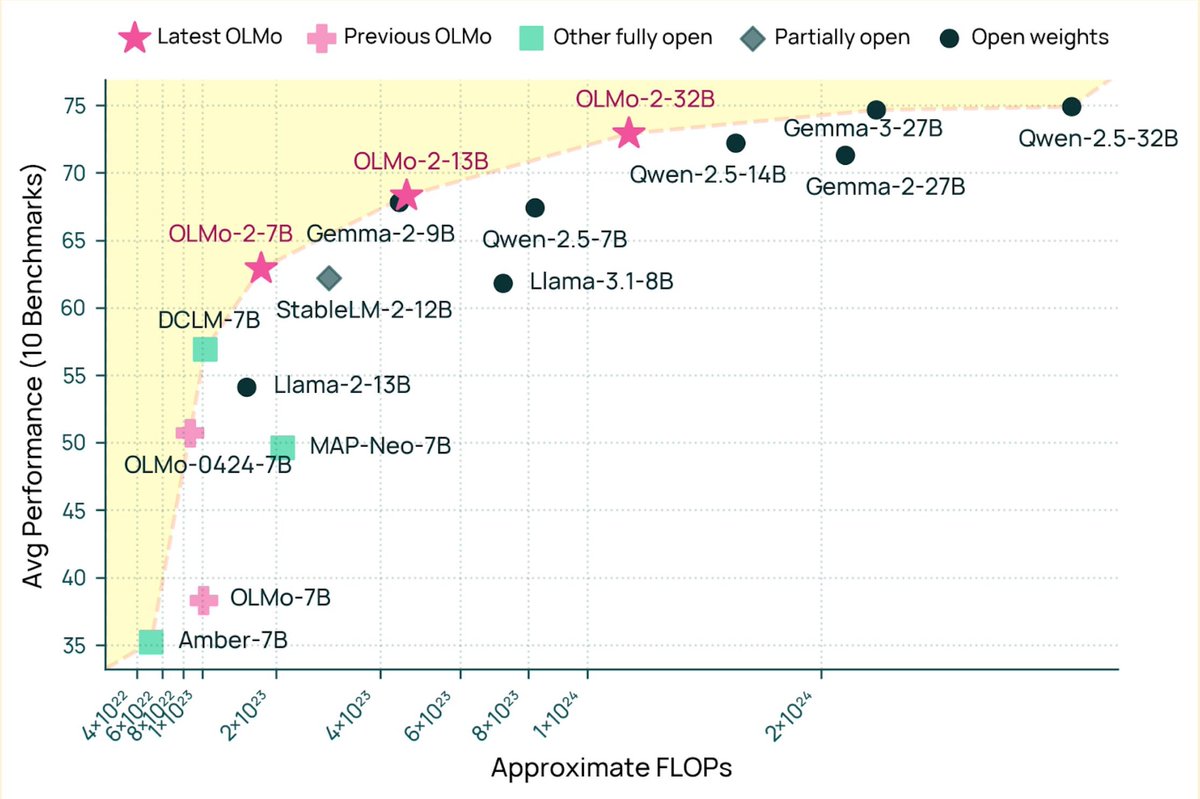
A very exciting day for open-source AI! We're releasing our biggest open source model yet -- OLMo 2 32B -- and it beats the latest GPT 3.5, GPT 4o mini, and leading open weight models like Qwen and Mistral. As usual, all data, weights, code, etc. are available.
For a long time, people have asked for an truly open-source version of ChatGPT and we finally have it. This is multiple years coming into efforts following the release of ChatGPT and builds on the efforts of so many at both Ai2 and in the broader open AI ecosystem.
With just a bit more progress everyone can pretrain, midtrain, post-train, whatever they need to get a GPT 4 class model in their class. This is a major shift in how open-source AI can grow into real applications.
Oh yeah, it's also Apache 2 as always, so happy to make things that are simple to use. I did NOT expect to be undercutting OpenAI's offerings this year but here we are :D
51
146
932
99,658
Amanpreet Singh retweeted
11 Mar 2025
The world's first instruction-following reranker, which is SOTA on leading benchmarks like BEIR, powers our platform for building specialized RAG agents. Hear from our team about why and how we built it.
11 Mar 2025

AI struggles with messy, conflicting, ever-changing data. Today's AI ranking methods can't prioritize clearly, because they lack human guidance. Introducing the world's first instruction-following, SOTA reranker!
Give our reranker instructions to control exactly how it ranks:
• “Prioritize recent documents”
• “Prefer PDFs over other sources”
• “The boss is always right”
Can’t wait to see what people build with it!
7
5
43
6,517