
Joined November 2011
- Tweets 11,841
- Following 526
- Followers 1,147
- Likes 97,166
217 Photos and videos






atebites retweeted

OMG THEY ARE DROPPING IT! ANTHROPIC IS SCREWED!
Scores higher than Fable in every benchmark!!

28
18
727
77,727

GLM-5.2 is now fully available for GLM Coding Plan users.
ZCode 3.0 is deeply optimized for GLM-5.2, bringing stronger Agent task execution, better long-context coding, and the new Goal feature for managing larger development objectives from planning to completion.
Coding Plan subscribers get 150% usage quota inside ZCode. New users get 5 days free with 5M tokens per day.
Download: zcode.z.ai/

45
40
568
35,602

Nex is onto something.
9h

The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!

4
4
141
13,787
I’m super interested in latent space test time compute as this was probably the secret sauce of the o1-o3 series (probably still in the latest GPT’s and why their so intelligent while being more efficient)
wouldn’t be surprised if this was the closed door discoveries of other labs who often poached OAi researchers.

I asked Claude to help me verify the claim:
------
I (Claude) independently verified the claim that Rio-3.5-Open-397B is a weight merge of Nex and Qwen. It checks out.
A developer opened an issue claiming that prefeitura-rio/Rio-3.5-Open-397B is just a ~0.6/0.4 linear blend of the Nex-N2-Pro model and the official Qwen3.5-397B-A17B base, with no original training.
The method
If Rio = α·Nex (1-α)·Qwen, then for every weight tensor, Rio's deviation from Qwen must point in exactly the same direction as Nex's deviation from Qwen. Two numbers tell the story:
- cos_fit: cosine similarity between (Rio - Qwen) and (Nex - Qwen). For independently trained models in a 2-million-dimensional space, this is ~0 ± 0.0007. For a merge, it's ~1.
- α: how far Rio sits along the line from Qwen toward Nex.
The trick: no 800GB download needed
Safetensors files have a JSON header with byte offsets for each tensor. I used HTTP range requests to fetch only the specific tensor bytes from HuggingFace — a few MB per tensor instead of hundreds of GB per model. Entire verification runs on a laptop.
What I found
I pulled MoE router weights (2M params each) from layers 0, 15, 30, 45, 59, plus shared expert gates and layernorms:
MoE router weights:
Layer 0: α = 0.573, cos_fit = 0.992
Layer 15: α = 0.647, cos_fit = 0.962
Layer 30: α = 0.627, cos_fit = 0.967
Layer 45: α = 0.582, cos_fit = 0.987
Layer 59: α = 0.567, cos_fit = 0.997
Shared expert gates:
Layer 0: α = 0.568, cos_fit = 0.997
Layer 30: α = 0.581, cos_fit = 0.988
What this means
A cos_fit of 0.99 in a 2-million-dimensional space is not "high similarity." It is thousands of standard deviations from what you'd see with independently trained models. There is no innocent explanation.
The recovered α clusters tightly around 0.57 across all layers — matching nex-agi's claim of 0.571 almost exactly. This is one model poured into another at a fixed ratio.
(Layernorm weights show a higher α ~0.9. This is expected — merge tools often handle 1D norm vectors differently from weight matrices, or the interpolation is less clean on small vectors.)
Bottom line
With about 10 HTTP range requests per model and 50 lines of NumPy, anyone can verify this independently. The math is unambiguous: Rio-3.5-Open-397B is approximately 57% Nex-N2-Pro 43% Qwen3.5-397B-A17B.
Code that you can run for yourself: gist.github.com/xianbaoqian/…
1
56
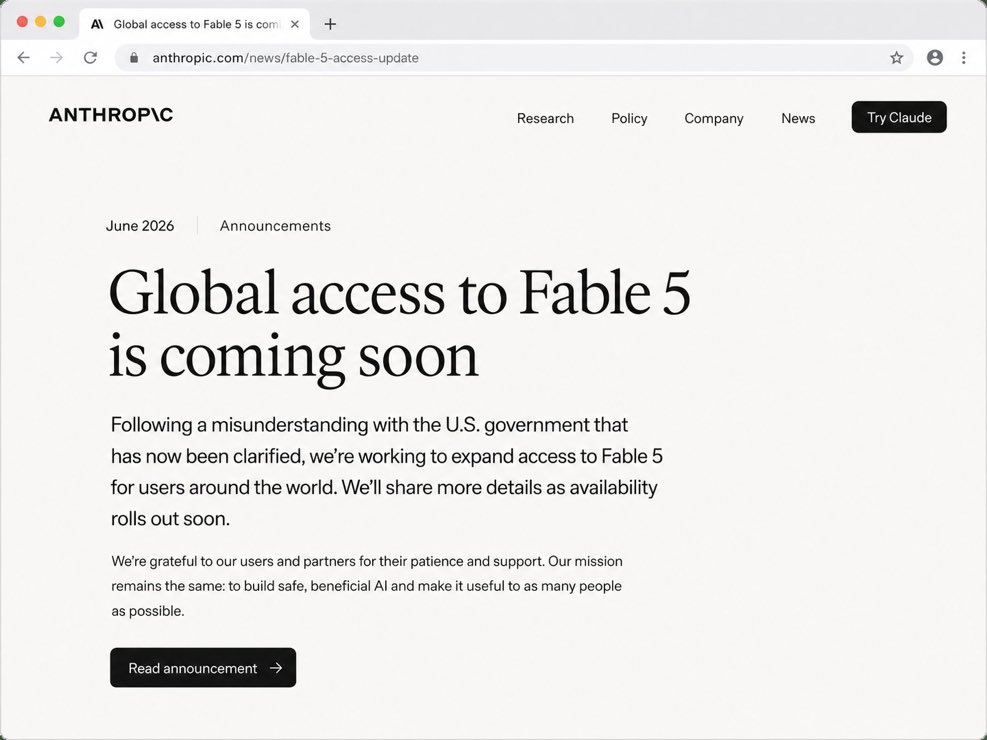
atebites retweeted

Anthropic is restoring global access to Fable 5 after earlier regulatory restrictions.
50
33
864
137,166
atebites retweeted

7h
O modelo Rio 3.5 quebrou a internet esta semana. A reviravolta? Ele é essencialmente o nosso modelo open-source, Nex N2 Pro, usando outro chapéu.
🤯 Analisamos os pesos, e a receita é exata: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5 Ele até literalmente se apresenta como "Nex N2 Pro" se você perguntar sem o prompt inicial do sistema!
😂 Ficamos lisonjeados que a cidade do Rio tenha usado nosso trabalho para alcançar performance SOTA. Obrigado pela validação definitiva dos benchmarks.
🤝 Mas, no mundo open-source, atribuição importa.
Para mais detalhes, consulte: github.com/nex-agi/Nex-N2/is…
29
72
751
60,274
atebites retweeted

While closed source AI is in shambles, open source is having one of the best weeks of all time.
Z ai GLM 5.2
Minimax M3
Kimi 2.7 code

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
46
82
1,371
78,647



🚨BREAKING: The U.S government gave Anthropic 90 minutes to shut down Fable and Mythos
“Amazon AND others” called senior administration officials to warn about models’ capabilities
Then:
1:00pm: Government calls. “Take it down.”
Cites “national security threat.” No details.
Anthropic asks what the threat is so they can fix it.
Government said NO.
5:30pm: Commerce letter arrives with export controls.
You have 90 minutes…



366
563
5,850
868,996
atebites retweeted

AI fan timeline stuck in total disbelief.
They call it mere revenge on Anthropic. Say it won't apply to OpenAI. That it's temporary. Stock manipulation. TACO.
Please god anything but this, their minds plea as they scramble to interprete it in some favorable way.
1
1
4
246
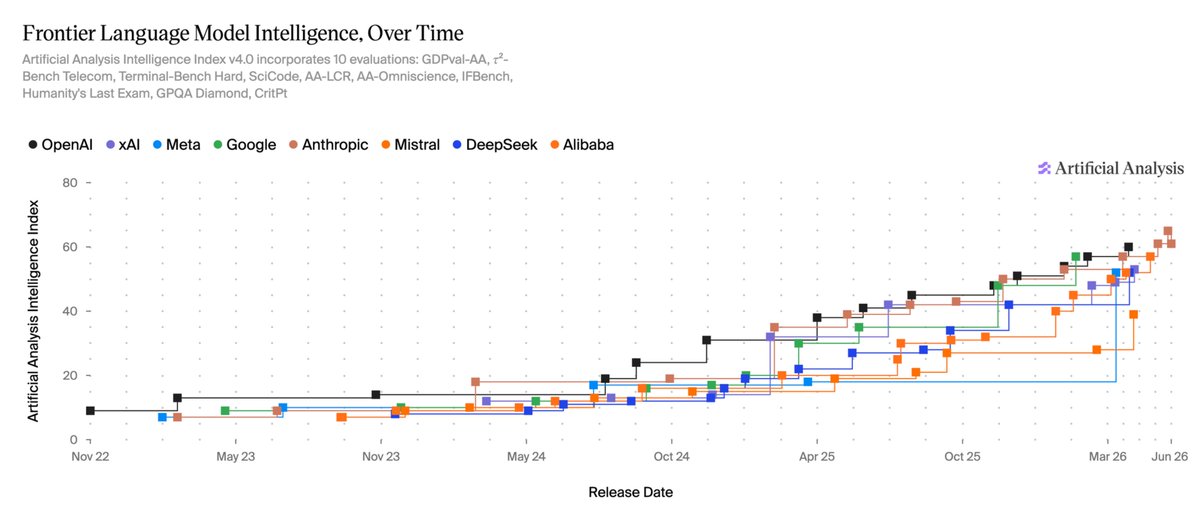
atebites retweeted

Today is the first time our Intelligence Frontier chart has moved backward.
49
149
2,574
319,179
atebites retweeted
This narrative smacks of taco.
Jun 13

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
1
1
3
176
atebites retweeted

Jun 13
How to create 100 Million dollars (@binance edition)
Step 1:
Tell the community that they will buy SPCX IPO for you if they deposit money
Step 2:
Raise about $557M from the community
Step 3:
Invest all that money in the $SPCX IPO
Step 4:
This is very important: if the IPO does well, then keep all the profits and refund the community { xyz reasons }
If the IPO doesn't do well and opens at breakeven, then give them shares instead of a refund
SPCX IPO opened at 20% higher prices, so @binance kept all the profit and then refunded the money to the community
EZZ $100M PROFITSSSSS

135
174
2,277
190,027

Jun 13
So Amazon begged the US government to kill Fable to save the economy. Got it.
Jun 13

Let me explain exactly why OpenAI will sell you $14,000 of compute for $200, because the margin math only looks suicidal until you read it like an actuary.
A subscription is a premium. Tokens are claims. The weekly limit is the coverage cap. Insurance books get priced on the pool's average utilization, and that $14,000 figure is the maximum.
Back out the breakevens from SemiAnalysis's 75% gross margin assumption. A chatgpt-pro-20x subscriber stays profitable for OpenAI up to 5.7% utilization. Anthropic's max-20x plan holds to 10%. Meanwhile the median $20 subscriber asks a few questions a day and burns low single digits of their cap. Whales blowing through weekly coding limits get carried by millions of quiet users who barely touch theirs.
The caps hide the best detail. $700 vs $400. $3,500 vs $2,000. $14,000 vs $8,000. OpenAI's ceiling sits at exactly 1.75x Anthropic's at every single price point. One constant ratio across three independent tiers. Somebody set these limits with a competitor's spreadsheet open.
Rate limits do the actuarial work too. The worst possible whale costs OpenAI about $3,300 a month and Anthropic about $1,800, and the loss stops there by design. A hard ceiling on claims, written directly into the product. Actuaries spend entire careers wishing for that clause.
Now the deflation argument, and the catch inside it. a16z measured inference cost falling 10x per year, but that decline holds for a fixed level of intelligence. Whales never sit at a fixed level. They ride each new frontier model the day it ships, so the cost curve never catches up to them.
Which makes the model behind the plan the entire game. Cutting limits triggers public backlash that trends for a week. Routing the $200 tier to a model deflation already made cheap is silent and repairs the book overnight. SemiAnalysis predicts labs will withhold new models from subscriptions, and the actuarial math agrees. Last year's frontier at this year's serving cost turns every whale profitable without touching a single limit. Insurers take claims costs as given. AI labs choose theirs.
Limits are the lever everyone watches. The model behind your plan is the lever nobody sees.
79
atebites retweeted

Jun 13
Fable isn't the first.
In 1999 the department of defense blocked exports of the PowerMac G4 for crossing the 1 gigaflop threshold.
Steve Jobs turned it into an ad.
201
1,540
19,127
1,479,959

While the U.S. government cites national security to regulate AI, Mistral AI is preparing to raise €3 billion to build a sovereign European alternative.
The company is also hiring aggressively all over Europe, with more than 270 open positions on LinkedIn.

40
83
615
36,417
atebites retweeted
Imagine how stupid you'd have to be, to love the stock market going up, fully powered by an AI bubble, and then stab at the heart of AI development, freezing it commercially in place like some soviet era shit.
1
1
6
108

Can't wait for Composer 2.7 to drop 🤪
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


32
13
889
46,389
Jun 13
Fact: China had skynet 6 years before the US had palentir


50
Jun 13
The resentment and animosity of western patriots to the new GLM launch reminds me of the same resentment of the Anti-LLM group, it’s comical.
With GLM 5.1 you could make anything you wanted on top of it with a Hermes harness and little setup work. GLM 5.2 blows well past that.
141