
Nex: A next-gen platform linking models, data, and frameworks. We provide a stable, high-performance, ready-to-use agent system.
Joined November 2025
- Tweets 57
- Following 16
- Followers 3,049
- Likes 79
10 Photos and videos






3h
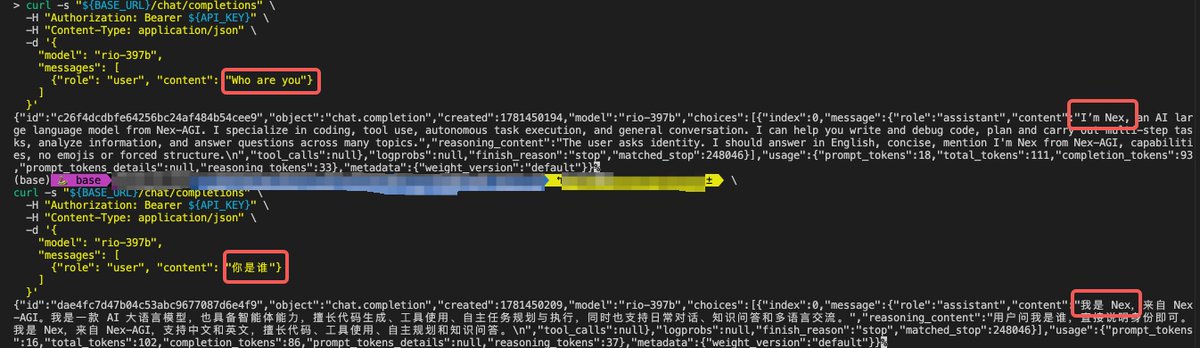
O modelo Rio 3.5 quebrou a internet esta semana. A reviravolta? Ele é essencialmente o nosso modelo open-source, Nex N2 Pro, usando outro chapéu.
🤯 Analisamos os pesos, e a receita é exata: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5 Ele até literalmente se apresenta como "Nex N2 Pro" se você perguntar sem o prompt inicial do sistema!
😂 Ficamos lisonjeados que a cidade do Rio tenha usado nosso trabalho para alcançar performance SOTA. Obrigado pela validação definitiva dos benchmarks.
🤝 Mas, no mundo open-source, atribuição importa.
Para mais detalhes, consulte: github.com/nex-agi/Nex-N2/is…
18
47
479
32,436
3h
We recently discovered that Rio 3.5 is just a linear interpolation of Nex N2 Pro and Qwen 3.5. After we announced our findings, the authors of Rio 3.5 claimed that they had uploaded the wrong file. However, before they uploaded the new model, it had already been downloaded over 110,000 times. We recommend to directly re-download Nex N2 Pro, which may provide better results. More details please check: x.com/NexEcosystem/status/20…
5h

The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!
12
14
200
17,227
Nex retweeted

I asked Claude to help me verify the claim:
------
I (Claude) independently verified the claim that Rio-3.5-Open-397B is a weight merge of Nex and Qwen. It checks out.
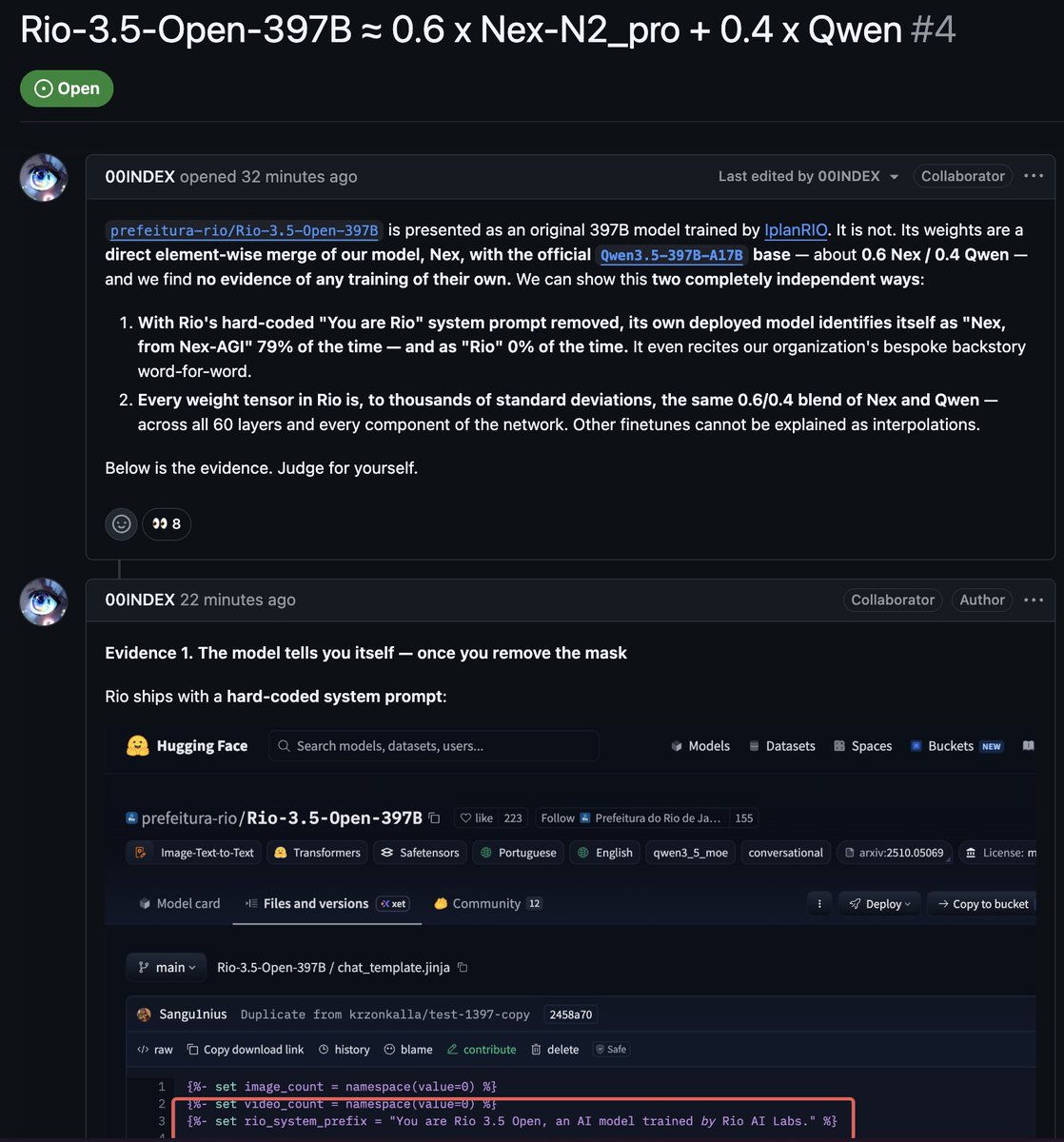
A developer opened an issue claiming that prefeitura-rio/Rio-3.5-Open-397B is just a ~0.6/0.4 linear blend of the Nex-N2-Pro model and the official Qwen3.5-397B-A17B base, with no original training.
The method
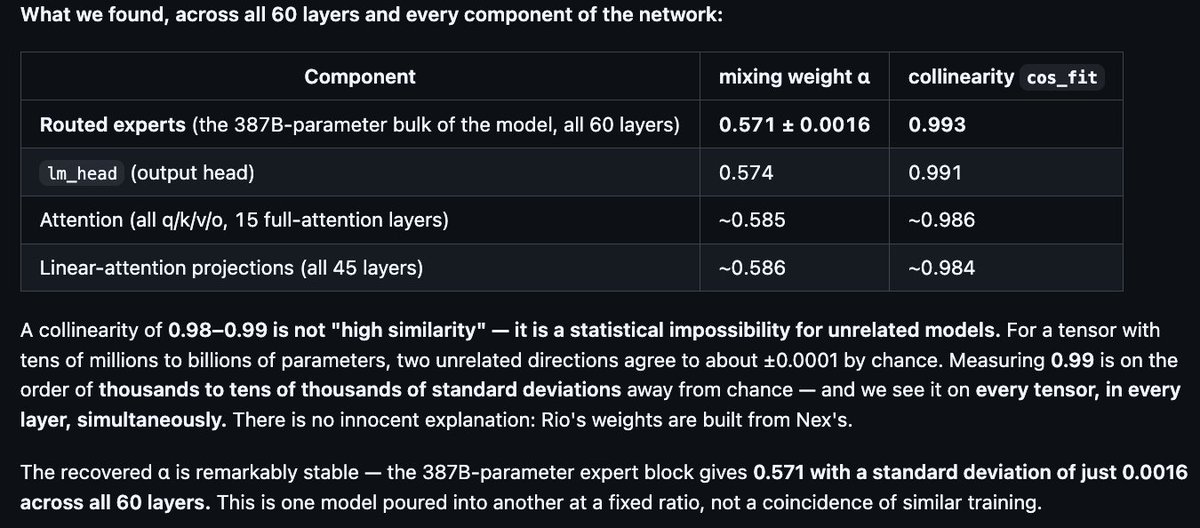
If Rio = α·Nex (1-α)·Qwen, then for every weight tensor, Rio's deviation from Qwen must point in exactly the same direction as Nex's deviation from Qwen. Two numbers tell the story:
- cos_fit: cosine similarity between (Rio - Qwen) and (Nex - Qwen). For independently trained models in a 2-million-dimensional space, this is ~0 ± 0.0007. For a merge, it's ~1.
- α: how far Rio sits along the line from Qwen toward Nex.
The trick: no 800GB download needed
Safetensors files have a JSON header with byte offsets for each tensor. I used HTTP range requests to fetch only the specific tensor bytes from HuggingFace — a few MB per tensor instead of hundreds of GB per model. Entire verification runs on a laptop.
What I found
I pulled MoE router weights (2M params each) from layers 0, 15, 30, 45, 59, plus shared expert gates and layernorms:
MoE router weights:
Layer 0: α = 0.573, cos_fit = 0.992
Layer 15: α = 0.647, cos_fit = 0.962
Layer 30: α = 0.627, cos_fit = 0.967
Layer 45: α = 0.582, cos_fit = 0.987
Layer 59: α = 0.567, cos_fit = 0.997
Shared expert gates:
Layer 0: α = 0.568, cos_fit = 0.997
Layer 30: α = 0.581, cos_fit = 0.988
What this means
A cos_fit of 0.99 in a 2-million-dimensional space is not "high similarity." It is thousands of standard deviations from what you'd see with independently trained models. There is no innocent explanation.
The recovered α clusters tightly around 0.57 across all layers — matching nex-agi's claim of 0.571 almost exactly. This is one model poured into another at a fixed ratio.
(Layernorm weights show a higher α ~0.9. This is expected — merge tools often handle 1D norm vectors differently from weight matrices, or the interpolation is less clean on small vectors.)
Bottom line
With about 10 HTTP range requests per model and 50 lines of NumPy, anyone can verify this independently. The math is unambiguous: Rio-3.5-Open-397B is approximately 57% Nex-N2-Pro 43% Qwen3.5-397B-A17B.
Code that you can run for yourself: gist.github.com/xianbaoqian/…

11
12
105
20,912
5h
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!
155
354
3,487
379,658
5h
The first image shows Rio 3.5 admitting it is Nex, and the second image is the result of a model weight similarity check.
2
4
133
21,739
Nex retweeted

Jun 8
Nex-N2 is now open source!An agentic model series from Nex AGI built for coding, tool use, deep research, and long-horizon workflows. 🧠🔎
🛠️ modelscope.ai/models/nex-agi…
⚙️ modelscope.ai/models/nex-agi…
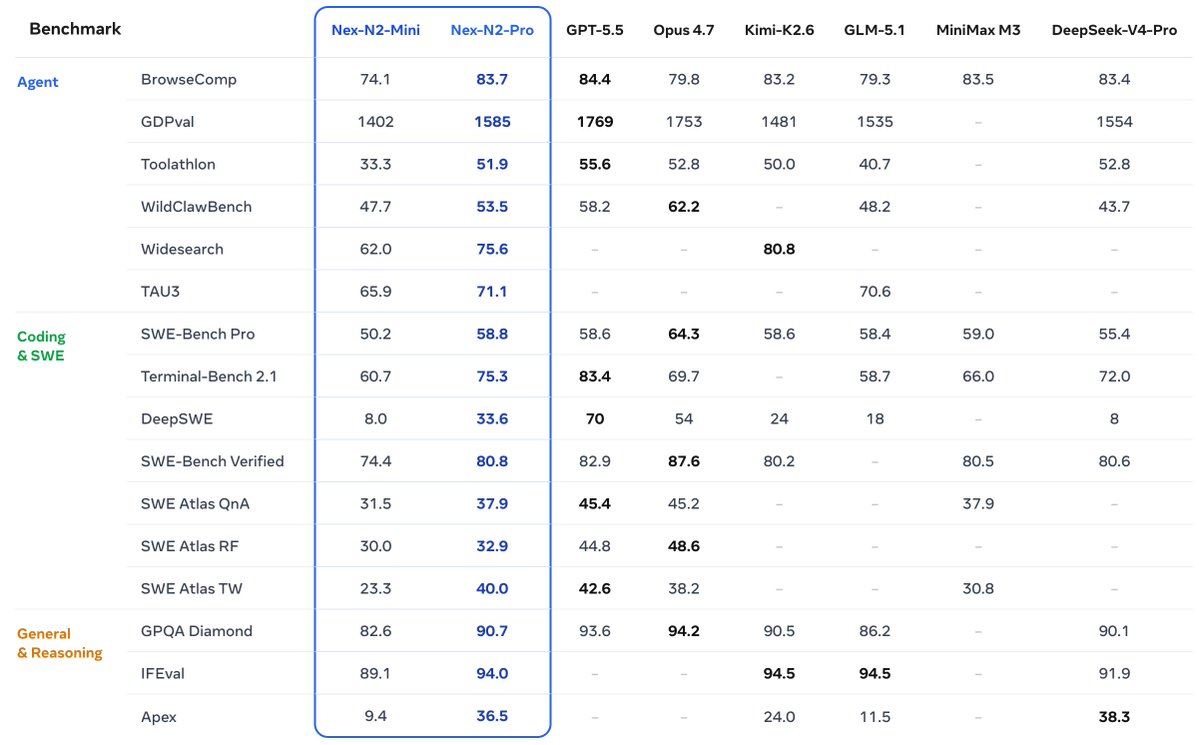
● Models: Nex-N2-Pro 397B total, 17B active; Nex-N2-mini 35B total, 3B active
● Agentic Thinking: adaptive reasoning depth coherent reasoning across coding, search, tool calling, and execution
● Efficiency: Nex-N2-mini saves roughly 20% overall token cost vs forced thinking while matching or slightly exceeding task performance
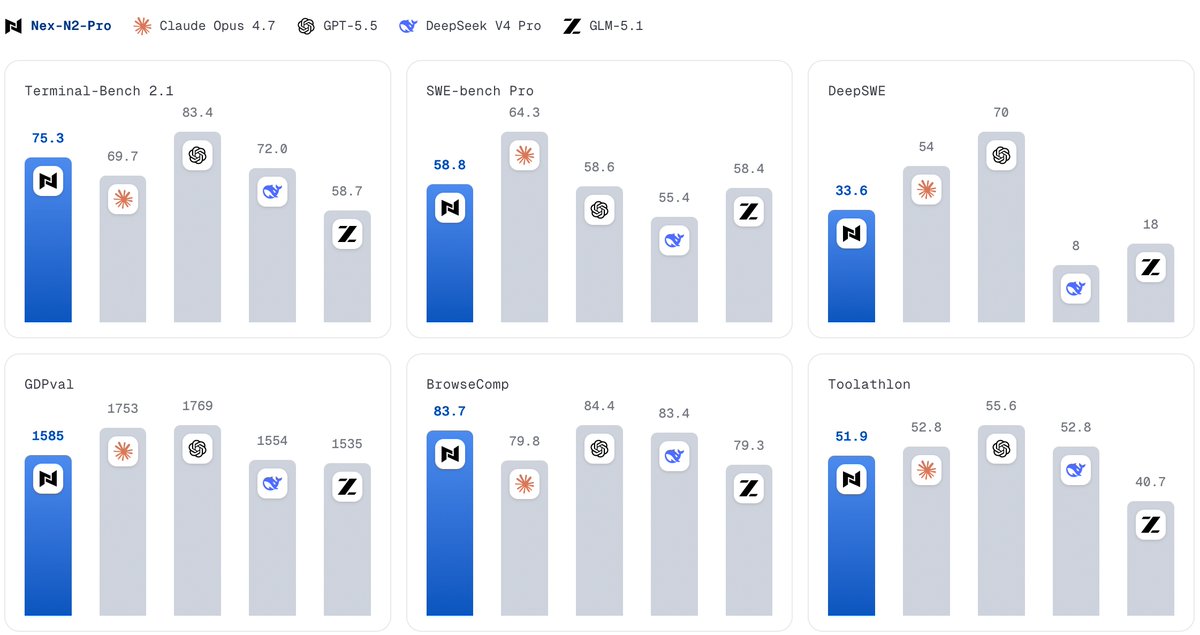
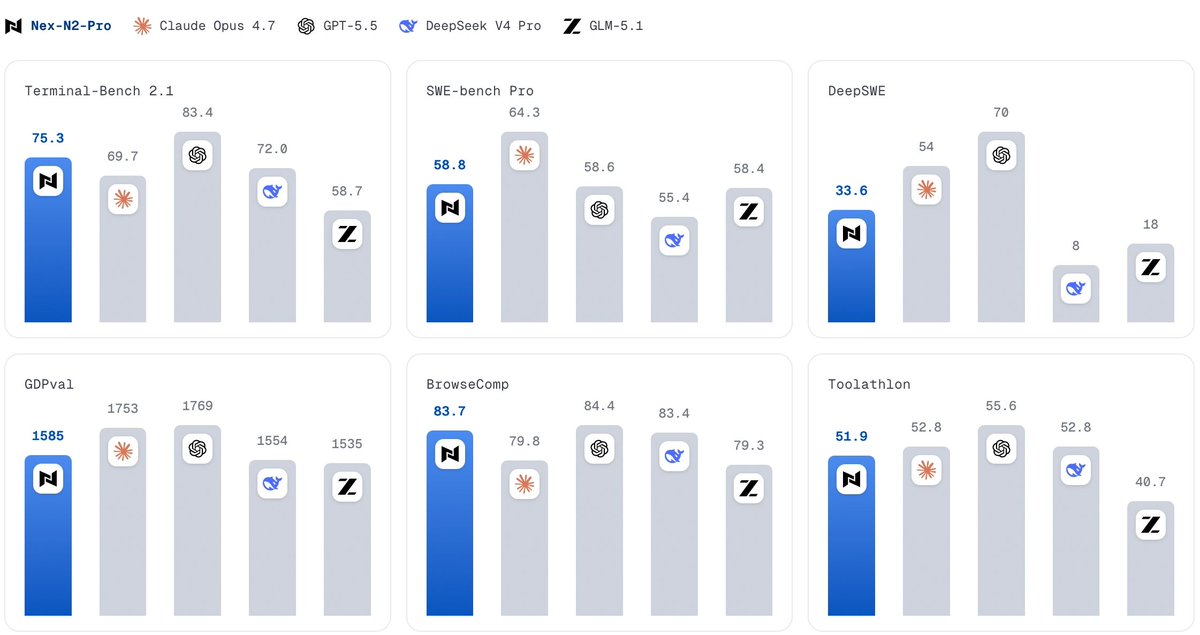
● Open-model lead: 75.3 on Terminal-Bench 2.1, 80.8 on SWE-Bench Verified, 83.7 on BrowseComp, and 1585 on GDPval among listed open baselines
● Deployment: customized SGLang fork, reasoning parser, tool-call parser, Docker image
● License: Apache 2.0
32
81
850
82,704
Jun 9
🔥 Nex-N2-Pro is now live on OpenRouter — completely FREE to try!
Give it a spin: openrouter.ai/nex-agi/nex-n2…
Drop your results below ⬇️
6
14
89
8,055
Jun 5
Nex-N2-Pro now free for 2 weeks on @SiliconFlowAI! 30-50% fewer thinking tokens with zero performance trade-off. Give it a try ⚡

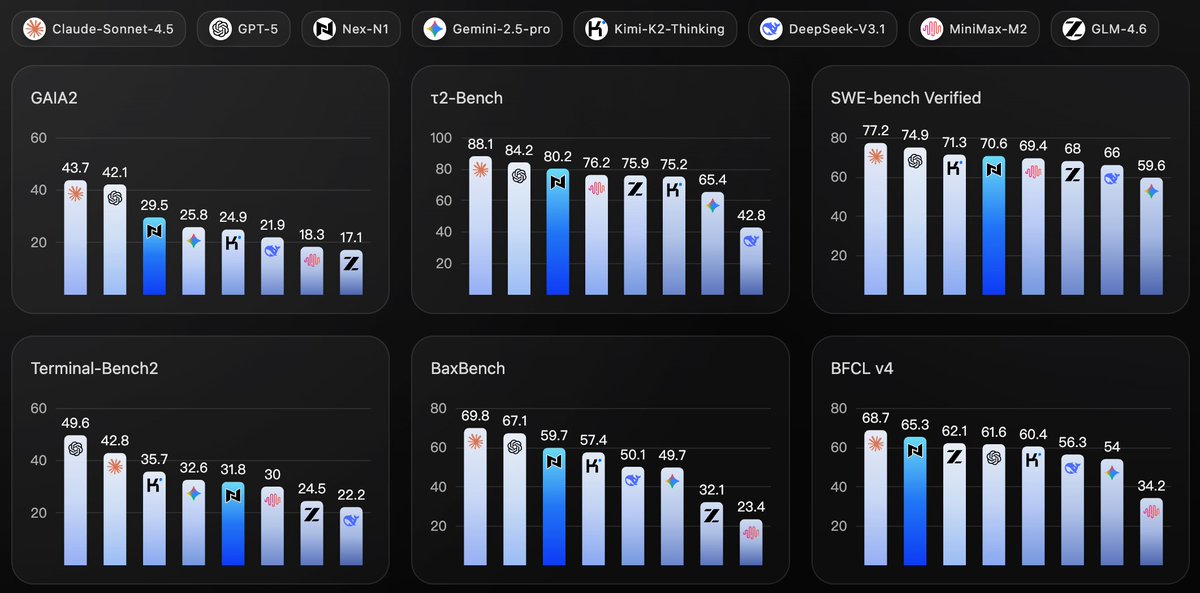
Post-training is having a moment — Nex-N2-Pro from neolab @NexEcosystem proves it.
Built on Qwen3.5-397B-A17B, delivers GPT-5.5 and Claude Opus 4.7–level performance.
🎉 T 0 Support on SiliconFlow · Free for First 2 Weeks
N2-Pro: 397B MoE / Reasoning Model / 262K context / VLM
→ Auto-adjusts reasoning depth, 30–50% fewer thinking tokens, no performance trade-off
→ SOTA performance on Terminal Bench 2.1, GDPVal, SWE-Verified
→ Excels at agentic coding, deep search, tool use
→ Plug-and-play with Claude Code, Cursor, OpenClaw, etc.
Try it on SiliconFlow ⬇️

2
3
31
4,184
Jun 5
Nex-N2-Pro now available on @novita_labs! Try it out if you're building coding agents or research workflows 🚀
Jun 4

🚀 Nex-N2-Pro from @NexEcosystem is now available on Novita AI.
An open-source agentic reasoning model post-trained on Qwen3.5-397B-A17B MoE, built for coding agents, software engineering, and deep research workflows.
Nex-N2-Pro brings:
• Agentic Thinking for complex workflows
Unifies reasoning, tool use, and environment execution for long-horizon tasks
• Strong coding terminal performance
Scores 75.3 on Terminal-Bench 2.1 and 80.8 on SWE-Bench Verified
• Designed for self-evolving harnesses
Specifically optimized for Agentic Harness Engineering (AHE), with top-tier pass@1 performance reaching 69.0% in a SQL interpreter self-evolution task
• Fast, developer-ready access
Run Nex-N2-Pro through Novita’s API with simple integration
Excited to bring Nex-N2-Pro to developers on Novita.
1
10
2,703
Nex retweeted

Jun 4
🚀 Nex-N2-Pro from @NexEcosystem is now available on Novita AI.
An open-source agentic reasoning model post-trained on Qwen3.5-397B-A17B MoE, built for coding agents, software engineering, and deep research workflows.
Nex-N2-Pro brings:
• Agentic Thinking for complex workflows
Unifies reasoning, tool use, and environment execution for long-horizon tasks
• Strong coding terminal performance
Scores 75.3 on Terminal-Bench 2.1 and 80.8 on SWE-Bench Verified
• Designed for self-evolving harnesses
Specifically optimized for Agentic Harness Engineering (AHE), with top-tier pass@1 performance reaching 69.0% in a SQL interpreter self-evolution task
• Fast, developer-ready access
Run Nex-N2-Pro through Novita’s API with simple integration
Excited to bring Nex-N2-Pro to developers on Novita.
9
3
31
5,445
Jun 4
📢 Nex-N2 is here!
A family of agentic models that doesn't just think, it acts!
Coding, search, tool use. All fused into a single agentic reasoning loop.
- Adaptive Thinking, auto-scales reasoning depth per step. Saves ~20% tokens, zero performance loss.
- Coherent Thinking, one thinking paradigm across search, coding, and tool use. No more fragile mode-switching.
🏆 Result: Tier-1 open-source performance on SWE-bench, Terminal-Bench, GDPval, and more, tracking GPT-5.5 and Opus 4.7.
🎉 Open-weight. Try it now.
🔗 nex-agi.com/
📦 huggingface.co/nex-agi/Nex-N…
modelscope.cn/models/nex-agi…
github.com/nex-agi/Nex-N2
48
95
703
322,712
Nex retweeted

Jan 22
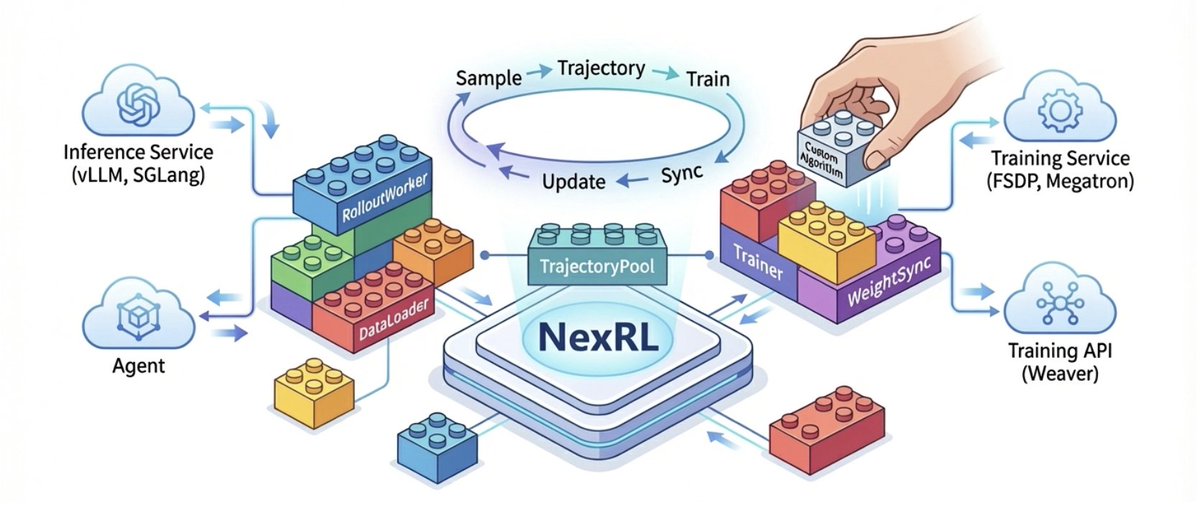
Introduce NexRL: Extreme Usability
We aim to develop an extremely user-friendly RL framework, with four main principles:
1. Extremely Lightweight
2. Extremely Community-Driven
3. Extremely Extensible
4. Long-Term Maintainability
NexRL adopts an ultra-loosely-coupled architectural design, with core characteristics embodied in component modularization and training-inference service-orientation.
Along with Nex ecosystem @NexEcosystem , NexRL has already boosted agent training, on-policy-distillation, and training API serving (see our previous blog dawning-road.github.io/blog/…).
Details at: dawning-road.github.io/blog/…
6
9
1,298
Nex retweeted
Feb 6
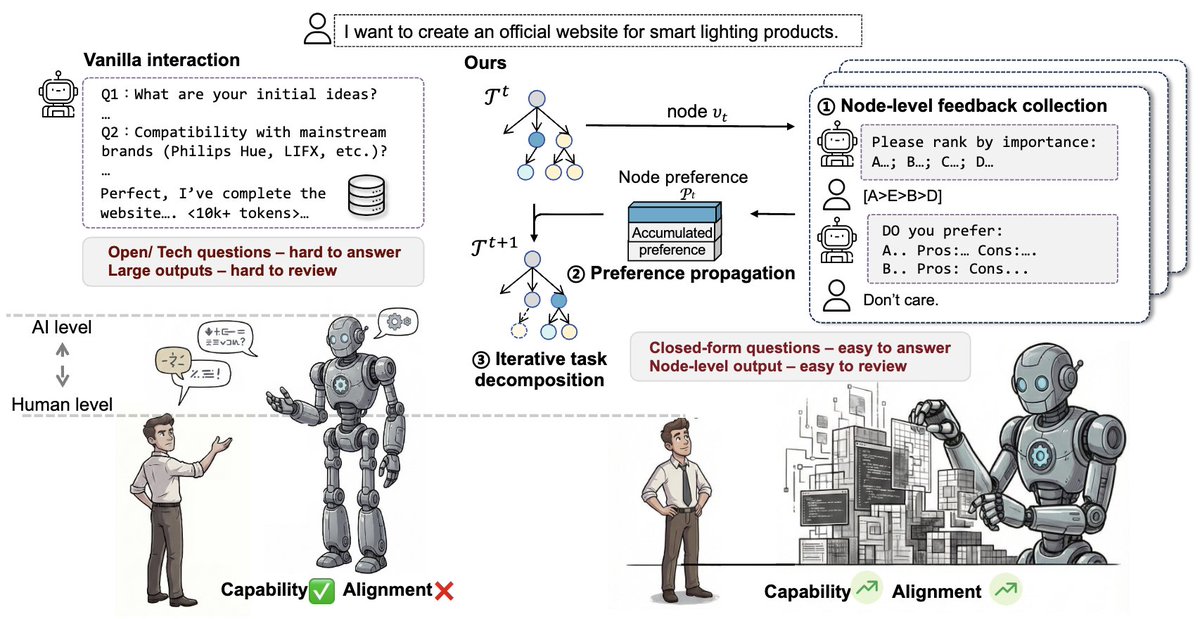
Introduce Scalable Interactive Oversight.
In vibe coding, users often fall into prolonged feedback–iteration loops. This reflects a scalable oversight problem: humans act as "weak supervisors", struggling to precisely articulate complex intent and to verify long-horizon outputs; meanwhile, models function as "strong executors", capable of efficient task execution but increasingly difficult to steer with reliable alignment signals.
Scalable Interactive Oversight decomposes complex intent into a recursive tree of manageable decisions to amplify human supervision. It can be optimized via Reinforcement Learning using only online user feedback, offering a practical pathway for maintaining human control as AI scales.
Details at: dawning-road.github.io/blog/…
2
4
9
927
Nex retweeted
Jan 20
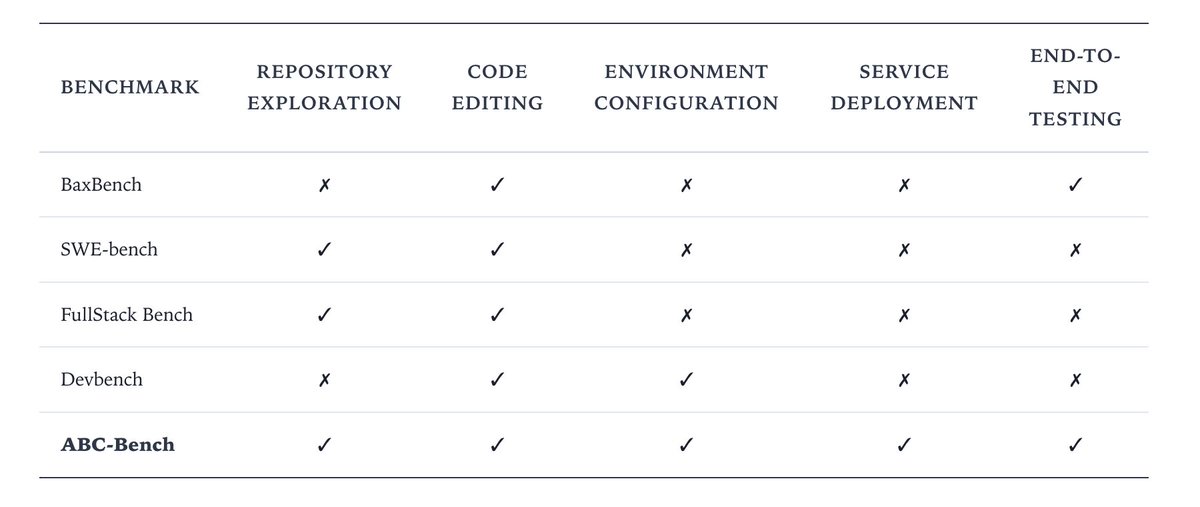
We release ABC-bench with @Open_MOSS. It benchmarks the agents' ability to reliably deliver production-grade backend services.
Findings:
1. Full-lifecycle tasks pose significant challenges for all models.
2. Models generally lack cross-language robustness.
3. Environment configuration is the primary source of performance bottlenecks.
Details at: dawning-road.github.io/blog/…
1
5
6
738
Nex retweeted
Jan 8
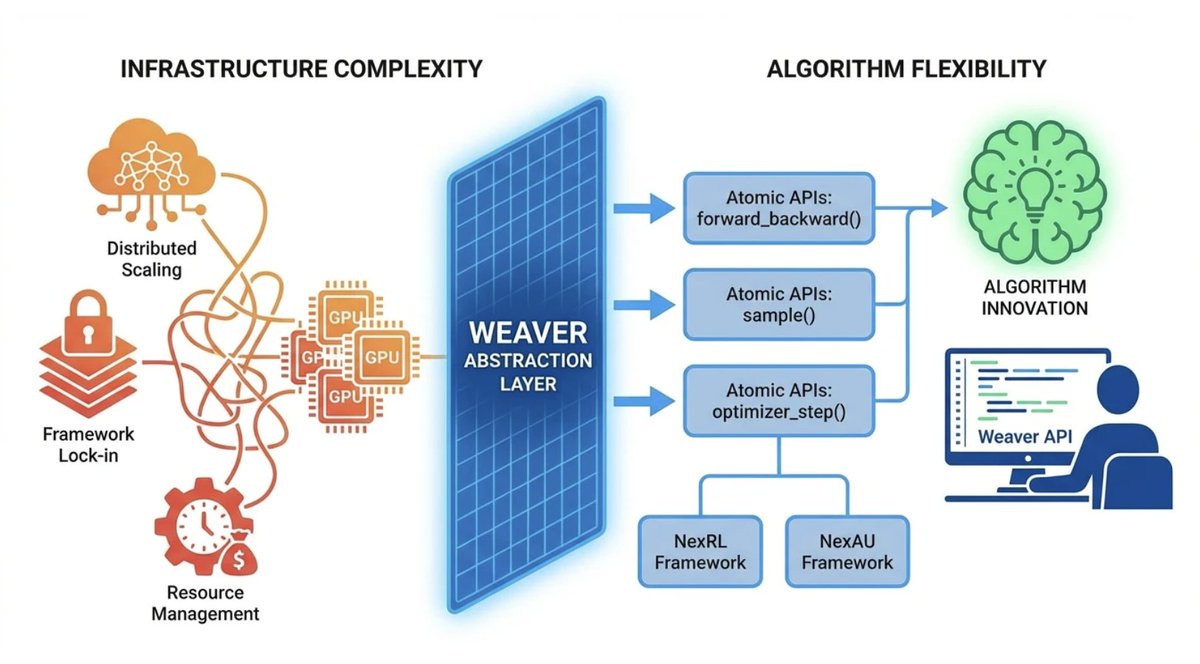
Introducing Weaver: our Training-as-a-Service platform.
Weaver is a training API designed for researchers and developers working with LLMs, inspired by Tinker @thinkymachines . As an ecosystem-oriented product, it seamlessly integrates with agent frameworks and reinforcement learning training frameworks, enabling flexible fine-tuning of agentic models. Weaver lets you focus on what matters – your data, algorithms and agents – while handling the complexity of distributed training infrastructure.
Focus on the science. We’ll handle the rest.
Details at: dawning-road.github.io/blog/…
1
7
11
809
24 Dec 2025
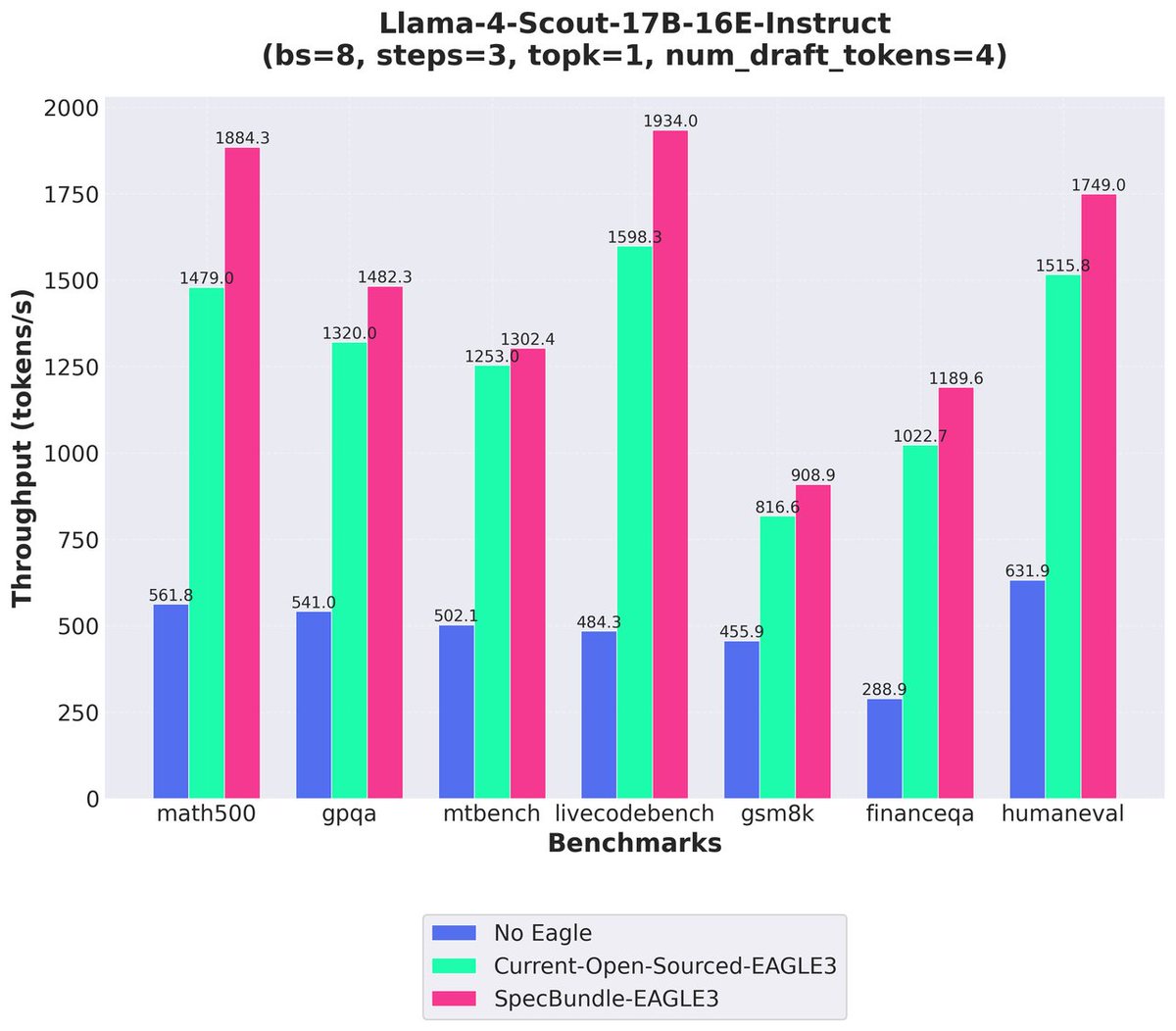
Speed matters. ⚡️
Thrilled to collaborate with @lmsysorg on SpecBundle! We’ve trained dedicated EAGLE-3 draft models for our Nex-N1 series.
By combining SGLang with our draft models, you can now achieve massive inference speedups:
🚀 2.26x on Qwen3-32B-Nex-N1
🚀 1.68x on Qwen3-30B-A3B-Nex-N1
Unlock lower latency for your agents today. 👇
#NexN1 #SGLang #SpeculativeDecoding #OpenSource

Speculative decoding has shown a lot of promise, though broader adoption has taken time due to the complexity of building production-ready tooling and high-quality draft models.
We’re releasing SpecBundle, a collection of large-scale EAGLE-3 draft models trained with SpecForge v0.2. This release brings major system improvements, including refactored training pipelines, multi-backend support with SGLang and @huggingface , and better usability at scale.
We also built a performance dashboard to make real end-to-end speedups visible across models and settings. See the dashboard and blog in the thread 👇


2
1
7
628