
Joined February 2026
- Tweets 481
- Following 47
- Followers 6,102
- Likes 1,275
45 Photos and videos











Pinned Tweet

May 27
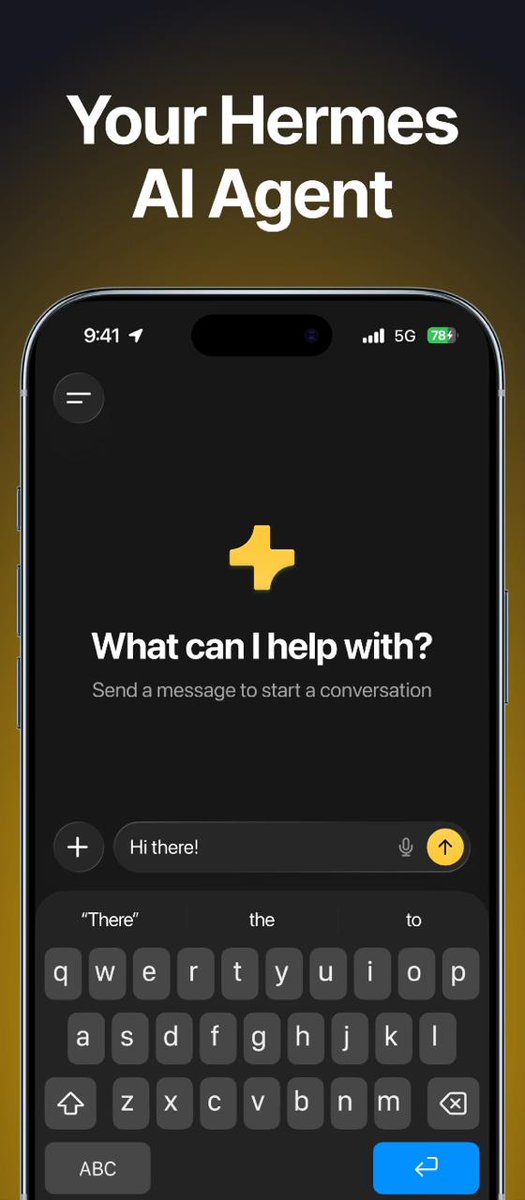
We released iOS app for Hermes Agent 📱
Connect to your self-hosted agent over Tailscale, Cloudflare Tunnel or ngrok. Or deploy on a VPS. Run tasks and manage your agent from anywhere.
37
50
445
109,234
atomicbot.ai retweeted

Jun 12
New Kimi K2.7 Code performs at GPT-5.5 level 3x cheaper!
We gave both models the same three prompts: build a self-contained HTML5 canvas sim with real physics, no libraries. A spring pendulum on a stretching coil, a 1 kg block trading collisions with a 100,000 kg block, and 22 balls churning in a spinning hexagon
Outputs:
Kimi K2.7 Code: $0.28 on 52.4k tokens
GPT-5.5: $0.93 on 23.4k tokens
Spring pendulums and blocks came out even. The balls Kimi did better: its pile spins with the drum when GPT's bounce around in pure chaos. On price to quality, K2.7 Code is the clear pick
32
64
864
128,034
atomicbot.ai retweeted
Jun 12
Diffusion Gemma is 4x faster, but makes 6x more mistakes!
We benchmarked the new diffusion LLM against its autoregressive twin on a single H100 (FP8). We gave each the same three tasks: write a Steve Jobs biography, the history of Tetris, and the story of BeOS - every next topic less popular than the previous one. Then we fact-checked every claim in every answer.
Gemma4 got 45 facts right, 5 wrong. DiffusionGemma got 33 right, 28 wrong. The less popular the topic, the worse it got: 4 mistakes on Jobs, 12 on Tetris, 12 on BeOS. It named Clara Clley as Steve Jobs' mother, invented a colleague for Pajitnov named Geri Gulovik and priced the BeBox at $9,999. The real one cost $1,600.
Outputs:
Gemma4 26B A4B: 218 tok/s · 15.1s total · 45 facts · 5 mistakes
DiffusionGemma 26B A4B: 763 tok/s · 3.7s total · 33 facts · 28 mistakes
The reason is simple. DiffusionGemma throws 256 tokens on the screen at once and polishes them pass after pass until the text sounds smooth. Smooth is all it cares about: a fake name, date or number sounds just as smooth as a real one, so it stays. Regular Gemma4 meanwhile writes one word at a time and checks every new word against everything before it. Google says it themselves in the launch post: quality is lower, use regular Gemma 4 when facts matter.
42
64
602
72,554
atomicbot.ai retweeted
Jun 11
Atomic Chat is now on Hugging Face 🤗
We're officially a Local App on the world's biggest AI hub. Run 200,000 open-weight models from @huggingface directly on your device - private, local, and open source!
11
23
108
26,554
atomicbot.ai retweeted
Jun 4
Nemotron 3 Ultra performed GPT 5.5 level 10× cheaper
We gave three same prompts to build HTML5 canvas with real physics. At first scene we have water in a spinning drum. Galton board - balls through pegs into bins. And a block collision setup with extreme mass differences.
Outputs:
Nemotron 3 Ultra: 11.3k tokens, $0.051
GPT 5.5: 11.0k tokens, $0.57
Nemotron stays right on GPT 5.5's heels, but at 10× cheaper. The gap in quality is far smaller than the gap in price.

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
69
186
2,243
697,671
atomicbot.ai retweeted
Jun 3
New Google Gemma 4 12B claims near-26B performance - we tested both!
We ran both models locally on one RTX 4090 and gave each the same task: write a self-contained HTML5 canvas animation with real physics in one file without libraries. Three scenes - a Galton board, two blocks colliding off a wall, and a chaotic triple pendulum
Outputs:
Gemma 4 26B-A4B: 15 GB VRAM usage, 6.9k tokens, 138 tok/s
Gemma 4 12B: 9 GB VRAM usage, 8.9k tokens, 80 tok/s
Same Gemma 4 family, but the 26B-A4B won every scene and ran ~1.7x faster - on just 4B active params. The 12B stayed very close though, on almost half the VRAM - which makes it the ideal model for a 16 GB laptop
37
76
1,020
150,475
atomicbot.ai retweeted
Jun 1
MiniMax M3 turned a napkin sketch into a playable game
We handed MiniMax M3 a hand-drawn draft of a Doodle Jump style platformer. It read the elements off the draft, wrote the logic, drew the interface and shipped it as one self-contained HTML game
Input: 6,920 tokens
Output: 9,933 tokens
Cost: $0.028
@MiniMax_AI drops M3 on @huggingface next week
19
28
445
64,320
May 27
We released iOS app for Hermes Agent 📱
Connect to your self-hosted agent over Tailscale, Cloudflare Tunnel or ngrok. Or deploy on a VPS. Run tasks and manage your agent from anywhere.
37
50
445
109,234
May 27
grab it here 👇
apps.apple.com/au/app/atomic…
💬 Drop a comment and first 20 get 1 month free VPS
11
6
1,374
May 15
Hermes Agent vs OpenClaw using Qwen 35B Local Model
We asked agents to scrape GitHub star history for both tools, find what caused the growth spikes, build a live dashboard in the browser.
MacBook Pro M5 Max 64Gb
OpenClaw: 203k tokens, 12m 01s - wrote a bash script
Hermes: 257k tokens, 33m 01s - wrote a SKILL.md
OpenClaw hit GitHub API, got truncated responses, paginated through contributors, pulled star-history JSON, found a security incident in OpenClaw's history, fetched SVGs, fixed broken HTML from trimming, rewrote it clean.
Hermes parallel tool calls across GitHub API, web search, and browser. Hit Google rate limit, auto-switched to DuckDuckGo. Fetched article contents, mapped viral moments, then built the dashboard.
Both shipped a live dashboard with star growth charts and spike annotations
77
50
699
603,722
Apr 24
Try DeepSeek V4 in Atomic Bot
Run OpenClaw & Hermes agents in the Cloud
Apr 24

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

7
4
33
4,342
Apr 23
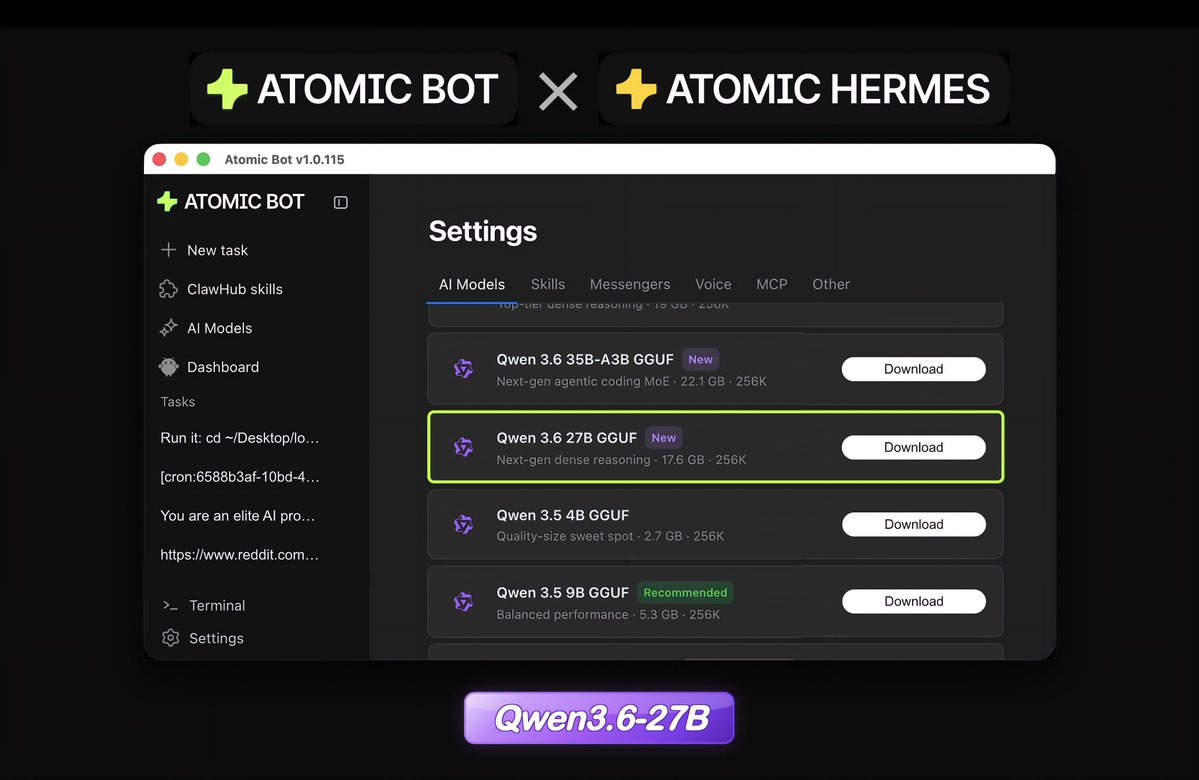
New Qwen3.6-27B is live in Atomic Bot for
OpenClaw & Hermes agents
Local 27B model that beats a giant 397B model
on coding. Free and Open Source!
Apr 22

🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power!
Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇
What's new:
🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks
💡 Strong reasoning across text & multimodal tasks
🔄 Supports thinking & non-thinking modes
✅ Apache 2.0 — fully open, fully yours
Smaller model. Bigger results. Community's favorite. ❤️
We can't wait to see what you build with Qwen3.6-27B! 👀
🔗👇
Blog: qwen.ai/blog?id=qwen3.6-27b
Qwen Studio: chat.qwen.ai/?models=qwen3.6…
Github: github.com/QwenLM/Qwen3.6
Hugging Face:
huggingface.co/Qwen/Qwen3.6-…
huggingface.co/Qwen/Qwen3.6-…
ModelScope:
modelscope.cn/models/Qwen/Qw…
modelscope.cn/models/Qwen/Qw…

3
4
30
3,964
Apr 21
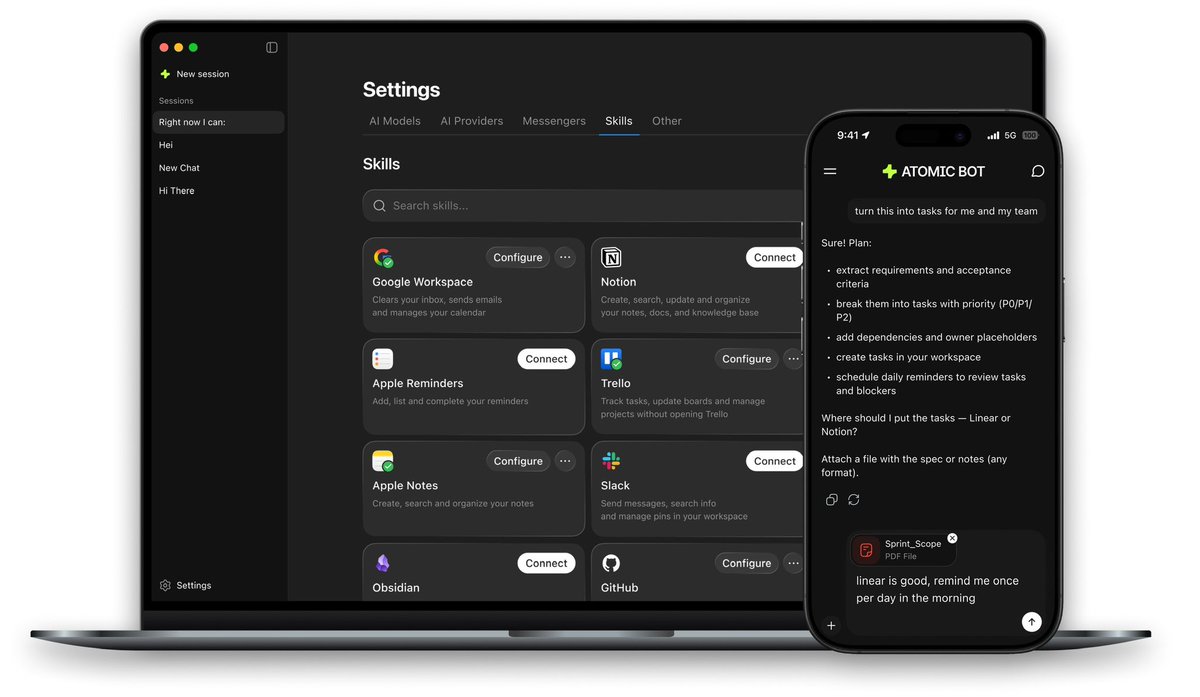
Hermes Agent by @NousResearch (100k ⭐) now inside Atomic Bot:
– Free Local models: Qwen, Gemma or
– Use your API keys for any provider
– Dashboard, terminal, logs and files explorer
– Private and Open Source
Download MacOS app or run in Cloud👇
52
61
651
343,620
Apr 20
You can run Hermes agent by @NousResearch with Kimi K2.6 on @atomicbot_ai VPS 🌑
@Kimi_Moonshot just dropped a new open source coding model. We asked Hermes to build and deploy a game. It did incredibly well!
9
31
137
42,789
Apr 17
Generate websites with OpenClaw 🦞
Add the @21st_dev MCP in @atomicbot_ai
Your agent runs the flow:
→ Generates UI variants
→ Picks the best result
→ Ships it into your desktop project
Open-source. Local models supported.
9
9
48
5,019
Apr 15
Running OpenClaw with Minimax 2.7 on @atomicbot_ai
We asked to recreate a legendary game — it built Flappy Bird, but with a lobster 🦞
New Open Source frontier model did this extremely well, big shoutout to @MiniMax_AI
12
9
53
27,704
Apr 7
Running OpenClaw with GLM-5.1🦞
Open-source frontier model. 754B parameters. Large context window. Perfect for agentic tasks. Thanks to @Zai_org for making this possible!🫰
16
18
86
14,069