
4 Photos and videos





Another good article explaining agents and harness.

As usual, @hadleywickham has one of the cleanest, simplest, nicest explanations of things: in this case, the relationship between LLMs, harnesses, and agents. Better than a million Medium posts.
tidydesign.substack.com/p/wh…
3
Sourav retweeted

Jun 10
I've been writing a whole guide! simonwillison.net/guides/age…
12
33
423
55,063

很好的综述

19
34
299
72,181
Agents doing boring work is good for solid engineering.

Old software engineering patterns are coming back because of coding agents. Dax Raad(@thdxr), co-founder of AI coding agent OpenCode, on why DDD is becoming more relevant and less painful:
“I think it's the same problem as always, which is how do you make code bases that are easy to work in, scalable, that can flex to new requirements.
A lot of the old patterns for me are coming back. We've always been a big domain-driven design company. We did it in a very light way.
We're now doing it in a much heavier way because we find that these, kind of boring, enterprisey patterns end up being pretty useful because you have a bunch of idiots on your team now.
Coding agents are a bunch of idiots. They are going to work 24/7 and they're going to ship a lot of stuff so you need way more guardrails than you used to.
What's nice is some of these old patterns we hated because they were very verbose, they produced reliable code that was modular and safe but they were very verbose and annoying to type out… you're not typing it out anymore.
Now you can get the benefits of these patterns without the downsides."
3
If you don't know what a harness is, read this.

8
Sourav retweeted

May 28
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
308
980
8,944
791,761
Sourav retweeted

May 29
Mock foodpharmer all you want but a part of this change has to be credited to him for making people aware of what they are consuming. Else nobody would have given a rats ass about consumer benefits

166
1,948
13,882
257,934
Sourav retweeted

May 13
I believe that spec-driven development, whether formal specs or conversations, is the future. But writing great specs is hard, and always has been.
That's why I'm super excited about this new blog post from the @kirodotdev team, and our automated reasoning teams at AWS.
6
40
339
30,094
Sourav retweeted

May 8
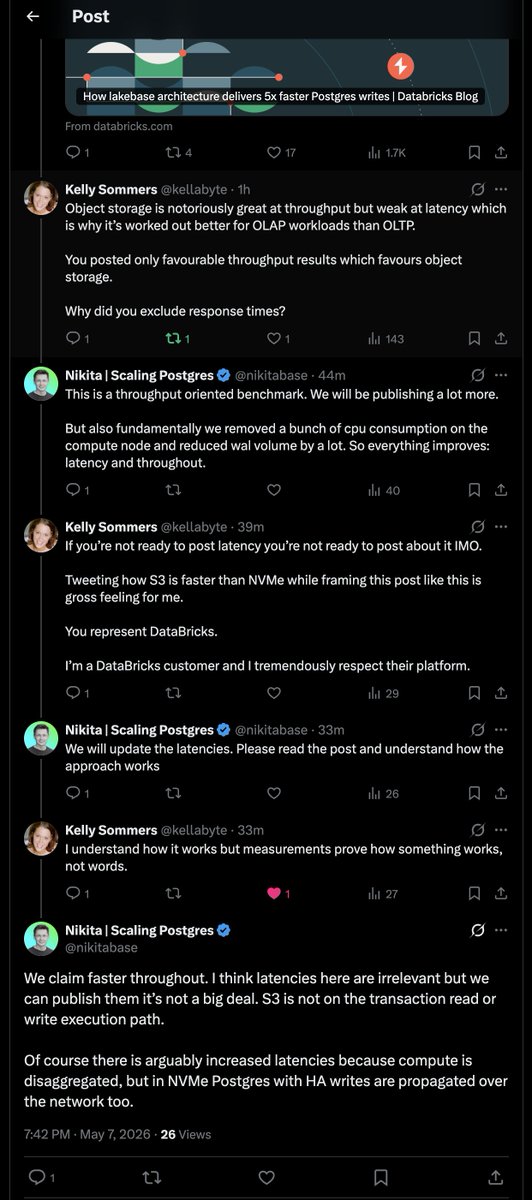
We built a database system on S3 Express, and I wrote a book about latency, so let me comment on some of the technical details.
When we talk about write latency in a database system, the limiting factor is typically the time to commit to durable storage. If you are using object storage as your backing store, you have two options for the write path, depending on your durability model. The first option is to write to the object store asynchronously, which means object storage is irrelevant to your write latency, and therefore, uninteresting when comparing S3 Express and NVMe latency.
The second option, which is what we actually do, is that you write to S3 Express synchronously, and now your commit latency is bound by it. In other words, when a commit needs to become durable, we perform a PUT request on S3 Express as a replacement for a `fsync()` call on NVMe. In other words, if the PUT request succeeds, your commit is now durable on S3 Express, just like with `fsync()`, it's durable on disk. (Of course, you often want replication to multiple disks, but you can parallelize that, and it does not change the scenario very much.)
In this scenario, we can meaningfully compare NVMe and S3 Express latency: NVMe has up to 100x lower latency because enterprise-grade NVMe latency is in the tens of microseconds, whereas S3 Express latency is in the single-digit millisecond range. Of course, depending on your database architecture, you may also see additional latency from networking, but there is no scenario where object storage has lower latency than NVMe.
Of course, there are many other advantages to building on top of object storage. For example, high availability, elastic storage scaling, cost-efficiency, and, in my opinion, competitive latency for many use cases. But we're talking about just pure write latency; S3 Express is clearly not faster than NVMe.

10
28
485
62,458
Sourav retweeted

Apr 27
Barbara Liskov is a Turing award winner famous for her contributions to programming languages and distributed systems. I interviewed her recently about:
• Being rejected from college based on gender
• The software crisis of the 1970s
• Paxos vs Viewstamped replication (her invention) and why one is more well known
• Stories of Dijkstra and how his work influenced hers
• Why her Turing award was questioned
Where to watch:
• Youtube - youtube.com/watch?v=T9CGjbPZ…
• Spotify - open.spotify.com/episode/7yM…
• Apple Podcasts - podcasts.apple.com/au/podcas…
• Transcript - developing.dev/p/turing-awar…
10
93
627
169,429
Sourav retweeted

Apr 26
The DDIA book (Designing Data Intensive Applications) is a classic no-doubt and has much in-depth stuff about distributed systems (Nowhere close to completing it though). However it is also too much to digest for any beginner (me).
Personally I found this one a much better starter book. Gives a birds-eye-view of the systems and components along with a hands-on exercise after each pattern. Also just a bit over ~160 pages - readable in a few days. A week or so if doing hands-on›




9
128
1,688
110,797
Sourav retweeted
Apr 26
Marc Brooker (AWS Distinguished Eng): "The downside of caches, especially in distributed systems, is they have this mode, where the cache is empty or contains the wrong data.
The system is slow, often down, because now the backend isn't scaled to deal with all of this uncached traffic.
Customers are very disappointed and often it is down in a stable way. Like it's still it's down, but it's not going to come back up under its own energy.
Because, for example, all of this traffic is causing a huge amount of contention in my database or is saturating the network and so I can't even refill the cache. It's not even getting the right kind of data in
In general, I prefer to see the teams around me avoiding caching where possible." @MarcJBrooker
Apr 13

Marc Brooker ( @MarcJBrooker ) is a Distinguished Eng at AWS who has been building distributed systems there for almost 2 decades. I interviewed him about technical learnings from his experience. We discussed:
• Learnings from 3000 post mortems
• When caching is a bad idea
• How software engineering is changing
• Visibility and apparent expertise
• How to find the best problems
Where to watch:
• YouTube: youtu.be/u3GjIXP9N0s
• Spotify: open.spotify.com/episode/1qX…
• Apple Podcasts: podcasts.apple.com/us/podcas…
• Transcript: developing.dev/p/aws-disting…
13
36
513
136,831
Sourav retweeted

Apr 20
I love Geoff.
But he understands even less than Dario about the effects of technological revolutions on the labor market.
Again, don't listen to AI scientists, as brilliant as they might be, and even less to AI CEOs, as successful as they might be, for questions of labor economics.
Listen to reputable economists who have studied these things like @Ph_Aghion , @DAcemogluMIT , @erikbryn , @amcafee , @davidautor , etc.
151
220
2,804
290,857
Sourav retweeted

In India, the unemployment rate for illiterates is 3%. For graduates aged 15 to 24, it's 40%. The more educated you are in this country, the more likely you are to be jobless. Not because education is worthless, but because it creates aspirations the economy struggles to absorb. 🧵👇
82
586
3,517
218,950

Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
4,137
14,992
148,106
63,901,878
Sourav retweeted

Apr 17
Honestly I really *enjoy* engineering work. I also doubt you can develop the structured thinking required to be a leveraged engineer without actually doing it every day. If you want to keep doing leveraged engineering work, come to Convex.
5
7
153
9,076

Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
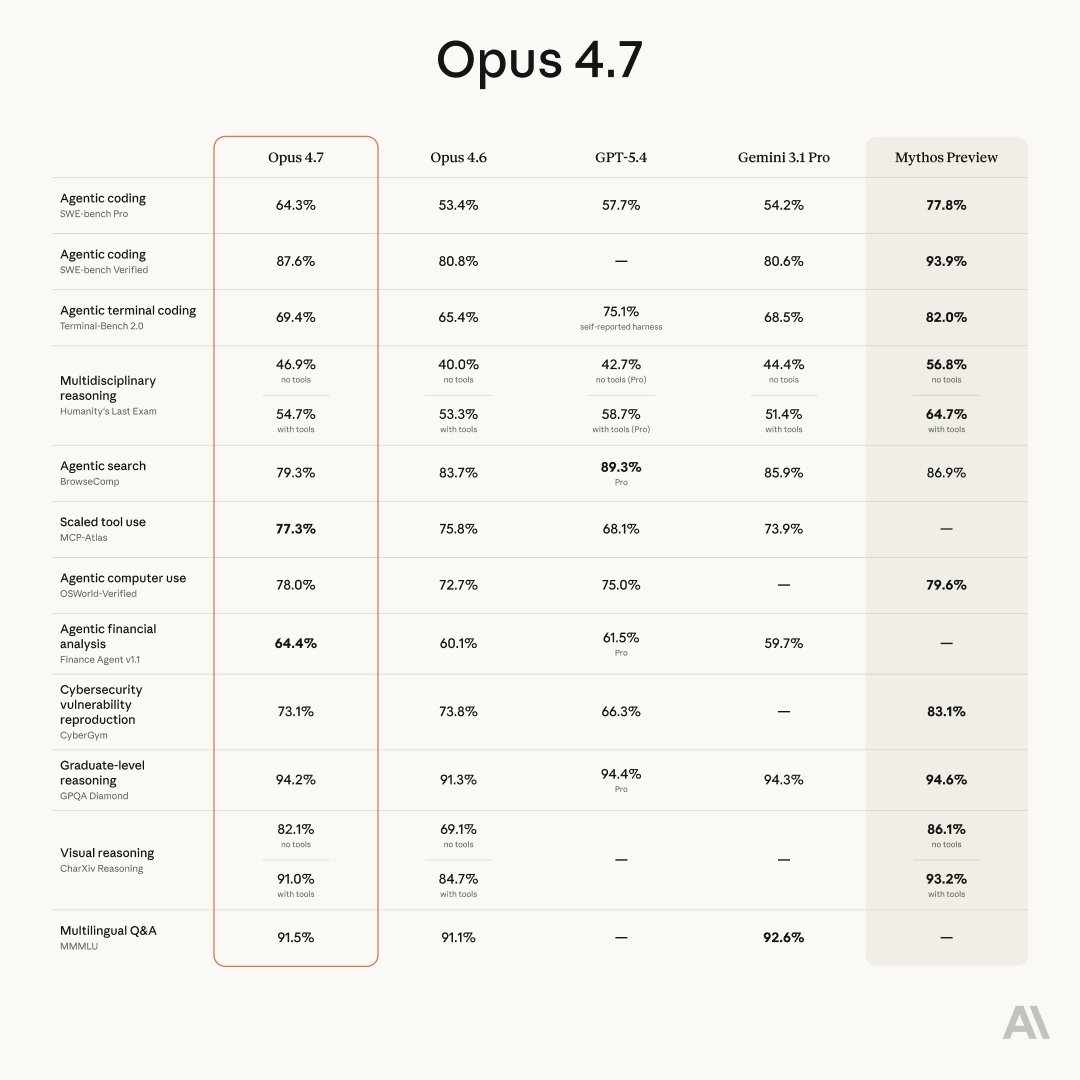
ALT Claude Opus 4.7 Benchmarks
4,718
10,113
80,736
13,960,424
Sourav retweeted
Apr 10
Time for a big systems advice thread!
In distributed systems there's no magic "push everything to prod at once" button. Every service gets pushed independently and nodes within a service get updated incrementally. If you mess up forwards/backwards compatibility you can fail irrecoverably.
So how to avoid this?
1/5: Decouple data and code changes. Never push out a release that changes how data is stored at the same time as the code that uses this new data. If there's a bug and you need to roll back to the old version of your code it won't be able to handle the new data in the new format. Instead push out a release that first changes the data in a way that’s compatible with both the old and new code (e.g., optional fields etc), when that’s stable push out the new code that uses it, then when that’s stable you can change the data to remove backwards compatibility. This is known as a “migration” in the database world and yes it’s annoying, but yes you need to do it.
16
69
692
61,140

have you read the red team blog post? i believe it has oodles of technical detail you'd appreciate
red.anthropic.com/2026/mytho…
2
1
11
8,154