
Joined January 2023
- Tweets 120
- Following 30
- Followers 1,427
- Likes 122
6 Photos and videos




Pinned Tweet

14 Aug 2024
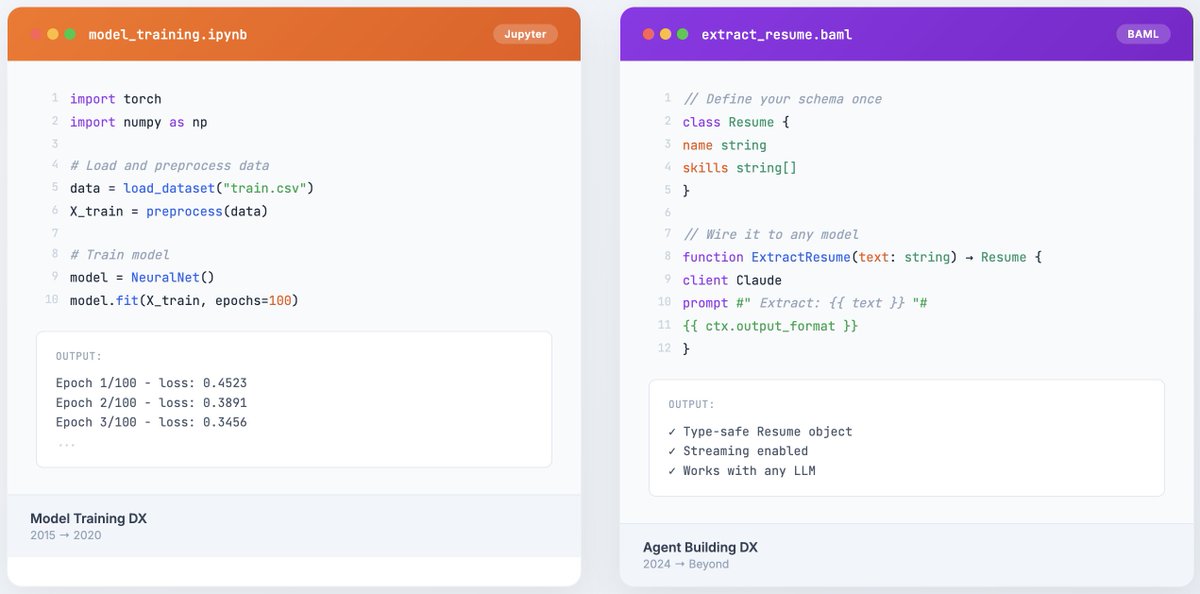
We decided to make our function-calling benchmark results fully public and interactive!
14 Aug 2024

Our interactive function-calling benchmark results are live!
boundaryml.com/blog/sota-fun…
11
4
27
17,398
Jun 10
lets go!!
Jun 9

One week out: Seattle Rust User Group meets Thursday, June 18 at 6pm PT, hosted by @boundaryML.
@conradirwin from Zed is in town to talk CRDTs, alongside talks from @boundaryML and the local Rust crowd.
Excited to see you there!
meetup.com/seattle-rust-user…
1
564
Boundary retweeted

Jun 4
The Seattle Rust User Group meetup is on Thursday, June 18 at 6pm PT, hosted by @boundaryML.
@conradirwin from Zed is giving a talk on CRDTs, alongside talks from @boundaryML and the Seattle Rust community.
RSVP:
meetup.com/seattle-rust-user…
2
38
8,589
Boundary retweeted

May 29
At @boundaryML We're building building a full compiler, VM and async runtime.
Kinda like TypeScript V8 Node.

i wonder about people who are claudemaxxing/codexmaxxing 18 hours a day, like what are these folks building exactly?
3
3
17
3,416
May 28
marginally manageable is the highest form of flattery

5/x: and then use @boundaryML 's BAML for chunking things out and testing / iterating quickly. fuck llms and prompts etc but if you have to work with them BAML is like the only thing that makes it feel marginally manageable.
348
Boundary retweeted

May 19
We are launching a programming language built for agents soon called BAML that has been in the making for 1 years. You can follow @boundaryML
We are a small team of 6 developing it with care, gathering feedback from humans and agents.
Fully Open Source.
If you are interested DM me for early alpha access.
May 15

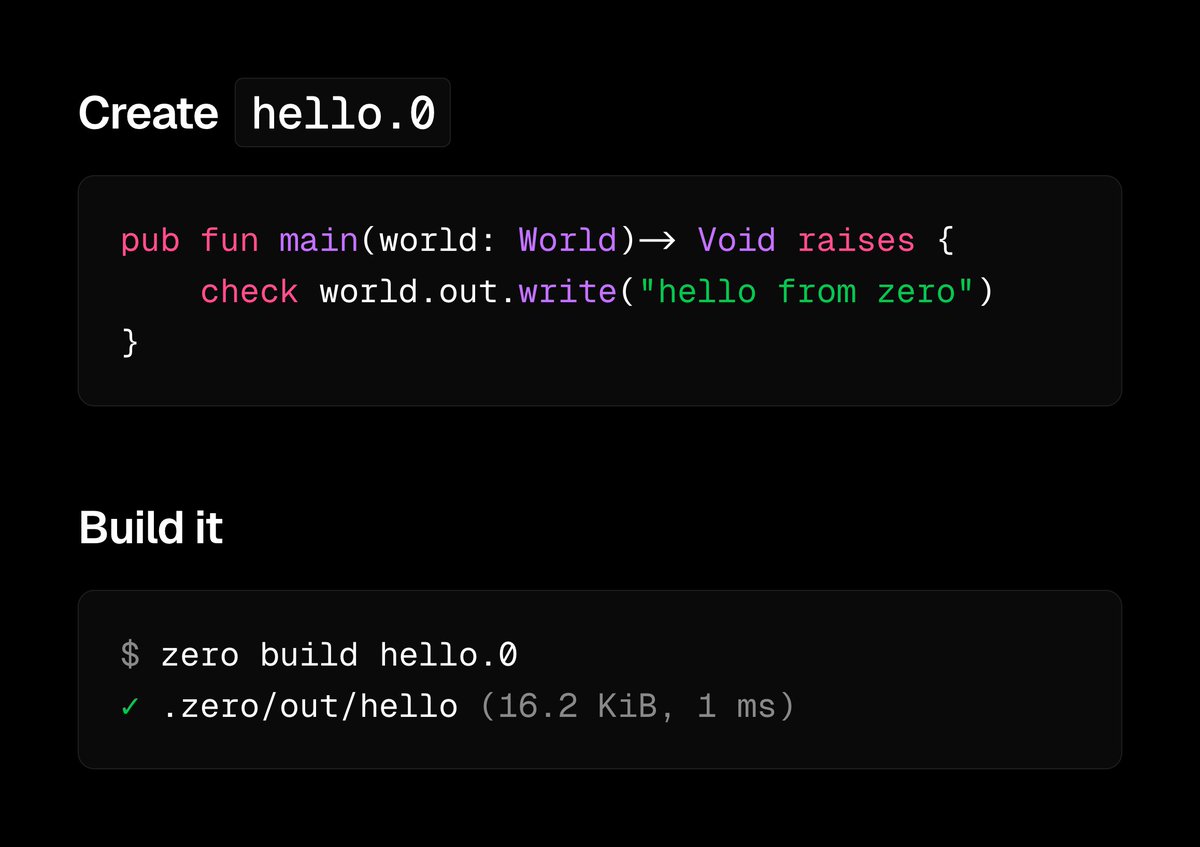
Introducing Zero
The programming language for agents.
I wanted a systems language that was faster, smaller, and easier for agents to use and repair.
Explicit capabilities. JSON diagnostics. Typed safe fixes.
Made for agents on day zero.
2
2
13
1,554
Boundary retweeted

May 14
I benchmarked a new extraction harness on a private eval dataset for lerim-cli (new version is out now - v0.1.83) and the main lesson was very clear: if you want smaller models to work well, you should stop asking the model to do everything and start doing more engineering work.
Before, the agent was closer to a single-pass PydanticAI setup: read a large trace, understand what matters, decide what is durable memory, call tools correctly, stay inside the context window, and output clean structured records.
That puts too much burden on the model, especially when you want to use smaller or cheaper models.
The new harness is BAML (@boundaryML) LangGraph (@LangChain).
The graph now does more of the deterministic work:
- read the trace in windows
- ask the model to scan one window at a time
- keep compact findings instead of the whole trace
- synthesize memory records only at the end
- validate/retry typed BAML outputs
- persist with normal code, not model improvisation
So the model is not the whole agent anymore -> It is one reasoning component inside a more engineered system.
On the private benchmark, using the same MiniMax M2.7 model, the new harness completed all cases while the old harness had multiple failures from tool retries and context window issues.
- Task completion: BAML LangGraph completed 100.0% vs PydanticAI at 72.73%, a 27.27 point lead.
- Case failures: BAML LangGraph had 0 failures vs PydanticAI with 6, meaning 6 fewer failures.
- Episode count rate: BAML LangGraph reached 100.0% vs PydanticAI at 81.25%, a 18.75 point lead.
- Record budget rate: BAML LangGraph reached 46.88% vs PydanticAI at 28.12%, a 18.76 point lead.
- Concept recall average: BAML LangGraph scored 0.428 vs PydanticAI at 0.2598, a 0.1682 improvement.
- Quality average: BAML LangGraph scored 0.3352 vs PydanticAI at 0.318, a 0.0172 improvement.
- Tool call errors average: BAML LangGraph had 0.0625 vs PydanticAI at 1.9688, much better.
Quality is not solved yet. It is only slightly better overall and still needs better pruning before persistence. But robustness improved a lot.
This is the direction I think specialized agents should go: smaller models, more deterministic scaffolding, less magical thinking about one giant prompt doing the whole job.
Next step is to make this work well with models people can run locally.
A new version of Lerim-cli is now released with the extract agent refactored to use Langgraph BAML. Next agents will be refactored as well soon in the next releases.
github.com/lerim-dev/lerim-c…

1
1
5
335
Boundary retweeted

Apr 5
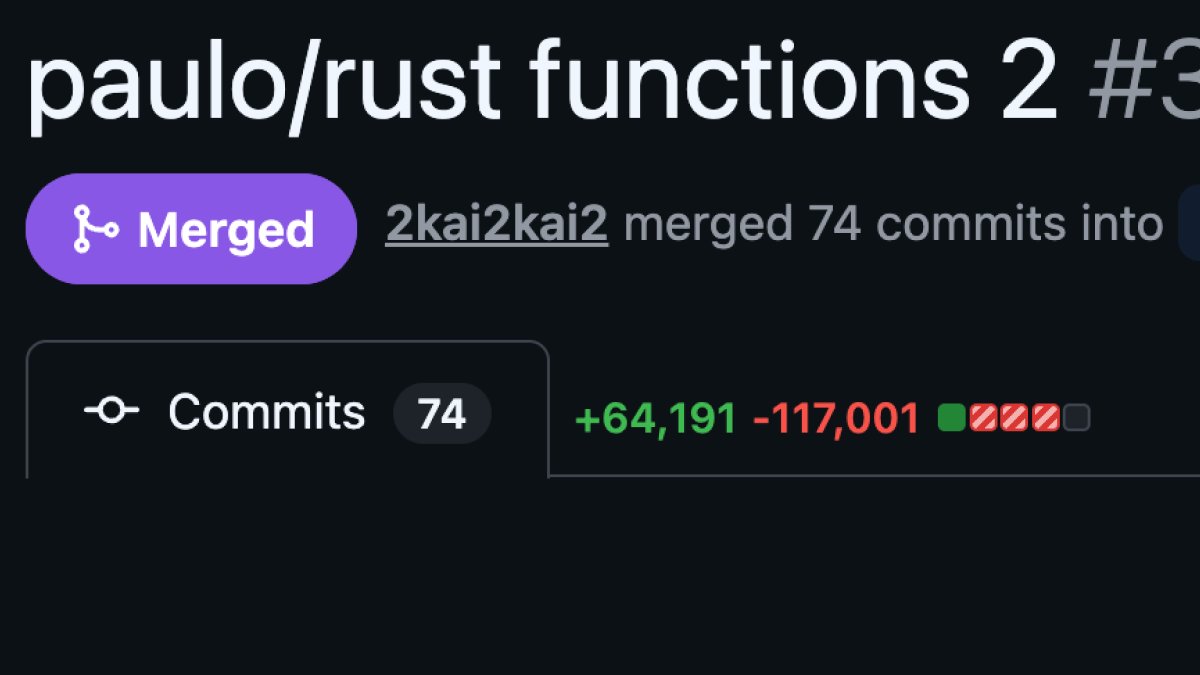
Refactoring is definitely much easier now. Here's how i used agents to refactor our entire compiler ( 65k, -117k, 74 commits).
1. Forked parallel crates (foo --> foo2) 2. Strict dependency firewall (enforced via precommit)
3. Audited core data structures first <-- took time
Apr 5

"Refactoring is so much easier now"
Not if you're generating 100x more code to refactor
2
1
26
6,177
Mar 29
Mar 28

My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept):
Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
1
12
1,728
Boundary retweeted

Mar 26
Announcing the BAML Bounty...
For all power-users of BAML, we're giving away free BAML merch! (t-shirts, stickers, hoodies 🔥🧯).
Share what you built with BAML with #baml → Fill out tally.so/r/PdErze → Free merch!
Hurry! Supplies are limited to the first 50 posts.

5
6
885
Boundary retweeted
Mar 17
Looking for designers who have Blender experience! Will pay ~$500 for a single asset
49
2
61
3,258
Mar 18
RT @anishpalakurT: Hiring an absolutely cracked video editor for something big @boundaryML...
DM me and follow so I see it! 👇
1
180
Boundary retweeted
Mar 18
If you read papers like this for fun you'll fit right in @boundaryML
Join us, we're growing

1
7
471
Boundary retweeted
Mar 17
syntax makes a huge difference to how good coding agents are, and languages should be rethought. some great learnings from rust and go!
great post by @aaronvi
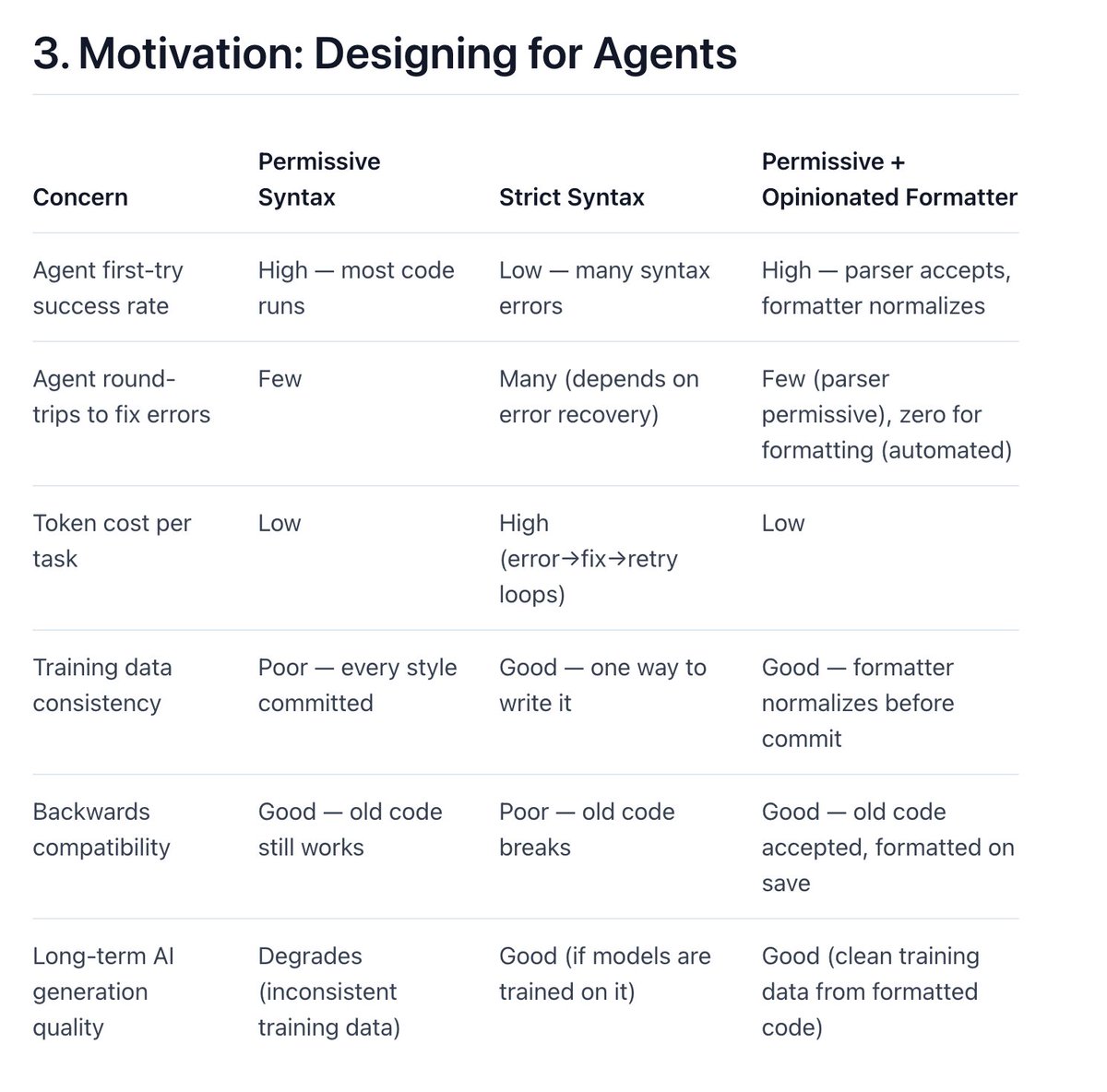
2
1
10
1,258
Feb 18
Hot take: building agents without BAML in 2026 is like training models without Jupyter notebooks in 2020.
Technically possible? Sure.
But why would you torture yourself?
Type-safe prompts. Instant playground testing. Multi-language support.
promptfiddle.com
7
486
Feb 17
This is what we're building. BAML — the first language designed for AI-native software. promptfiddle.com
Feb 16

I think it must be a very interesting time to be in programming languages and formal methods because LLMs change the whole constraints landscape of software completely. Hints of this can already be seen, e.g. in the rising momentum behind porting C to Rust or the growing interest in upgrading legacy code bases in COBOL or etc. In particular, LLMs are *especially* good at translation compared to de-novo generation because 1) the original code base acts as a kind of highly detailed prompt, and 2) as a reference to write concrete tests with respect to. That said, even Rust is nowhere near optimal for LLMs as a target language. What kind of language is optimal? What concessions (if any) are still carved out for humans? Incredibly interesting new questions and opportunities. It feels likely that we'll end up re-writing large fractions of all software ever written many times over.
2
11
895
Feb 16
Feb 10
Seattle, this one's for you. 🫶 We've added @lenadroid to our already awesome speaker lineup.
Come spend an evening with us, hear from Lena and @radgendervibes from Zed, @vaibcode from @boundaryML, and @matsonj from @motherduck go on a much needed rant on what AI gets wrong (and sometimes gets right).
Link to rsvp in the thread. 🧵
1
290
Boundary retweeted

28 Dec 2025
How to bundle BAML by @boundaryML Nitro for @vercel deployment

ALT Screenshot of https://laurentcazanove.com/blog/baml-nitro-vercel-deployment
2
2
4
1,298
17 Dec 2025
In the next version of BAML (0.215.0), you will be able to optimize your prompts using GEPA
`uv run baml optimize`.
Thanks to @imalsogreg
10
1
18
961
Boundary retweeted

25 Nov 2025
Cool tutorial with end-to-end structured extraction for Patient intake forms using #BAML @boundaryML @cocoindex_io. Production-grade, Fully #OpenSource.
get started:
🔗 cocoindex.io/blogs/extractio…
repo:
🌟 github.com/cocoindex-io/coco…
> BAML defines a typed Patient schema role-correct PDF prompt (critical for OpenAI providers).
> CocoIndex orchestrates file input, transformation, and incremental indexing.
📄 What the tutorial covers
• Defining a FHIR-inspired patient schema in BAML
• Configuring Gemini 2.5 Flash for structured extraction
• Generating the Python client with baml-cli
• Writing a CocoIndex flow that ingests PDFs, calls the BAML function, and exports to Postgres
• Leveraging incremental processing caching for real-world scale
• Debugging lineage using the CocoInsight UI (now in free beta)
#LLM #KnowledgeGraph #RAG #GraphDatabase #GraphAI #OpenAI #AIInfra #DevTools #DataPipelines #RealtimeAI #VectorDB #LLMApplications #GenerativeAI #AIEngineering #Python #AI4Docs #SemanticSearch #Rust #cplusplus

1
7
23
4,633