
ceo @skycatch, builder of bits and atoms, us navy vet 🇺🇸
Joined August 2007
- Tweets 29,918
- Following 4,239
- Followers 10,324
- Likes 14,571
2,203 Photos and videos













Pinned Tweet

10 Jul 2025
We’re heading toward a world where autonomous systems will be everywhere. They will move people, goods, sensors, and even decisions without asking for human input.
Today, we only see the early signals. A few drones in the air. A handful of self-driving trucks. Some real-time sensing of key infrastructure. But the truth is we still see very little. At best, we capture five percent of our own terrain in real time. Satellites give us fragments. Drones give us glimpses. Most of the world, most of the time, is still invisible.
That is going to change.
At some point, every square inch of land and ocean will be monitored continuously. Machines will scan, interpret, and update the state of the physical world with no gaps and no delay. That data will be available not just to us, but to whoever gets there first.
The same shift is coming to logistics. Right now, we move things within the limits of what humans can manage. Flights are scheduled. Trucks are driven. Operators are assigned. But once autonomy becomes the default, the scale of movement changes. We will see a four or five-fold increase in volume. Goods will be transferred instantly. People will be relocated without pause. Entire networks will function without waiting for human authorization.
This introduces a different kind of power structure.
The question becomes who owns the pathways. Who sees what. Who can act first. This has nothing to do with ideology and everything to do with speed, saturation, and reach. The systems that dominate communication, transportation, and sensing will also shape which forms of government persist. Those with the clearest picture and the fastest ability to respond will set the conditions the rest of the world has to live within.
We like to believe that the future will preserve the values we care about. But that depends on who gets there first. And what they decide to build.
I’m obviously biased. As a U.S. Navy veteran, my bet is on the United States. Not just to build faster systems, but to build ones that reflect something deeper… our values, our way of life, and the belief that power should still answer to people.
That only happens if we pay attention. If we stay in the race. If we lead.
🇺🇸
cc @USAvionix @pmarca @Benioff @garrytan @rauchg @elonmusk @nikitabier @naval
28
36
323
700,125


Christian Sanz retweeted

Jun 1
Wow, Claude 4.8 finally nailed Three.js camera filming the ocean floor at the beach correctly.
14
8
133
5,039
Christian Sanz retweeted

May 30
Here's a list of the upcoming features in Three.js Water Pro v3. It's a big update!
✅ Improved Wave Realism — Updated spectrum produces more organic wave patterns.
✅Improve Lighting Model — completely revamped lighting model that produces realistic color changes in shallows areas and allows you to see through water surface
✅Persistent Wave-Crest Foam — Foam lingers and rolls off breaking waves.
✅Multiplayer-Ready Determinism — fixed-step simulation and syncing between clients
✅Sea Spray — attach emitters to boats, rocks, etc. to generate spray as water hits the surface
✅Rain — wind-driven streaks plus water-surface ripples.
✅HDRI Environment Maps — procedural sky has been replaced by realistic HDRI maps
✅Boat Wake — V-shaped wakes with automatic foam on breaking crests,
and much more!
49
79
1,130
60,584
Christian Sanz retweeted

May 17
Underrated life advice: Make yourself easy to root for. Be kind. Be reliable. Celebrate other people’s wins. Work hard without complaining. Carry good energy into rooms. You'll be shocked by how many doors open for you by making life better for others.
172
3,612
23,566
503,805
Christian Sanz retweeted

Apr 27
Portless killed :3000
Dev servers got stable names like myapp.localhost
Agents could use worktrees in parallel without stepping on each other
Now it's easier than ever in v0.11
Just run: portless
Zero config. Zero args. Zero code changes.

107
191
3,463
513,155
Christian Sanz retweeted

Apr 25
An MIT professor taught the same math course for 62 years, and the day he retired, students from every country on earth showed up online to watch him give his final lecture.
I opened the playlist at 2am and ended up watching three of them back to back.
His name is Gilbert Strang. The course is MIT 18.06 Linear Algebra.
Every machine learning engineer, every data scientist, every quant, every self-taught programmer who actually understands how AI works learned the math from this one man. Most of them never set foot on MIT's campus. They just opened a free playlist on YouTube and let him teach.
Here's the story almost nobody tells you.
Strang joined the MIT math faculty in 1962. He retired in 2023. That is 61 years of standing at the same chalkboard teaching the same subject to 18-year-olds.
The interesting part is what he did when MIT launched OpenCourseWare in 2002. Most professors were skeptical. They worried that putting their lectures online would make their classrooms irrelevant. Strang did not hesitate. He said his life's mission was to open mathematics to students everywhere. He filmed every lecture and gave it away.
The decision quietly changed how the world learns math.
For decades linear algebra was taught the wrong way. Professors started with abstract vector spaces and proofs about field axioms. Students drowned in the abstraction. Most never recovered. They walked out believing they were bad at math when they had simply been taught in an order that nobody's brain is built to absorb.
Strang inverted the entire curriculum.
He started with matrix multiplication. Something you can write down on paper. Something you can compute by hand. Something you can see. Then he showed his students that everything else in linear algebra eigenvectors, singular value decomposition, orthogonality, the four fundamental subspaces was just a different lens for understanding what the matrix was actually doing under the hood.
His rule was strict. If a student could not explain a concept using a concrete 3 by 3 example, that student did not actually understand the concept yet. The abstraction was supposed to come last, not first. The intuition was the foundation. The proofs were just confirmation that the intuition was correct.
The second thing Strang changed was the classroom itself. He said please and thank you to his students. Every single lecture. He paused mid-derivation to ask "am I OK?" to check if anyone was lost. He never used the word "obviously" or "trivially" because he knew exactly what those words do to a student who is one step behind. He treated 19-year-olds learning math for the first time the way he treated his own colleagues. With patience. With respect. With the assumption that they belonged in the room.
For 62 years.
The result is something that has never happened in the history of education. A single math professor became the default teacher of his subject for the entire planet.
Universities in India, China, Brazil, Nigeria, every country with a computer science department, started telling their own students to just watch Strang's lectures. The University of Illinois revised its linear algebra course to do almost no in-person lecturing. The reason was honest. The professor said they could not compete with the videos.
His final lecture was in May 2023.
The auditorium was packed with students who had never met him before. He walked to the chalkboard, taught for an hour, and at the end the entire room stood and applauded. He looked confused for a moment, like he genuinely did not understand why they were cheering. Then he smiled and waved them off and walked out.
His written comment under the YouTube video of that final lecture was four sentences long. He said teaching had been a wonderful life. He said he was grateful to everyone who saw the importance of linear algebra. He said the movement of teaching it well would continue because it was right.
That was it. No book promotion. No farewell speech. No legacy management.
The man whose teaching is the foundation of modern AI just thanked the audience and went home.
20 million views. Zero ego. The entire engine of the AI revolution sits on top of math that millions of people learned for free from one quiet professor in Cambridge.
The course is still on MIT OpenCourseWare. Every lecture, every problem set, every exam, every solution. Free.
The most important math course of the 21st century is sitting one click away from you. Most people will never open it.

546
8,271
32,072
2,400,230
Christian Sanz retweeted

Apr 16
MOST PEOPLE:
6-12 months
escalate → discuss → roadmap
“let’s circle back”
HEAT SEEKER:
1-2 days
isolate → fix → ship
“done”

10
33
432
91,135
Christian Sanz retweeted
Apr 15
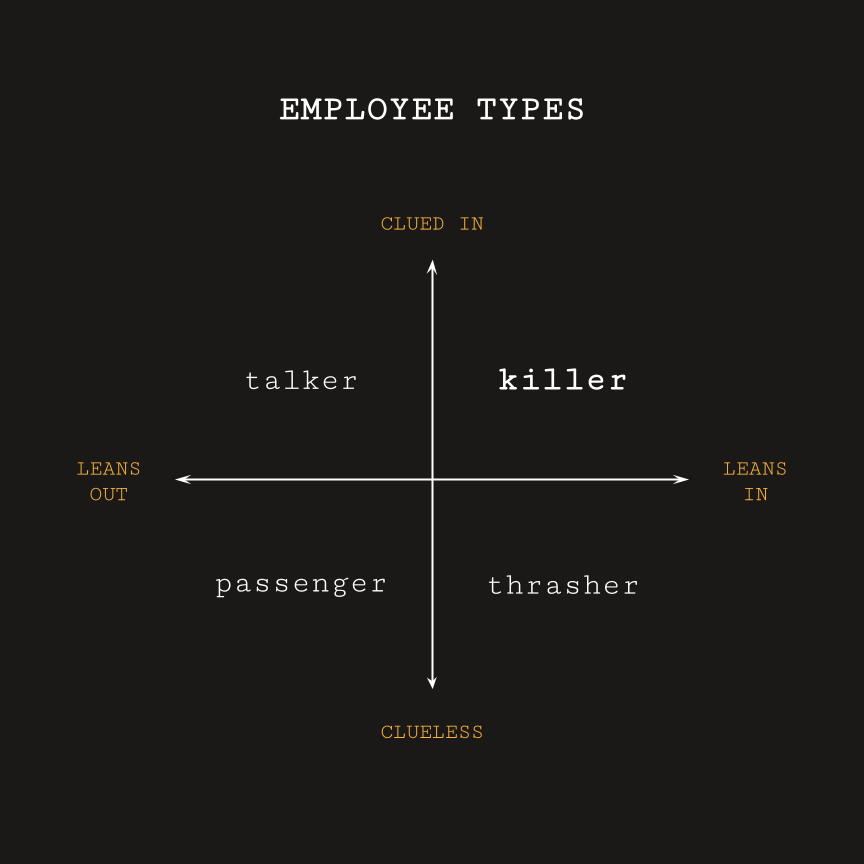
Get rid of passengers and talkers. Reguide thrashers. Invest in killers.
31
82
1,128
235,415
Christian Sanz retweeted
Apr 14
58
117
1,306
715,481

Christian Sanz retweeted

19 Nov 2025
🧵Announcing Segment Anything 3! SAM 3 extends SAM 2 with open vocabulary text and exemplar prompts, enabling it to detect, segment, and track all instances of a target category in images/videos. We're releasing code, a checkpoint, an eval benchmark, & demo playground. SAM 3 will be coming soon to features in Edits, Vibes, & FB Marketplace! Deep dive below 👇
19 Nov 2025

Meet SAM 3, a unified model that enables detection, segmentation, and tracking of objects across images and videos. SAM 3 introduces some of our most highly requested features like text and exemplar prompts to segment all objects of a target category.
Learnings from SAM 3 will help power new features in Instagram Edits and Vibes, bringing advanced segmentation capabilities directly to creators.
🔗 Learn more: go.meta.me/591040
7
15
148
29,520



Christian Sanz retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,119
2,821
26,771
7,140,496
Christian Sanz retweeted
Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,887
7,228
59,759
21,352,084
Christian Sanz retweeted

Mar 31
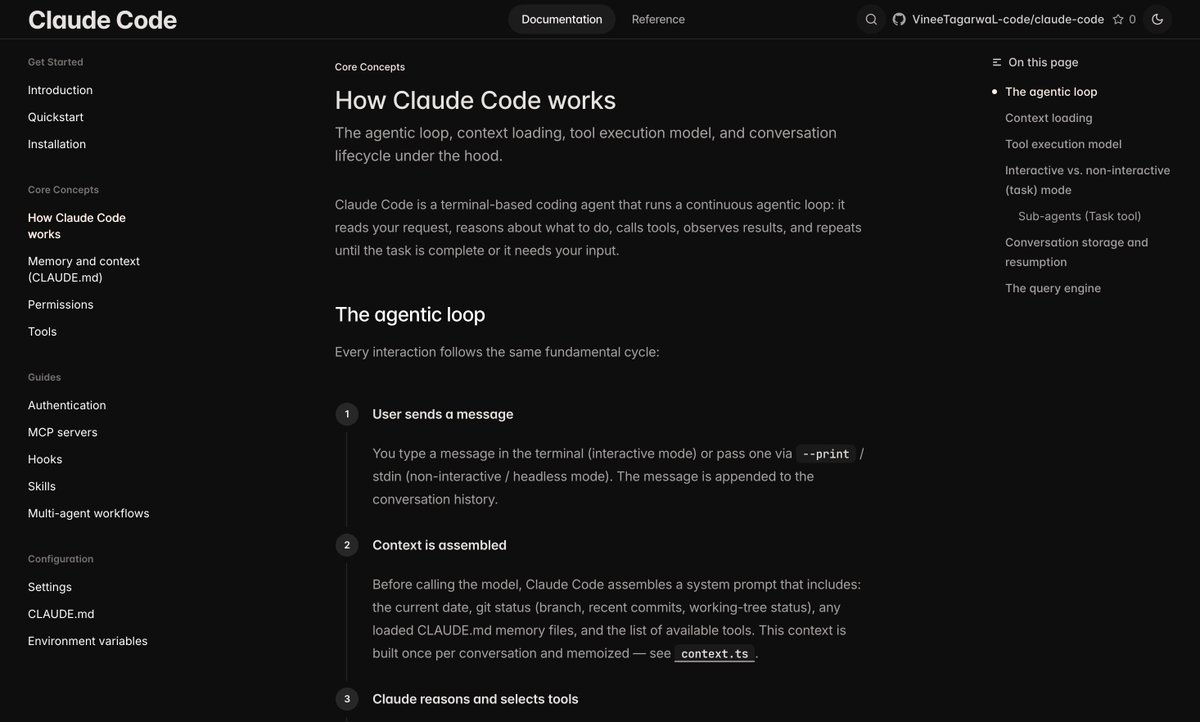
I created documentation over Claude Code's Codebase, which explains
- Its pipeline
- How it works
- How it handles Context
- How it handles Memory
& More
Read it here - mintlify.com/VineeTagarwaL-c…
Mar 31

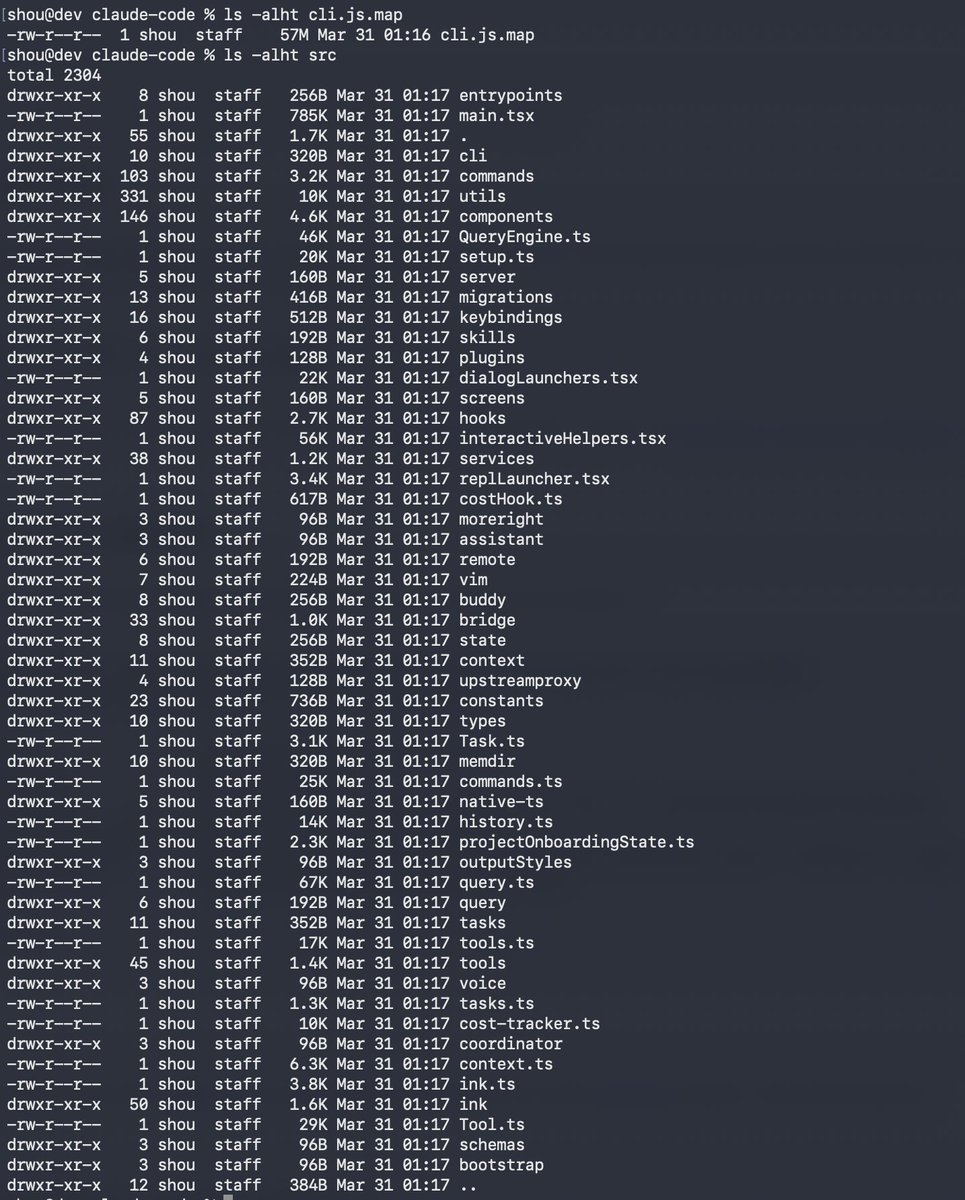
Claude code source code has been leaked via a map file in their npm registry!
Code: pub-aea8527898604c1bbb12468b…
153
644
5,914
1,227,562
Christian Sanz retweeted

Mar 31
Claude code source code has been leaked via a map file in their npm registry!
Code: pub-aea8527898604c1bbb12468b…
3,329
7,538
48,503
35,673,213

🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages.
The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise.
This is textbook supply chain installer malware. axios has 100M weekly downloads. Every npm install pulling the latest version is potentially compromised right now.
Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that:
• Deobfuscates embedded payloads and operational strings at runtime
• Dynamically loads fs, os, and execSync to evade static analysis
• Executes decoded shell commands
• Stages and copies payload files into OS temp and Windows ProgramData directories
• Deletes and renames artifacts post-execution to destroy forensic evidence
If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.
541
4,026
16,168
12,403,785
Christian Sanz retweeted

Mar 27
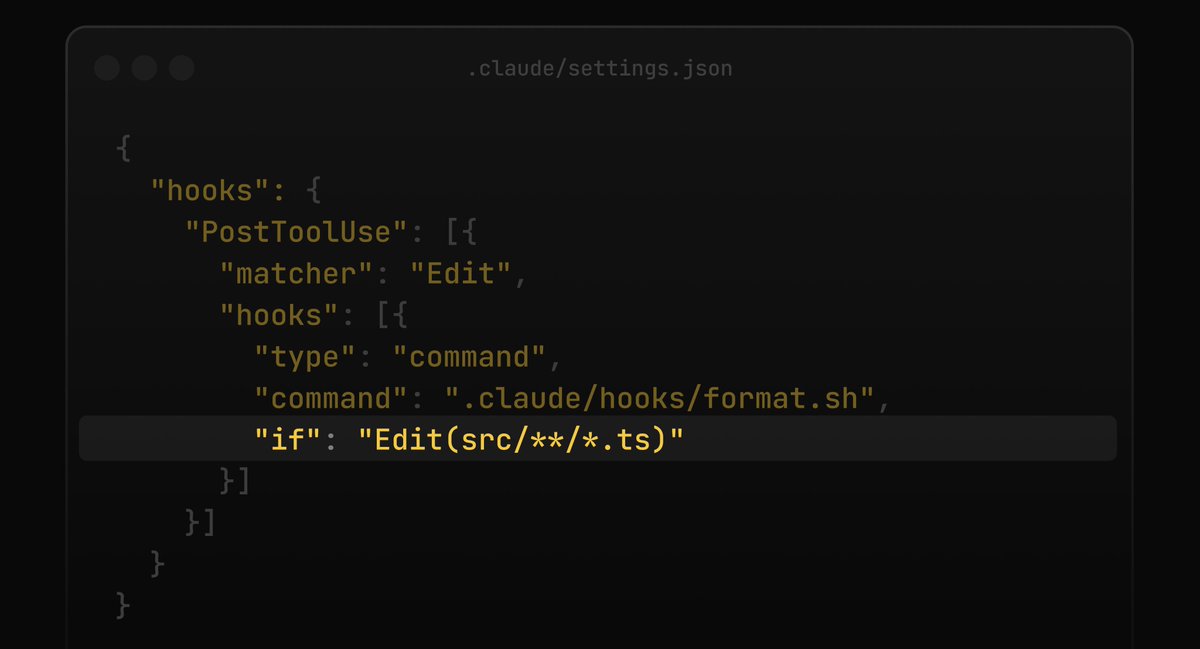
Claude Code now supports an `if` field in hooks
It uses permission rule syntax to filter when a hook runs, which is useful when you want a hook on some bash commands but not every single one!
77
133
1,308
197,890

Alec Radford is legend
Mar 28

Every LLM from any lab today traces back to this guy, who was the only person at OpenAI pushing for pretraining transformer language models.
He built GPT-1. After that did others see the potential.
He invented it, and almost none of the so called AI experts even know his name.

14
30
502
43,601