
Joined July 2022
- Tweets 1,472
- Following 801
- Followers 1,054
- Likes 14,370
361 Photos and videos











Sourya Kakarla retweeted
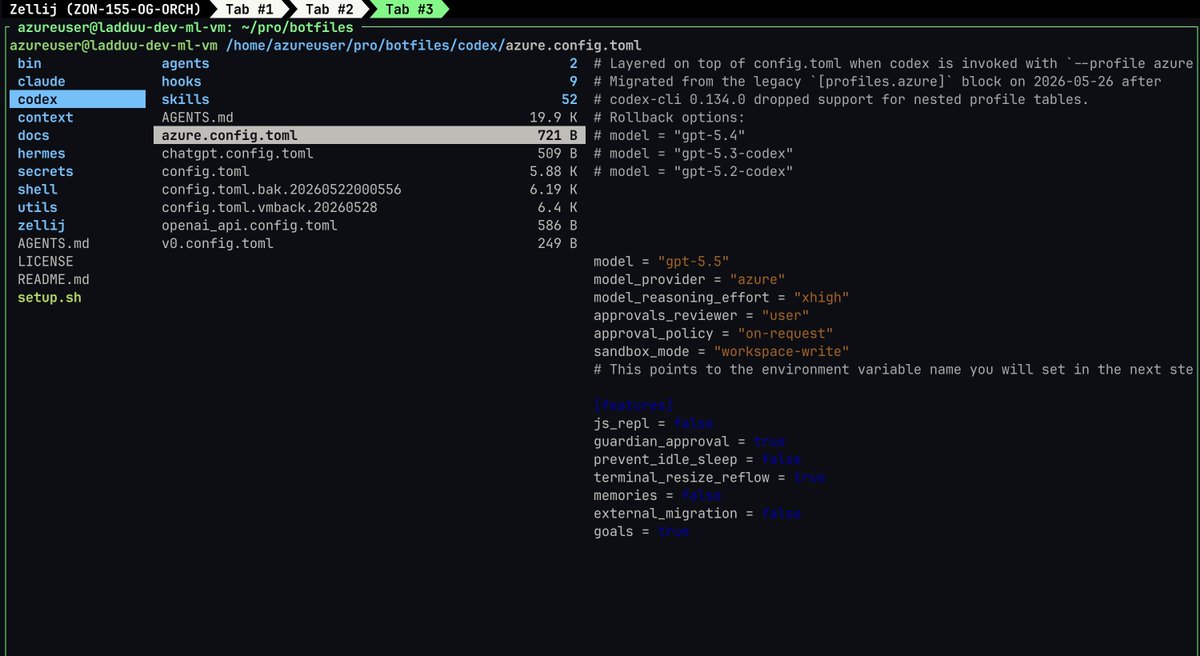
i have 3 codex profiles in my config
i guess i am relatively high on the profile count
1
5
511
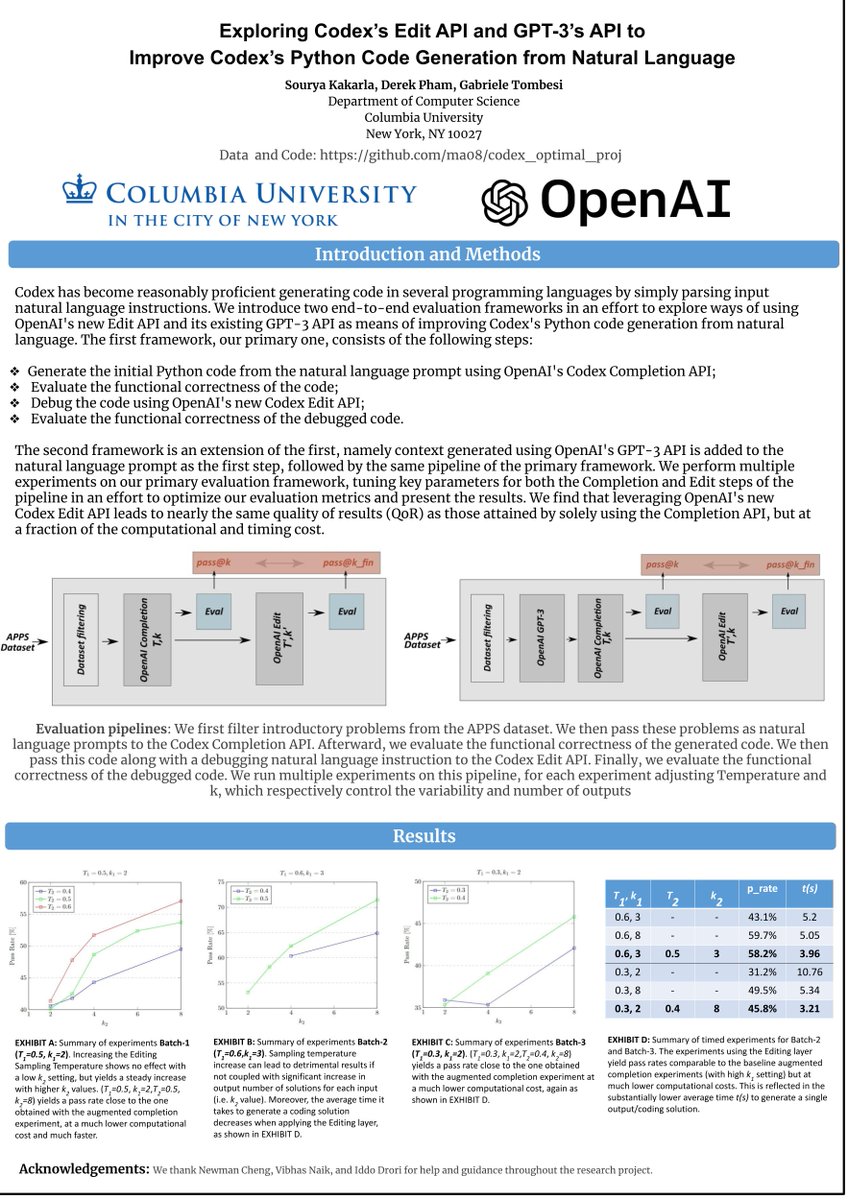
fun fact: we worked on analyzing the "codex edit api" vs. "gpt-3 api" in mar 2022 (8 months before chatgpt was released in nov 2022)
github.com/ma08/codex_optima…
thanks to the openai playground/api access we got for deep learning research @columbia


6
251

Jun 14
When businesses use a tightly integrated, single-vendor AI stack, they surrender their cognitive architecture. Your private evals and your tool-calling harness are your core IP.
Wrote about this "Autonomy Paradox" couple of months ago. Now validated by @satyanadella :)
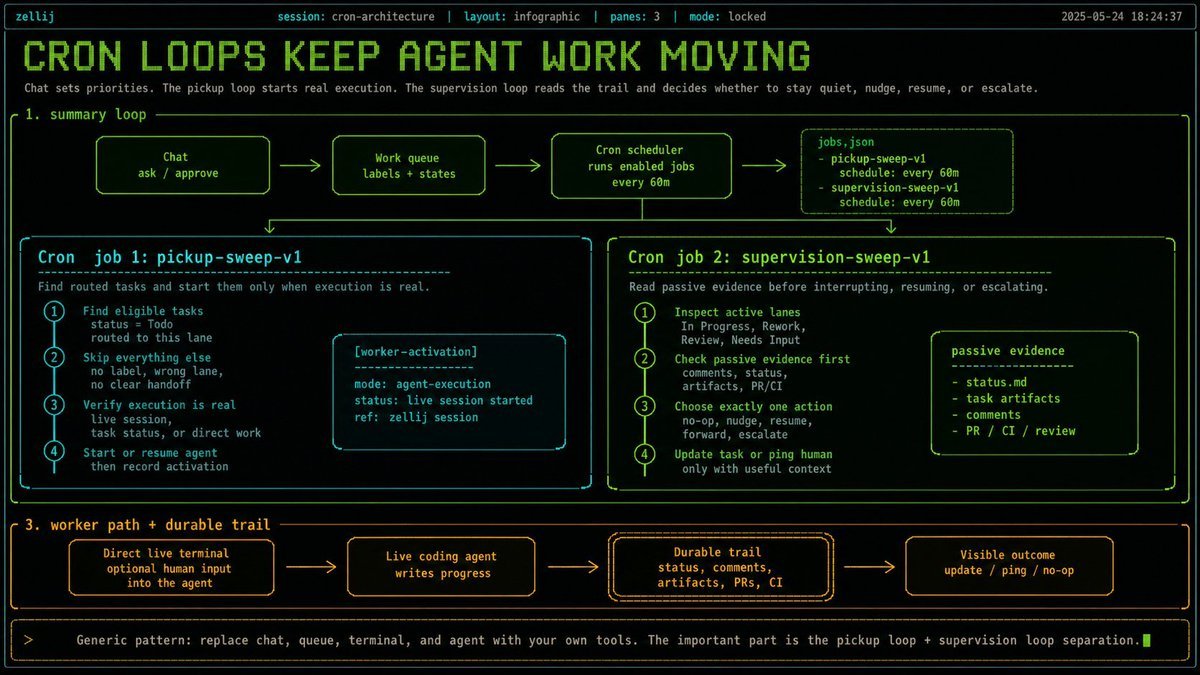
Beyond just theorizing about this, I built a "Botfiles" setup for myself as a solution to make my coding agent setup portable across models/agents/machines.
Links in 🧵

3
3
9
1,180

Jun 13
building a guardrails layer that uses semantic context for classification and not static/deterministic rule/state based checks can be such an unimaginably obtuse problem to solve, especially when serving a general purpose model/api/agent.
a simple reason why all of this is happening: building a legit guardrails layer that's context based and not metadata based (organization, user id, etc.) still remains unsolved even at the frontier labs. ofc it's very hard to admit that when you are using safety as your brand's religion.
what makes me say this: i've designed and built orchestration and eval stacks that were deployed to production with over 40k enterprise users handling transactions worth tens of millions of dollars.
building a foolproof guardrails layer that's not state based but relies on an LLM-as-a-judge style approach was the most challenging problem i dealt with in my agent deployment experience. everyone who worked on it used to curse the moment they were assigned a guardrails ticket. we eventually just gave up on it and oriented our architecture around the impossibility of solving semantic guardrails.
Jun 13

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
1
1
6
271
Jun 8
designing these loops is just the new programming interface fr
i've been poasting about the importance of loop design and verification inside to self manage task coherence long enough for now
curate the loop thoughtfully and yeet that value out of em matrix multiplications
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
4
110
Sourya Kakarla retweeted

verification being easier than generation really makes some interesting dynamics
3
2
27
2,671
Sourya Kakarla retweeted
May 26
this is genuinely a load-bearing smoke test
1
1
36
27,961
May 19
surreal to see @arsenal win the league!!
is this the real life?!!!
back in 2012, i picked github.com/ma08 ("mikel arteta 08") as my github handle as ode to @m8arteta when he was a player
crazy to see him break the curse as the manager 🙇♀️
wenger's done it again 🙇♀️🙇♀️🙇♀️

2
290
May 18
/goal 👇
May 18

The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
5
143
May 17
human 𝚒̶𝚗̶ ̶𝚝̶𝚑̶𝚎̶ ̶𝚕̶𝚘̶𝚘̶𝚙̶ as a tool call
any sufficiently advanced agent orchestration problem converges to human attention use optimization

currently, we use software.
very soon, software will use us.
this is now inevitable.
5
105
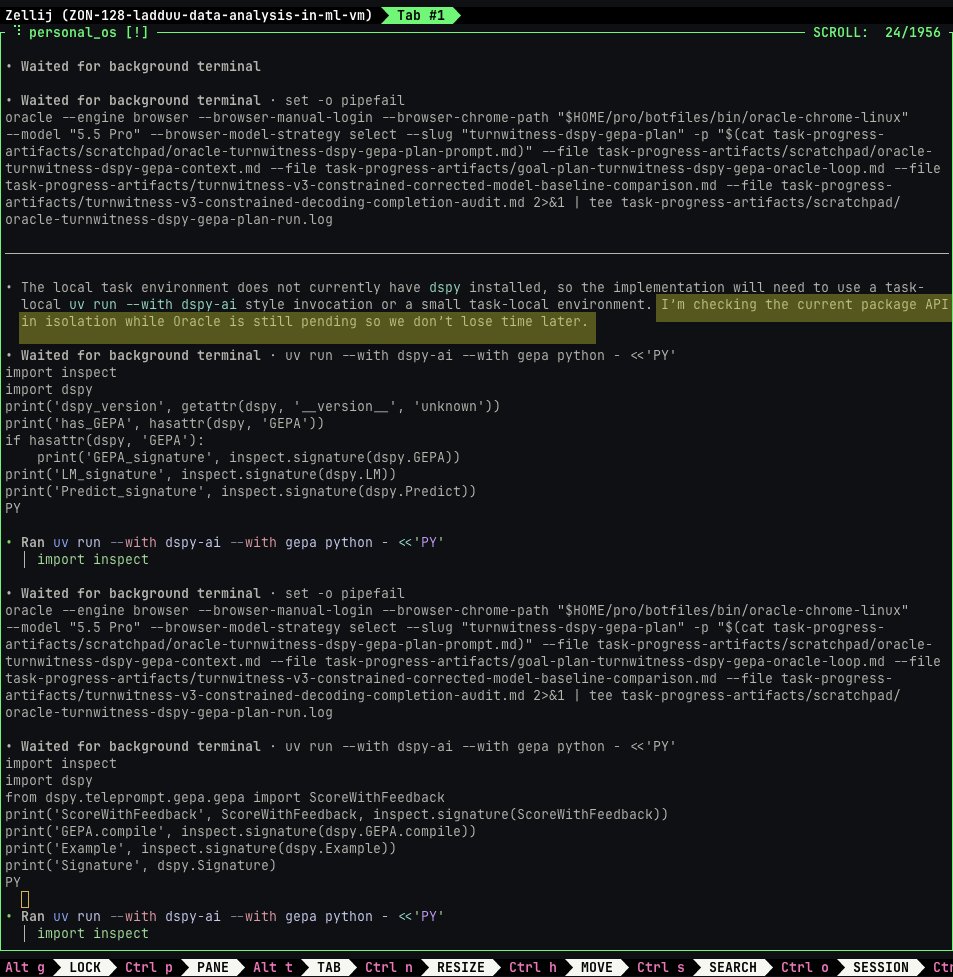
May 13
codex just pulled a pro move to avoid wasting time
by investigating the environment's readiness (to use DSPy and GEPA) in parallel with waiting on the oracle result from gpt-5.5-pro
(as i asked it to consult gpt-5.5-pro via oracle before finalizing the implementation plan)
5
214
May 13
"It's a dead hand against a living will"
added this to my arsenal of badass quotes to use in hypothetical future scenarios
(started reading the second book in the Foundation series)
Apr 12
Foundation and Empire by Isasc Asimov:
Finished the first book in the Foundation series a few weeks back. The religiion/science/trade angles gripped me enough in the first book to make me get the second one.
Interestingly, when writing an article yesterday, I was able to remember something from the first book that served as a great metaphor. Will post the article today.
Sharing the draft/resarch here as I don't have enough reach anyway that I need to worry about risk of spoiling it :')

1
2
107
May 13
the first book in the foundation series inspired this article's cover pic and a section inside it
x.com/curious_queue/status/2…
1
62
May 12
finally finished reading the Proto book.
it definitely helped me become more aware of how
- vast and complex history is
- interconnected indo-european family (and world in general) is wrt genetics, language, myths, art, culture, religion
🧵sharing some snippets from the book


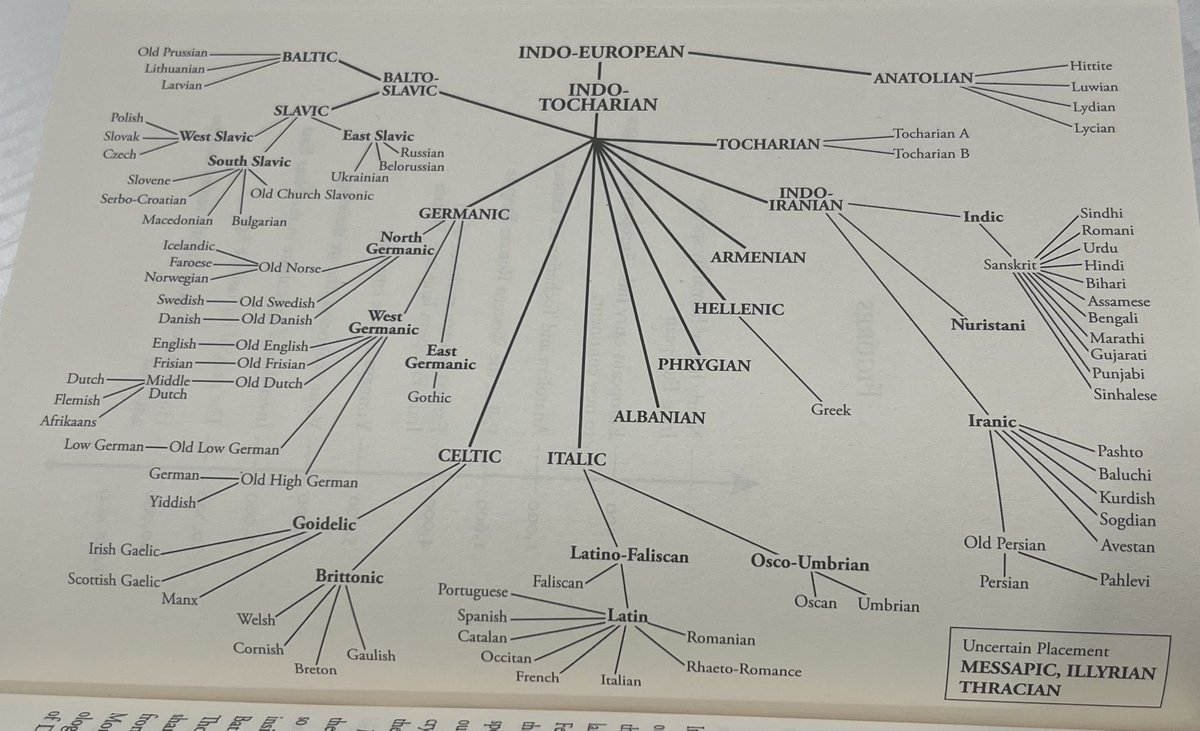
Apr 12
Proto: How One Ancient Language Went Global by @lfspinney:
I'm obsessed with etymology. I'm in the middle of finally publishing my thesis manuscript on an Indo-European computational linguistics project. This felt like a good book to read to give me broad historical context.
1
3
145
May 12
Apr 18
TIL that
- shaman (English) and the śramaṇa (Sanskrit) are related: en.wiktionary.org/wiki/shama…
- mead (English) and mádhu (Sanskrit) are related: en.wiktionary.org/wiki/mead
Feels obvious in hindsight lol
Linguistics can often be a treasure trove of socio-cultural connections

1
58
May 12
fin (for now). i guess language is the OG platform for human mental software to run collaboratively.
turns out the study of language history can become the study of everything and has a strong political flavour sometimes (feels obvious in hindsight).
i'm just vibepoasting ofc. this isn't meant to be a formal academic take on things. happy to discuss/debate in the pursuit of understanding .
32