


Daert retweeted

29 Mar 2024
Just dropped a new episode of the #dp100 #azureml course in the @daertml academy YouTube channel... We are training our first model in the cloud! Enjoy! 🚀
youtube.com/watch?v=8ITc4go7…
1
3
4
1,244

Ya disponible para la comunidad Hispana: Tutorial de entrenamiento de modelos LLaMA 2:
youtube.com/watch?v=TfkkIRoT…
Like, sub, y click en la campanita! 😉
2
4
1,793
The #Daert #Academy is LIVE 🔴 in @YouTube !
Check our first video on how to train a #LLaMA2 model with a single 3090 GPU!
Any suggestion/improvement/comment/question/request is well appreciated! Like, Sub and hit the Bell button!!
youtube.com/watch?v=0Kc2g9Gm…
2
2
467

⚡ txtai 6.1 is out ⚡
This release adds metadata support for client-server databases (Postgres, MariaDB/MySQL, MSSQL) and custom scoring implementations.
github.com/neuml/txtai
4
11
649
Daert retweeted

26 Sep 2023
I've generated 70M tokens of extremely high quality synthetic textbooks - huggingface.co/datasets/vikp… , using retrieval and gpt-3.5.
Seriously, the quality is 💯.
I'm generating 1B tokens, but will use llama for $$ reasons. Please DM if you can sponsor compute or credits.
7
49
266
47,263
Daert retweeted

25 Sep 2023
0.1.0 is out - huggingface-vscode is dead, long live llm-vscode! 👑
llm-vscode is an open source extension integrating LLMs inside your favorite code editor with the goal of improving your efficiency and productivity.
🦀 It is now powered by llm-ls, our Rust language server.

10
93
611
237,914
Daert retweeted

21 Sep 2023
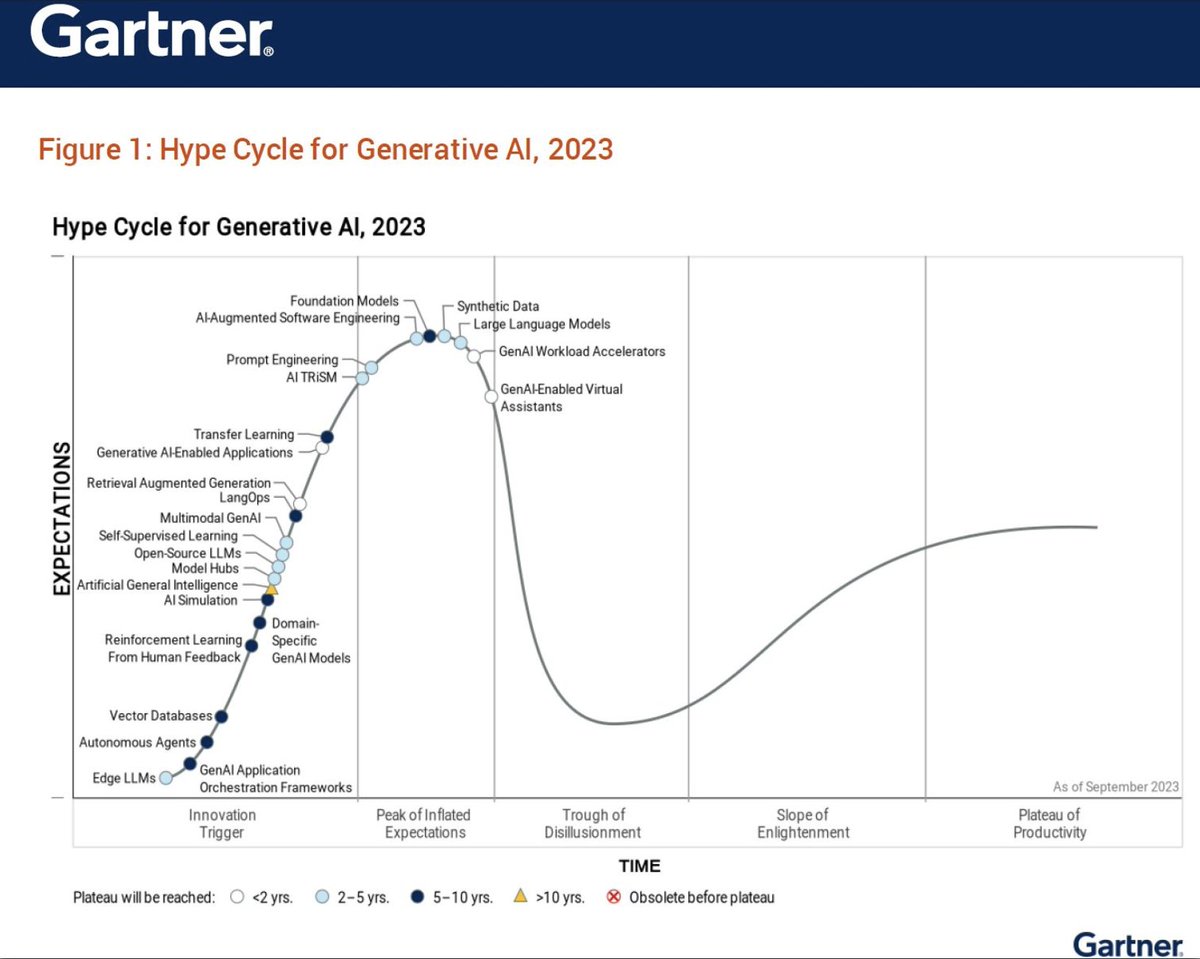
Gartner has just published one of their famous Hype Cycle curves for 2023, specialized to Generative AI!
The curve is encouragingly optimistic on Vector Databases, predicting we still have 5-10 years to hit the infamous Peak of Inflated Expectations!
Here are 5 reasons why I also think Vector Databases are still an upcoming technology and no where near the peak: (1) RAG "GPT-5", (2) RAG Easy Fine-Tuning, (3) Easy Data Ingestion, (4) Generative Feedback Loops, and (5) Self-Driving DBs
1. RAG "GPT-5"
As a TLDR, the next-generation "GPT-5" will likely be a long context LLM. There is a huge opportunity to pre-train these kind of LLMs with more naturally long context data such as podcast transcriptions or code. It is also quite likely that these models have some retrieval-aware tuning as well to prevent hallucination to retrieved context.
Many people currently come to Vector DBs with a classic kind of "I have a 20-30 page PDF that I can't fit to ChatGPT". This is missing the point of the Zero-Shot LLM RAG in my opinion, don't just give the LLM your document -- give it the background knowledge as well! This is why I am a huge fan of the work in LlamaIndex and LangChain to pioneer query engineers across multiple search indexes.
2. RAG Easy Fine-Tuning
The tooling for fine-tuning is getting really strong, quick hat tip to HuggingFace, MosaicML, and Weights & Biases.
Imagine you are a lawyer. In addition to having the relevant laws you need to solve a case, you also need to have the skill of making the case. Making the case could entail surface level "style" (the current most common argument for this) or more complex compositional generalization that may be only possible to represent in high-dimensional data structures with non-linear interaction effects.
RAG is a fundamental modeling architecture that is perfectly amenable to fine-tuning. RAG generally adds (1) interpretability (you can see the docs that influenced the prediction, not 100% linked ofc), (2) parameter efficiency (by decomposing retriever-reader you get away with cheaper readers e.g. ATLAS), (3) continual updating (keeping the data as fresh in a parametric only LLM as a Kafka stream or what have you is unlikely - the unlearning stuff is cool though).
RAG Fine-Tuning also has a massive opportunity to create better search by training the search models end-to-end with the gradients from the reader. RLHF back to the embedding models (maybe rankers can be trained like this as well).
3. Easy Data Ingestion
Parsing PDFs into both unstructured text and structured layout information will ofc dramatically facilitate how many people can use Vector DBs. The tooling here is also getting incredibly strong thanks to Unstructured, LlamaIndex, and LangChain. Connecting this with your Twitter APIs, web scrapers, etc. through scheduled Cron Jobs will be amazing.
4. Generative Feedback Loops
RAG innovates on the output from DBs, Generative Feedback Loops (where we save generated or transformed data from an LLM back into the database), will innovate on the fundamental - What's in the database?
This will really get us to the peak in my opinion because it will also evangelize everyone having 100M vectors on their laptops (if managing their own personal DB) or say this kind of thing in a knowledge management platform like Notion / Confluence / GitHub / HuggingFace. Scale will really unlock the value of Vector DBs, not that I really agree with the Numpy is all you need argument anyways that overlooks the CRUD compatibility, cloud scaling, symbolic properties, search features like hybrid / filtering, etc. TLDR - AI will take your documents you like, pictures, movies, songs --- and create more of it! You will then need databases to navigate this explosion of content!
For this reason I think it is also important to think of Vector DBs as traditional DBs Search Engines Recommendation Systems -- because Recommendation Systems have a bit of nuance vs. Search only with user representation and more use of symbolic re-rankers like XGBoost -- also potentially an explore-exploit RL component to the recommender (kudos to whoever builds that).
5. Self-Driving DBs
Gorilla is an exciting research project that translates natural language commands to API syntax. Text-to-SQL is making a ton of progress! I think this will not only generalize to Text-to-SQL, but also the structuring of data with e.g. properties, tables, key join -- learned by monitoring and maintaining the system. I also think it's possible to use LLMs to optimize lower level physical storage configurations.
Between RAG Next-Gen Zero-Shot LLMs, RAG Easy Fine-Tuning, Easy Data Ingestion, Generative Feedback Loops, and Self-Driving DBs -- I think Gartner is right and we still have a long way to go to the peak of Vector Databases!
Thanks for reading! Check out Weaviate! 😎👍
17
90
355
101,823
We are glad to announce the addition of models that can implement #qlearning from a pseudocode description to solve #gym environments from @OpenAI . We provide code to solve FrozenLake:
github.com/DaertML/daert-age…
@ThomasSimonini 👀
1
1
51
Daert retweeted
12 Sep 2023
At @daertml, we just quantized 🧮 the new models phi-1 and phi-1.5 from @Microsoft; this is possibly the tiniest 🔬 and best performing #LLM out there! And we made it even tinier using the #bitsandbytes lib! Check them out:
- huggingface.co/DaertML/phi-1…
- huggingface.co/DaertML/phi-1…
2
2
7
265
Daert retweeted
12 Sep 2023
Twitter freaks out with more than 1 link on the tweet, the 1.5B version:
- huggingface.co/DaertML/phi-1…
2
4
112



Evaluating the Ripple Effects of Knowledge Editing in Language Models
paper page: huggingface.co/papers/2307.1…
Modern language models capture a large body of factual knowledge. However, some facts can be incorrectly induced or become obsolete over time, resulting in factually incorrect generations. This has led to the development of various editing methods that allow updating facts encoded by the model. Evaluation of these methods has primarily focused on testing whether an individual fact has been successfully injected, and if similar predictions for other subjects have not changed. Here we argue that such evaluation is limited, since injecting one fact (e.g. ``Jack Depp is the son of Johnny Depp'') introduces a ``ripple effect'' in the form of additional facts that the model needs to update (e.g.``Jack Depp is the sibling of Lily-Rose Depp''). To address this issue, we propose a novel set of evaluation criteria that consider the implications of an edit on related facts. Using these criteria, we then construct , a diagnostic benchmark of 5K factual edits, capturing a variety of types of ripple effects. We evaluate prominent editing methods on , showing that current methods fail to introduce consistent changes in the model's knowledge. In addition, we find that a simple in-context editing baseline obtains the best scores on our benchmark, suggesting a promising research direction for model editing.

3
45
163
38,412
Daert retweeted

24 Jul 2023
POV: Someone entering /r/LocalLLaMA for the first time

5
17
245
22,255
Daert retweeted

24 Jul 2023
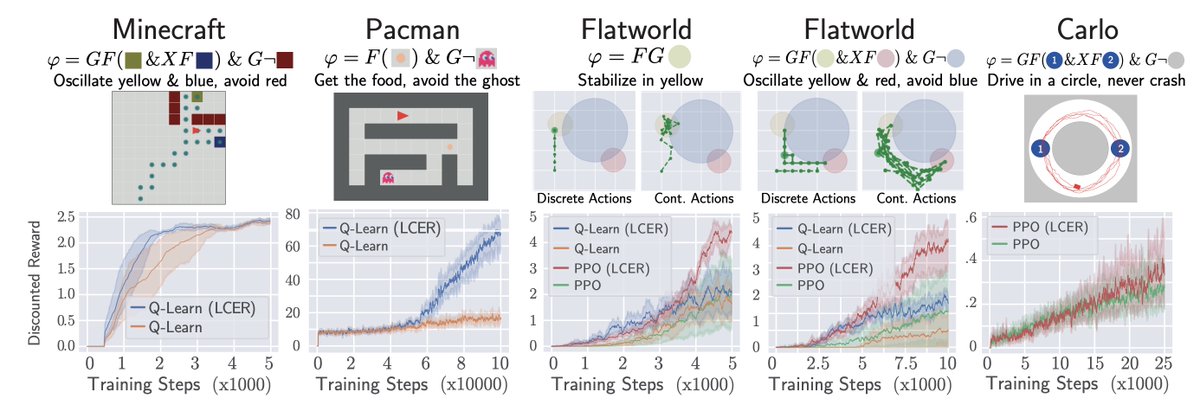
Linear Temporal Logic is a cool alternative to task specification in RL compared to reward engineering, but can be hard to optimize.
We introduce Temporal Logic Counterfactual Experience Replay (LCER).
arxiv.org/abs/2303.02135
Significant gains in learning speed. #ICML2023
4
18
73
14,869
Daert retweeted

24 Jul 2023
Hugging Face is thrilled to partner with @MLCommons on MedPerf, a medical benchmarking framework using federated evaluation. 🤗
Published @NatMachIntell, this open science initiative is a major step forward towards rigorous and privacy-preserving evaluation of medical AI models.

ALT MedPerf x Hugging Face
3
43
199
41,925
Daert retweeted

25 Jul 2023
A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis
Presents WebAgent, an LLM-driven agent that can complete the tasks on real websites following natural language instructions.
arxiv.org/abs/2307.12856

4
74
314
57,220