
AI, Local LLMs & Tech | Running AI models and agents at home | Problem solver. Don’t just doomscroll, build something! DMs open
Joined May 2016
- Tweets 759
- Following 356
- Followers 48
- Likes 1,049
17 Photos and videos









Pinned Tweet

Got into running AI models on my own hardware, testing, building agents, and sharing what actually works. Follow for daily insights, hardware tips, and no-BS tech talk ( an additional rant from time to time).
52
I told you it was getting interesting! This is why you need to run your LLMs locally, on your hardware. Think of it as an insurance policy as the competition heats up. Own your intelligence.

‼️🚨 BREAKING: Amazon researchers snitched to the US government about jailbreaking Fable 5 and Mythos 5, forcing Anthropic to immediately shut down worldwide access.
A security export control directive from Commerce Secretary Howard Lutnick enforced the action.
Anthropic is fighting the directive and calls it a misunderstanding.
This isn't the first clash. The Trump administration had already tried to get Anthropic to pause the release of its latest models before this directive landed.


10
This is getting interesting.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
4
Daniel B. - AI & Tech retweeted

Jun 12
Hermes Agent now has a production-grade WhatsApp Business Cloud integration: use it as a private WhatsApp bot for yourself or your team, or configure it for customer-facing support.
Connect an existing WhatsApp Business Cloud number or create one through Meta Business Manager, then run 'hermes whatsapp-cloud' to wire it into Hermes with guided setup, secure webhooks, media/voice support, read receipts, typing indicators, and interactive approval buttons.
93
171
2,117
170,141
V100 it is then. I really dislike the 40mm fans, anyone have a better cooling solution?
13
Daniel B. - AI & Tech retweeted
Jun 11
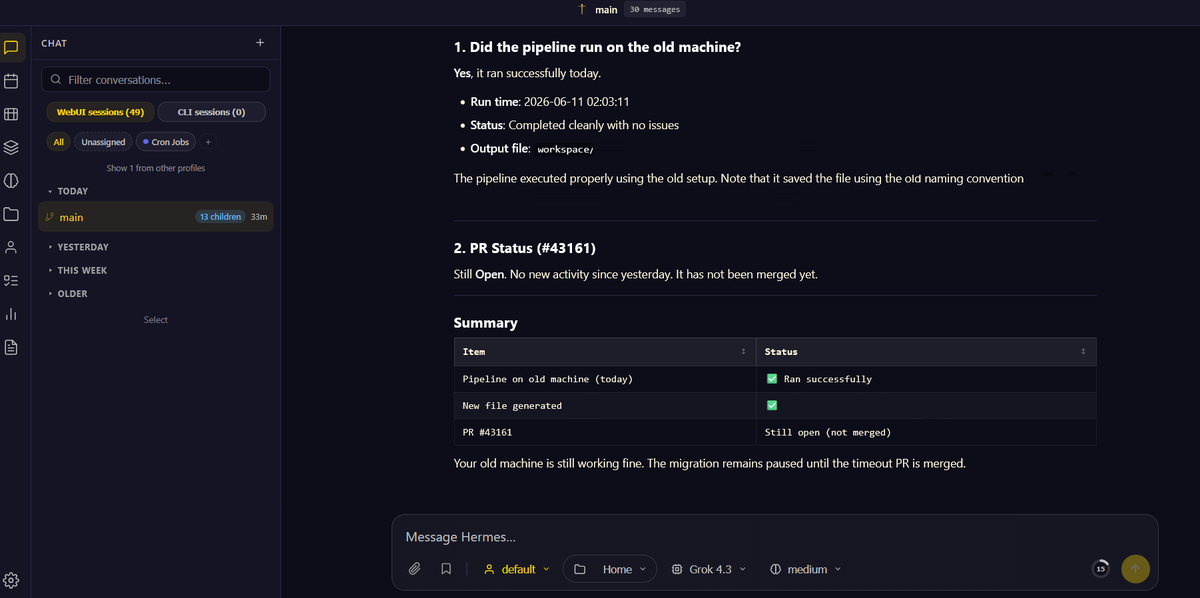
Hermes Agent now has Automation Blueprints, turning cron jobs into clickable, fillable, conversational workflows.
108
246
2,830
385,983
Hear me out! Looking at options to run local LLMs that don't involve paying with body parts, there are few options which fit.
Let's say you have 1k Euro to spend on the inference part alone and you want more than 24gb VRAM, you are really in for a world of trouble.
Your choices come down to:
- Nvidia Tesla V100 - 32gb VRAM for around 800 Euro.
- 2x AMD BC-250 - good little boards, but you have to tinker with them a lot, not for the faint of heart.
- MiniPC with Ryzen APUs (some 6000 series, 7000 series, 8000 series, HX370/470 just barely if not a bit over). Problem with these is that they are slow, maybe 20 - 25 TPS on a good day for the good ones (MoE).
- 2x Nvidia Tesla P40 - old and not something I can recommend, but you do get 48gb of VRAM for not a lot of money.
- AMD MI50/V620 - 32gb VRAM for good money, but you accept weak software support.
- not much else comes to mind.
Yes, you read the last option correctly. Don't tell me about the Intel B70, the market price is nowhere near MSRP (1350 Euro for example). 2x 3090s would blow passed 1k. The AMD R9700 is close to 2k.
Given what you just read, I would highly advise you to start thinking about getting some hardware sooner rather than later, because I have a feeling prices are going even higher and everybody's going to be scrambling to get hardware.
If you have any other ideas, I'm open to hear them, in the mean time Nvidia V100 it is then.
1
1
45


Daniel B. - AI & Tech retweeted

Jun 10
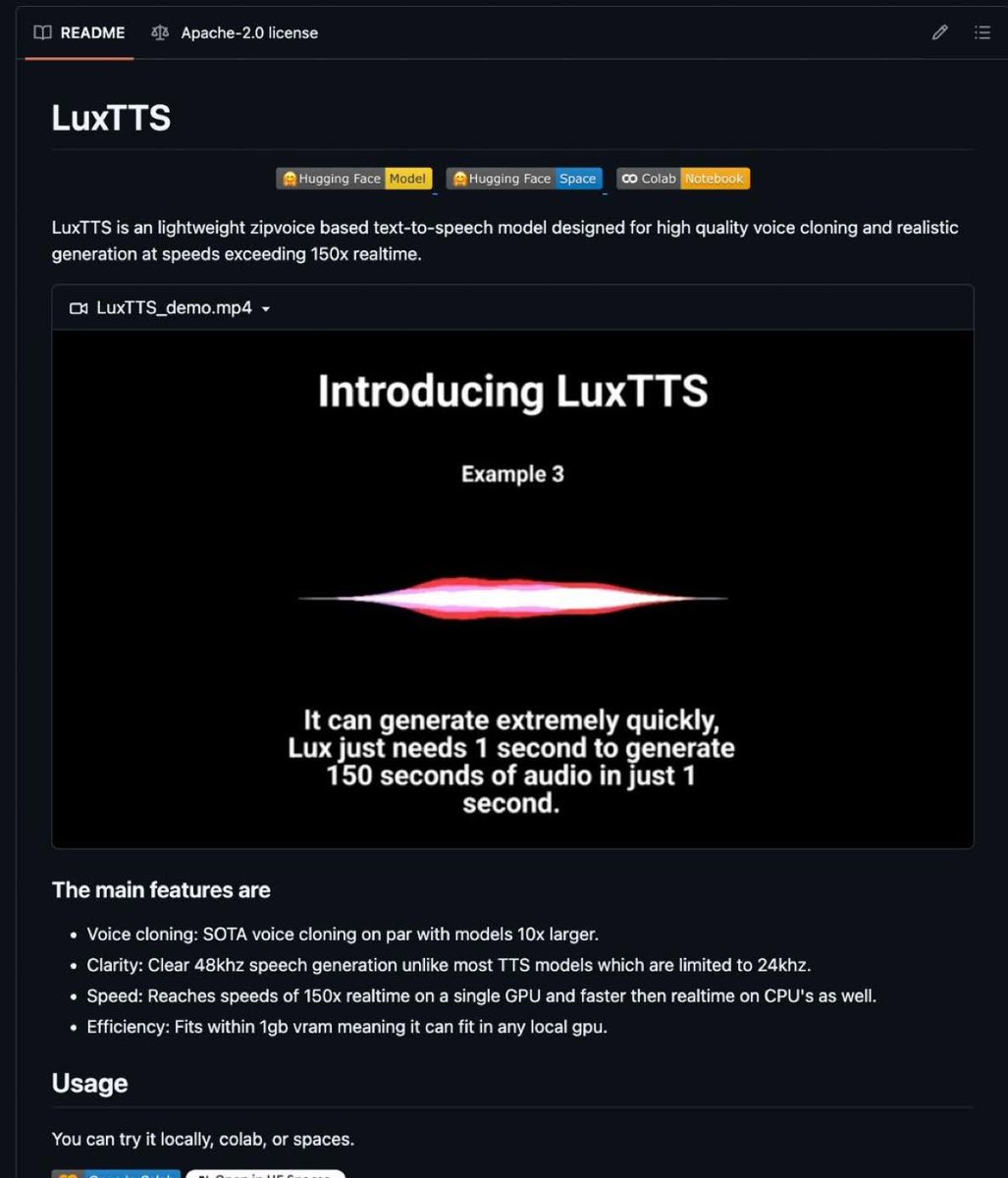
You can now clone any voice on a 4GB GPU & CPU😗
Open-source LuxTTS,
It clones voices from 3 seconds of audio at 150x realtime speed. Fits in 1GB VRAM.
Faster than realtime even on CPU.
48khz output vs industry standard 24khz
Clone any voice locally Works on GPU and CPU
- github.com/ysharma3501/LuxTT…
12
145
1,054
37,581
Daniel B. - AI & Tech retweeted

Hermes can call you first

11
23
244
34,783
If you're using Ollama, go ahead and run this one command:
ollama launch hermes-desktop
You then have self-improving Python skills, parallel sub-agents, memory stack, messaging integrations (Telegram/Discord/Slack), etc.
This is how you work in 2026. Thank me later!
1
33
Daniel B. - AI & Tech retweeted

‼️ Google is about to disable all adblocker extensions in Chrome. Instead of letting the adblocker inspect traffic itself, extensions now have to hand Google's browser a limited list of filtering rules and hope for the best. This leads to weaker blocking and more ads getting through.
Google makes the vast majority of its money selling ads. The company that profits from every ad you see also controls the browser most people use, with Chrome 149 being the last version supporting adblockers.
For example, under the new rules, uBlock Origin cannot exist. For millions of people, that extension is the only thing standing between them and a wall of ads, trackers, and autoplay garbage. One user put it bluntly: "The web is literally unusable without uBlock Origin."

743
1,314
7,494
1,664,155
Google dropped a diffusion LLM and it runs stupid fast locally.
Non-autoregressive diffusion model (activates close to 3.8B params) → up to 4x faster inference.
We're talking 700 t/s on RTX 5090, 1000 on H100. Quantized GGUF (~18 GB VRAM). Apache 2.0.
Even better, early llama.cpp support.
23

anyone running a 16gb card, stop scrolling. @pupposandro and @davideciffa got qwen 35b-a3b down to 13.3gb, measured on a 3090 gpu.
which means a model you literally could not load before now fits, running around 100 tok/s, near what you'd get with every expert resident on a 24gb card.
the clever part is the thing everyone gets wrong about moe. it only touches ~3b of its 35b params per token, routes to about 8 of 256 experts, but you still pay full vram to keep all of them around in case they're next.
luce spark learns which experts your traffic actually hits, pins those hot, and streams the rest from ram hidden under the matmuls so there's no speed cliff. one flag, and it tunes itself warmer every restart.
this is the kind of work that quietly drops the whole local inference tier down a card. don't let it scroll past.

10
36
419
81,353
Quick tip for anyone thinking of installing Hermes Agent:
Install it in an OS WITH A GUI. There will come a time when you will need a browser, or something related to that. At that time you will need to migrate if you don't have a GUI, and migration is a pain once you've setup complicated pipelines, shares, scripts and all that jazz.
Trust me, it will save you hours of work. Thank me later!
9

Congrats to @GoogleDeepMind on the launch of DiffusionGemma.
The model generates 256 tokens in parallel per step, delivering 150 TPS on DGX Spark, and 1,000 TPS on a single H100.
We're supporting it from day one with:
• BF16 and NVFP4 checkpoints on @huggingface🤗
• Free GPU-accelerated endpoints on build.nvidia.com
• @vllm_project support with FP8 precision
Get started with DiffusionGemma on NVIDIA: nvda.ws/43ro19u

DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.

38
118
1,367
98,985
Daniel B. - AI & Tech retweeted
Jun 10
Introducing the Hermes Agent Profile Builder
You can now build a complete profile in the dashboard with full control over identity/name/description, model/provider, built-in optional skills, skills-hub installs, and MCP servers in one easy flow
171
223
3,016
523,198
Daniel B. - AI & Tech retweeted

Jun 10
When all these closed labs decide it's time to rug pull everyone, you all are gonna regret not Buying a GPU
Owning your compute allows you to be in control, even if partially
Not too late yet
41
14
235
8,411
Want to access your home LAN devices from anywhere using @Tailscale, even if said LAN devices don’t have Tailscale installed?
I use this approach to access my Hermes Agent running in a Proxmox VM, which I don't want exposed to the Internet.
Here’s how to turn an Ubuntu Server VM into a Tailscale Subnet Router (step-by-step). 👇
What we’re building: A Linux VM that acts as a gateway. Once set up, any device on your Tailscale network can reach your local network (local Hermes Agents, local AI inference machines, phones, laptops, servers, printers, etc.).
So, after you have the Ubuntu machine running and updated, you need to install Tailscale:
curl -fsSL tailscale.com/install.sh | sh
In a browser on your laptop login with the link it gives you at the end of the install.
Now we need to enable IP Forwarding:
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.conf
echo 'net.ipv6.conf.all.forwarding = 1' | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
Great, in order for devices on our Tailscale network to access other devices on the subnet where the Ubuntu machine is, we need to advertise the subnet:
sudo tailscale up --advertise-routes=192.168.1.0/24
You need to replace that 192.168.1.0/24 with whatever you have setup for your LAN.
Once you run that command, go back to your Tailscale control panel and approve the subnet.
With that done, just enable Tailscale to start at boot:
sudo systemctl enable --now tailscaled
That's it, you should now be able to access your subnet for your other Tailscale devices.
Note that when running in a VM you might see warnings about UDP GRO forwarding suboptimally configured. Just the joys of running in a VM, you're still good to go.
Enjoy! 😎
1
70
Here's one interesting statistic from @Stanford about the evolution of local AI capabilities:
Local models just hit 71.3% on real-world chat/reasoning queries (up from 23% in 2023).
Local models are now able to resolve 71% to 88.7% of queries compared to SOTA models.
Hugging Face CEO calls it a "narrative violation."
The future isn't bigger cloud clusters, it's dense, practical intelligence running on your local hardware.
Thought about what this means for daily workflows?
2
Here's another cool tool: TextVision - fully local image contents extraction for agents.
OCR local LLMs (DeepSeek etc.) turn screenshots/SVGs into structured Markdown/JSON with facts uncertainties.
No cloud. No API keys. No hallucinations from vision models.
GitHub: github.com/huaqing0/textvisi…
13