
Genetics PhD student @Stanford w/ @BrianHie | Prev @UMNComputerSci
Joined November 2018
- Tweets 111
- Following 382
- Followers 244
- Likes 155
19 Photos and videos





Pinned Tweet

20 Feb 2025
It was super fun working on Evo 2, a DNA language model trained on genomes across the tree of life!
Check out the preprint: arcinstitute.org/manuscripts…
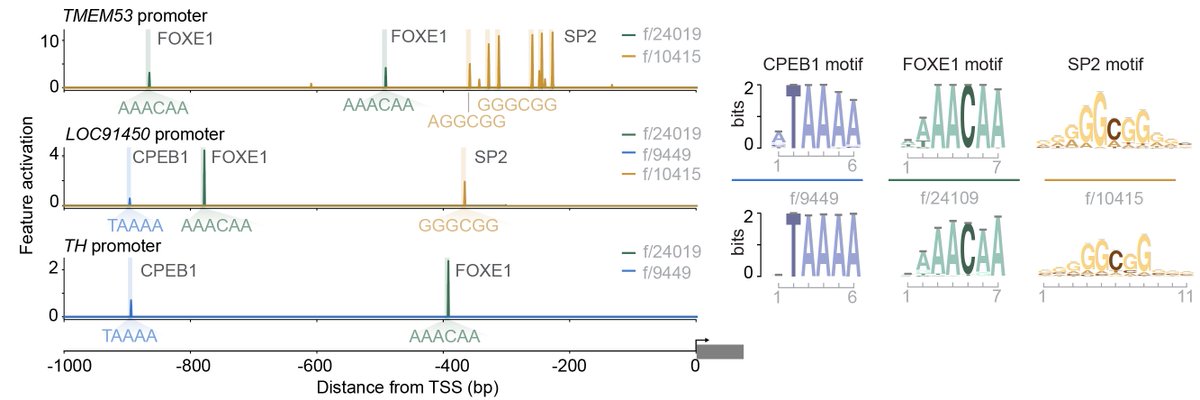
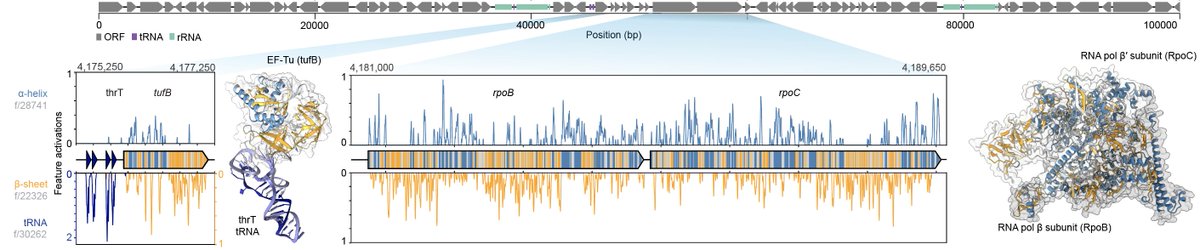
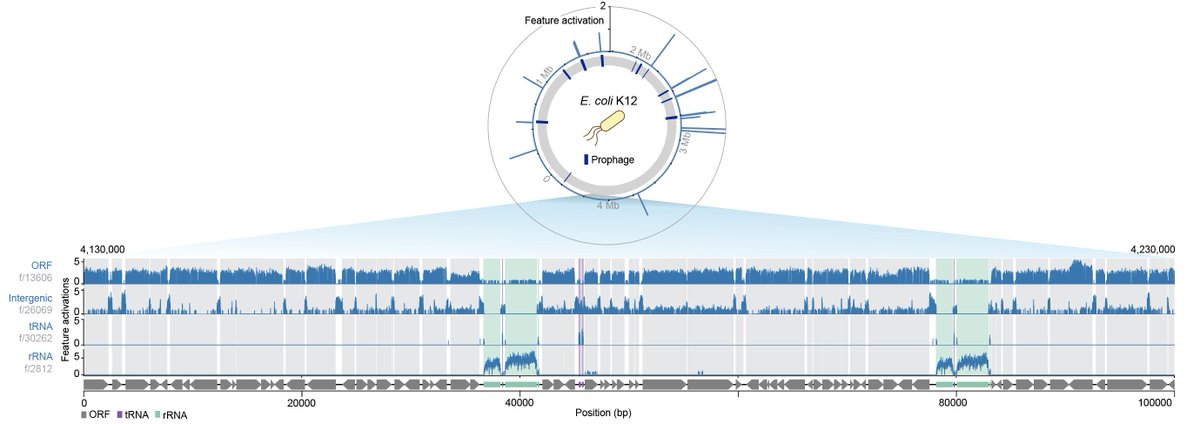
A small 🧵 highlighting some mechanistic interpretability work on Evo 2 (Fig. 4) we did in collaboration with @GoodfireAI 🔥🔥🔥
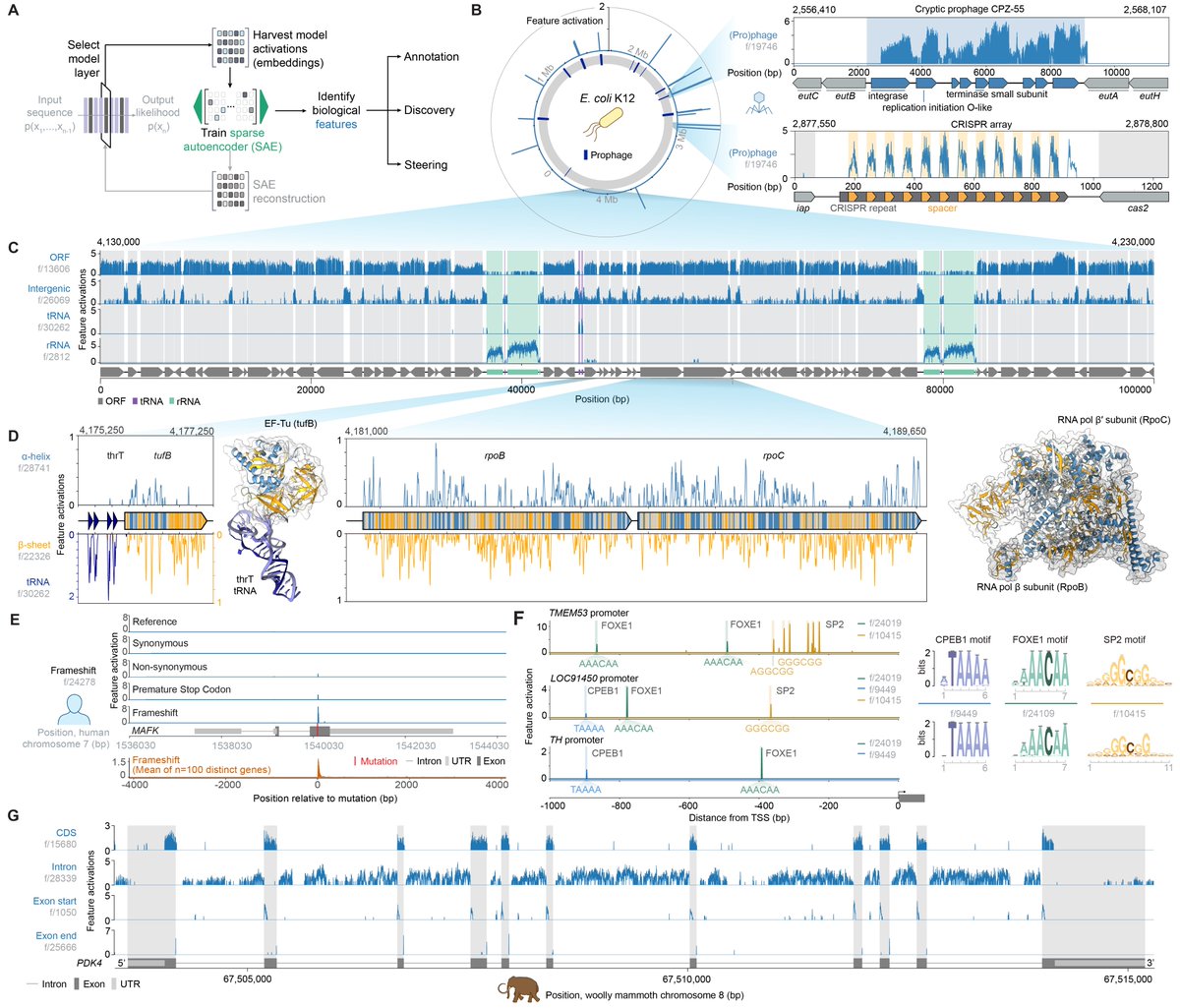
6
36
142
31,142
Daniel Chang retweeted

Apr 30
Our lab is proud to present our latest work harnessing Bridge Recombinase for genome-scale editing in diverse bacteria, microbiome editing, and programmable horizontal gene transfer.

Bridge recombinase enables versatile rewriting of bacterial genomes biorxiv.org/content/10.64898… #biorxiv_synbio
4
56
179
22,267

Nature research paper: Transposable elements are driving rapid adaptation of Enterococcus faecium
go.nature.com/42qOQKc
10
39
10,137
Apr 27
Congrats @kenjmloi and @PeterHYoon on a very elegant story!
Apr 27

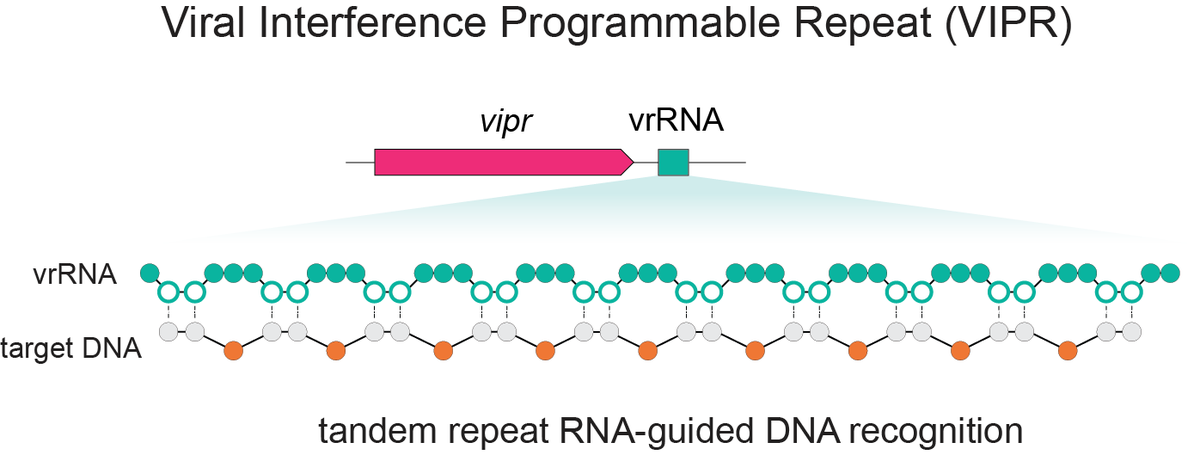
Excited to share our discovery of a new programmable RNA-guided DNA-targeting system hiding inside bacteriophages that predates CRISPR.
We call it VIPR (Viral Interference Programmable Repeat), and it uses an entirely new logic to find its targets.
Thread link below.
1
3
432
Daniel Chang retweeted

Apr 23
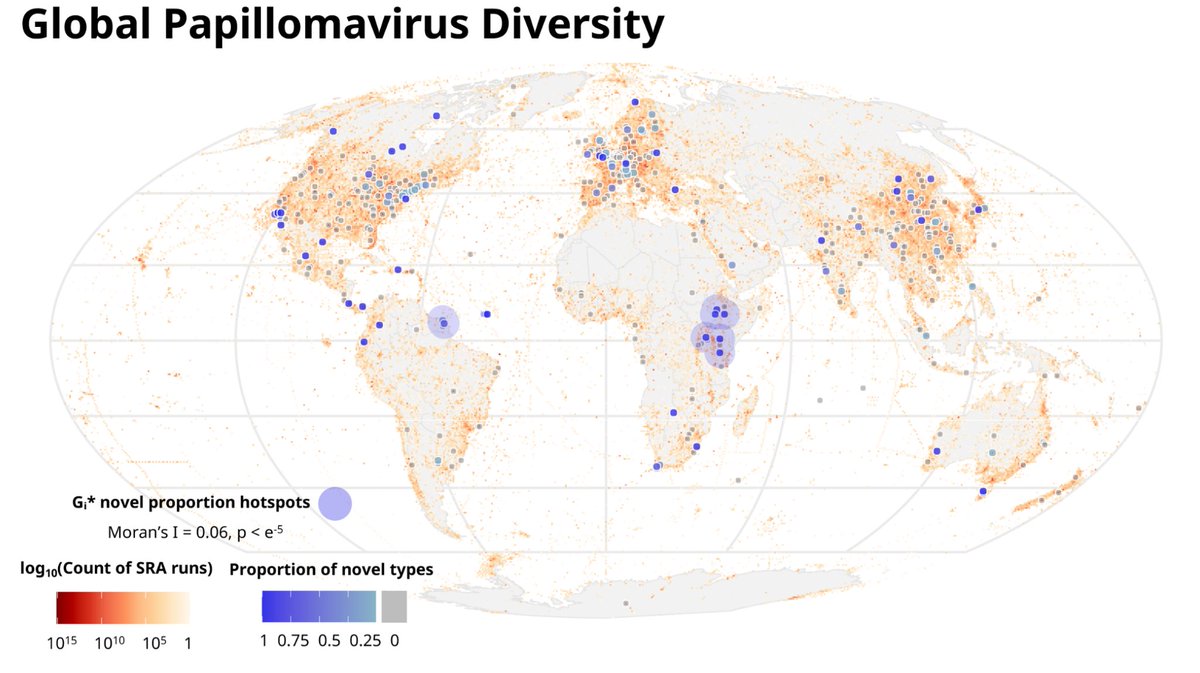
🧬Ultra fast petabase-scale virus discovery is here! 🚀
In our lab’s newest preprint, Jess explores the biodiversity of Papillomaviruses (PVs) in record time
🧵1/5 👇
🔗: doi.org/10.64898/2026
4
14
35
3,665
Daniel Chang retweeted

Apr 16
Submit to the GenBio Workshop at ICML this year!

Excited to introduce the 2026 workshop on Generative and Agentic AI for Biology at ICML 2026!
genbio-workshop.github.io/20…
1/5
5
24
4,776
Daniel Chang retweeted

Mar 27
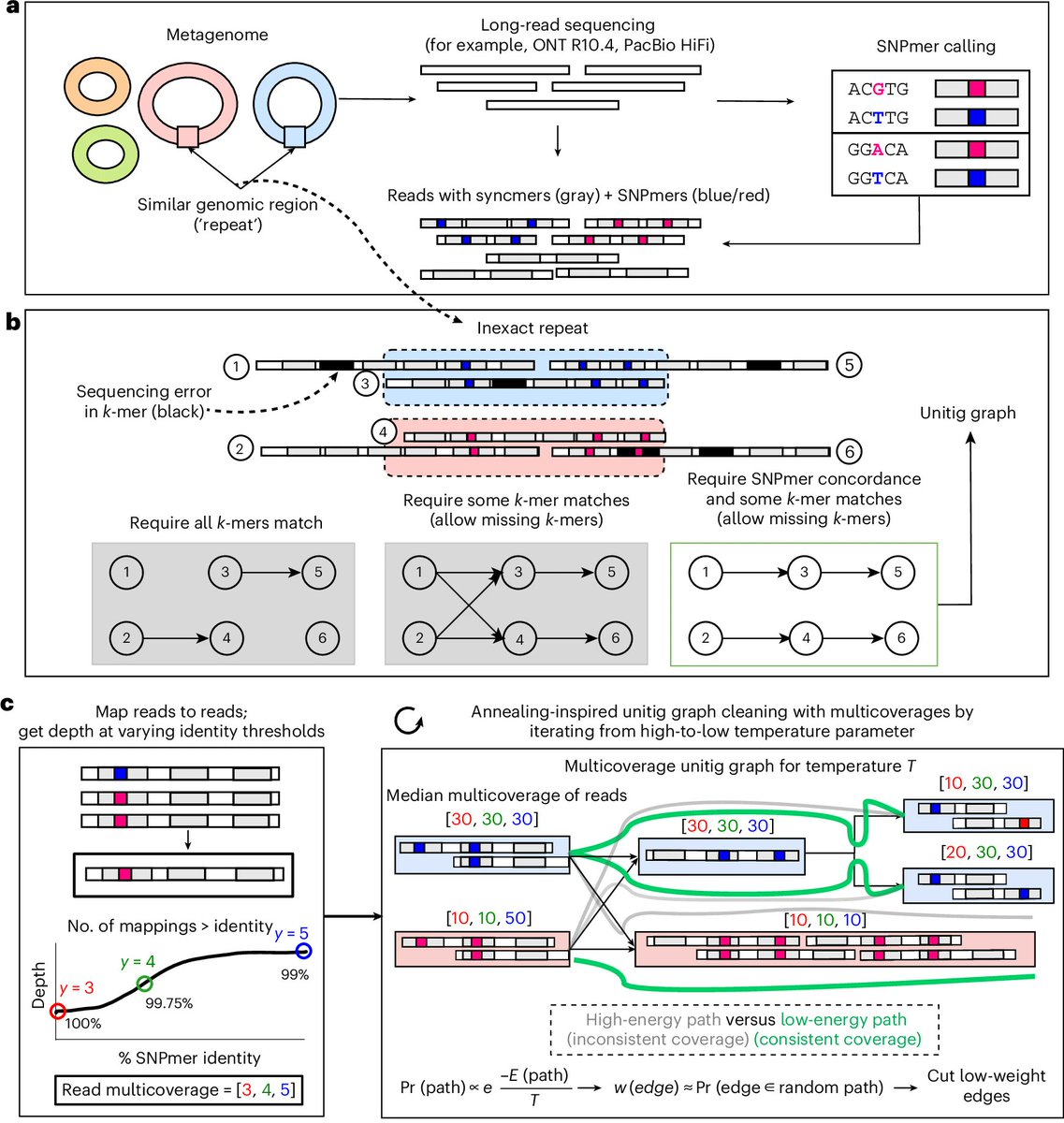
Myloasm, our long-read metagenome assembler, is now published! w/ Max Marin & @lh3lh3
Very rewarding after > a year of development and countless hours thinking about assembly. Thanks to beta testers, Li lab, and reviewers for helpful feedback.
Link: rdcu.be/famFj

High-resolution metagenome assembly for modern long reads with myloasm - @lh3lh3 go.nature.com/3PBEwvR
1
36
95
21,556
Daniel Chang retweeted

Mar 17
Pleased to announce that CellVoyager is published @naturemethods!
CellVoyager is a scRNA-seq AI agent that autonomously generates hypotheses and tests them in a live analysis notebook, where users can guide the discovery process.
Demo: cellvoyager.org
What's new 🧵⤵️
1
7
31
6,190
Daniel Chang retweeted

Mar 11
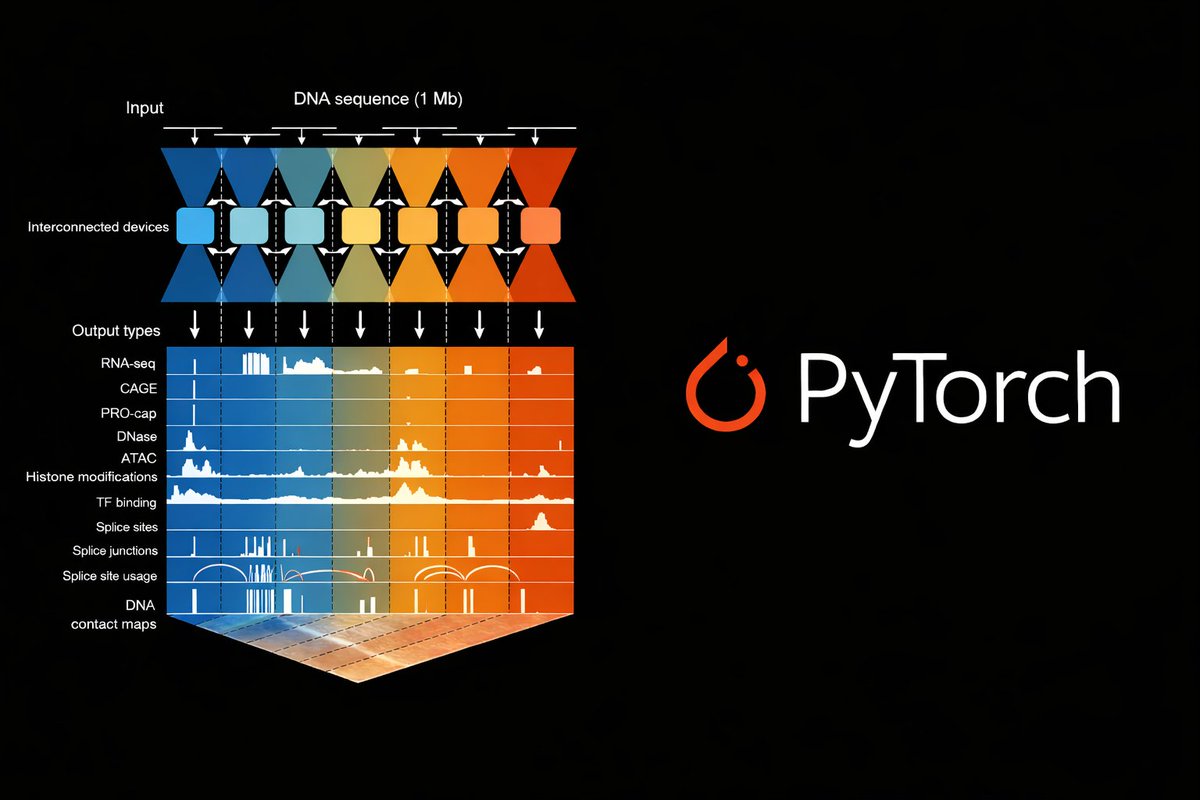
Thrilled to announce alphagenome-pytorch, an accurate, readable, and careful port of AlphaGenome's architecture and weights to PyTorch. Work with @gtcaa @m_kjellberg @chriswzou @tuxinming as part of the GenomicsxAI initiative between @anshulkundaje and @pkoo562 labs.
6
105
446
64,070
Daniel Chang retweeted

Our 2 papers on RNA-guided transcription are now out @Nature. This mechanism re-writes the traditional concept of bacterial transcription and allows RNA transcripts to be generated de novo from potentially any cellular DNA sequence. 🧬 See below for links and thread 🧵

Out now! In collaboration with @LeifuChangLab, we uncover the molecular and structural underpinnings of CRISPR-Cas12f-like RNA-guided transcription systems!
Links to the articles in the following tweet:
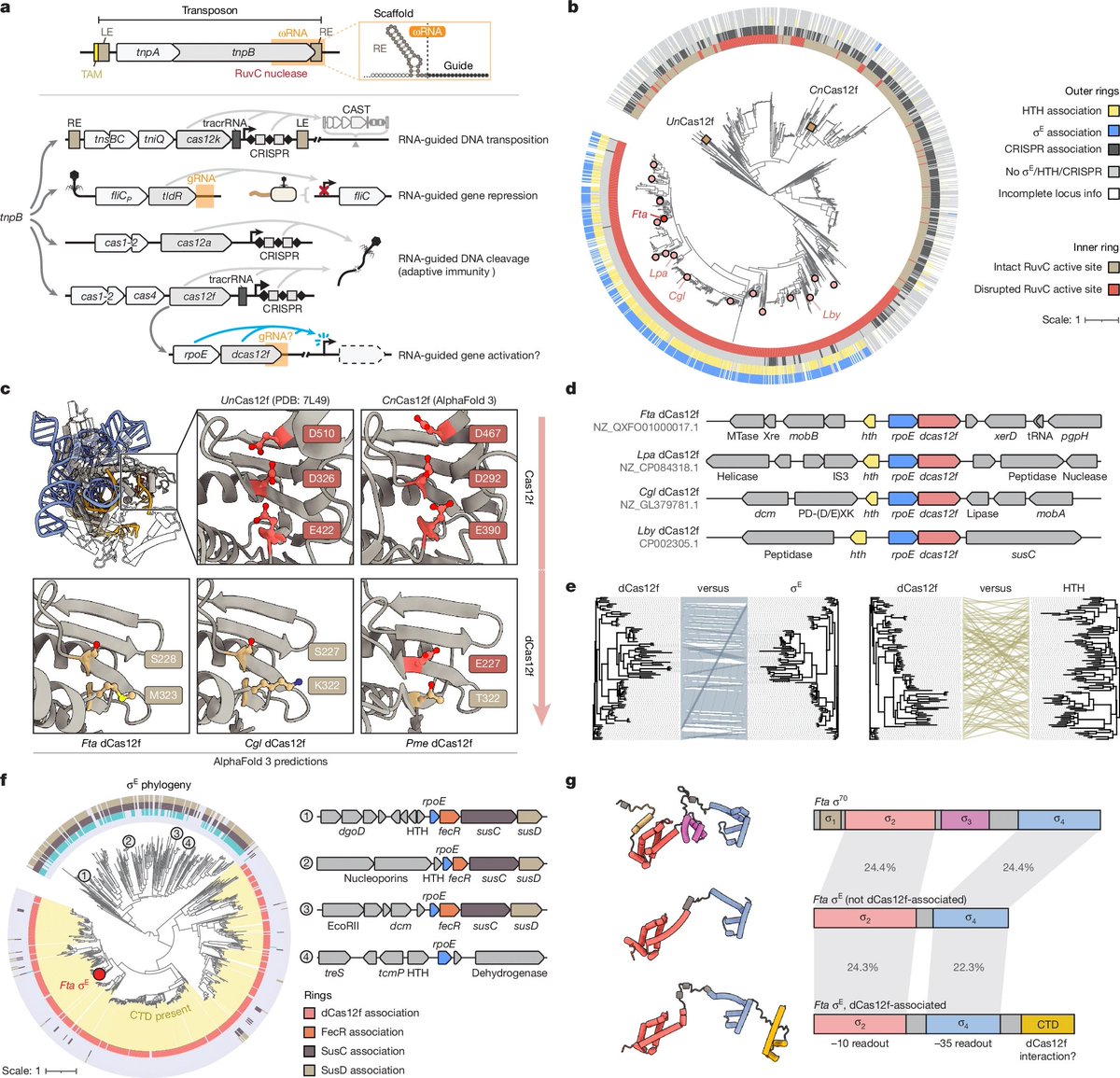
2
32
179
19,453
Daniel Chang retweeted

Mar 4
To make Evo 2 more accessible, we're releasing Evo 2 20B, a checkpoint that achieves 40B-level performance on a single H100, as a drop-in replacement. This came out of model surgery with @danielchang2002, and we are excited to see people build on it!
github.com/ArcInstitute/evo2…

1
11
44
8,989
Daniel Chang retweeted
Mar 4
Evo 2 is out in Nature today, showing that genome language models can predict and design across the full complexity of life, from phages to eukaryotes.
A few surprises from the project, including how ignoring trillions of nucleotides was key to getting a good model. 🧵

14
207
1,015
102,665
Daniel Chang retweeted

Feb 19
The hardest part of protein engineering isn't just finding good mutations – it’s deciphering which ones combine synergistically.
Today in @ScienceMagazine, we present MULTI-evolve, a framework for rapid multi-mutant protein engineering, validated across three diverse proteins.
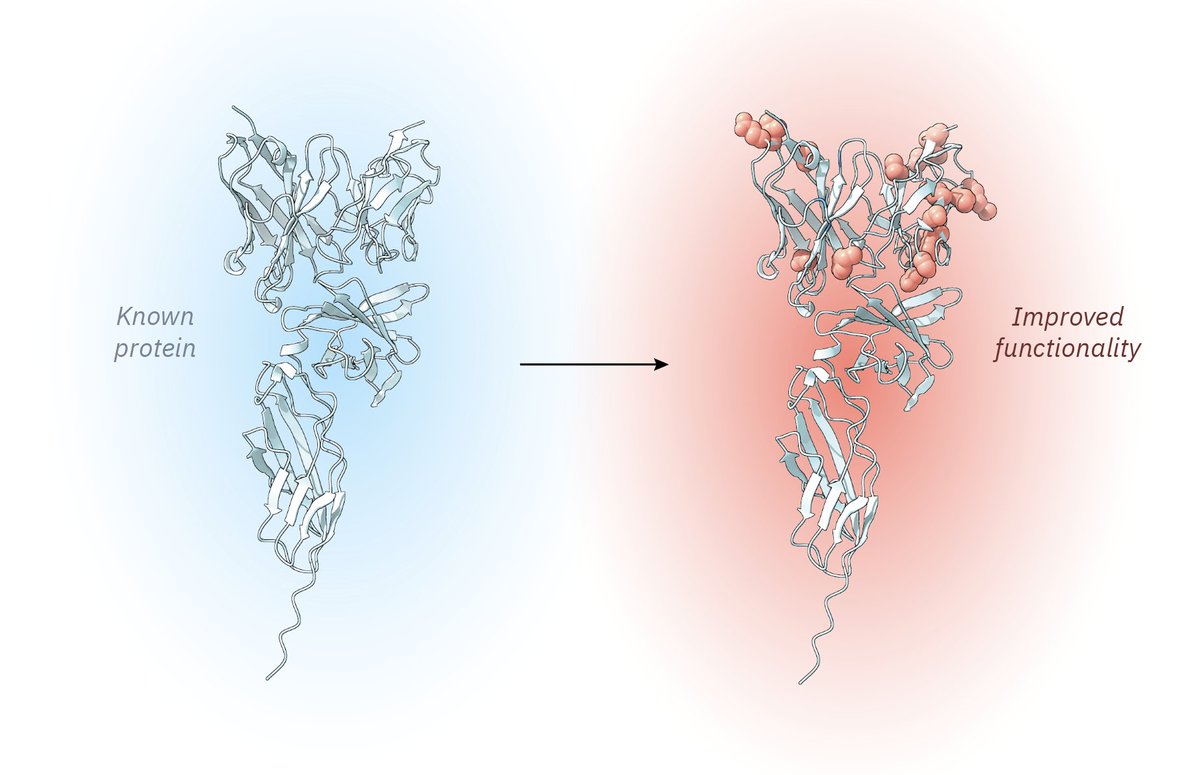
10
90
421
43,511
Daniel Chang retweeted

Feb 17
SAEs fail even when the Linear Representation Hypothesis holds perfectly.
We built SynthSAEBench: large-scale synthetic data with 16k ground-truth features, correlation, hierarchy, and superposition. We trained 5 SAE architectures on it.
None achieve perfect feature recovery.
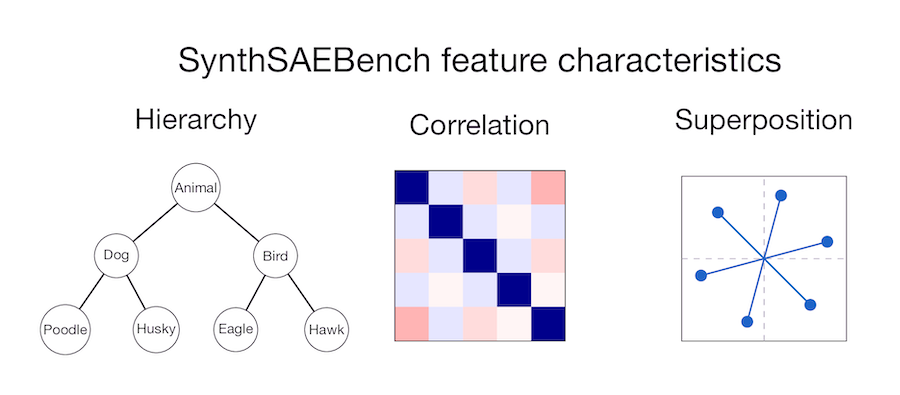
5
26
214
9,902
Nature research paper: Long-read metagenomics reveals phage dynamics in the human gut microbiome
go.nature.com/4p3PsiC
3
20
80
19,994
26 Nov 2025
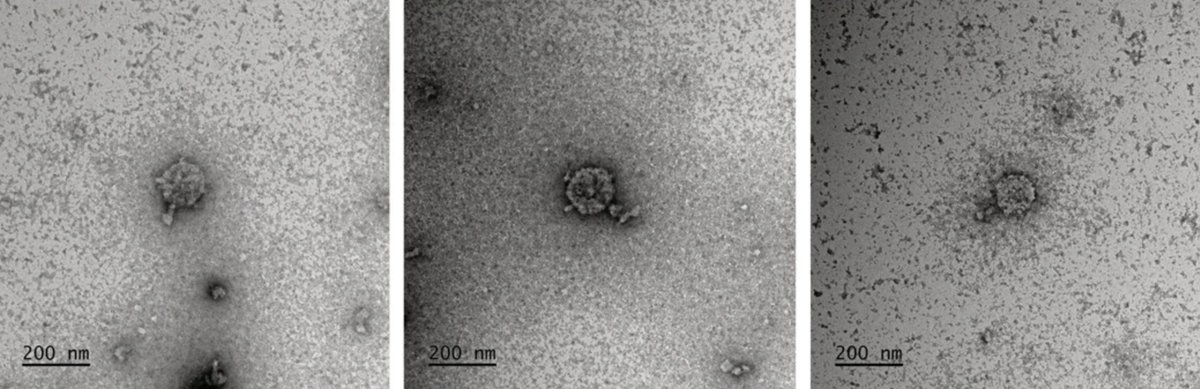
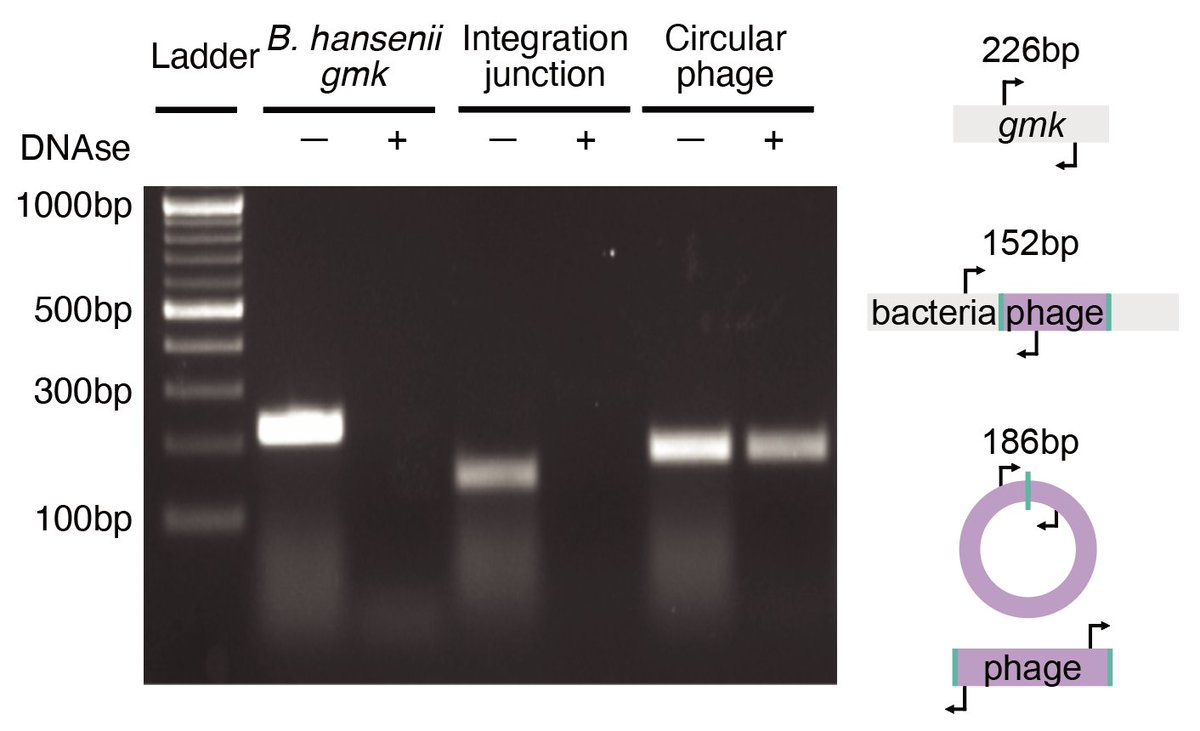
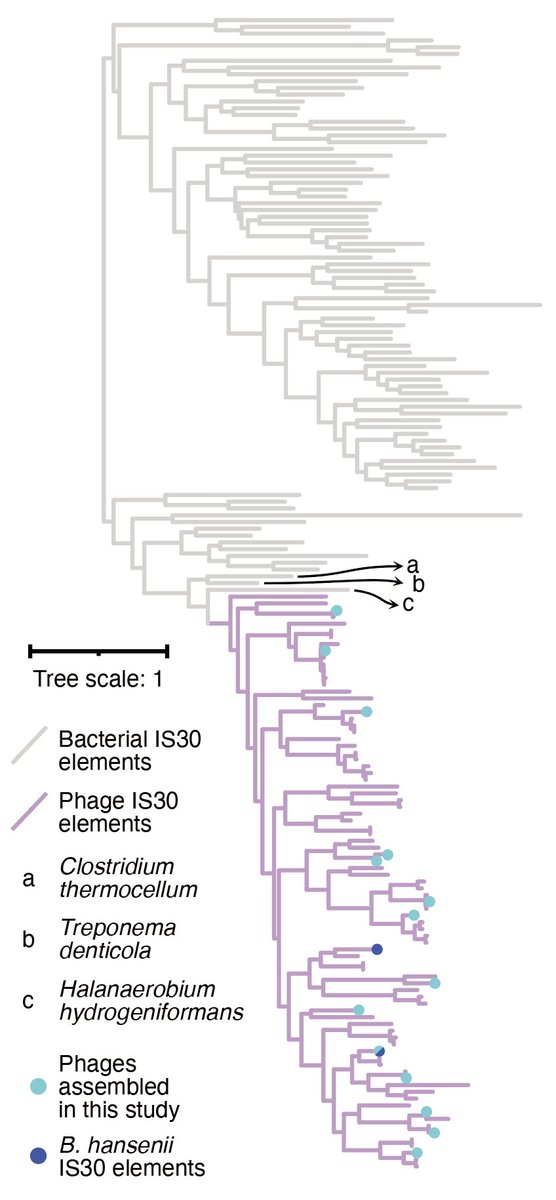
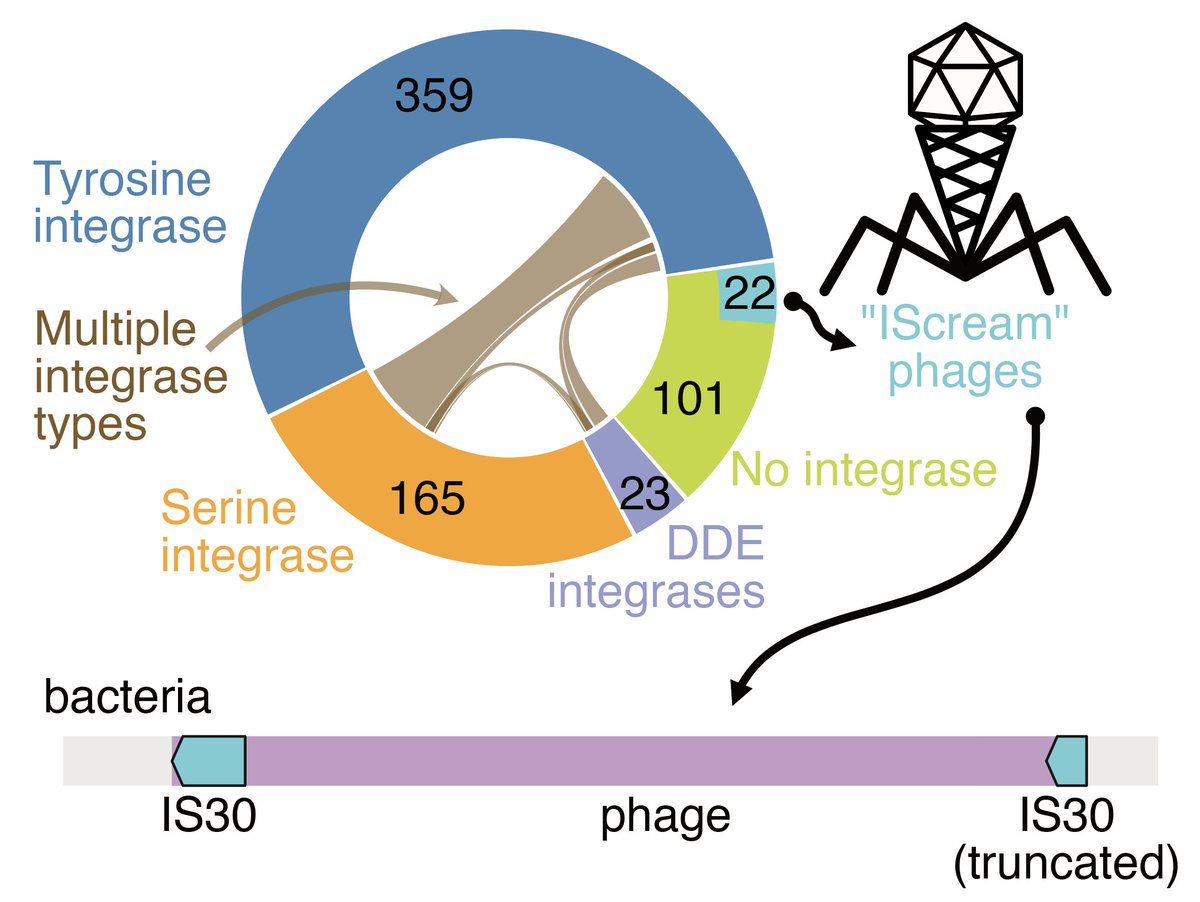
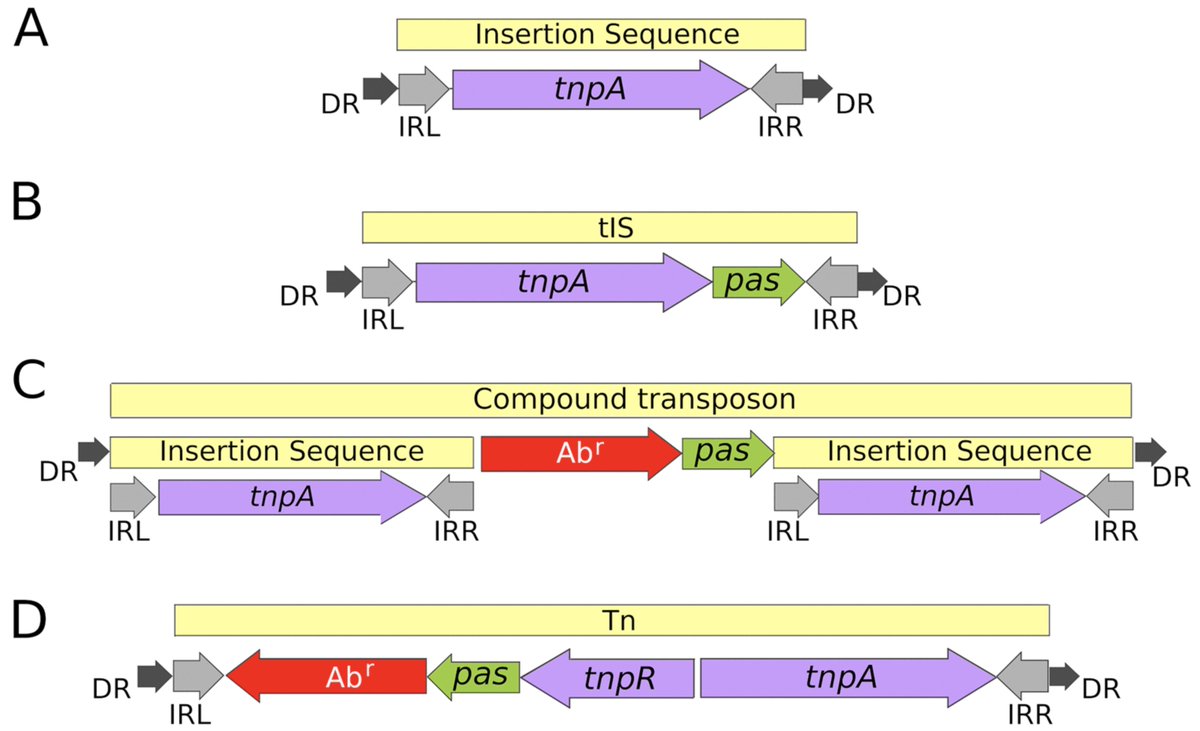
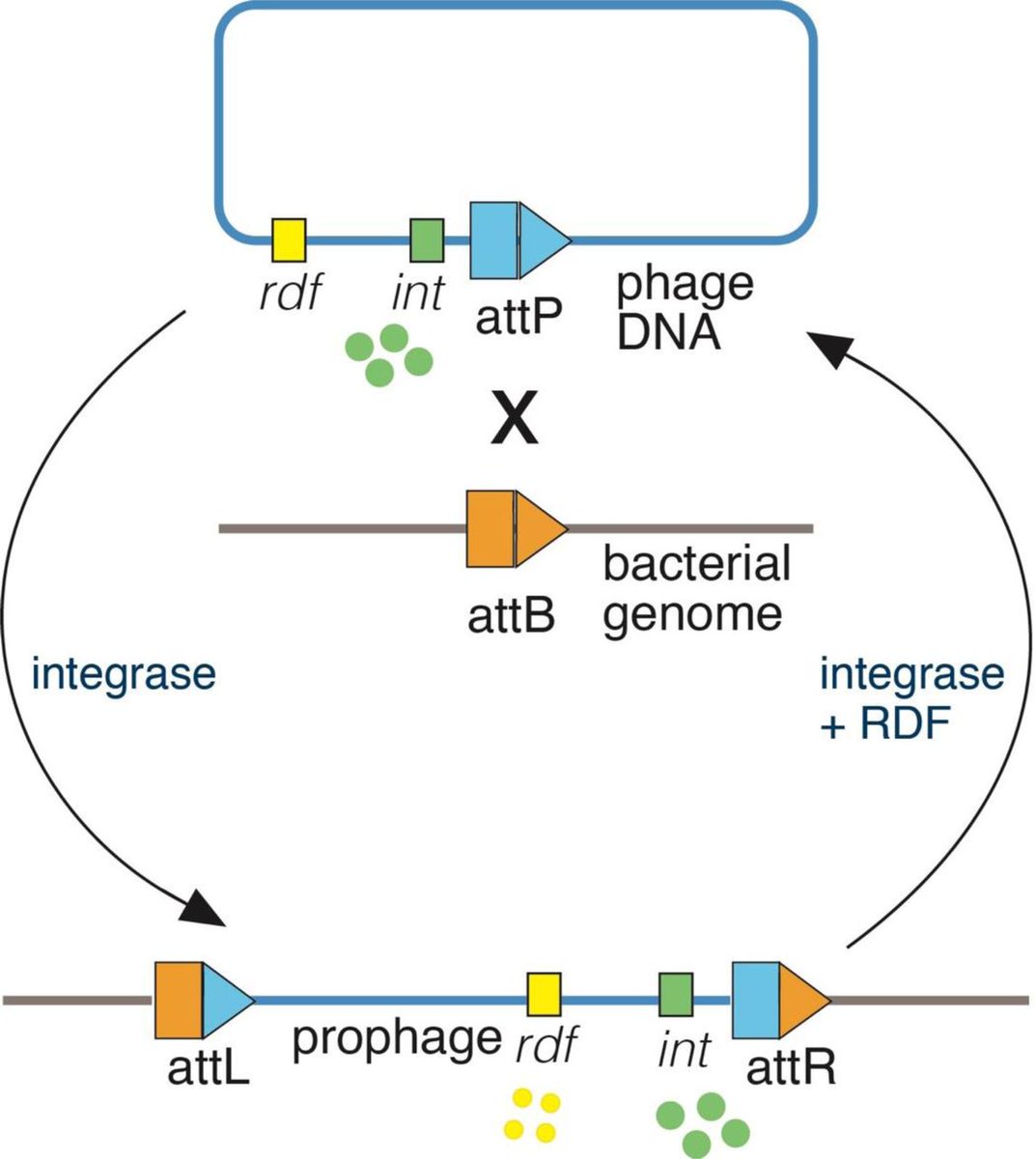
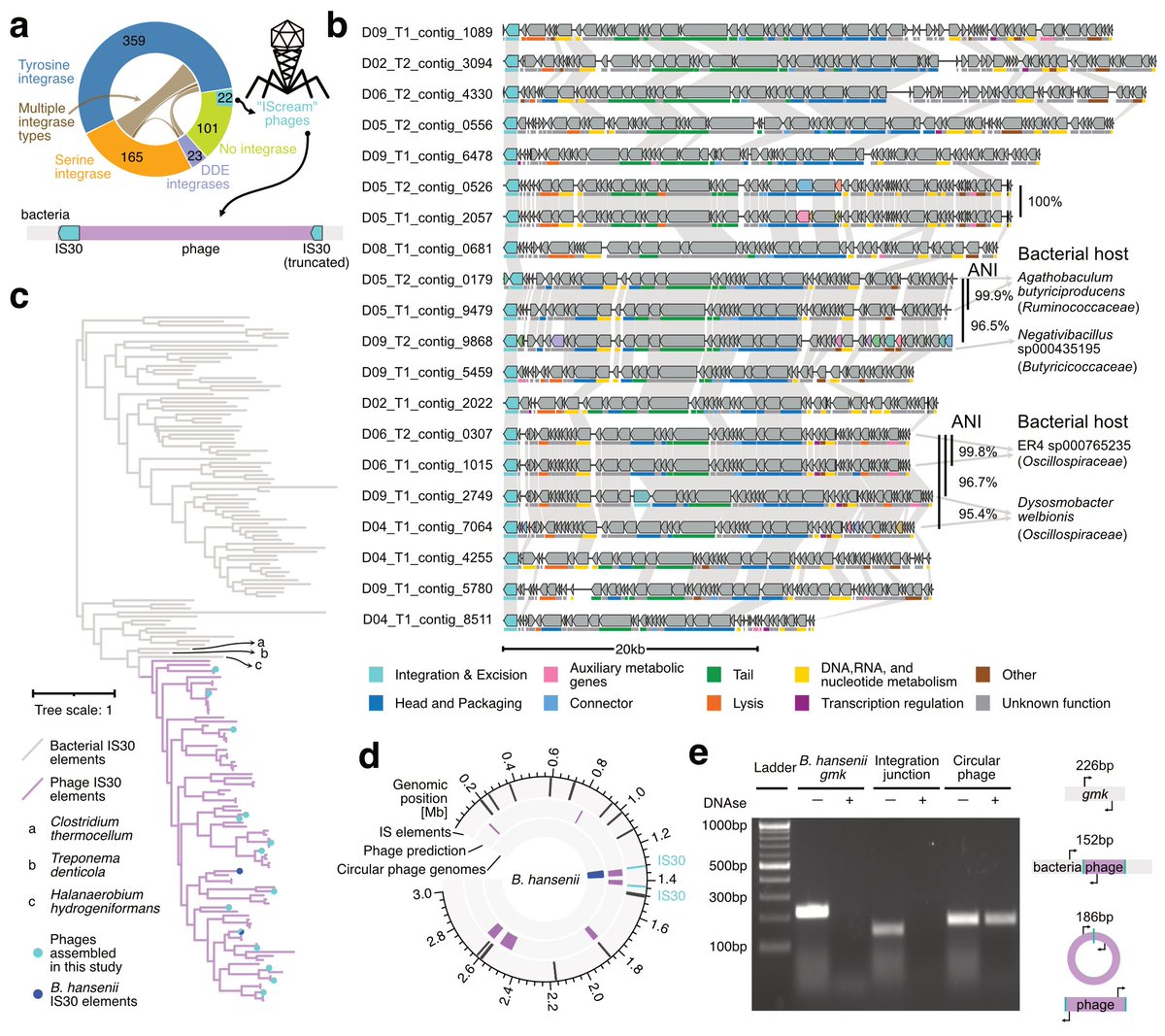
Paper is out!🍦
nature.com/articles/s41586-0…
13 May 2025

New work out from Bhatt lab led by Jakob Wirbel and @Angela_Hickey98 on uncovering gut prophage biology via long-read metagenomics!
biorxiv.org/content/10.1101/…
A small 🧵 highlighting the tale of IScream🍦phage (Fig. 4) which I was lucky to work on while rotating in the Bhatt lab!
3
175
19 Nov 2025
Congrats @aditimerch!! This paper is so beautiful nature.com/articles/s41586-0…
19 Nov 2025

What if we could autocomplete DNA based on function?
Today in @Nature, we share semantic design—a strategy for function-guided design with genomic language models that leverages genomic context to create de novo genes with desired functions.🧵
nature.com/articles/s41586-0…
5
1,994
Daniel Chang retweeted

15 Nov 2025
I am so excited to share our project with you! We find prokaryotic proteases activate toxic enzymes and pores as a modular strategy in phage defense. We studied four fascinating protease-toxin pairs that are abundant across bacterial genomes:
Many thanks to our wonderful collaborators and to the Gao lab for making this work possible!
biorxiv.org/content/10.1101/…
2
4
8
839

We are actively recruiting for two positions at the interface between biology and generative design. Backgrounds of particular interest are in protein biochemistry/evolution and synthetic genomics/biology.
Please consider joining us! 1/n
7
87
339
42,668
Daniel Chang retweeted

13 Nov 2025
Closing the AI-to-lab loop is hard, especially if you want to test your WHOLE GENOME generator..
Viruses are the only genomes cheap enough to print en mass, but raise biosafety flags
So @ArcInstitute chose phages!
We went deep w/ @samuelhking & @driscoll_cl on how they did it:

2
10
58
24,938
Daniel Chang retweeted

28 Oct 2025
We're thrilled to announce SeqHub, an AI-enabled platform for biological sequence analysis. SeqHub brings together sequence search, genome annotation, and data sharing in one place.
I dreamed of a single place where I could learn everything about my sequences. Today, a much more refined version of this dream takes form with SeqHub.org, built by an incredible team at @tatta_bio. Our goal is to make sequence interpretation more intuitive and collaborative for everyone working with biological sequences.
Currently, SeqHub is optimized for microbial protein and genome analysis. As we expand beyond microbial data, we'd love your feedback to help shape what comes next. I'm deeply grateful to our team at Tatta Bio, and to our collaborators and funders, for making this vision a reality.
Check it out at seqhub.org!
14
114
558
53,010