
Taking a break | previously @databricks MosaicML @allen_ai @semanticscholar | @harveymudd | he/him | Black lives matter.
Joined October 2011
- Tweets 108
- Following 660
- Followers 542
- Likes 236
4 Photos and videos

25 Jul 2025
Last week was my last week at Databricks. I'm so grateful to have worked with many incredible folks at Mosaic and Databricks, and proud of everything we accomplished, released, and learned together. Thank you to everyone who has been part of the journey. And now, a break :)
21
1
83
6,018
Daniel King retweeted

26 Jun 2024
A while back we ran into this problem. This was our fix: github.com/mosaicml/llm-foun…
1
2
13
970
Daniel King retweeted

22 Mar 2024
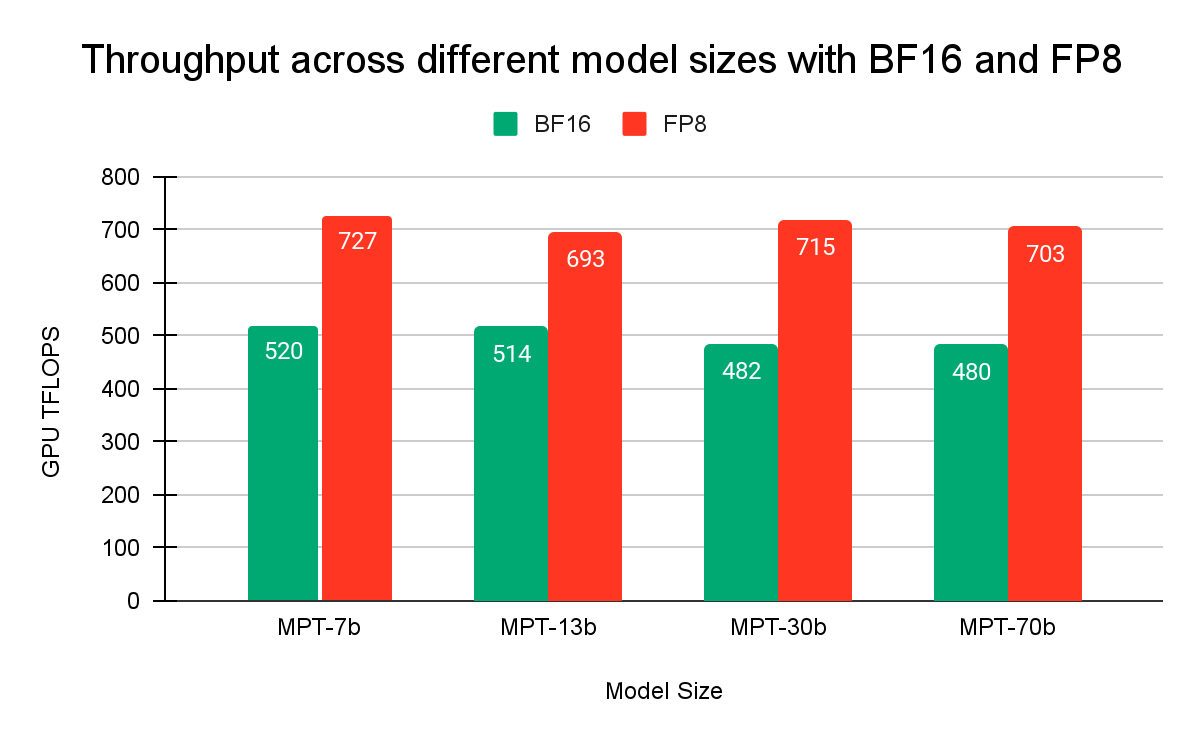
🚨New🌟blog✍️ on ⏩ maximizing🌙 FLOPS 🚀
Training large models requires maximizing flops/GPU, especially at scale. Excited to share a few of the cool tricks in thread👀. 1/N
6
35
186
48,410
1 Feb 2024
It is very fun to be able to collaborate with old friends from AI2 ❤️ Congrats on the launch @kylelostat @mechanicaldirk @i_beltagy @soldni Pete and everyone else!
1 Feb 2024

@MosaicML was, and continues to be, an amazing partner of the OLMo project. Not just on the compute side! If you look at the OLMo codebase (github.com/allenai/OLMo), you'll see a lot of shared DNA between that and LLM Foundry (github.com/mosaicml/llm-foun…)!
1
19
1,486
Daniel King retweeted

4 Sep 2023
My EMNLP paper got desk-rejected post-rebuttal because I posted it to arxiv 25 minutes after the anonymity deadline. I was optimistic about our reviews, so I spent a whole week while visiting my family writing rebuttals and coding experiments to respond.
4 Sep 2023

Just got a desk reject, post-rebuttals, for a paper being submitted to arxiv <30 min late for the anonymity deadline. I talk about how the ACL embargo policy hurts junior researchers and makes ACL venues less desirable for NLP work. I don’t talk about the pointless NOISE it adds.
3
27
180
105,034
Daniel King retweeted

28 Jul 2023
If you're at #ICML 🌴on Saturday, make sure to check out the es-fomo.com/ workshop on efficient training of LLMs!
@abhi_venigalla and @jefrankle will be at our poster on optimized pretraining of MosaicBERT ⚡️🚄
📜workshop paper: openreview.net/forum?id=WH1S…
🧵
1
16
46
6,879
Daniel King retweeted

24 Jul 2023
🌴Aloha from Oahu!🌴 We're at the @icmlconf all week talking about #generativeAI, #llms, #diffusionmodels and our #opensource projects. Come say hello - and grab a lei! #icml2023 #icmlconf 🥥 🏄♀️ 🏖

4
24
6,464
23 Jul 2023
At ICML in Hawaii this week! DM me or come find me at the @MosaicML @databricks booth if you want to chat!
1
22
2,250
30 Jun 2023
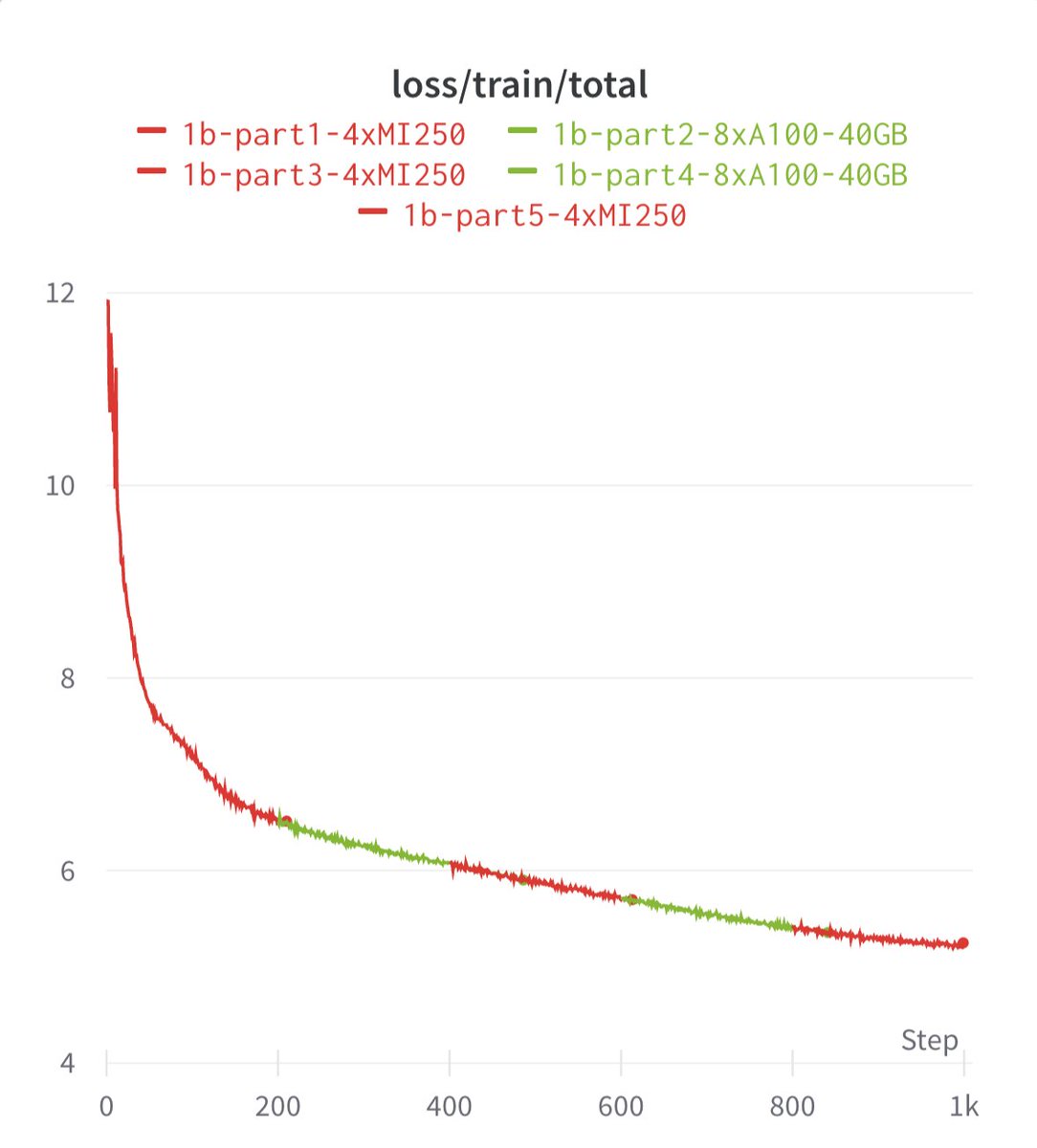
Love these types of plots. @MosaicML we've made them for cloud compute provider, cloud storage provider, and now GPU type as well!
30 Jun 2023

And yes, you can switch back and forth between NVIDIA and AMD, even within a single training run.
It's Christmas in July!🎄
1
7
934
Daniel King retweeted
26 Jun 2023
Today, we’re excited to share that MosaicML has agreed to join @Databricks!

16
85
601
318,431
Daniel King retweeted
22 Jun 2023
Meet MPT-30B, the latest member of @MosaicML's family of open-source, commercially usable models. It's trained on 1T tokens with up to 8k context (even more w/ALiBi) on A100s and *H100s* with big improvements to Instruct and Chat. Take it for a spin on HF! huggingface.co/spaces/mosaic…

17
116
516
295,578
5 May 2023
Incredibly excited to release our open source MPT-7B! The most exciting part of this imo is that the process is all repeatable, and nearly all open source. Between the @MosaicML platform, and our Composer, Streaming, and LLMFoundry libraries, the final run was pretty easy :)
5 May 2023

MPT is here! Check out our shiny new LLMs, open-source w/commercial license. The base MPT-7B model is 7B params trained on 1T tokens and reaches LLaMA-7B quality. We also created Instruct (commercial), Chat, and (my favorite) StoryWriter-65k variants. 🧵 mosaicml.com/blog/mpt-7b
2
25
7,819
Daniel King retweeted

30 Apr 2023
In the last two weeks, @MosaicML had lots of big news: We trained a 1B/200B token LLM on RedPajama in < 72hrs, Replit used us to train a SOTA code model in < 10 days, we trained SD2 for < $50k, long context BERTs, and perf #'s on H100s. But the biggest news is coming this week 👀
6
16
252
70,305
29 Apr 2023
Took a quick break from training LLMs with @MosaicML to do a much needed update of scispaCy's entity linker to the latest UMLS release (2022AB)! github.com/allenai/scispacy/…
2
10
67
11,804
Daniel King retweeted
27 Apr 2023
How good are @nvidia H100s actually? In collaboration with @CoreWeave, we benchmarked A100 vs H100 performance for large language model training.
Here's what we found: [1/6]
mosaicml.com/blog/coreweave-…
2
46
213
106,506
Daniel King retweeted

27 Apr 2023
What training duration are you aiming for? Even a (30B param, 2T token) run would only cost ~$1.5M in compute.
And you can rent short-term “hero run” clusters from us, no need to buy GPUs outright or 1-yr commits
Cost estimate from here: mosaicml.com/blog/gpt-3-qual…
1
9
253
Daniel King retweeted
26 Apr 2023
And now it's < $50k. 🖼️Announcing @MosaicML's diffusion offering 📷We replicated Stable Diffusion 2.0, training from scratch with huge speedup, and we can do it on your data too. Human eval showed the model to be indistinguishable from the original. Blog: mosaicml.com/blog/training-s…
8
29
277
66,963
Daniel King retweeted
26 Apr 2023
4. Large model training no longer requires super teams with the right tools. We had 2-4 people working on this for about 1-2 months. @Replit trained their recent 3b code model with 2 people in a week. Great tools will empower small teams. Timelines are accelerating
1
1
12
1,458
Daniel King retweeted
20 Apr 2023
72 hrs ago, @togethercompute released the RedPajama dataset. Like everyone, we at @MosaicML were very excited about the idea of a fully open-source Llama. So excited, in fact, that we've already trained a 1B model on 200B tokens! It's on HF (Apache2) here: huggingface.co/mosaicml/mpt-…
12
78
457
152,539

At Replit, we're training our own LLMs.
We’ve partnered with @databricks, @huggingface, and @MosaicML to build a full LLM stack.
Curious about how?
Check out this post by @truerezashabani, our Head of AI.
blog.replit.com/llm-training
6
56
284
42,061