
APCyc: Property-Informed Design of Cyclic Peptides via Automated Cyclization
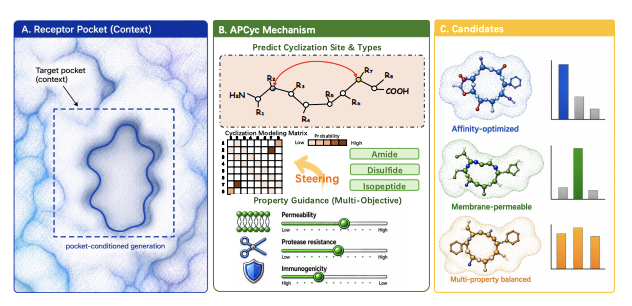
1. APCyc is a target-aware latent diffusion framework that designs cyclic peptides while treating cyclization topology (linkage type residue-level linkage sites) as a first-class, pocket-conditioned design variable rather than a post-hoc constraint.
2. The key idea is “automated cyclization”: given a receptor binding-pocket context, APCyc predicts which residues should be cyclized and which chemistry to use (amide, disulfide, isopeptide), enabling pocket-adaptive macrocyclization strategies without manual heuristics or enumerating preset patterns.
3. To make cyclization learnable from data, APCyc expands the residue vocabulary by splitting standard amino acids into cyclization-specific tokens (e.g., CYS_SS, LYS_ISO/ASP_ISO), so the model can represent “same residue identity, different cyclization role” directly at the token level.
4. APCyc introduces Automated Cyclization Pair Injection: it constructs pairwise residue representations from both E(3)-invariant latents and equivariant geometric latents, predicts a globally normalized linkage probability matrix over valid residue pairs, and injects this “online topology” signal into an SE(3)-equivariant AM-EGNN denoiser via edge feature augmentation plus message bias/gating schedules.
5. During late denoising, APCyc discretizes the predicted linkage into a “hard” covalent edge to help geometric closure, while maintaining SE(3)-equivariance of the overall denoising update.
6. Beyond topology, APCyc performs property-informed generation using Bayesian posterior guidance: differentiable, time-conditioned surrogate models in latent space provide gradients that steer diffusion sampling toward user-specified multi-objective targets (affinity, membrane permeability proxy, protease resistance, solubility, immunogenicity).
7. For multi-objective control, APCyc balances competing property gradients with adaptive per-step weights based on gradient norms, aiming to prevent a single objective from dominating the reverse diffusion trajectory.
8. Training/evaluation uses CPCore (a refined subset of CPSea): 71,867 cyclic peptide–protein complexes derived from AFDB; split by FoldSeek structural clusters to reduce leakage. Testing uses a Large Non-Redundant set with 56 targets; 10 candidates generated per receptor, with validity requiring cyclization success (3.0–8.0 Å closure) plus negative Rosetta interface energy.
9. In benchmarks vs PepGLAD, CP-Composer, and PepFlow (with PepGLAD/PepFlow retrained on CPCore), APCyc shows controllable shifts in drug-like properties while maintaining strong generative quality; e.g., best permeability proxy in the membrane-permeable setting (0.107) and best protease-resistance score in joint multi-property optimization (−1.474), alongside strong stability (best Rosetta total score −758.545) and high sequence–structure consistency (up to 0.971).
10. Target-level case studies (e.g., 3rc4 and 4xal) indicate APCyc can improve docking/immunogenicity proxies while increasing permeability and maintaining or improving protease resistance relative to baseline means, suggesting gains are not only aggregate but also observable per target.
💻Code: github.com/HKUSTGZ-ML4Health…
📜Paper: arxiv.org/abs/2606.12991
#CyclicPeptides #PeptideDesign #DiffusionModels #GenerativeAI #ComputationalBiology #DrugDiscovery #MachineLearning #KDD2026
17
1,289
Uncertainty Estimation for Molecular Diffusion Models
1. The paper addresses a practical gap in 3D molecular diffusion generation: pretrained diffusion models can output chemically invalid/unstable molecules, but they provide no principled per-sample signal of “this generation is likely low quality,” which is crucial when downstream evaluation (docking, wet lab) is expensive.
2. The authors propose a post-hoc uncertainty estimator that works with an existing pretrained molecular diffusion model (no retraining): fit a Laplace approximation around the denoiser’s MAP parameters and use it to quantify how variable the denoiser’s noise predictions are during sampling.
3. Core idea: for selected denoising timesteps, sample multiple parameter vectors from the approximate posterior q(θ), compute multiple noise predictions ε_t^m = f_{θ_m}(x_t, t), and take the elementwise sample variance across these predictions; then aggregate over timesteps, atoms, and feature dimensions into a single scalar uncertainty score per generated molecule.
4. The uncertainty is computed along the generation trajectory, motivated by the intuition that “internally uncertain” samples should induce more unstable/variable denoising behavior; empirically, only a small subset of timesteps is needed, reducing overhead.
5. On QM9, the resulting uncertainty score is informative of sample quality: it shows statistically significant negative Spearman correlations with molecular stability, atom stability, and validity, and it is consistently more predictive than diffusion negative log-likelihood (NLL) as a per-sample quality indicator.
6. Concrete QM9 correlations (Spearman ρ): for EDM, uncertainty vs. molecular stability is −0.284 (vs. NLL −0.150); for GeoLDM, −0.333 (vs. NLL −0.171). Similar gaps hold for atom stability and validity, suggesting likelihood is a weaker “verifier” than the proposed uncertainty for these quality metrics.
7. The paper then uses uncertainty for test-time scaling: oversample N molecules (10K→20K) and keep the 10K lowest-uncertainty samples. This improves stability/validity on QM9 for both EDM and GeoLDM, outperforming NLL-based filtering, with a modest tradeoff of ~1% drop in uniqueness.
8. The gains can be material relative to changing the base generator: for EDM on QM9, oversampling to 20K and filtering back to 10K yields ~10% molecular stability improvement, ~1% atom stability improvement, and ~5% validity improvement—comparable in magnitude to switching from EDM to GeoLDM at the same 10K budget.
9. Limitations and ablations: the filtering benefits do not transfer to GEOM-Drugs (larger, more complex molecules), where neither uncertainty- nor NLL-based filtering beats random subsampling. Ablations also show the Fisher-based Laplace covariance is not essential (isotropic perturbations around MAP perform similarly), implying the score may behave more like a sensitivity-to-perturbation measure than strict Bayesian epistemic uncertainty; signal concentrates near the clean end of the trajectory (late denoising steps).
📜Paper: arxiv.org/abs/2606.13451
#DiffusionModels #MolecularGeneration #ComputationalChemistry #UncertaintyEstimation #TestTimeScaling #BayesianDeepLearning #GenerativeModels #3DGeometry #QM9 #GEOMDrugs

1
15
1,213

Jun 13
DiffusionGemma is a new "experimental open model that explores text diffusion, an exceptionally fast approach to text generation" from Google.
I was wondering how long it would take until we could run diffusion text models!
"Released under an Apache 2.0 license, this 26B Mixture of Experts (MoE) model moves beyond the sequential token-by-token processing of typical autoregressive Large Language Models (LLMs). Instead, it generates entire blocks of text simultaneously, delivering up to 4x faster text generation on GPUs."
"DiffusionGemma is designed for researchers and developers exploring speed-critical, interactive local workflows such as in-line editing, rapid iteration, and generating non-linear text structures."
"By shifting the decode bottleneck from memory-bandwidth to compute, DiffusionGemma generates up to 4x faster token output on dedicated GPUs. (1000 tokens per second on a single NVIDIA H100, 700 tokens per second on NVIDIA GeForce RTX 5090)."
"Operating as a 26B total Mixture of Experts (MoE) model that activates only 3.8B parameters during inference, DiffusionGemma fits comfortably within 18GB VRAM limits of high-end dedicated consumer GPUs when quantized."
"Generating 256 tokens in parallel with each forward pass allows every token to attend to all others. This provides significant advantages for non-linear domains such as in-line editing, code infilling, amino acid sequences or mathematical graphs."
"The model iteratively refines its own output, allowing it to evaluate the entire text block at once to fix mistakes in real-time."
"Because it prioritizes speed and parallel layout generation, DiffusionGemma's overall output quality is lower than standard Gemma 4. For applications that demand maximum quality, we recommend deploying standard Gemma 4."
"You can improve DiffusionGemma's performance on specific tasks through fine-tuning. In the example below, Unsloth fine-tuned DiffusionGemma to play Sudoku -- a task autoregressive models struggle with because each token depends on future tokens. DiffusionGemma's bi-directional attention makes this much easier."
"Most language models act like a typewriter, generating one token at a time from left to right. In the cloud, this is efficient because servers can batch thousands of user requests together to share the hardware load. But when run locally for a single user, this word-by-word process leaves your dedicated GPU or TPU underutilized -- it spends most of its time simply waiting for the next 'keystroke.'"
"DiffusionGemma reverses this inefficiency. Instead of predicting words sequentially, it drafts an entire 256-token paragraph simultaneously. By giving the computer's processor a larger chunk of work at once, DiffusionGemma utilizes your hardware to its full potential. It upgrades your model inference from a single, sequential typewriter to a massive printing press that stamps the entire block of text simultaneously."
"In high-QPS cloud serving, autoregressive models can be deployed to saturate compute efficiently, so DiffusionGemma's parallel decoding offers diminishing returns and can result in higher serving costs. The throughput advantage is strongest at low-to-medium batch sizes on a single accelerator."
They go on to explain "how text diffusion works".
"Similar to AI image generators that start with visual static and iteratively refine it into a clear picture, DiffusionGemma applies this to text"
Do you have a GPU with enough memory? If so, you can go ahead and download the model weights from Hugging Face.
blog.google/innovation-and-a…
#solidstatelife #ai #genai #llms #diffusionmodels
104

Jun 11
day 10/30
if you’re deploying generative video or heavy diffusion models at scale, you quickly realize that standard backend frameworks will absolutely crush your server performance.
a typical web server handles requests concurrently in milliseconds. but a heavy generative model locks up a GPU for seconds at a time. if you build a standard synchronous API wrapper, your first few users will face massive latency bottlenecks, and your server will immediately time out.
moving a model from a local notebook to a reliable production API requires a completely decentralized architecture:
1. asynchronous task queues: separate your web server from your model workers using tools like celery or redis. let the web server immediately return a task ID and free up the connection.
2. dynamic batching: don't process requests one by one. use an optimization layer (like triton inference server or vllm) to group incoming inference requests together on the fly to maximize GPU utilization.
3. containerized scaling: wrap your model worker in a docker container. this lets you scale your GPU instances up or down based on queue depth, saving massive cloud infrastructure costs when idle.
if your deployment strategy is just wrapping a model in a raw flask or fastapi app and running it on a single machine, it’s going to crash the moment it gets real traffic lol.
how are you guys handling the asynchronous bottleneck in your inference pipelines? 👇
#MLOps #GenAI #DiffusionModels #BuildInPublic
2
2
39

Jun 10
📣 このたび、Autoware Foundation の Robotaxi Working Group において、auto_e2e リポジトリの Maintainer に就任いたしました。
Robotaxi Working Group ではオープンソースの End-to-End AI 自動運転モデルを構築しています。L2 および L4 Robotaxi アプリケーションを構築し、2027年5月にクローズドループ自動運転デモの達成を目標としています。
Tesla 、Waymo 、Wayve — 現在、プロダクションレベルの E2E 自動運転モデルはすべてプロプライエタリです。いずれもクローズドです。Tech Giants だけのものではなく、より多くの人に安全を届けるために自動運転の民主化を進めます。
Autoware は GitHub 11,700 stars を持つ世界最大のオープンソース自動運転フレームワークであり、TIER IV、Toyota、ARM、Intel をはじめとするグローバル企業が開発に参画しています。Robotaxi WG は、その中で E2E モデルのアーキテクチャ設計から学習基盤、デプロイまでを一貫して担う Working Group です。
この取り組みを主導できることを光栄に思います。自動運転の未来を、オープンに、ともに作っていきましょう。
Thanks Zain for the constant support and reviews 🙏
#AutonomousDriving #Autoware #EndToEnd #Robotaxi #OpenSource #AI #DiffusionModels #Level4 #SelfDrivingCars #DeepLearning #MLOps
5
33
1,781
Flexible Flows for Biological Sequence Design
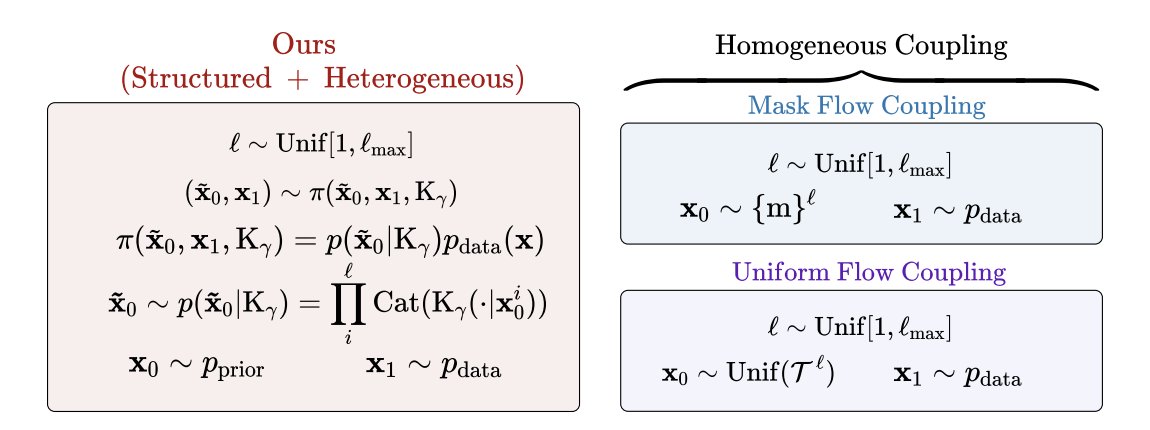
1. FlexFlow reframes discrete flow matching for biological sequences by changing the coupling (forward endpoint pairing) rather than the training objective: a structured, biology-informed coupling uses substitution matrices (e.g., BLOSUM for proteins; JC69/HKY85-style biases for nucleotides) to tilt the source distribution toward evolutionarily plausible neighborhoods.
2. The key idea is to keep the standard token-wise mixture path and CTMC machinery intact, but swap the usual “uninformative” couplings (uniform/masked) with a transition kernel Kγ that encodes preferred substitutions; when Kγ is uniform, the method reduces to the standard uniform coupling.
3. For variable-length generation, FlexFlow builds on Edit Flows by parameterizing reverse-time CTMC rates via edit operations (insertion, deletion, substitution). Instead of treating positions independently, it introduces a shared global latent r that conditions per-position edit decisions, coupling token-level operations through sequence-level context.
4. FlexFlow adds test-time control over edit behavior: operation probabilities are temperature-scaled and modeled with a Dirichlet prior over {ins, sub, del}. By changing Dirichlet concentrations α post-hoc, users can bias generation toward more insertions vs substitutions vs deletions without retraining, effectively acting as an “operation budget controller.”
5. The paper proposes latent classifier-free guidance (CFG) as an alternative to rate-space guidance: it performs CFG by interpolating conditional/unconditional latents (rc and r∅) in continuous space, then uses the guided latent to drive all edit operations jointly—aiming for more globally coherent conditioning than token-wise rate guidance.
6. The latent guidance has a probabilistic interpretation: under Gaussian conditional/unconditional latent encodings and sufficiency assumptions, the guidance direction corresponds to the score of an implicit classifier p(c|r), making the latent interpolation analogous to a gradient ascent step on log p(c|r).
7. Training uses an augmented alignment space with a blank token ε to make edit-based objectives tractable: alignments define edit sequences between endpoints, and a Bregman-divergence-style loss penalizes extraneous rates while rewarding edits that move xt toward x1.
8. DNA enhancer generation (unconditional, length 500) on fly brain and melanoma ATAC-seq datasets: FlexFlow achieves the best Fréchet Biological Distance among compared diffusion/flow baselines at the same sampling budget (100 reverse steps), and ablations indicate combining a frequency-informed prior with structured coupling performs best.
9. Conditional promoter design (human promoters, length 1024) conditioned on transcription initiation profiles: FlexFlow improves MSE of predicted regulatory activity versus prior baselines, with latent guidance outperforming rate guidance (reported 0.022 vs 0.024 MSE at 100 steps), suggesting benefits from global latent steering.
10. A new peptide–MHC II conditional generation benchmark is introduced using eluted ligand data with a strict split where no 9-mer is shared across train/test clusters. On this task, FlexFlow greatly improves a held-out DeepMHCII-based discriminator score (rate guidance 0.58; latent guidance 0.66), while highlighting a quality–diversity tradeoff (latent guidance can improve plausibility while worsening embedding-distance coverage metrics).
📜Paper: arxiv.org/abs/2606.10543
#ComputationalBiology #GenerativeModels #FlowMatching #DiffusionModels #ProteinDesign #DNADesign #PeptideDesign #MHC #MachineLearning #Bioinformatics
3
16
1,431
Jun 9
day 9/30
if you’re fine-tuning diffusion models, your output is only as good as your training captions. but manually labeling 10k images is impossible.
the solution isn’t just running a generic captioning script. you need a highly optimized, scalable auto-captioning pipeline.
here is the blueprint i use to process thousands of images efficiently without blowing up cloud compute:
automated quality filtering: run a script using a clip score or aesthetic predictor first. drop low-resolution or corrupted images before wasting GPU cycles processing them.
hierarchical tagging: combine structural tagging (like deepdanbooru for specific tags/attributes) with a heavy vision-language model (vlm) like joy-caption or florence-2 for descriptive natural language text.
structural pruning: use python scripts to strip out repetitive prefix phrases (like "a photo of...") that dilute token weight during training.
dockerize the pipeline: wrap the data-prep workflow in a clean docker container separate from your training infra. it keeps your environments clean and makes preprocessing easily reproducible.
if you spend 3 days tweaking your training hyperparameters but only 5 minutes on your dataset pipeline, your model is going to output absolute garbage.
how are you guys structuring your data preprocessing pipelines right now? 👇
#DiffusionModels #MLOps #GenAI #BuildInPublic
2
2
21

Entropy-weighted loss yields stronger musical development in diffusion models without mode collapse. Drop-in for existing pipelines. #MusicGeneration #DiffusionModels #MIR arxiv.org/abs/2606.07207v1
8
Text-guided audio editing gets 15.9% better quality and 64.5% faster without inversion. DirectAudioEdit makes audio editing cheaper and quicker. #AudioEditing #DiffusionModels #MIR arxiv.org/abs/2606.07356v1
10

Jun 8
𝗘𝘃𝗲𝗿𝘆𝗼𝗻𝗲 𝘄𝗮𝗻𝘁𝘀 𝟰𝗞 𝗔𝗜. But true native-4K data is still surprisingly scarce.
🚀 Excited to share our new work: 𝟰𝗞𝗟𝗦𝗗𝗕: 𝗔 𝗟𝗮𝗿𝗴𝗲-𝗦𝗰𝗮𝗹𝗲 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗳𝗼𝗿 𝟰𝗞 𝗜𝗺𝗮𝗴𝗲 𝗥𝗲𝘀𝘁𝗼𝗿𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻, accepted to CVPR 2026 DataCV.
Most public datasets are built around sub-1K, HD, or 2K images. But at 4K resolution, small artifacts become big problems: blurry textures, distorted boundaries, repeated patterns, and missing fine details.
To address this gap, we introduce 𝟰𝗞𝗟𝗦𝗗𝗕, a large-scale native-4K dataset and benchmark for high-resolution restoration and generation.
📌 𝟰𝗞𝗟𝗦𝗗𝗕 𝗶𝗻𝗰𝗹𝘂𝗱𝗲𝘀:
✅ 129K native-4K training images
✅ 2K validation images and 1,984 test images
✅ Diverse categories: nature, urban scenes, people, food, artwork, CGI, and more
✅ Aligned 4K image–text pairs for generative modeling
✅ Paired LR/HR evaluation sets for super-resolution
We also build a multi-stage curation pipeline combining resolution filtering, LMM-based quality scoring, texture-richness filtering, and human verification.
Across classical SR, real-world blind SR, and 4K text-to-image generation, fine-tuning on 4KLSDB consistently improves fidelity, local detail, perceptual quality, and human preference.
💡 Main takeaway: 𝗻𝗮𝘁𝗶𝘃𝗲-𝟰𝗞 𝘀𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗶𝗼𝗻 𝗺𝗮𝘁𝘁𝗲𝗿𝘀.
As visual AI moves toward ultra-high-resolution restoration and generation, we need datasets and benchmarks that expose the fine-scale failures hidden by low-resolution evaluation.
📄 𝗣𝗿𝗼𝗷𝗲𝗰𝘁 𝗽𝗮𝗴𝗲: 4klsdb.github.io
💻 𝗚𝗶𝘁𝗛𝘂𝗯: github.com/taco-group/4KLSDB
💽 𝗗𝗮𝘁𝗮𝘀𝗲𝘁: huggingface.co/datasets/Sing…
#ComputerVision #GenerativeAI #ImageRestoration #SuperResolution #TextToImage #DiffusionModels #Dataset #Benchmarking #TAMU

1
8
60
5,036

Excited to share our new preprint: AdvantageFlow, a forward-process RL algorithm for rectified flow models 🎨
RL post-training for text-to-image generation models like Stable Diffusion is hard. Most methods (e.g. Flow-GRPO) optimize along the reverse denoising trajectory, which requires introducing artificial stochasticity and solving a credit assignment problem across many denoising steps.
AdvantageFlow sidesteps both problems entirely.
The key idea: sample images, score them with rewards, compute advantages (how much better/worse each image is vs. the batch average), and train using the same forward-process prediction loss as pretraining, just reweighted by advantages.
The catch: negative advantages make the loss non-convex and optimization unstable. We fix this with rollout policy regularization, which also has a clean theoretical justification. It arises naturally as a variance reduction step when fitting a locally reward-improving target distribution.
Results on Stable Diffusion 3.5 Medium:
✅ Outperforms Flow-GRPO across all benchmarks
✅ Matches DiffusionNFT's best reward in half the training time
✅ Improves text rendering, object counting, color and position understanding without classifier-free guidance
Simple algorithm. Strong theory. Better empirics.
ArXiv: arxiv.org/pdf/2605.26013
Work with Branislav Kveton, Anup Rao, Krishna Kumar Singh, and Viet Lai at Adobe Research.
#GenerativeAI #ReinforcementLearning #DiffusionModels #AdobeResearch

1
69
Jun 7
When recruiters search for candidates, they filter out 90% of applicants because they look like "hobbyists" who only know how to call an OpenAI API. This 7-day sequence completely destroys that perception by demonstrating five core traits of a senior-minded engineer:
You can just follow me to build the Mindset that company looks:
Recap:
Day 1: The Foundation & Credibility
2 years in the ML trenches and the biggest realization? the math is cool but fighting CUDA out-of-memory errors and optimizing pipeline latency is where the real battle is lolgonna start sharing daily raw dev notes here—everything from scaling diffusion models and lora fine-tuning to optimizations that actually save compute costs.day 1/30. if you’re building in the genai space, let’s connect 🚀#mlops #genai #ai #buildinpublic
Day 2: The Cost & Efficiency Angle
day 2/30everyone loves talking about training models, but nobody talks about the absolute nightmare of scaling inference pipelines in production without burning through cloud budgets.spent a lot of time optimizing heavy genai and image synthesis models. the secret isn't just throwing more expensive gpus at the problem. it’s about aggressive quantization, smart memory management, and containerizing the infra so it scales down when idle.if your production pipeline is eating up all your compute, you’re doing it wrong lol#MLOps #GenAI #BuildInPublic
Day 3: The Complex Architecture Hook
day 3/30everyone wants to talk about prompt engineering, but if you’re actually building autonomous systems, the real challenge is dealing with agent state management and tool-calling latency.it’s one thing to get an llm to output a clean json payload in a notebook. it’s a completely different beast when you deploy multi-agent loops in production and have to handle race conditions, token limits, and broken api dependencies without the whole system crashing.reliable agents require strict orchestration layers, not just clever system prompts lol#LLMOps #AIAgents #GenAI
Day 4: Deep Niche Problem Solving
day 4/30if you’re working with diffusion models, you quickly learn that fine-tuning a lora is the easy part. the real nightmare is making sure it doesn't break the base model.you train it to get a perfect style, and suddenly the model forgets how to render basic human hands or backgrounds lolfixing this in production comes down to clean data and strict regularization, not just praying for a good checkpoint.if you’ve dealt with this, how do you handle dataset balancing? let me know 👇#DiffusionModels #GenAI #MLOps
Day 5: Real-World Pragmatism
day 5/30everyone is trying to build the next big ai app, but nobody wants to talk about how painful it is to maintain clean data pipelines for training.you can have the most advanced model architecture in the world, but if your dataset is filled with duplicate images, bad captions, or low-quality data, your model will output absolute garbage.in production, spending 80% of your time on data cleaning and preprocessing isn't a meme, it is the literal job. building automated filtering scripts saves way more compute than tweaking hyperparameters ever will.what is your biggest bottleneck when preparing data for fine-tuning?#MachineLearning #GenAI #MLOps #BuildInPublic
Day 6: The Industry Call-Out (Viral Hook)
day 6/30unpopular opinion: the ai/ml space has a major proof-of-concept problem.building a wrapper app or a cool prototype takes a weekend. but taking that prototype and turning it into a real, reliable production system that doesn't break under load is what separates junior devs from actual engineers.if you aren't thinking about model quantization, caching strategies, and strict latency budgets from day one, your app will fall apart the moment it gets real user traffic.stop chasing the hype of new model drops and focus on building robust infrastructure that actually scales.agree or disagree? let’s talk in the comments 👇#MachineLearning #MLOps #GenAI #BuildInPublic
Day 7: The Advanced FinOps Mindset
day 7/30everyone is rushing to build multi-agent workflows, but the biggest bottleneck nobody is talking about is token cost and latency compounding.when you chain three or four agents together, a single user request turns into ten different internal llm calls. if your agents are passing massive, unoptimized system prompts and entire conversation histories back and forth, you’re just lighting money on fire.building reliable agents isn't about making them "smarter" with longer prompts. it’s about aggressive context pruning, custom semantic caching, and knowing exactly when to hardcode a rule instead of letting the model guess.efficiency is going to separate the viable ai products from the bankrupt ones real soon.how are you guys optimizing token usage in your orchestration layers? 👇#LLMOps #AIAgents #GenAI #BuildInPublic
1
2
2
167

Pixel Cube: Diffusion-based Portrait Video Relighting Through Realistic Lighting Reproduction
👥 Yufan Zhang, Yu Ji, Ayo Ajiboye et al.
#AIResearch #ComputerVision #DiffusionModels #VideoRelighting
🔗 trendtoknow.ai/paper-reviews…

11
AlloGen: Conformation-Selective Binder Generation with Differential State Scoring
1. AlloGen targets a core limitation in protein binder design: optimizing affinity to a single receptor structure can yield binders that engage both active/inactive (apo/holo) states, providing little functional specificity for allosteric systems (kinases, nuclear receptors, GPCRs).
2. The framework decouples generation from evaluation: any backbone generator proposes candidates for the desired state, then a learned scorer Qθ ranks or guides designs by a differential selectivity margin between goal (holo) and undesired (apo) conformations.
3. Qθ is an SE(3)-invariant interface graph transformer that scores receptor–binder interface geometry in a rigid-motion-invariant way, using interface graphs (8 Å cutoff) with residue-local frames, geometric edge features (distance RBFs, directions, relative orientations), and optional ESM-2 embeddings.
4. Training uses a two-phase curriculum to avoid degenerate “ignore-the-conformation” solutions: Phase 1 regresses to DockQ (interface quality grounding), then Phase 2 applies paired InfoNCE fine-tuning on (holo, apo, binder) triplets with cross-target negatives to force true conformational discrimination rather than receptor identity bias.
5. On 8 held-out OOD targets, Qθ shows consistent rank correlation with DockQ (mean Spearman ρ ≈ 0.520), while contact/energy proxies (PRODIGY, interface size, edge density) largely fail to track docking quality and cannot provide a differential state signal.
6. Qθ appears to encode target- and conformation-specific information: cross-target scoring shows strong diagonal dominance (designs score best on their intended target/state), and on calmodulin it produces a monotonic score increase along an interpolated apo→holo conformational path, suggesting it learns a continuous landscape rather than a binary label.
7. Because Qθ is differentiable and generator-agnostic, it supports multiple integration modes without retraining generators: passive best-of-K reranking and active guidance (classifier guidance, twisted diffusion sampling, SMC resampling, and post-generation Langevin refinement).
8. Across 15 generator×guidance combinations (RFdiffusion, PXDesign, Proteina-ComplexA), resampling-based guidance (TDS/SMC) is broadly strongest; Langevin refinement helps structure-only generators but can harm sequence-aware priors (e.g., PXDesign), emphasizing that guidance interacts with generator assumptions.
9. Experimental validation on calmodulin (a challenging ~30 Å apo↔holo rearrangement) supports the computational selectivity signal: 5/10 synthesized de novo peptides bound holo CaM (KD 46.6 nM to 1.06 µM) with no detectable apo binding, while a low-∆q negative control showed no binding—linking predicted differential scoring to measurable state specificity.
10. The study positions conformational selectivity as a learnable, transferable design objective: a modular scorer trained on paired states can retrofit existing binder-generation pipelines to design molecules that recognize functional states rather than static structures.
💻Code: huggingface.co/ChatterjeeLab…
📜Paper: arxiv.org/abs/2606.05474
#ComputationalBiology #ProteinDesign #GenerativeAI #MachineLearning #StructuralBiology #Allostery #ProteinEngineering #DiffusionModels #GNN #Calmodulin

7
35
2,386

Jun 5
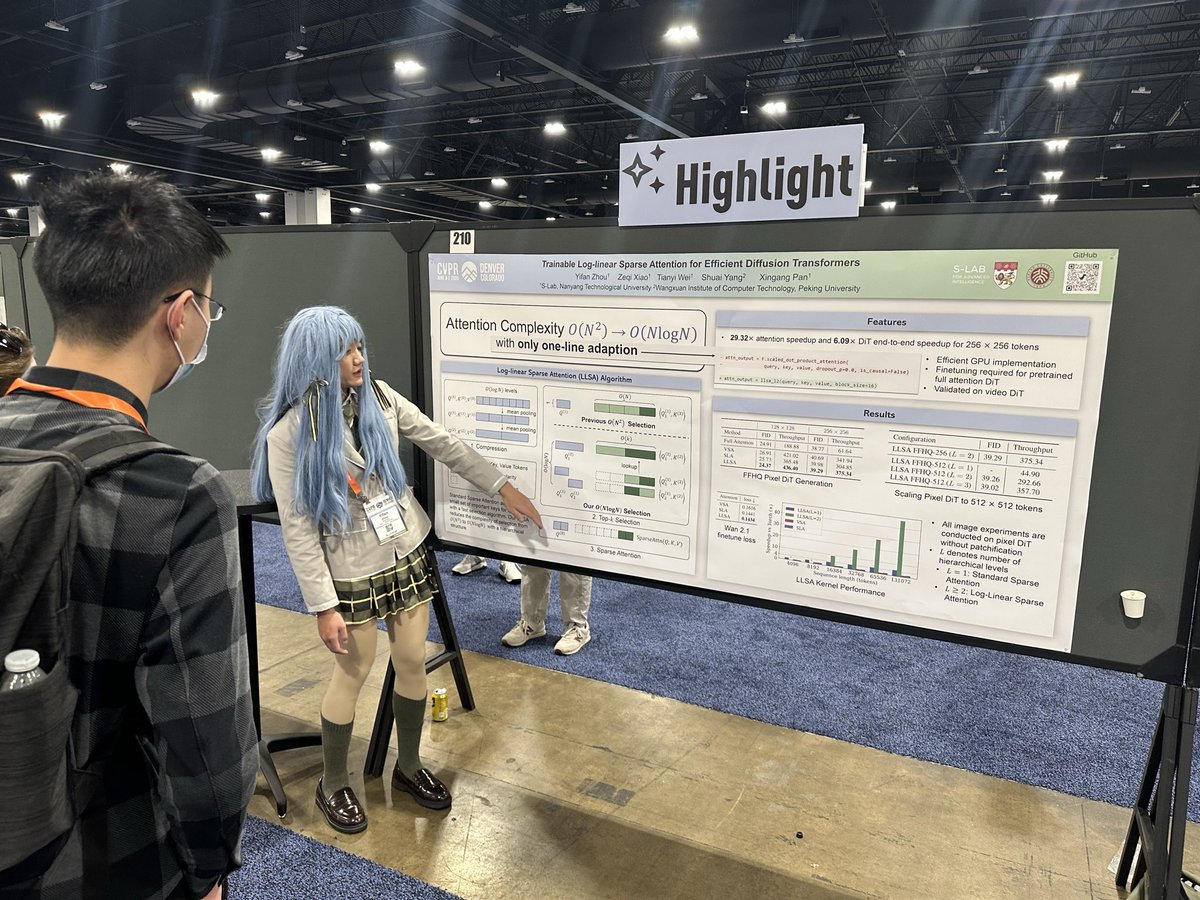
Proud to share our lab’s @MMLabNTU work Log-linear Sparse Attention (LLSA) - a trainable sparse attention mechanism that reduces attention complexity from O(N²) to O(N log N), making diffusion transformers much more efficient.
Also, special shout-out to the first author @zhouyifan1107 for presenting the poster in full costume - truly above and beyond. The level of dedication is impressive! 👏
#CVPR2026 #DiffusionModels #EfficientAI #SparseAttention

14
87
826
101,158

9/ Project page:
amirhossein-kz.github.io/fac…
Paper:
arxiv.org/abs/2603.16570
#ComputerVision #ImageRestoration #DiffusionModels #FaceRestoration #CVPR2026
3
74
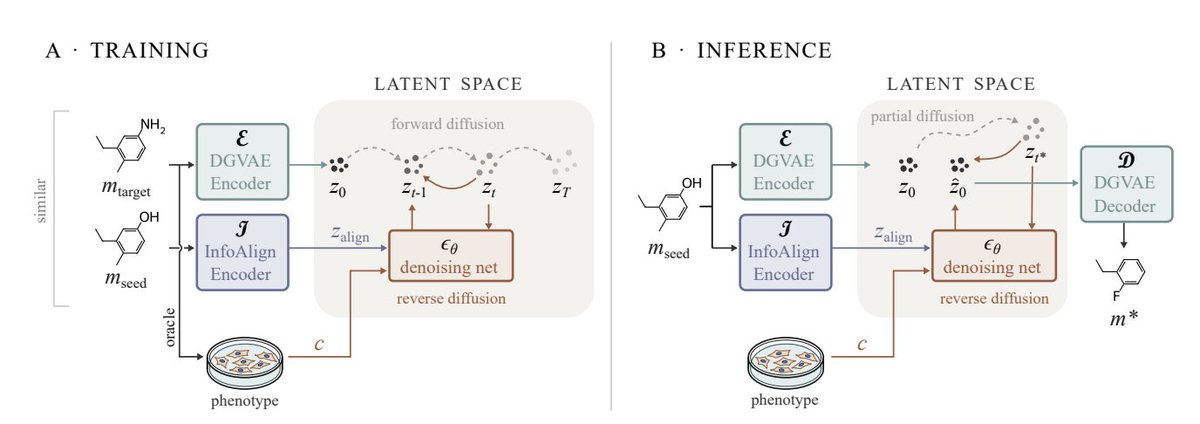
PhAME: Phenotype-Aware Molecular Editing via Latent Diffusion
1. PhAME frames hit-to-lead as latent-space editing that can simultaneously (a) steer molecules toward high-dimensional phenotypic targets (transcriptomics or cell morphology) and (b) keep outputs close to a known seed—two requirements that prior phenotype-conditioned generators and standard diffusion guidance typically cannot satisfy at once.
2. The key technical idea is compositional classifier-free guidance with two independent knobs: wc for phenotype conditioning and wa for seed anchoring. Instead of a single CFG scale that forces an implicit trade-off, PhAME decomposes guidance into separate phenotype and alignment directions, letting practitioners tune property/phenotype improvement vs. structural conservatism explicitly.
3. Architecture: a frozen graph-based VAE (DGVAE) defines a continuous latent space for molecules; diffusion happens only in this latent space. The model conditions on (i) the target signature c and (ii) an anchoring embedding zalign computed from InfoAlign, which is trained to align molecular structure with both Cell Painting and L1000 signals, so “similarity” is biased toward phenotype-relevant chemistry rather than only fingerprint similarity.
4. Editing mechanism: encode a seed molecule, partially diffuse it to a chosen noise level t* (controlling exploration radius), then denoise under compositional guidance. This provides two complementary controls: t* sets how far the model can drift structurally, while (wc, wa) controls the phenotype-vs-structure pull during denoising.
5. Training strategy: construct paired examples across a threshold (e.g., low vs high logP, weak vs strong docking score) by matching molecules across partitions via nearest-neighbor Tanimoto similarity. The diffusion model learns transformations that cross the threshold while preserving similarity. An additional alignment loss enforces that predicted latents remain close to a projection of zalign, improving seed preservation.
6. Controlled property editing (MOSES logP): compared to Mol-CycleGAN, DiGress, and PURE, PhAME achieves the best NTS (Novelty × Target success × Similarity), indicating a better overall balance. Ablations show the expected behavior: increasing wc boosts target success; increasing wa boosts similarity but can reduce optimization strength; removing the alignment loss reduces similarity and overall NTS.
7. Docking-score optimization (MOOD-style benchmark on ZINC250k; PARP1, FA7, 5HT1B, BRAF, JAK2): PhAME achieves the best “novel top 5% docking score” on all five targets and the best novel hit ratio on 4/5 targets under strict novelty and quality filters (QED>0.5, SA<5, max Tanimoto-to-train <0.4). Gains are attributed largely to a three-stage curriculum that progressively tightens binder/non-binder thresholds; a single-stage variant collapses hit rate (shown on FA7).
8. Transcriptomics-guided generation (LINCS L1000, MCF7): conditioned only on target-specific perturbation profiles (knockdown for inhibitors; overexpression for activators), PhAME generates molecules with stronger similarity to known ligands for 8/10 targets versus TRIOMPHE, GxVAE, and SmilesGEN, while also improving molecular quality (higher QED, lower SA) and avoiding memorization (perfect novelty/uniqueness in their evaluation).
9. Cell Painting phenotype → MoA generation (JUMP Cell Painting): in de novo mode, PhAME conditions on MoA-specific morphology centroids and is evaluated via retrieval/classification against reference compounds across multiple representation spaces (ECFP fingerprints, CLOOME, InfoAlign). PhAME is the only evaluated method that consistently clears chance across all spaces and metrics, suggesting MoA-relevant signal capture rather than overfitting to a single embedding. In editing mode, it can recover known drugs (e.g., aspirin, clofibrate, dyphylline) when seeded with similar hits and guided by MoA centroids.
💻Code: github.com/gmum/PhAME
📜Paper: arxiv.org/abs/2605.28226
#ComputationalBiology #DrugDiscovery #DiffusionModels #MolecularGeneration #PhenotypicScreening #CellPainting #Transcriptomics #GenerativeAI #Cheminformatics
6
16
1,422

May 29
Going to #CVPR2026. Great to catch up with old friends and meet new friends.
Talk 1: diffusion post-training in AIMS workshop sites.google.com/view/aims20…
Talk 2: REPA-E and NanoGen in EDGE workshop cvpr26-edge.github.io/
DM for ☕️ chat. #CVPR2026 #GenerativeAI #DiffusionModels
1
9
512
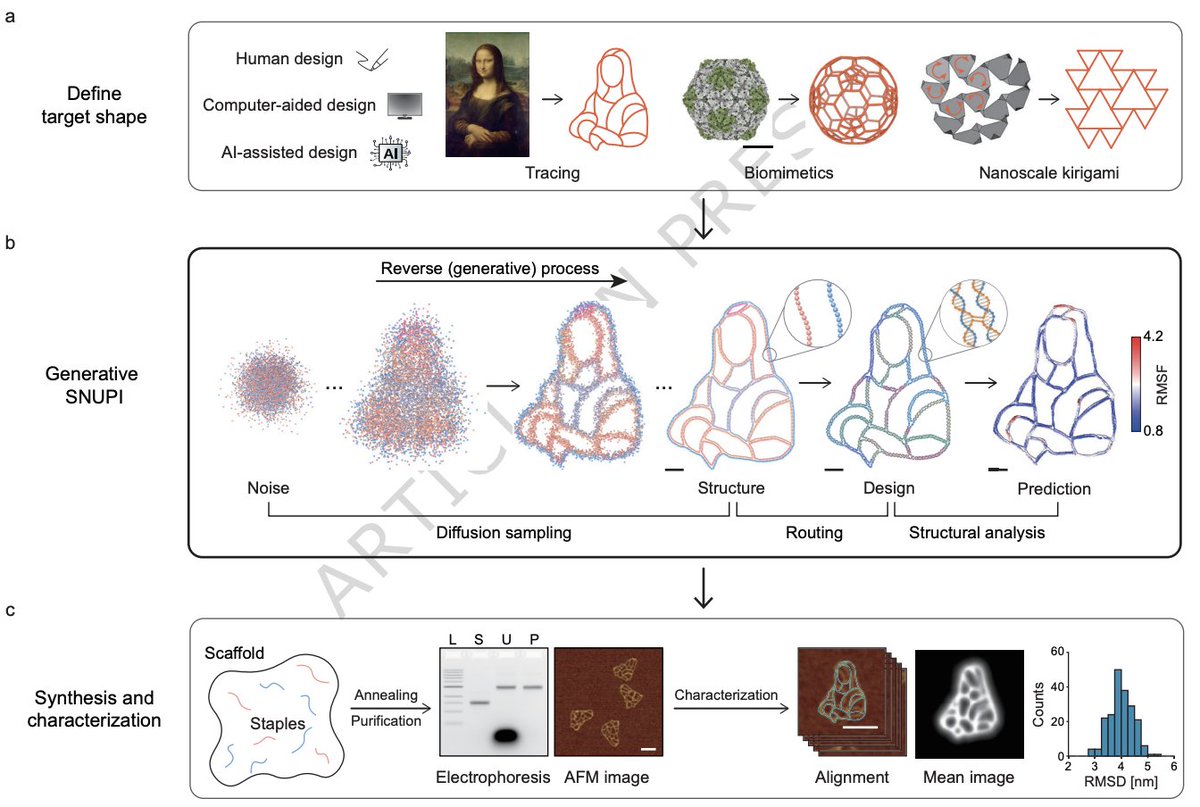
De novo design of DNA origami with a generative diffusion model
1 Generative SNUPI introduces diffusion-model-based inverse design for DNA origami: given a user-defined line-based target geometry, it generates base-pair-level 3D structures that are physically plausible, then automatically produces scaffold routing and staple sequences for experimental fabrication.
2 A key bottleneck in generative DNA origami—lack of large standardized structural datasets—is addressed by training on simulated equilibrium conformations: 450 wireframe 2HB designs (216 2D, 234 3D) whose base-pair coordinates were generated with the SNUPI multiscale model.
3 The generative core is a denoising diffusion probabilistic model operating on base-pair coordinates as a point-cloud-like representation, implemented with a scalable graph Transformer using random graph construction and SE(3)-aware geometric handling to avoid alignment during training.
4 To follow a target shape, the model uses conditional guidance based on optimal transport: classifier-style gradients derived from Wasserstein Distance (WD) bias diffusion sampling so generated structures converge toward the provided geometry, improving shape fidelity and routing success.
5 Across 100 diverse conditional generations (hundreds to ~15,000 base pairs), the WD to the target drops from widely varying initial values (192.69–2178.54 nm) to a low final average of 2.21 ± 1.32 nm, indicating consistent convergence to the intended geometry across sizes and complexities.
6 The pipeline goes beyond shape generation by integrating a deterministic routing program: generated geometries are converted into loop representations, spanning trees, scaffold routes, and staple sets (20–60 nt), with bond-length regularization (0.34 ± 0.05 nm), and export to atomic models via CNDO → oxDNA → PDB post-processing.
7 Generative SNUPI also embeds fast, in-workflow physics evaluation using SNUPI-based simulation to predict equilibrium shapes and flexibility (RMSD, RMSF) without heavy molecular dynamics; for 100 designs, many cluster around RMSD 2.49 ± 1.29 nm and average RMSF 1.72 ± 0.15 nm, enabling pre-experimental screening.
8 Experimental validation shows the simulation-guided design loop is actionable: a “Face 1” dog design predicted to have locally high RMSF folds with high monomer yield yet shows AFM distortion; adding edges to stiffen flexible regions (“Face 2”) improves AFM agreement and reduces RMSD (4.07 ± 0.48 nm to 3.45 ± 0.35 nm).
9 The framework supports functional free-form mechanics and assembly: auxetic metastructures (rotating triangle, re-entrant) are designed and experimentally transformed open→closed using junction gaps plus site-specific connectors, achieving mean enclosed-area reductions of 34.9% and 47.3%; modular dog face/body components with matched curved interfaces assemble into dimers with >65% yield across combinations.
💻Code: github.com/SSDL-SNU/Generati…
📜Paper: doi.org/10.1038/s41467-026-7…
#DNANanotechnology #DNAOrigami #GenerativeAI #DiffusionModels #InverseDesign #ComputationalBiology #Biophysics #Nanorobotics #StructuralBiology #MachineLearning
17
66
13,327
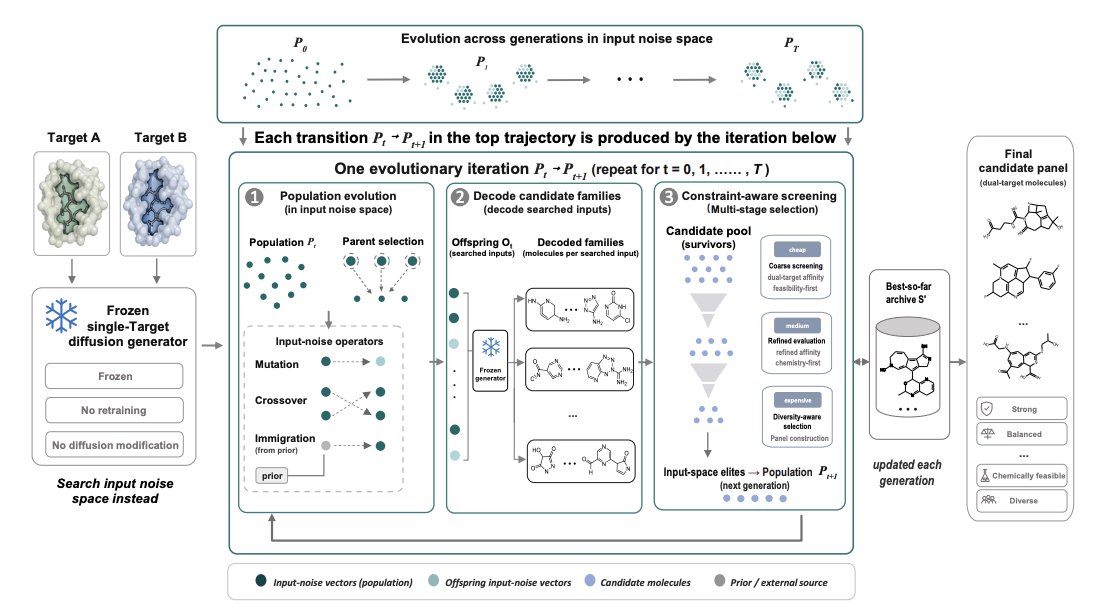
Don’t Retrain, Just Reuse: Recovering Dual-Target Molecules from Single-Target Diffusion Models
1. The paper asks a practical question in structure-based drug design: instead of retraining or adding sampling-time guidance for dual-target generation, can dual-target ligands be recovered by searching the input noise space of a frozen single-target diffusion model, keeping both parameters and denoising dynamics unchanged?
2. It formalizes dual-target design as constrained multi-objective optimization over searched noise inputs and a final candidate panel, jointly optimizing (i) dual-target affinity with explicit balance, (ii) chemical quality (drug-likeness and synthesizability), and (iii) set-level diversity, under hard feasibility constraints.
3. The proposed method, REUSE, is a hierarchical evolutionary search in the generator’s input noise space: maintain a population of noise vectors, generate offspring via mutation/crossover/immigration, decode each noise vector into a small “molecular family,” and use family-level evidence (not a single sample) to score and evolve the population toward regions that reliably yield dual-target candidates.
4. A key design choice is family-based fitness: each noise input is evaluated by aggregating scores of the top-ranked molecules within its decoded family, reducing sensitivity to stochastic decoding and favoring noise regions that consistently produce good candidates rather than one-off lucky samples.
5. REUSE uses cost-aware multi-stage environmental selection (coarse-to-fine): cheap docking/chemistry proxies first filter large pools with feasibility-first ranking, then expensive high-fidelity docking is applied only to a reduced frontier; final output is a diverse panel (not a single molecule), with explicit similarity constraints to avoid redundancy.
6. Balance is enforced directly in the affinity objective using a penalty on cross-target score disparity, discouraging “one-target-only” solutions; chemistry control is incorporated via QED/SA-based terms plus hard floors, so optimization does not collapse into unrealistic high-docking-score artifacts.
7. On the Zhou et al. dual-target benchmark (12,917 target pairs, 438 targets), using TargetDiff as the frozen backbone, REUSE achieves the best reported docking-centered dual-target metrics: best average P-2 Vina Dock (-9.26), best Max Vina Dock (-8.64), and highest Dual High Affinity rate (58.3%), improving Dual High Affinity by 20.9 percentage points over the strongest prior baseline (MDRL).
8. Ablations isolate failure modes: removing input-space search sharply degrades dual-target recovery (Dual High Affinity 58.3% → 31.8%); removing balance hurts cross-target consistency; removing chemistry control can slightly improve docking but substantially worsens QED/SA, highlighting why multi-objective constraints matter.
9. The paper provides evidence that the frozen input space has exploitable local structure: high-quality noise “anchors” tend to have enriched high-quality neighbors, supporting why evolutionary local exploration (mutation) can work better than naive random sampling.
📜Paper: arxiv.org/abs/2605.25681
#ComputationalBiology #MachineLearning #DiffusionModels #DrugDiscovery #Polypharmacology #StructureBasedDrugDesign #MolecularGeneration #MultiObjectiveOptimization #EvolutionaryAlgorithms
8
18
1,647