
CEO @MinuteBox | AI for corporate and transactional legal teams #legaltech
Joined April 2008
- Tweets 200
- Following 207
- Followers 904
- Likes 4,603
11 Photos and videos










CEOs doing everything they can to cut AI spend

Jesus it keeps getting worse.
What would be the strategy behind Amazon’s CEO telling Trump to worry about Fable/Mythos?
94
Apple out here playing 4D chess building Siri on models that will never get banned.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
53

Jun 11
“Their” is doing a lot of work in this sentence
Jun 8

Large law firms are meeting the AI moment with a new strategy: use that advanced tech to mobilize their rich, internal data trove as a competitive advantage. news.bloomberglaw.com/legal-…
1
3
25
6,406
Jun 11
Be wary of this analysis if you rely on ZDR for data residency or jurisdictional processing reasons.
Moreover, for enterprise, be mindful of specific GC guidelines in enterprise that only allow processing with ZDR.
Finally, don’t assume that the same encryption at rest and in transit apply to observability logs on prompts, inference etc as apply to, say, storing files on cloud services like Dropbox etc.
Jun 11

1/ Some are questioning whether lawyers can safely use Claude Fable 5 for legal work. I run an AI-native litigation practice and have studied this issue. The short answer: Yes, Fable 5 is generally safe for ordinary litigation work.
2
433
Jun 11
Wow, Claude Fable 5 is incredible.
I asked it to create a world-class entity management and governance product. It cranked for about 15m22s and it one-shotted this.
Anthropic totally cooked on this one!
71
Jun 9
I believe a 2019 double-blind placebo-controlled study proved there is, indeed, a way

is there any proven way to make time go slower?
1
1
137
Jun 9
"Constructive development"

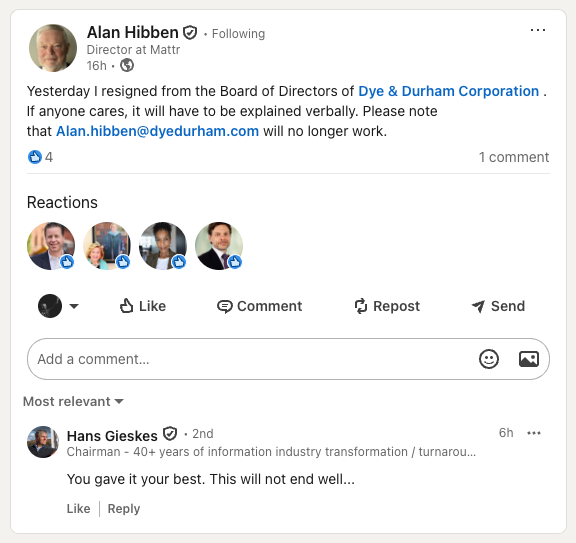
Board Update - Dye and Durham $DND.TO / $DYNDF
Alan Hibben’s just resigned from the Board.
I actually view this as a constructive development, not a negative one.
Hibben stepped in as Chair late last year during a turbulent period (activist pressure, strategic review).
He helped stabilize governance, pushed for the Sales Process, and even put his own money in (buying ~61k shares in Feb at $2.67–$3.45).
His job there looks largely done.
Nov 20, 2025: Hibben joined the board and was appointed Independent Chair.
Early 2026: The board was refreshed (part of the settlement with OneMove / Tyler Proud). Edward Smith became Chair for a period.
By May 2026 (latest Management Information Circular dated May 6): Mary Filipelli (M&A Specialist) joins as the Chair of the Board.
Today: Hibben resigned as a director (not as Chair - he had already stepped down from that role earlier).
Now that Tyler Proud is on the board and the Sales Process is deep in due diligence, the board is likely streamlining to be leaner and more focused for the final stages (second-round bids, exclusivity, carve-out negotiations).
This is common in live M&A situations - companies often refresh the board to align it tightly with the transaction phase.
There’s zero indication of any beef with the Proud brothers. Plantro and OneMove have been supportive of the process (they’re voting FOR the poison pill tomorrow), and Hibben’s resignation was clean with no public disagreement.
If there was real conflict, we would have seen it disclosed.
Net effect:
- The board is getting transaction-ready.
- The Sales Process continues uninterrupted, and the core thesis (credible first-round bids and carve-out) remains intact.
- This is housekeeping.
- The stock is still ridiculously cheap relative to the bids that already exist.
I'll be adding more on any weakness.
2
454
Jun 7
This is from the Tirami region of northern Italy.
It’s only Tiramisu if it comes from this region. Otherwise, it’s just coffee-soaked ladyfinger dessert.


1
3
187
Jun 7
Engineers push back against lines of code like writers push back on word count or support team on tickets closed.
Goodhart’s law is real but doesn’t disqualify measuring output.
Data is a canary. It’s useful but how you use it is and the conclusions you draw are far more important.
Jun 7

LoC gets too much hate. When you start a project it has 0 LoC. When it’s done it will have >0 LoC. At 3 month granularity LoC should trend line up and to the right.
There is signal in LoC and you get the metric for free. It’s worth taking a look at occasionally.
140
Jun 6
This is very true.
The problem is that most people don’t expect computers to make mistakes. And AI is computers, after all.
They don’t understand this as a fundamental property of large language models.
Most people have no concept of probabilistic computer technology. It didn’t exist in the consumer space until ChatGPT.
So when AI produces a hallucination, people evaluate this the same way they evaluate an Excel formula being wrong. Because AI and Excel are the same thing. They’re computers.
Then they conclude that AI isn’t good enough yet or can’t be trusted because it makes mistakes and computers don’t make mistakes. They view it as disqualifying of the technology.
It is a fundamental misattribution error.
It’s also confirmation bias.
People do expect to find mistakes in human work. So we find them and under-index on them by treating human error as normal or expected. It’s just human-error, after all.
This will change over time as people begin to better understand LLMs and as adoption increases. It will take people like @scottastevenson @willchen500 @gordon_cassie @StevePulver pointing this out and building great technology.

However bad you think AI hallucinations are in law, I promise you that human hallucinations are worse
And AI is really good at catching human hallucinations
(from a document filed to the SEC by a major bank)

1
1
11
1,461
Jun 6
People on X are talking like AI has fully saturated legal. Not so.
I talk to around 30 legal professionals a week. Here are the most common comments on legal AI:
- I’m worried about hallucinations
- I’m not sure what to use it for
- I’ve tried it for writing emails
- I don’t trust it
Does this sound like an industry with no alpha left?
There is so much opportunity in legal with AI.
8
5
46
3,150
Jun 5
Makes me feel better about our GCP bill

BREAKING; SpaceX and Google enter a cloud service agreement through which Google has agreed to pay SpaceX $920 million per month from October 2026 to June 2029.
Compute capacity provided includes about 110,000 Nvidia GPUs, CPUs, memory and other related components
1
195
Jun 5
To summarize, @paulg aims to write with such high information density that summarizing it inevitably loses important ideas.
Jun 5

I strive to make my writing unsummarizable, in the sense that it has so little fluff left in it that if you take any words out, as summaries by definition do, you lose a lot of interesting ideas.
2
223
Jun 5
If you are on X a lot, it might seem every lawyer is operating a fleet of agents.
I've presented to more than 1000 legal professionals in the last 90 days.
Very few are using AI. Even fewer are using it in any meaningful way.
There's still so much alpha.

I think that boat has left the dock
7
2
55
11,054
Jun 5
Propriety of the data is as much, if not more, a concern, than confidentiality.
If Harvey and its sub-processors can process the data then there is no further confidentiality issue to training (except insofar as there are concerns about training data being regurgitated by the model as inference). Fair enough.
But there is a bigger question around propriety. A great deal of records that the firm has are not work-product of the firm. The firm has no license, right or title to use the records for training, whereas they do have (maybe) license to process the records when using them in provisioning legal services.
Not enough firms are talking about this.
Jun 5

Our goal isn’t to get a data advantage over our law firm clients and even if we wanted to we can’t for exactly the reason you described - the majority of their data is actually client data so even a law firm like Kirkland can’t take all that data and train a model on it bc it would break confidentiality.
The two things firms can do are 1) firm-specific models - encode all of your firm knowledge in client agnostic ways to train models (templates, deal points, using your lawyers feedback on non-client data, disentangle your firm’s trajectories from client data, etc) and 2) client-specific models - for deep enough client relationships work with your client to build a joint model where both parties benefit from converting the relationship into AI. This is especially good for firms with long lasting relationships with their clients to make those relationships stickier.
The best way to train either of these models is building a product that centralizes the entire client matter process (i.e. allows you to do an acquisition end-to-end and capture the entire trajectory and feedback across the entire team of associates, partners, client). These products will be specialized by practice area (M&A completely different from fund formation which is completely different from IP litigation). Without something like this it’s very hard to get meaningful signals from individual associate queries on a chat based product. We think this general product / infra will be shared across firms but then highly customized and the customizations and data will be owned by the law firms and their clients.
Another problem we want to help law firms and their clients solve is how do you manage client data at scale when you are doing this type of training? The Fortune 500 customers we work with already struggle with professional services providers and data security because most of the work is done over email, downloaded onto desktops and printed out. And it’s not the law firm’s fault - they need to stitch together many different products to support all the needs of their clients' regulatory and security requirements. This is already a huge challenge and model training on top of this is going to make things infinitely more complicated.
We’re building a collaborative platform (shared spaces) that allows law firms and clients to securely share data on client matters and build custom agents for their clients in a secure way. Eventually this will become infrastructure that allows firms to train client-specific models and for clients to have the piece of mind that the data they are sharing is isolated from other clients and it’s being used to their exclusive benefit. I think this is a good example of a very vertical product that it probably doesn’t make sense for a single law firm or model provider to build.
So I agree there isn’t a market for laptops for lawyers but I think there probably is for infrastructure that enables enterprises to manage all their internal and external legal spend, workforce, agents, processes and the same for law firms. Compute is a great moat but in the cloud era most SAAS companies didn’t build datacenters and many were still wildly successful by building on top of the cloud providers. I think we will see the same thing in the next decade as well with respect to model providers.
144
Jun 4
Firms typically have all their valuable precedents and institutional knowledge in a shared drive or DM available to all lawyers and then each lawyer has their actual valuable and up to date stuff on a personal drive shared with no one.
Every biglaw lawyer knows this. Whether the latter is actually valuable is another question.

So many firms are convinced that they have decades of valuable data. A lot of consultants have told them this is the case because it’s what they wanted to hear.
And 99 times out of 100 it’s not true.
3
216
Jun 4
—
Jun 4

AI for all Canadians — governed by Canadian values.
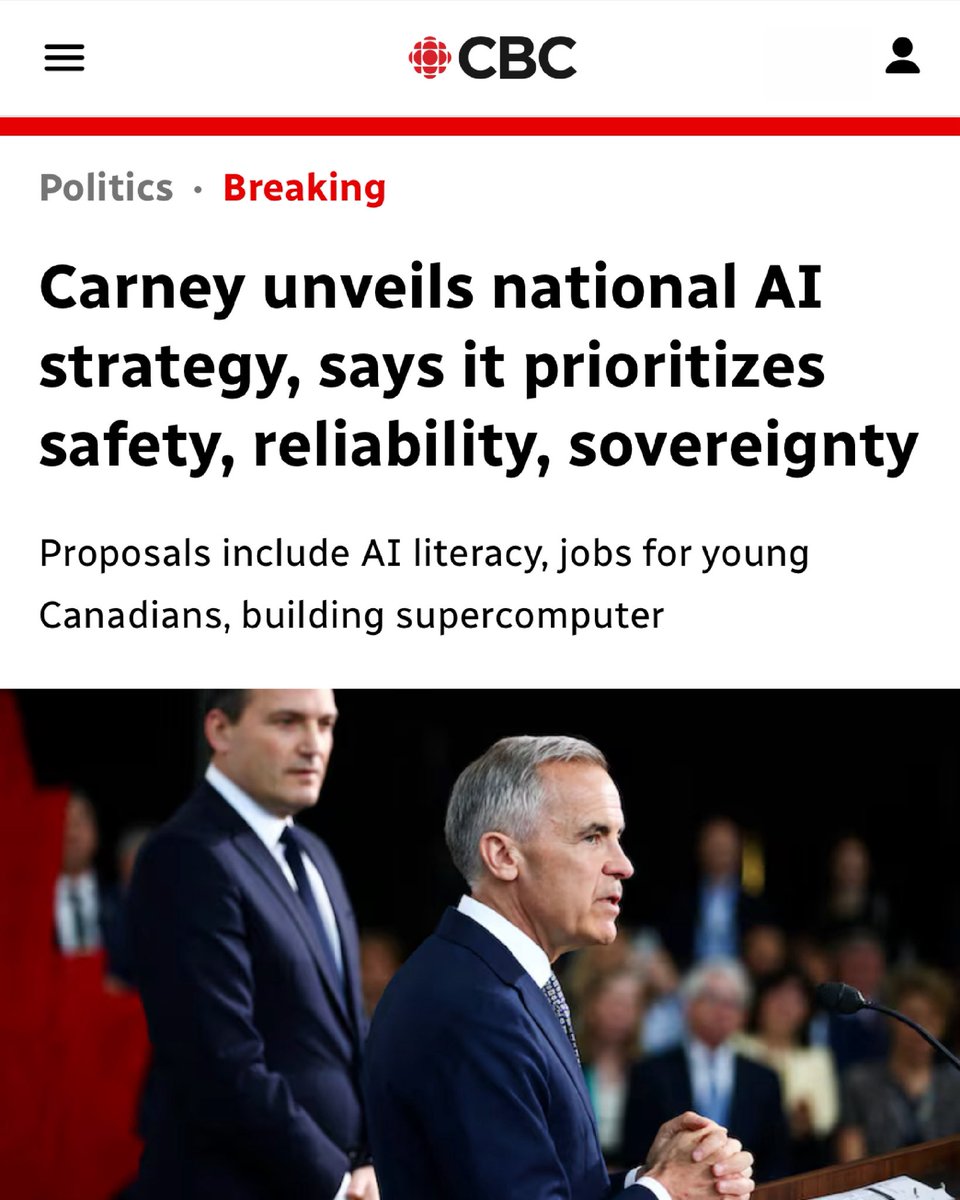
ALT New article that reads: Carney unveils national AI strategy, says it prioritizes safety, reliability, sovereignty
67
Jun 4
Fractional reserve banking
Jun 4

AI wrappers which are in essence token resellers exist as a brilliant form of financial engineering.
They have created significant paper wealth simply by accounting for token pass-through as ARR.
When token spend passes through a reseller, it supports the valuations of both the reseller and the model provider, doubling the amount of wealth creation on paper, even though almost all of the wrapper’s revenue is ultimately paid to the model provider.
89
Jun 3
Everyone knows the best way to leak is to sign an NDA and give a VC access to your data room
Jun 3

No matter how many times people tweet about it, I still don’t think founders realize how much VCs talk to each other.
1
246