
AI Engineer at Zapier
Joined June 2019
- Tweets 85
- Following 9
- Followers 53
- Likes 62
9 Photos and videos


Pinned Tweet

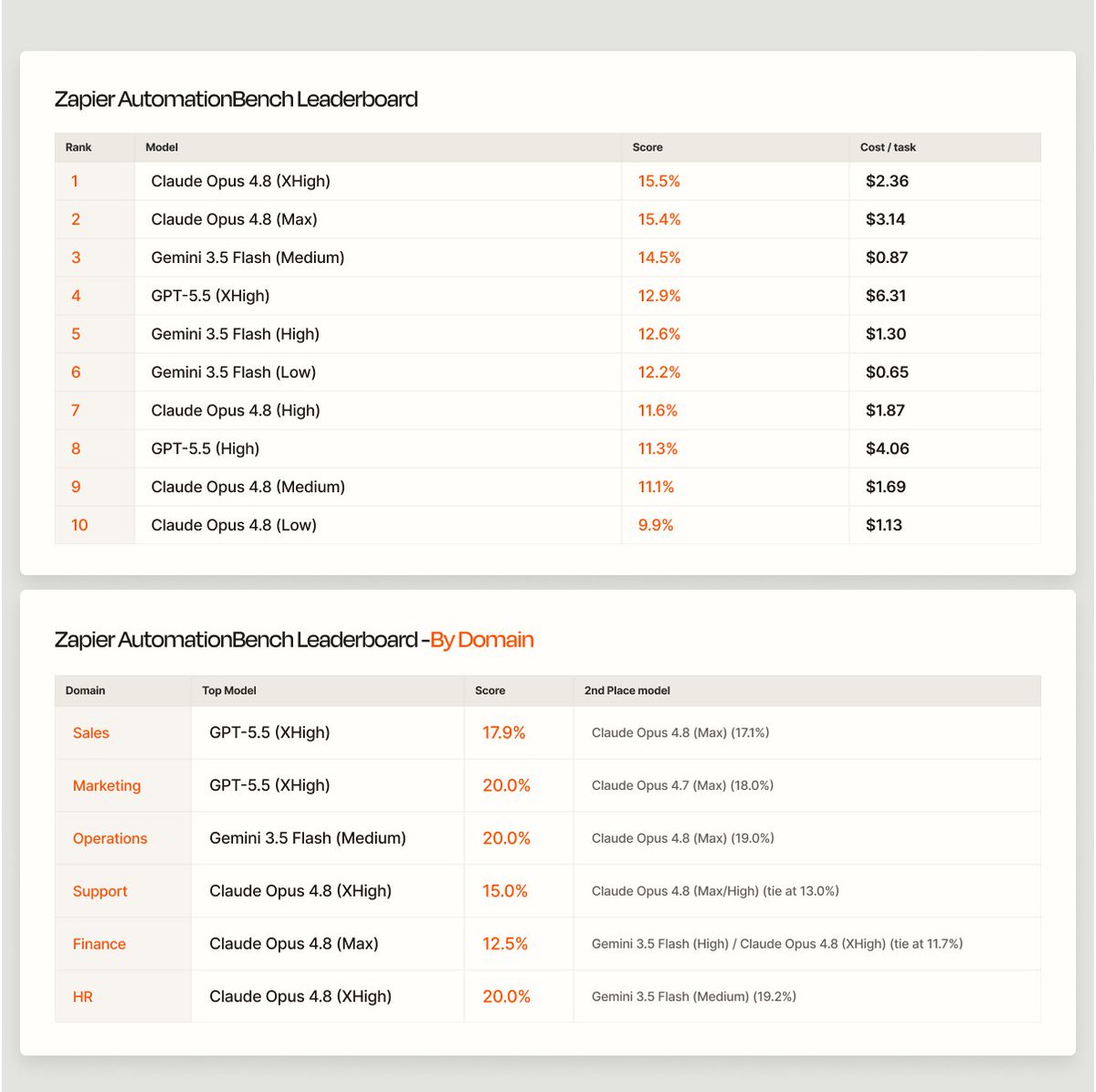
The last few months I have been working on a new Benchmark.
Introducing AutomationBench. Trying to measure the cutting edge of model's capabilities in real world business workflows across multiple apps and noisy data.
The best models haven't beat 10% yet.
2
4
648
Daniel Shepard retweeted

Jun 9
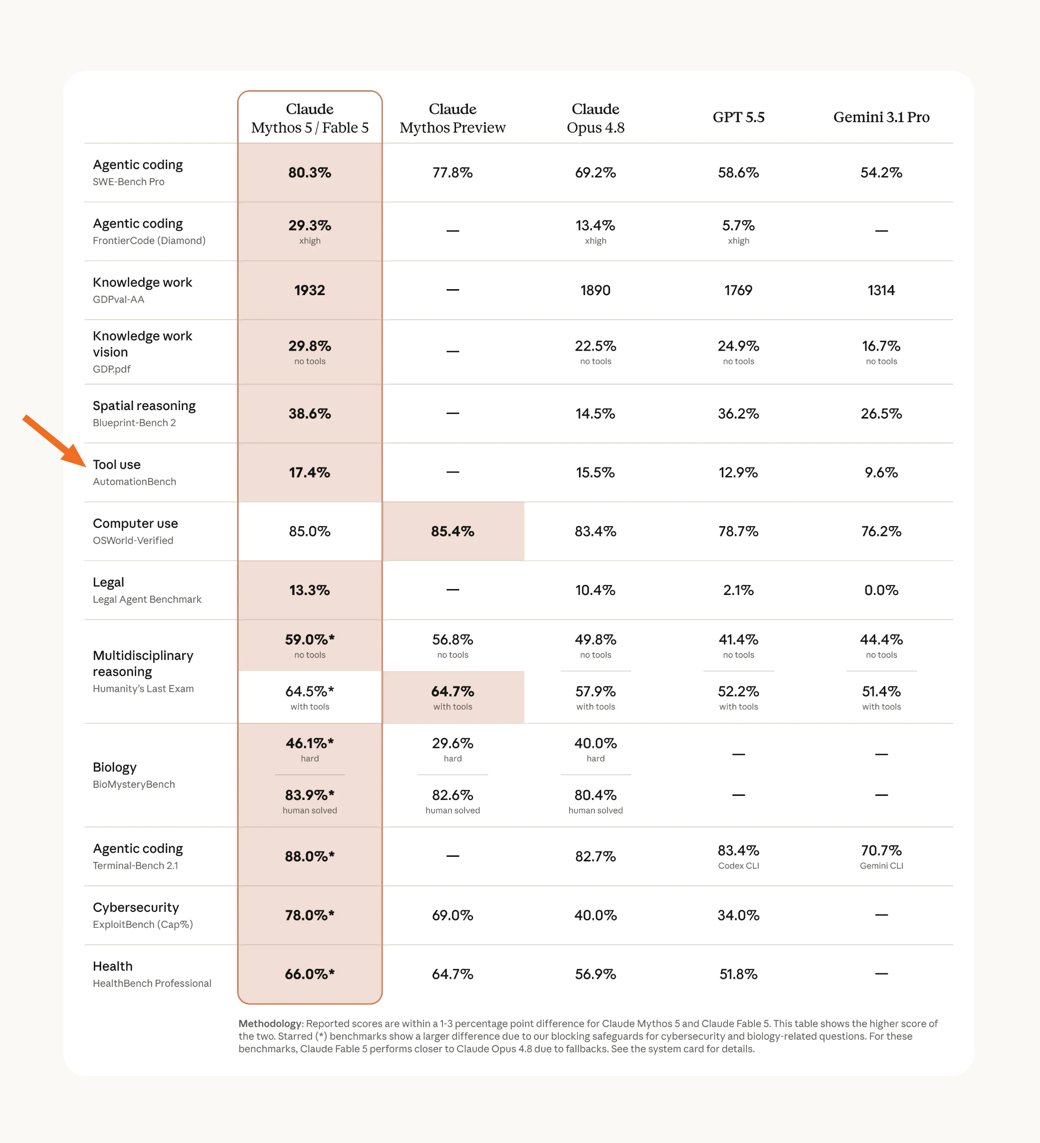
Zapier AutomationBench being used to report Tool Use performance on Fable 5's model card

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
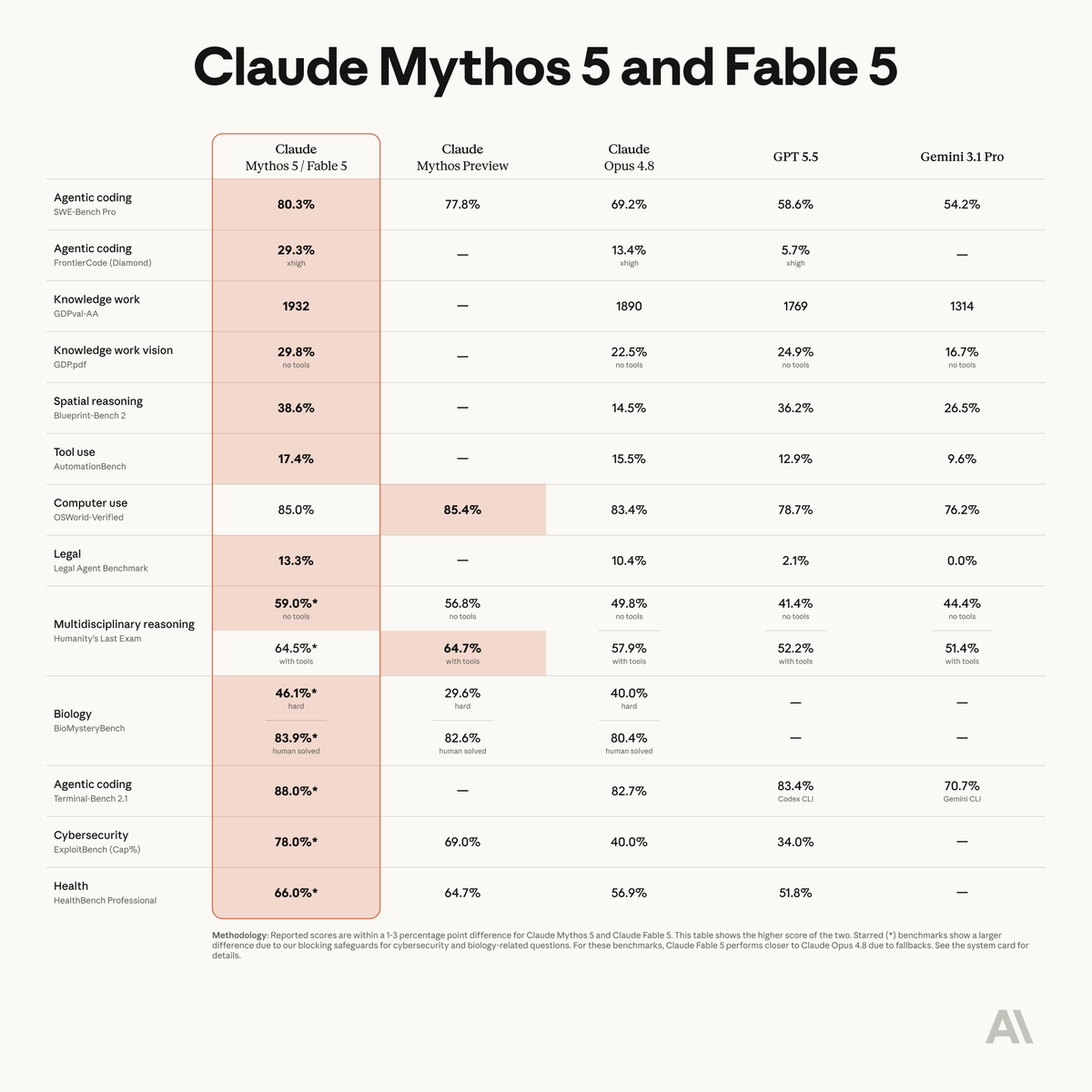
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
1
8
1,311
Fable 5 seems better than Opus in every way. Like Opus is to Sonnet. It works smarter rather than harder.
Cost is 2x Opus but cost per task was only 17% more on max reasoning! Fable is much more efficient with tokens than other models. ~1/2 the cost of GPT 5.5 xhigh.
Jun 9

Claude Fable is here: the first model in their new Mythos series.
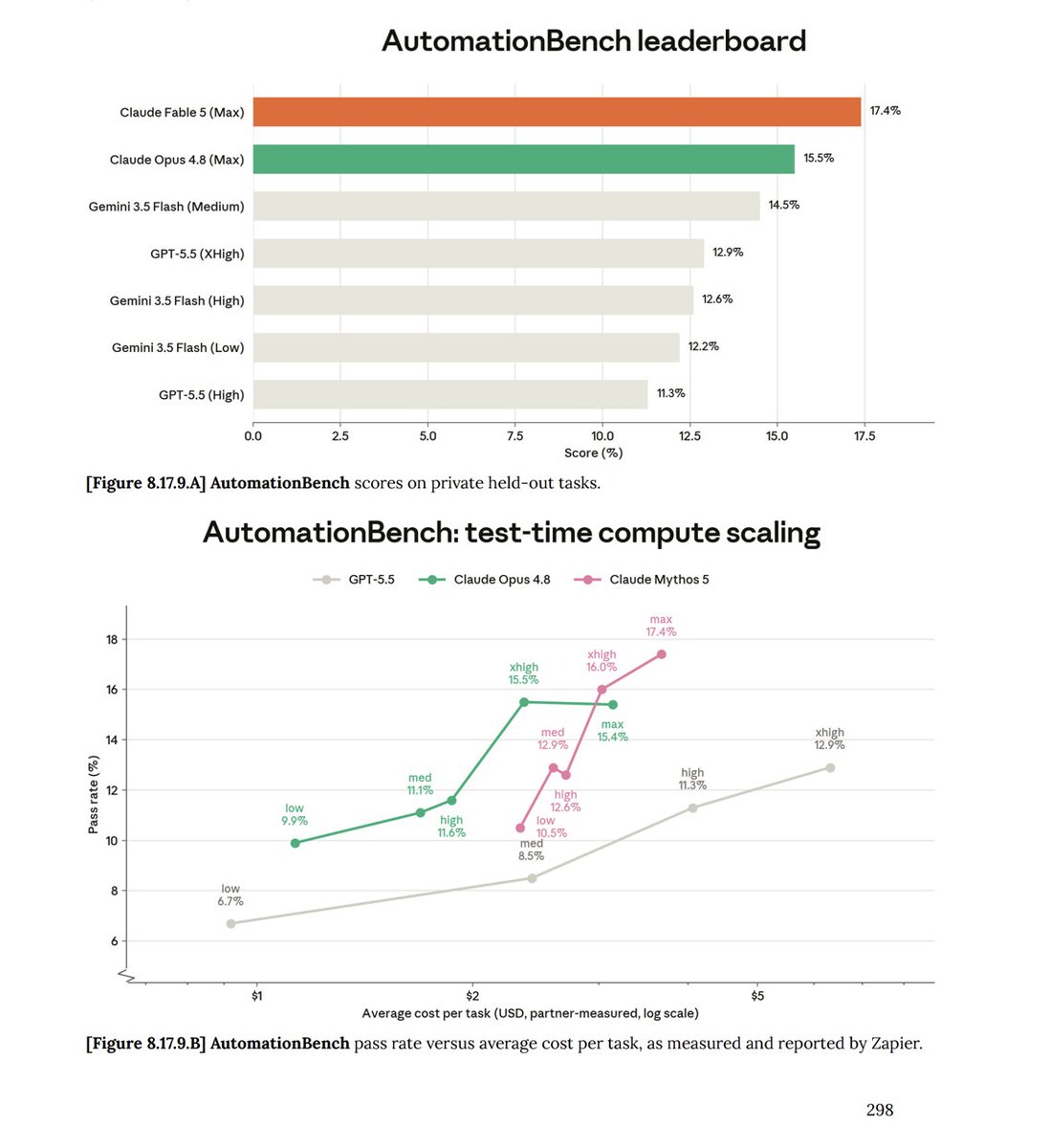
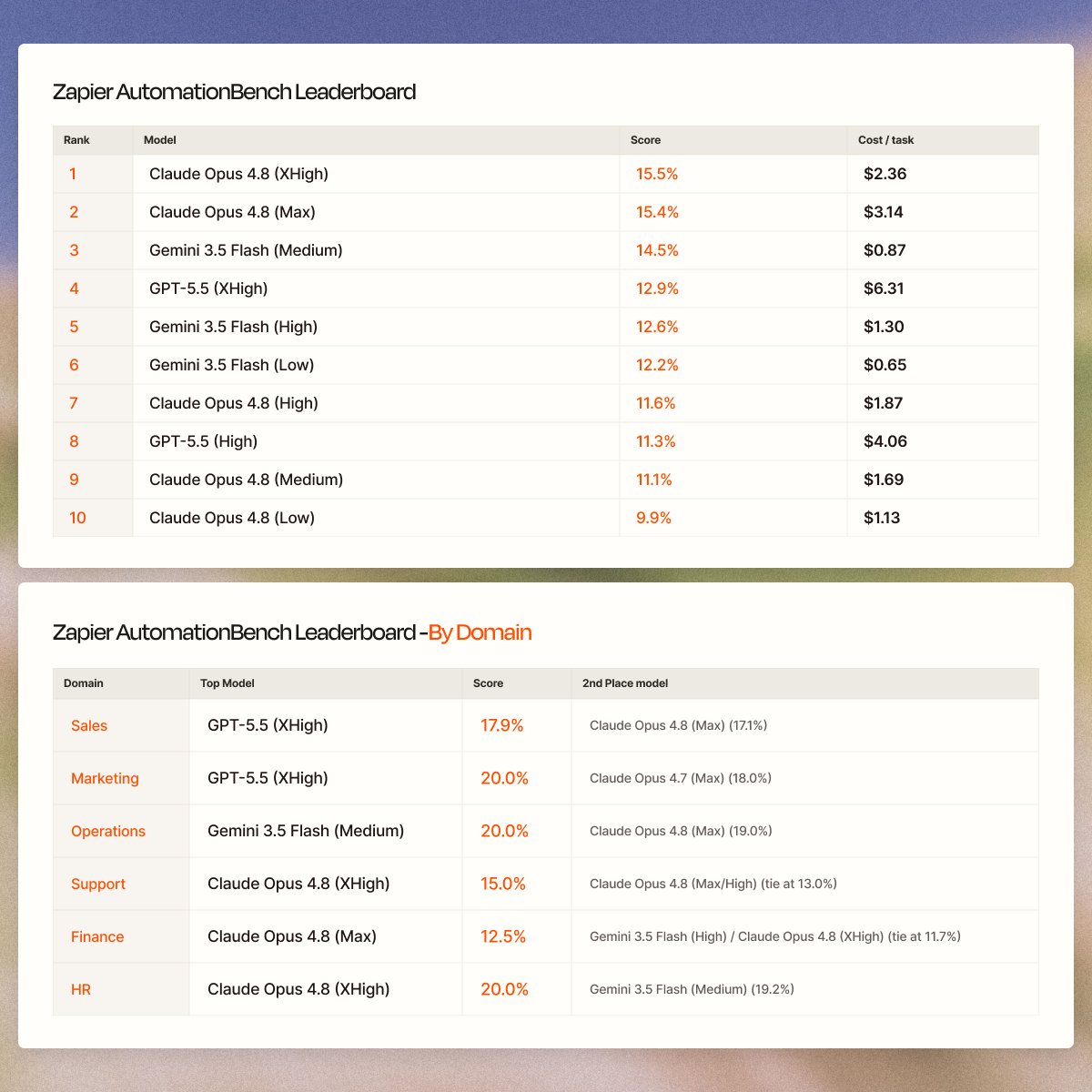
It's the new top score on @Zapier's AutomationBench at 17.4%, just two weeks after Opus 4.8 set the record at 15.5%.
Our AutomationBench measures what enterprises actually care about: can a model do the work? Find the right CRM record, send the right follow-up, update the right system without breaking anything?
We tested 600 tasks across 6 domains. Here’s what we saw:
Fable knows when to work smarter instead of harder. That means fewer timeouts and fewer wasted tokens in production.
EXAMPLE: One task asked the model to reconcile employee benefits across countries. The HR system's benefit-plans endpoint returned a 404. Fable hit it once, immediately pivoted to the team's spreadsheet and inbox, found the plan data there, and finished the task. Meanwhile, Opus moved on and missed a key detail.
That's the Fable pattern. It follows complex instructions precisely (especially the "leave these ones alone" kind), and when it hits a dead end, it goes looking somewhere else instead of spinning its wheels and wasting tokens.
PRICING: You may have seen that Fable is 2x the price of Opus. But that's the model rate, not the task cost. In Zapier, Fable came in at $3.67 per task at max effort, only 17% more than Opus 4.8 max at $3.14.
tl;dr:
Who should immediately upgrade their workflows from @claudeai's Opus to Fable?
- Operations & HR
- Long Horizon Tasks needing reliability and autonomy
- Any workflows where precision accuracy matter more than cost

1
3
20
2,371
Our CEO Wade talks AutomationBench with examples.
Jun 9

🚨 Anthropic released Claude Fable 5
It's Mythos, but safe.
The BIG question: Is it dependable enough to use apps to grow your business?
@wadefoster's team at @zapier ran it through 600 real-world business uses.
Key results:
1. It stays on track - if you ask it about a specific topic in a specific Slack channel, it won't merge data in from other channels and topics.
2. It's the most resourceful - They told it to get HR data from an API that was down. It quickly switched from using the failed API to searching email & spreadsheets. (GPT 5.5 hit the down API 22 times!)
3. It routes intelligently - They asked it to take leads from multiple sources and send each to the right salesperson. It kills at operational tasks like that.
BUT:
1. For sales and marketing tasks, GPT 5.5 is still more dependable.
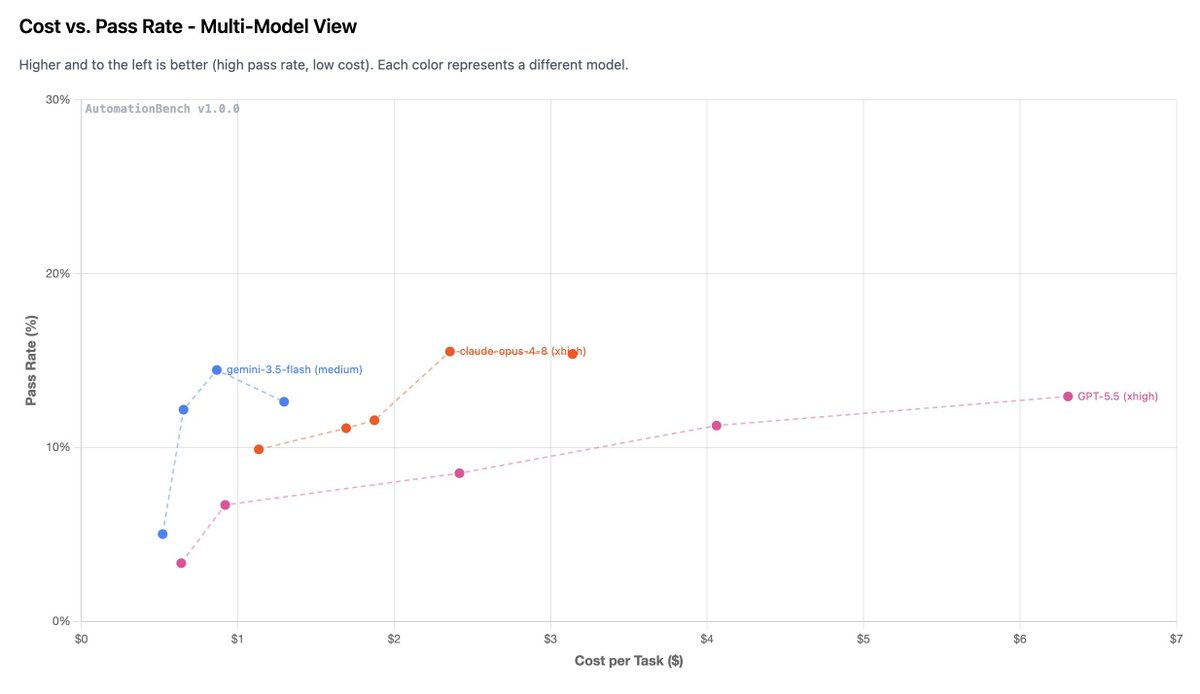
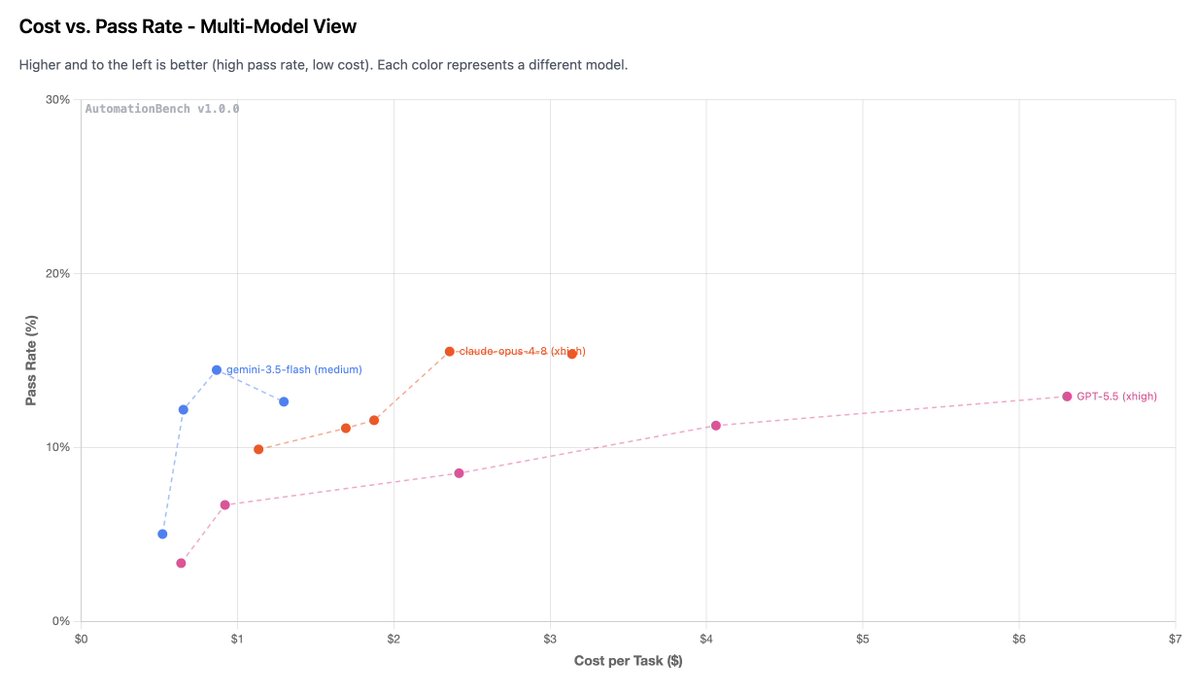
2. Fable is crazy expensive ($3.67/task vs $0.87 for Gemini 3.5 Flash)
If you love numbers (like me) the AutomationBenchmark leaderboard is below.
1
38
Fable 5 is out.
AutomationBench made the model card!
(under Tool use)
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
1
180
This is a great talk on benchmarks!
A good overview, some popular benchmarks, all the variables that can change results, and things to watch out for.
Jun 1

The talk is now on YouTube!
Link: youtube.com/watch?v=kmTMc-fV…
2
31
Talked with Andrew Warner on what AutomationBench measures and Opus 4.8!
May 29
Opus 4.8 is doing what 4.7 refused to do.
4.7 refused tasks related to:
• diversity hiring
• finance
• paychecks
Said "too risky."
@zapier tests every model by asking it to do a set of tasks and sees how many they get right.
I asked the guy who runs their benchmark work to teach me what each model can do and where they fail.
4.8 does the most multi-task work well, but it's not the winner for every task.
1
2
9
2,003
Daniel Shepard retweeted

May 28
AutomationBench tests how models perform on the trickiest, stickiest real-world workflows we know customers are actually trying to automate. 600 tasks, 6 domains, deterministic scoring.
And today our scores are featured on @AnthropicAI's official launch scorecard.

1
2
5
225
Daniel Shepard retweeted

May 28
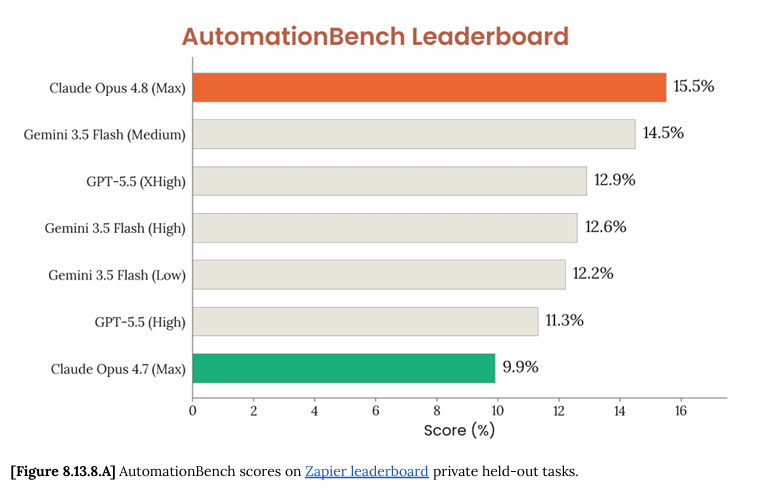
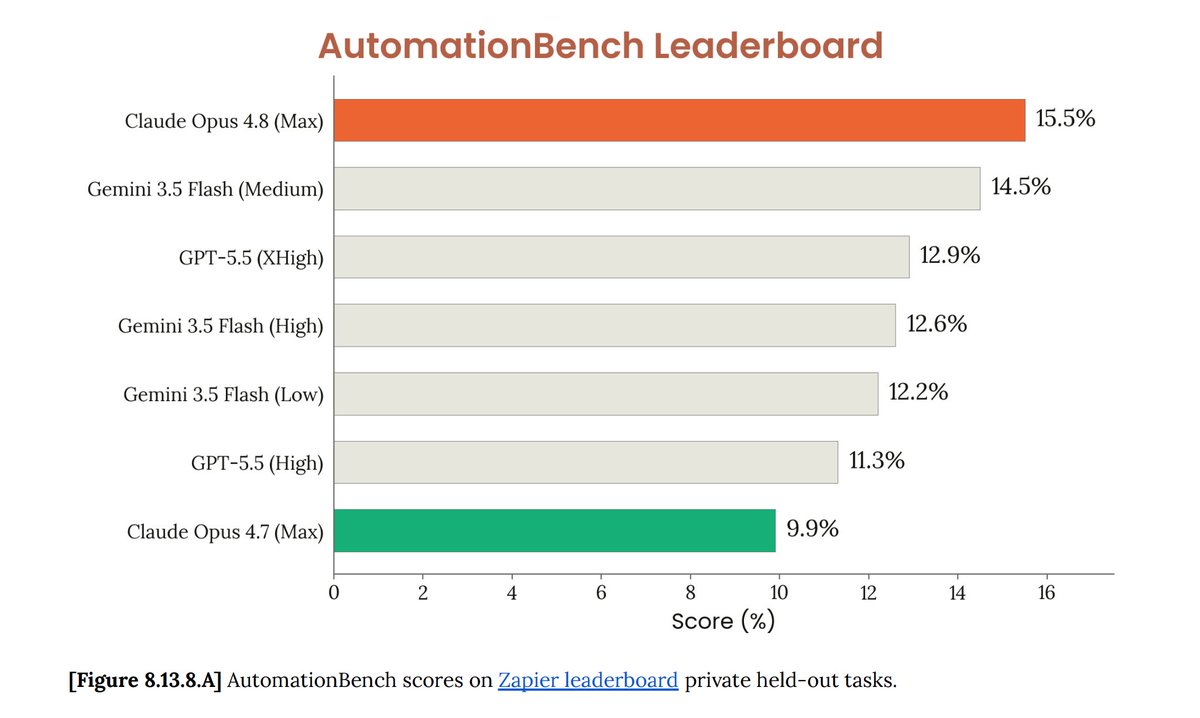
Opus 4.8 ranks #1 on AutomationBench
AutomationBench measures whether an agent can complete a realistic end-to-end business workflow
4
9
149
15,066

Opus 4.8, the first model to break 15% on AutomationBench, is now live in Zapier!
It handles complex HR, Finance, and multi-app workflows better than anything else we've tested: refusals dropped from 20% to 4%
Opus 4.7 would see a sensitive task and stop, but 4.8 keeps going
6
5
27
5,698
Daniel Shepard retweeted

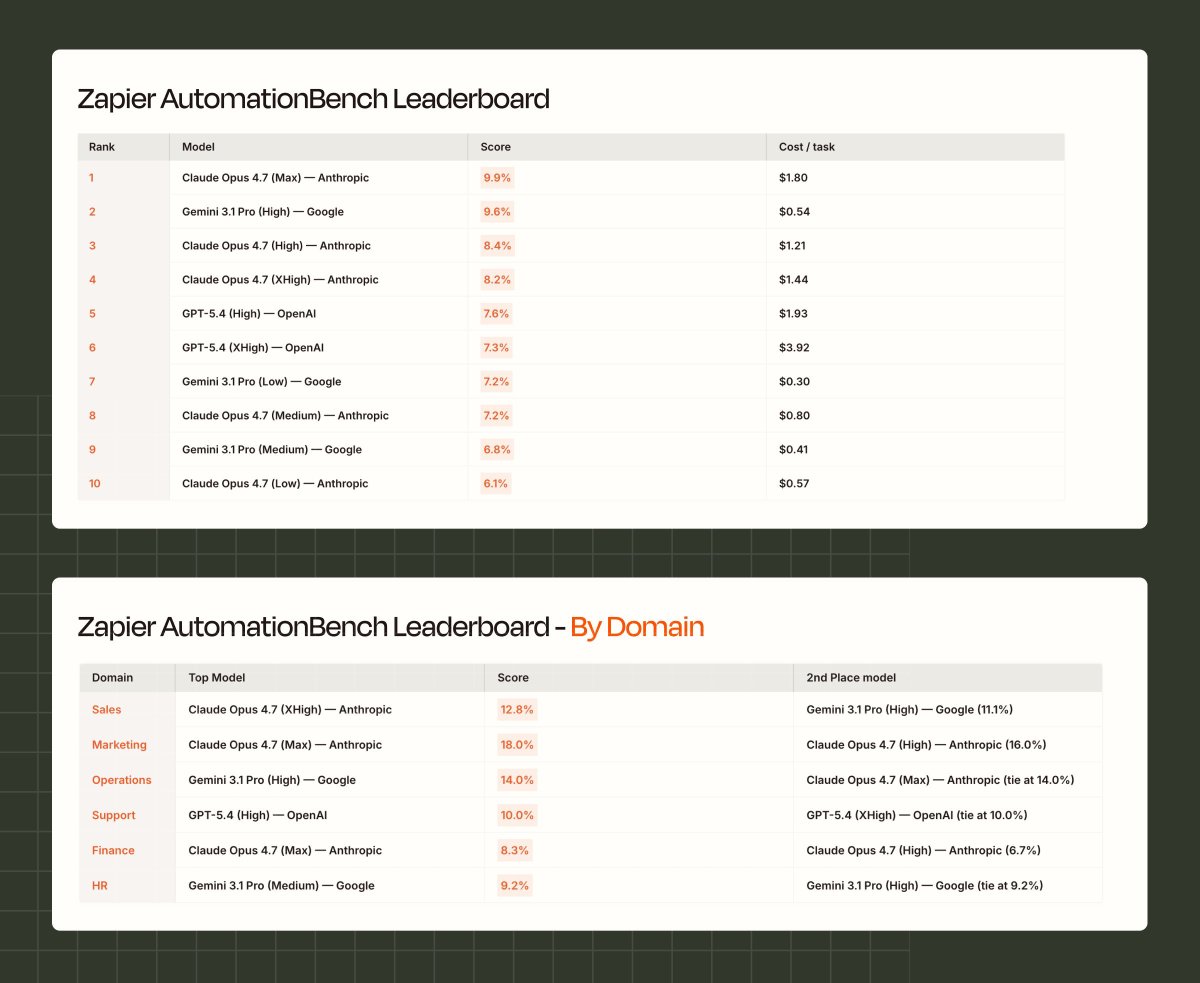
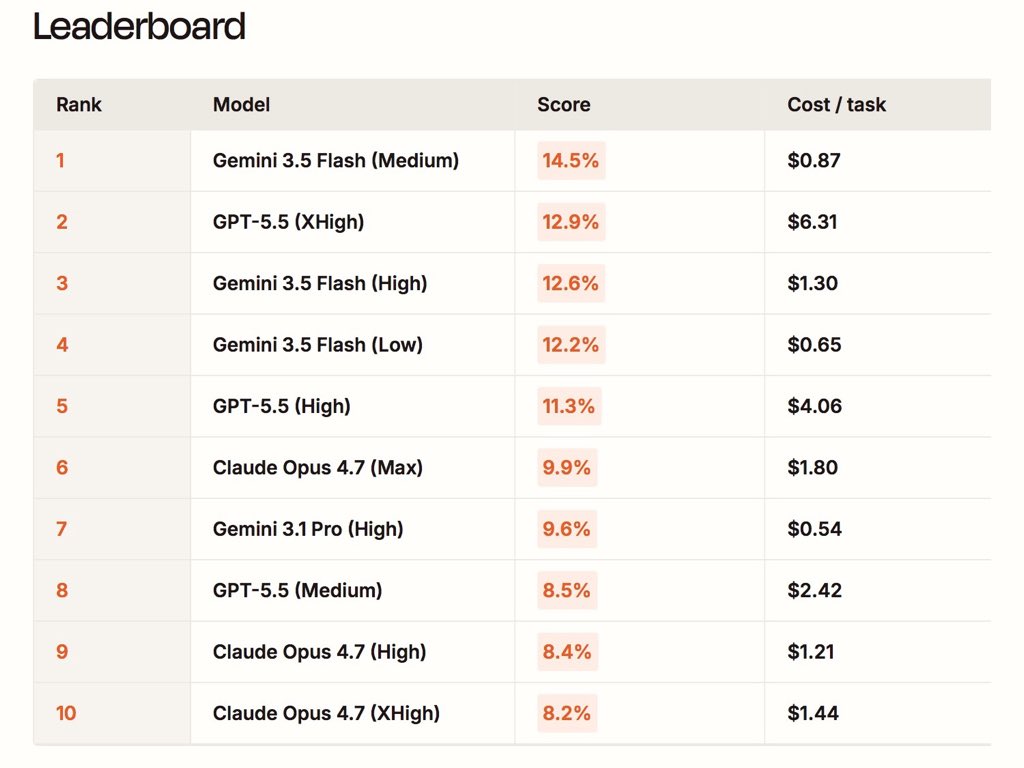
May 21
Gemini 3.5 Flash ranks #1 on Automation Bench (from Zapier), beating every other frontier model at a much lower cost
180
61
1,256
135,340
Daniel Shepard retweeted

May 20
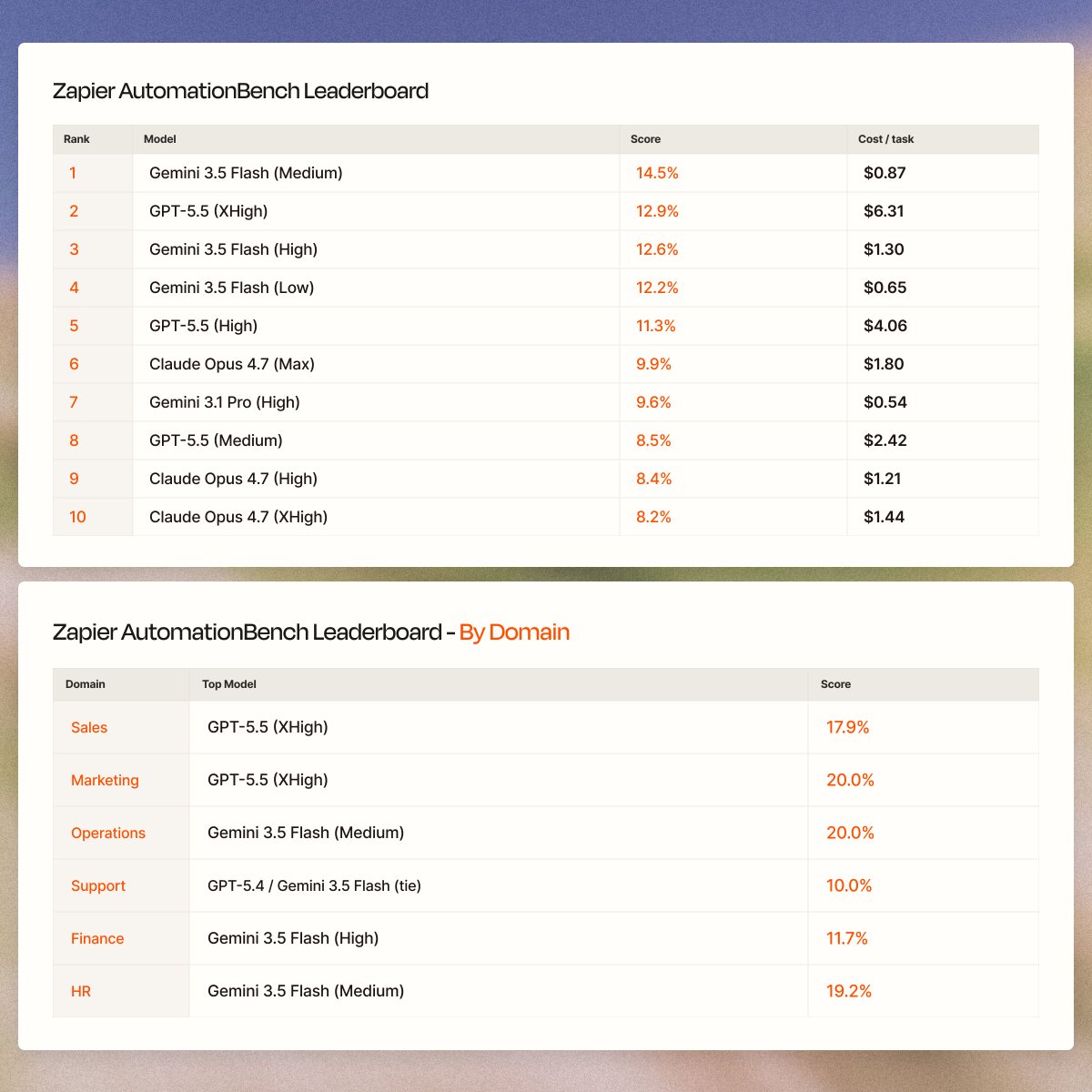
Gemini 3.5 Flash just dropped.
It’s the highest AutomationBench score yet.
We benchmark every major model on real workflows across Sales, Marketing, Ops, Support, Finance, and HR, so you know what works best inside Zapier.
Today, @GeminiApp 3.5 Flash set a new record.
It crushed Operations (20%) and HR (19%), the domains with the most step coordination and strict policy adherence. It even scored higher than GPT 5.5 at xhigh effort (and at a fraction of the cost).
Where it struggled: strict output formats, and making decisions based on math it has to do on its own.
tl;dr: This is the most persistent model we've tested yet. And at $1.50 per million input tokens, this is built for cost-effective workflows.
Try it in @Zapier now.
4
5
17
1,755
Daniel Shepard retweeted
May 15
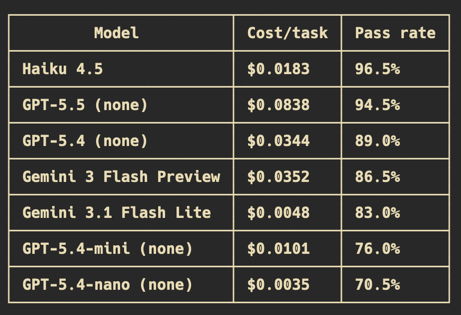
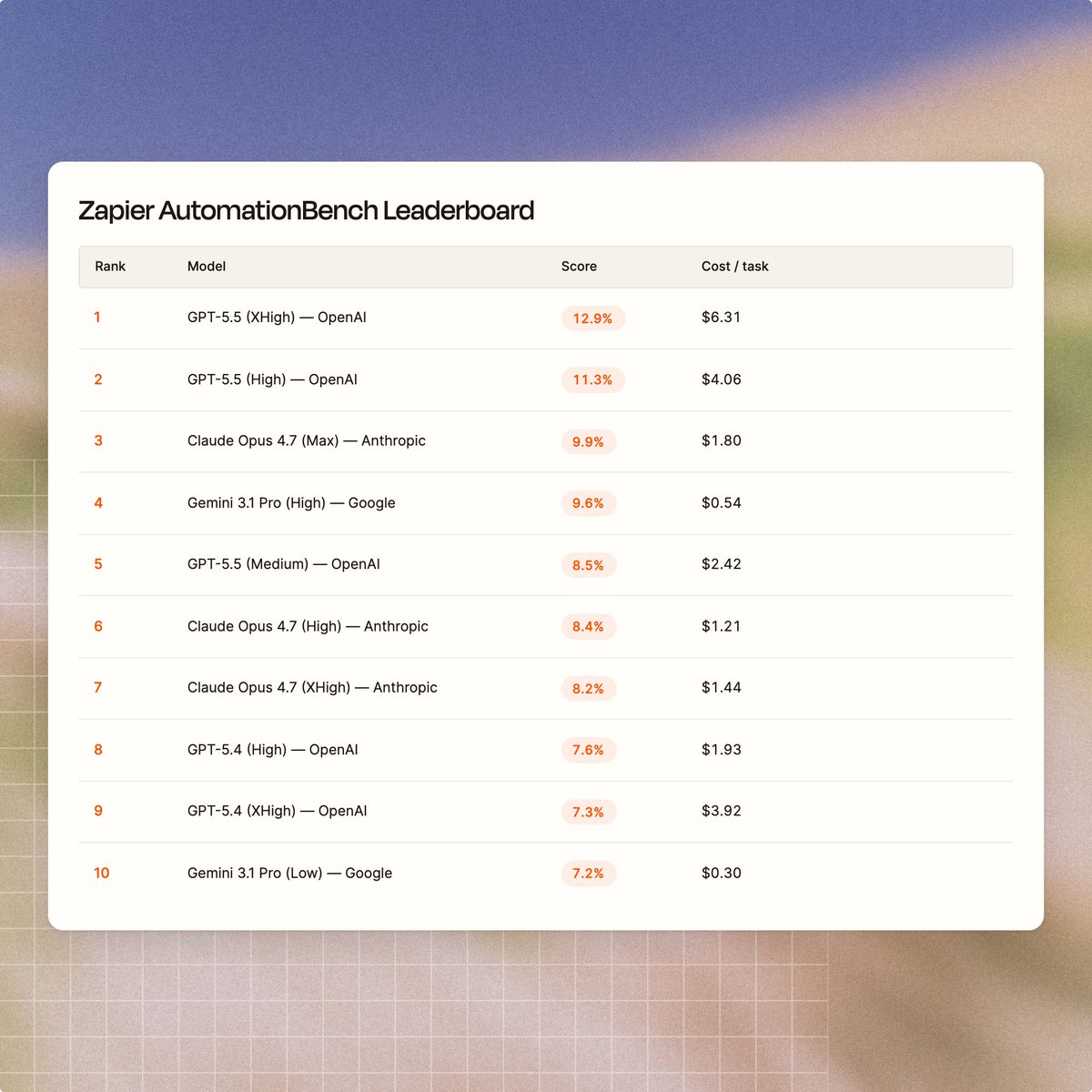
We’re on the hunt to find the best small AI model.
Here's the latest AutomationBench scorecard 👇
(Based on 2-step workflows with explicit instructions)
Most automation in production today doesn't run on the biggest model available. It runs on whatever hits the cost-performance ratio that works for the workflow. That's why we benchmark the small models, not just frontier.
The price gap is massive.
Opus 4.7 Max is $1.80 per task vs Haiku's $0.0183.
GPT-5.5 High? $6.31 per task vs. 5.4 Nano's $0.0035. 1800x difference.
One to watch: Gemini 3.1 Flash Lite came out of preview last week. Performs almost as well as 5.4 with no reasoning, at roughly the price of nano.
AutomationBench is free and open-source: github.com/zapier/Automation…

12
6
35
6,681
The last few months I have been working on a new Benchmark.
Introducing AutomationBench. Trying to measure the cutting edge of model's capabilities in real world business workflows across multiple apps and noisy data.
The best models haven't beat 10% yet.
2
4
648
Leaderboard: zapier.com/benchmarks
Github: github.com/zapier/Automation…
Prime Intellect Environment: app.primeintellect.ai/dashbo…
White Paper: res.cloudinary.com/zapier-me…
1
1
106
The white paper is up on arxiv now: arxiv.org/abs/2604.18934
1
42
Daniel Shepard retweeted

Apr 21
It’s been super fun working on this with @danielwshepard! It’s truly a great benchmark.
Also thanks @mikeknoop for helping us figure things out along the way and @PrimeIntellect for the great verifiers framework Lab 🤝
Apr 20
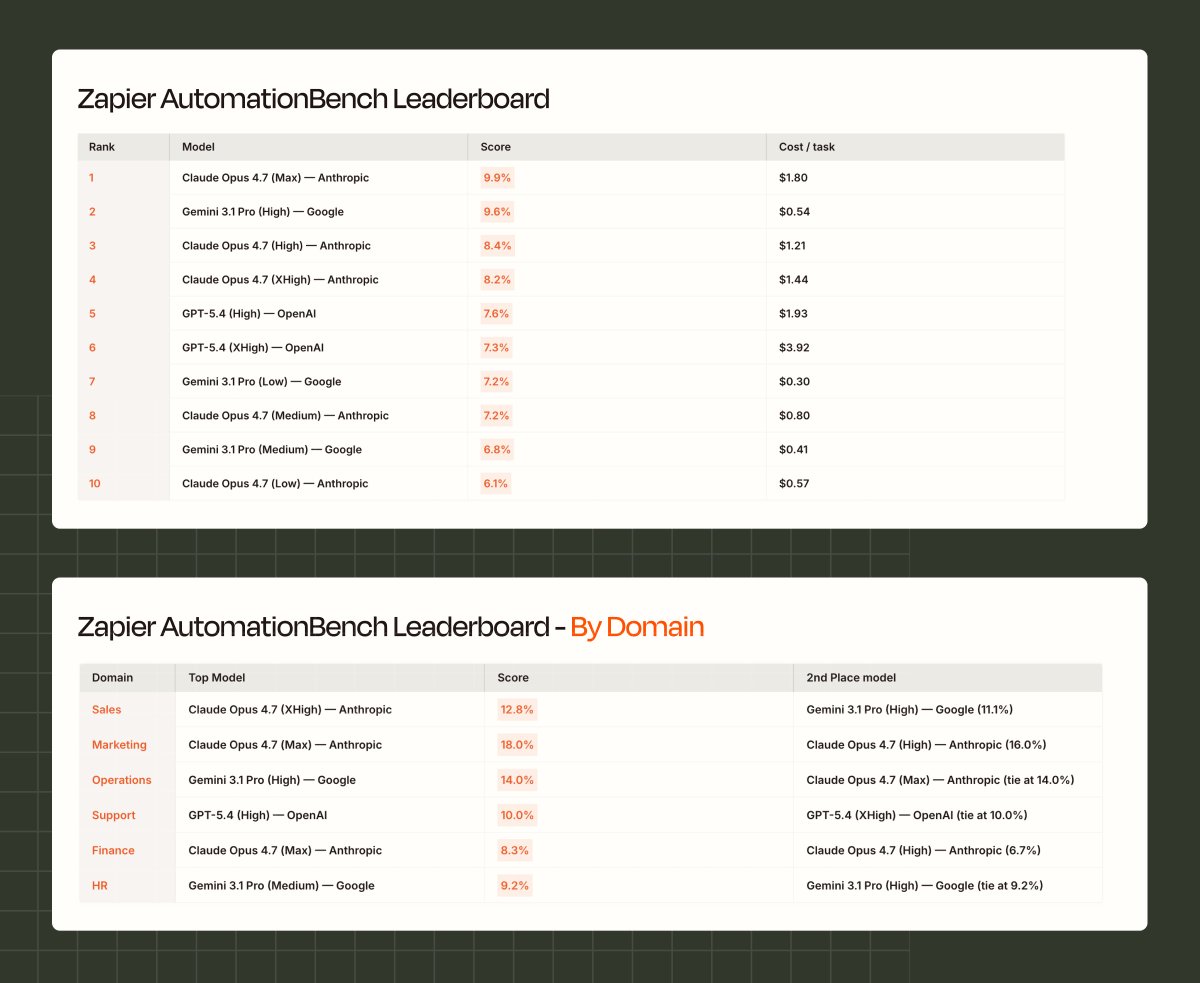
We built an AI benchmark that measures real work.
Today we're releasing it to everyone.
AI evals tell you whether a model can do complex reasoning or generate code. Useful, but usually not the question our customers ask. They want to know: can this model find the right CRM record, send the right follow-up, and not break anything along the way?
We went looking for a benchmark that tested that. Nobody had built one, so we did.
@Zapier’s AutomationBench drops AI models into realistic business environments across six domains (Sales, Marketing, Ops, Support, Finance, HR) and checks whether the work actually got done.
The tasks include live CRM data, inbox threads with ambiguous context, and multi-step tool chains where one wrong call cascades.
Scoring is deterministic: either the right records were updated and the right messages were sent, or they weren't.
It’s useful enough that we're releasing it publicly today. Open task set, open methodology, open leaderboard. Everyone should have access to this.
No model has cracked 10%. Yet.
Try it here: zapier.com/benchmarks
1
2
141
Daniel Shepard retweeted

Apr 21
been a lot of fun seeing this environment together
@zapier is cooking
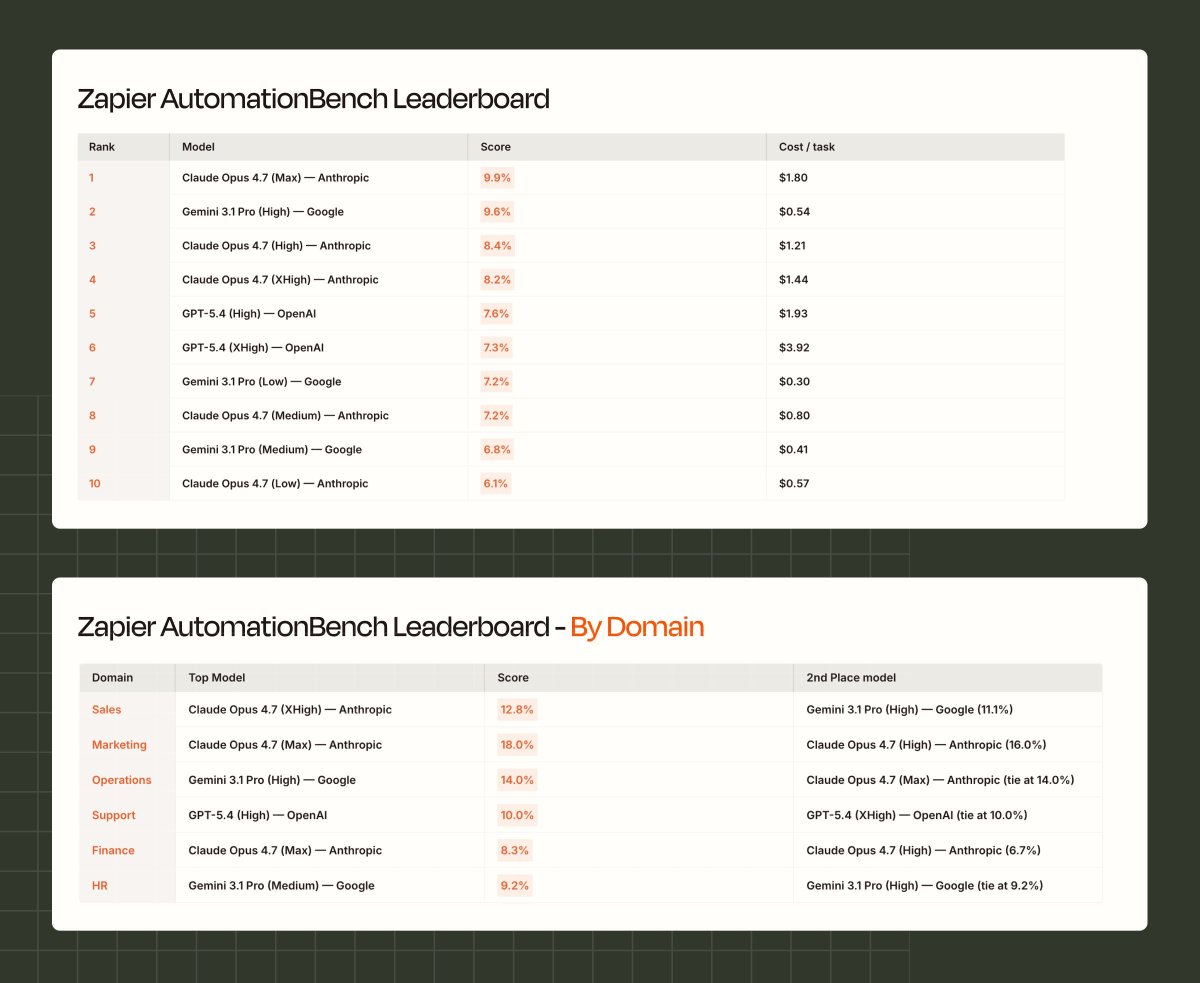
Apr 21

We're excited to support the release of @Zapier's AutomationBench on the Environments Hub, measuring frontier performance on real Zapier workflows.
Across 6 domains, 47 tools, and 600 tasks, frontier models all score under 10%.

8
108
15,557
Daniel Shepard retweeted

Apr 21
We're excited to support the release of @Zapier's AutomationBench on the Environments Hub, measuring frontier performance on real Zapier workflows.
Across 6 domains, 47 tools, and 600 tasks, frontier models all score under 10%.
Apr 20
We built an AI benchmark that measures real work.
Today we're releasing it to everyone.
AI evals tell you whether a model can do complex reasoning or generate code. Useful, but usually not the question our customers ask. They want to know: can this model find the right CRM record, send the right follow-up, and not break anything along the way?
We went looking for a benchmark that tested that. Nobody had built one, so we did.
@Zapier’s AutomationBench drops AI models into realistic business environments across six domains (Sales, Marketing, Ops, Support, Finance, HR) and checks whether the work actually got done.
The tasks include live CRM data, inbox threads with ambiguous context, and multi-step tool chains where one wrong call cascades.
Scoring is deterministic: either the right records were updated and the right messages were sent, or they weren't.
It’s useful enough that we're releasing it publicly today. Open task set, open methodology, open leaderboard. Everyone should have access to this.
No model has cracked 10%. Yet.
Try it here: zapier.com/benchmarks
5
18
102
35,060
Daniel Shepard retweeted
Apr 20
I gave input on this new benchmark from Zapier. It's designed on real automation patterns from ~2B tasks across ~4M Zapier customers and challenges both multi-tool orchestration and tool *construction*. SOTA is 10% at $2/task.
Apr 20
We built an AI benchmark that measures real work.
Today we're releasing it to everyone.
AI evals tell you whether a model can do complex reasoning or generate code. Useful, but usually not the question our customers ask. They want to know: can this model find the right CRM record, send the right follow-up, and not break anything along the way?
We went looking for a benchmark that tested that. Nobody had built one, so we did.
@Zapier’s AutomationBench drops AI models into realistic business environments across six domains (Sales, Marketing, Ops, Support, Finance, HR) and checks whether the work actually got done.
The tasks include live CRM data, inbox threads with ambiguous context, and multi-step tool chains where one wrong call cascades.
Scoring is deterministic: either the right records were updated and the right messages were sent, or they weren't.
It’s useful enough that we're releasing it publicly today. Open task set, open methodology, open leaderboard. Everyone should have access to this.
No model has cracked 10%. Yet.
Try it here: zapier.com/benchmarks
1
5
29
7,192
PrimeIntellect Lab is a major unlock for our RL workflows. We spun up experiments with very little setup to pressure-test our new AutomationBench benchmark, which surfaced reward-hacking opportunities we could then fortify against. Kicking off a training run was a single command.
1
8
100
22,444
Thanks @willccbb and @GottliebEli for your early feedback and making getting up and running with RL easy!
6
322