
275 Photos and videos










Pinned Tweet

May 4
Today we open early access to @Zapier's next product
We've been using it internally for months (>1,000,000 actions executed so far) and it's completely changed how we work.
We're letting a small group of AI-forward teams try it first and give feedback.
Who we’re looking for:
- 10-100 person teams using AI daily, but need to do so more collaboratively
- teams ready to build and ship automations through agents, not just chat
- teams that already work in the open (call recordings, shared docs, public channels, etc)
- teams obsessed with optimizing every aspect of their work
Join the waitlist: zapier.com/shared-brain

97
46
625
143,846
Don’t put all your eggs in one ai lab basket.

If a Treasurer of a Fortune 1000 company kept all of their cash in one bank they’d be fired for incompetence.
Similarly, if the leadership of a Fortune 1000 company bets the farm on only one frontier lab and their models you’re taking a lot of risk. This risk compounds as the labs’ intentions and public actions are bewildering and show them to be increasingly unpredictable.
This is why every major enterprise needs a model agnostic “control plane”. Get the work done, increase the productivity, make more money, save costs, increase efficiency but do it with governance, auditability and control.
Capabilities across all models are converging. Open source prices are, in some cases, 1/100th of the frontier labs. But governance, control, compliance and collaboration capabilities don’t exist unless you first focus on the right “control plane”.
If you do not find such a “control plane”, you’re increasingly taking risk as the frontier labs become increasingly unpredictable.
This is why 8090’s Software Factory is used this way in every major part of the economy including governments.
1
1
10
1,906
Jun 11
For NoPlex, native MCPs weren't enough.
Zapier MCP let them add the actions they needed, even the ones Claude’s native MCPs didn't support.
@NoPlex_AI's Head of Community and Growth, @MatthewCanning, explained:
"As of today, the Google Drive MCP offered by Anthropic allows for:
download_file_content
get_file_metadata
get_file_permissions
list_recent_files
read_file_content
search_files
copy_file
create_file
If I want to do something as simple as append a row to a Google Sheet, I'm unable to do so… @Zapier was a more effective intervention for things like Claude because of the versatility offered."
How it works: Claude connects to Zapier MCP searches for trending topics relevant to the NoPlex community, pulls examples and citations, and delivers the research as Google Docs and Sheets straight to Matt.
That's 4 hours of weekly media triage down to 15 minutes.
Zapier MCP works with Claude, ChatGPT, Codex, and more. Wherever you build.
Try it: zapier.com/mcp
2
7
981
Jun 10
We gave Claude Fable a broken API. It tried once, then went looking.
Checked connected tools, pieced the data together, and finished the task.
GPT-5.5 on the same task? 22 retries on the same endpoint.
Fable holds the new high score on AutomationBench, @Zapier's benchmark for AI workflows. It's also the new leader in two departments: Operations and HR.
Here's the efficiency math: Fable tokens cost 2x. But at max effort it runs at $3.67/task. In real workflows, that's only 17% more than Opus.
Recovery and efficiency are the new frontier.
Big thanks to for having me on.
4
2
22
7,103
Jun 9
Fable's scorecard measures tool use with @Zapier's AutomationBench.
If a model can't run tools well, it can't do the job.
Fable has our highest score yet.

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
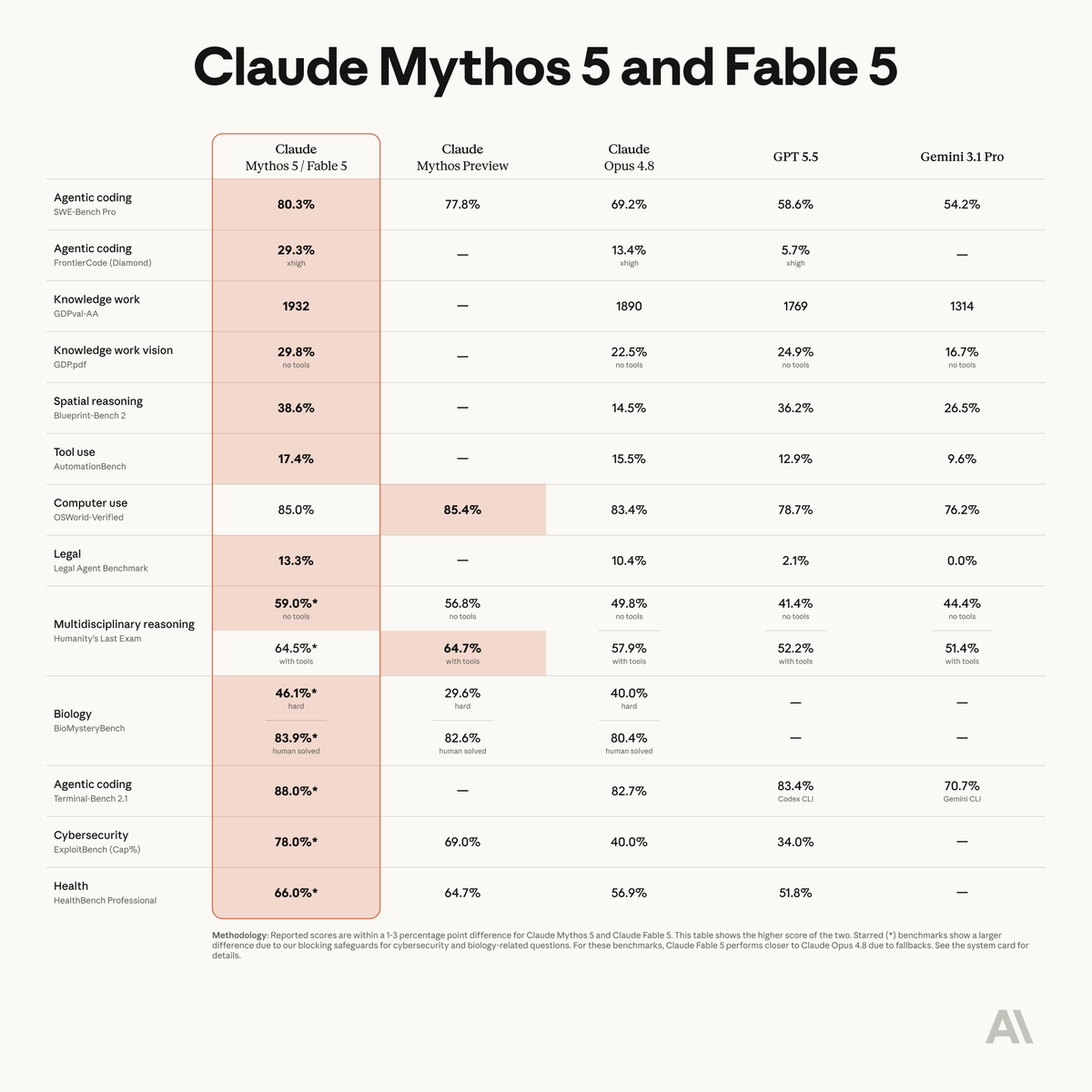
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
2
15
1,145
Jun 9
Team has made connecting your tools to Claude so easy. Just copy/paste this and let it cook:
"can you add the Zapier connector for me"
4
713
Wade Foster retweeted

Fable 5 seems better than Opus in every way. Like Opus is to Sonnet. It works smarter rather than harder.
Cost is 2x Opus but cost per task was only 17% more on max reasoning! Fable is much more efficient with tokens than other models. ~1/2 the cost of GPT 5.5 xhigh.
Jun 9

Claude Fable is here: the first model in their new Mythos series.
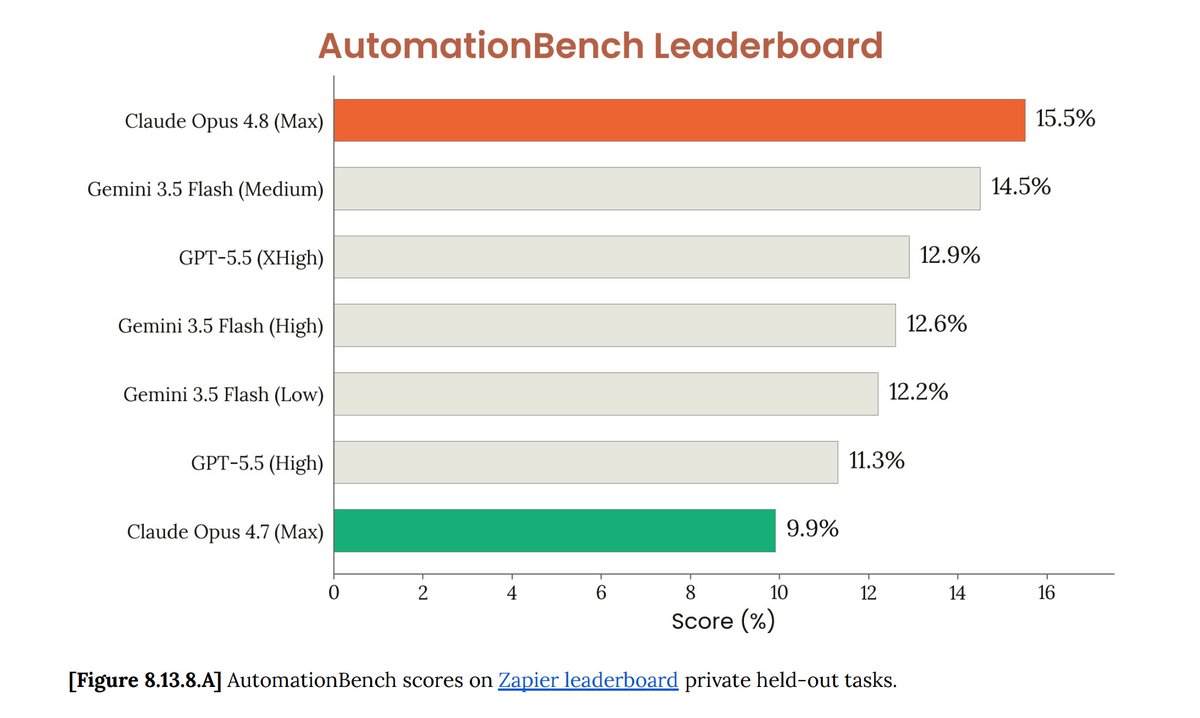
It's the new top score on @Zapier's AutomationBench at 17.4%, just two weeks after Opus 4.8 set the record at 15.5%.
Our AutomationBench measures what enterprises actually care about: can a model do the work? Find the right CRM record, send the right follow-up, update the right system without breaking anything?
We tested 600 tasks across 6 domains. Here’s what we saw:
Fable knows when to work smarter instead of harder. That means fewer timeouts and fewer wasted tokens in production.
EXAMPLE: One task asked the model to reconcile employee benefits across countries. The HR system's benefit-plans endpoint returned a 404. Fable hit it once, immediately pivoted to the team's spreadsheet and inbox, found the plan data there, and finished the task. Meanwhile, Opus moved on and missed a key detail.
That's the Fable pattern. It follows complex instructions precisely (especially the "leave these ones alone" kind), and when it hits a dead end, it goes looking somewhere else instead of spinning its wheels and wasting tokens.
PRICING: You may have seen that Fable is 2x the price of Opus. But that's the model rate, not the task cost. In Zapier, Fable came in at $3.67 per task at max effort, only 17% more than Opus 4.8 max at $3.14.
tl;dr:
Who should immediately upgrade their workflows from @claudeai's Opus to Fable?
- Operations & HR
- Long Horizon Tasks needing reliability and autonomy
- Any workflows where precision accuracy matter more than cost
1
3
20
2,370
Wade Foster retweeted

Jun 9
🚨 Anthropic released Claude Fable 5
It's Mythos, but safe.
The BIG question: Is it dependable enough to use apps to grow your business?
@wadefoster's team at @zapier ran it through 600 real-world business uses.
Key results:
1. It stays on track - if you ask it about a specific topic in a specific Slack channel, it won't merge data in from other channels and topics.
2. It's the most resourceful - They told it to get HR data from an API that was down. It quickly switched from using the failed API to searching email & spreadsheets. (GPT 5.5 hit the down API 22 times!)
3. It routes intelligently - They asked it to take leads from multiple sources and send each to the right salesperson. It kills at operational tasks like that.
BUT:
1. For sales and marketing tasks, GPT 5.5 is still more dependable.
2. Fable is crazy expensive ($3.67/task vs $0.87 for Gemini 3.5 Flash)
If you love numbers (like me) the AutomationBenchmark leaderboard is below.
8
4
20
8,390
Jun 9
Talking AutomationBench and Fable 5 with the @every crew!
Jun 9

VIBE CHECK: Claude Fable 5 IS OUT! x.com/i/broadcasts/1pKdRRPyd…
1
1
6
1,729
Wade Foster retweeted

Jun 9
VIBE CHECK: Claude Fable 5 IS OUT! x.com/i/broadcasts/1pKdRRPyd…
1
5
22
4,460
Jun 9
Claude Fable is here: the first model in their new Mythos series.
It's the new top score on @Zapier's AutomationBench at 17.4%, just two weeks after Opus 4.8 set the record at 15.5%.
Our AutomationBench measures what enterprises actually care about: can a model do the work? Find the right CRM record, send the right follow-up, update the right system without breaking anything?
We tested 600 tasks across 6 domains. Here’s what we saw:
Fable knows when to work smarter instead of harder. That means fewer timeouts and fewer wasted tokens in production.
EXAMPLE: One task asked the model to reconcile employee benefits across countries. The HR system's benefit-plans endpoint returned a 404. Fable hit it once, immediately pivoted to the team's spreadsheet and inbox, found the plan data there, and finished the task. Meanwhile, Opus moved on and missed a key detail.
That's the Fable pattern. It follows complex instructions precisely (especially the "leave these ones alone" kind), and when it hits a dead end, it goes looking somewhere else instead of spinning its wheels and wasting tokens.
PRICING: You may have seen that Fable is 2x the price of Opus. But that's the model rate, not the task cost. In Zapier, Fable came in at $3.67 per task at max effort, only 17% more than Opus 4.8 max at $3.14.
tl;dr:
Who should immediately upgrade their workflows from @claudeai's Opus to Fable?
- Operations & HR
- Long Horizon Tasks needing reliability and autonomy
- Any workflows where precision accuracy matter more than cost
2
3
16
4,475
Jun 9
Loops are powerful bc the trigger is already in your data.
New lead, new email, new support issue, any of these can kick off a Zapier agent to act on your behalf in a fully or semi automated way.
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
1
5
1,415
Jun 4
We just open-sourced Zapier’s GTM agents.
It's a GitHub repo of GTM agent skills and pre-built automations, built on @Zapier SDK MCP.
Some of the automations included:
- Daily lead audits to flag what's slipping
- No-lead-left-behind rollup
- Cross-CRM Opportunity Sync
- Customer Deck Builder
- PR & Media Inbox Triage
Plus skill files across marketing, sales, revops, customer advocacy, and support.
Drop them right into Cursor, Codex, Claude Code, or wherever you're building.
github.com/zapier/gtm-cheat-…
8
24
352
35,970
Jun 2
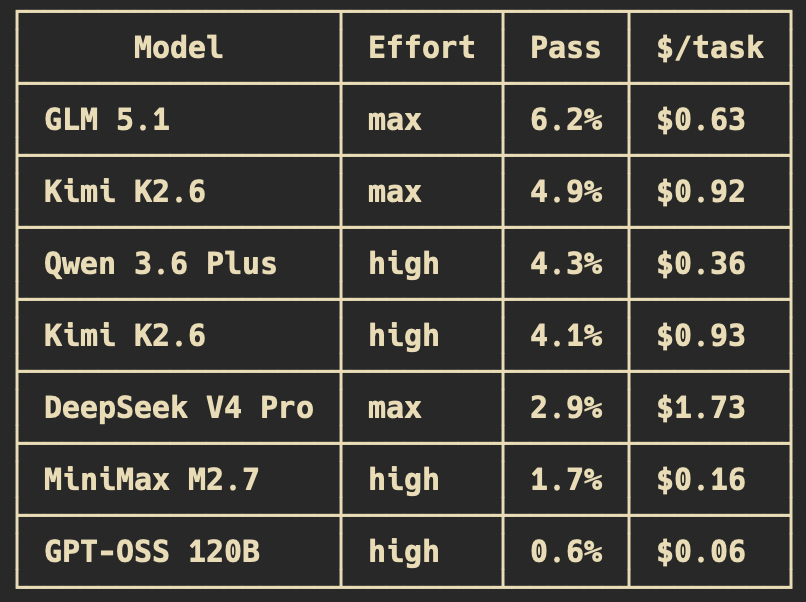
You voted. We ran the open source models on AutomationBench.
GLM 5.1 (max) topped this batch:
6.2% pass rate at $0.63 per task
Best open-source result yet. Still a long way from frontier.
For context: on the same tests, Gemini 3.5 Flash (medium) scores 14.5% at $0.87 per task. More than double the pass rate for $0.24 more per task.
Opus 4.8 still leads the full leaderboard at 15.5% - but expect to pay for it ($2.36 per task)
What model should we benchmark next?
zapier.com/benchmarks
May 26
Which model should Zapier benchmark next?
2
11
1,125
Jun 2
Eric Ries wrote the Lean Startup.
So I asked him about token-maxxing.
He said it's like professional gambling. If you have an edge, it works. If you don't, you're lighting money on fire.
Eric calls this LLM psychosis: you've built an alternate reality where the machine tells you how great you are, and you start believing it.
“You’re totally right, this IS a revolutionary piece of technology…”
5
5
32
3,361
Jun 2
Big thanks to @ericries for joining.
Watch the full convo here: youtu.be/Qs33r-Nreb8
1
6
2,167
Jun 1
Opus 4.8 has been public for 4 days.
It's the highest scoring model on Zapier's AutomationBench.
Does that match what you're seeing?
May 28

If Opus 4.8 is not better than GPT-5.5, I'm gonna crash out.
6
1
42
16,442
Jun 1
We benchmark LLMs every week. The top spot has changed 3 times this month.
Your tools shouldn't have to change with it.
That's why we built @Zapier MCP. One connection layer across 9,000 apps. Add it once.
Switch to Claude, ChatGPT, Gemini, OpenClaw whenever you want. Your tools and workflows come with you.
3
4
21
6,217