
Strategic Cloud Engineer at Google. Political thinker. Electronics tinkerer. Programmer.
Joined June 2009
- Tweets 8,863
- Following 972
- Followers 355
- Likes 14,270
95 Photos and videos


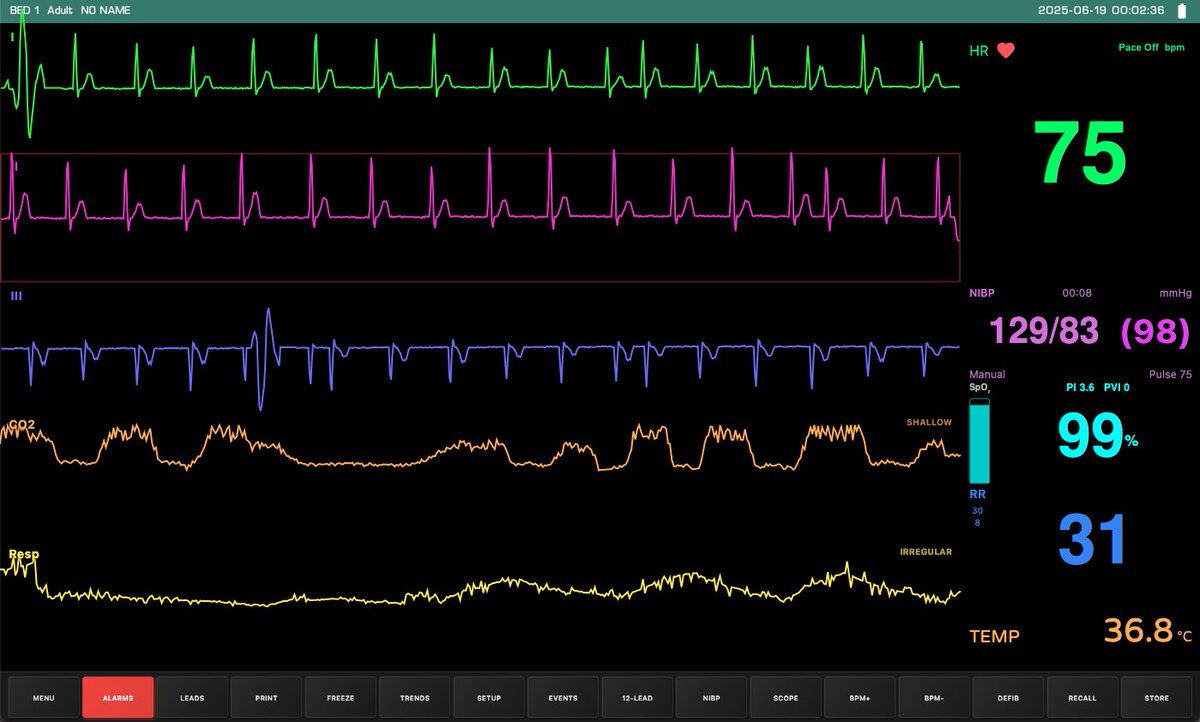





Danny Ackerman retweeted

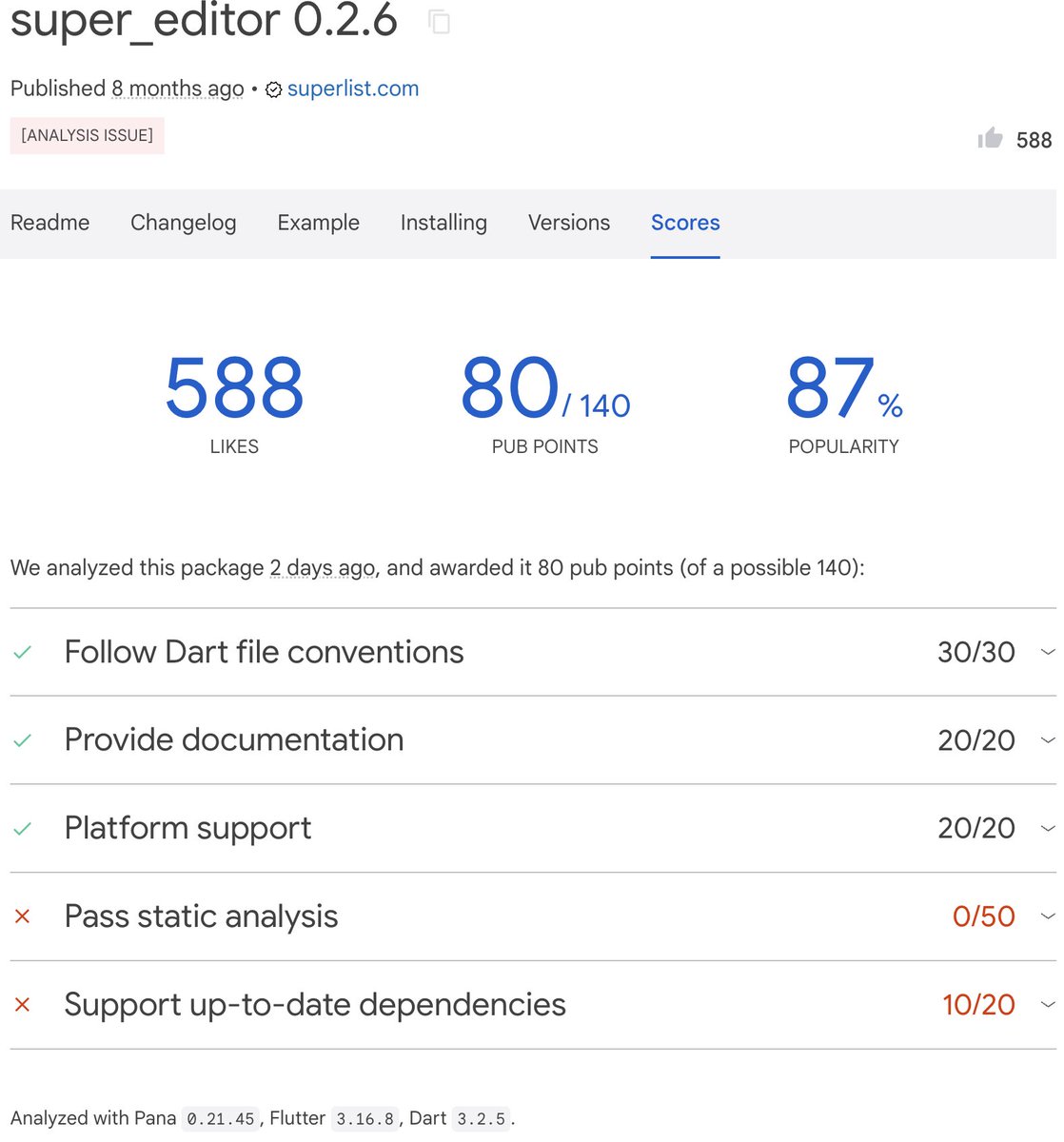
🖥️ Best Local LLMs for Consumer GPUs — llama.cpp Guide (June 2026)
What I actually run on consumer hardware right now. Every model below runs via llama.cpp with a simple one-liner — no Docker, no Python env, no cloud.
━━━ 8-16GB VRAM ━━━
🔹 Gemma 4-12B (Google)
• Smartest model in this size class — competes with stuff 2× bigger
• Unsloth's MTP GGUFs: 162 tok/s vs 52 tok/s normal (3× speedup)
• Minimum 8GB VRAM recommended for Q4_K_M quant
• GGUF → huggingface.co/unsloth/gemma…
🔹 LFM2.5-8B-A1B (LiquidAI)
• Hybrid MoE, only 1B active params — absurdly fast for its size
• Perfect for 8-12GB cards, MacBooks, or anyone on a tight budget
• GGUF → huggingface.co/LiquidAI/LFM2…
━━━ 16-32GB VRAM ━━━
🔹 Qwen3.6-27B (Qwen)
• Scored 1.00 on tool-efficiency benchmarks — best local agent available
• 40 deterministic tasks, 32k/128k context needle tests — all passed
• GGUF → huggingface.co/unsloth/Qwen3…
• MTP version (faster) → huggingface.co/unsloth/Qwen3…
🔹 Qwopus3.6-27B-v2 (Jackrong)
• Best quantization of Qwen3.6-27B — topped 5 agent & coding benchmarks (1200 samples)
• If you're running Q4, this is the one to grab
• GGUF → huggingface.co/Jackrong/Qwop…
• MTP version → huggingface.co/Jackrong/Qwop…
🔹 Gemma 4-31B QAT (Google/Unsloth)
• QAT variant with MTP draft head: 76-125 tok/s (1.67× speedup)
• Excellent for multi-agent / subagent workflows
• GGUF → huggingface.co/unsloth/gemma…
🔹 Nex-N2-Mini (Nex AGI)
• Post-train of Qwen3.5-35B-A3B — MoE with only 3B active params
• Fits on 16GB VRAM, overflow loads from system RAM
• Adaptive thinking saves ~20% tokens with no quality loss
• For deep multi-step reasoning, nothing in this size comes close
• GGUF → huggingface.co/sjakek/Nex-N2…
━━━ Quick Picks ━━━
• 16GB all-rounder → Gemma 4-12B with MTP GGUFs
• 32GB all-rounder → Qwen3.6-27B / Qwopus-v2
• Agents & tool use → Qwen3.6-27B or Qwopus Q4
• Deep reasoning → Nex-N2-Mini (MoE, fits 16GB )
• Tight budget → LFM2.5-8B-A1B
• Cheapest full build: 1× used RTX 3090 (24GB) rest of PC ≈ $1000-1500
━━━ Setup on Windows ━━━
1. Download llama.cpp → github.com/ggml-org/llama.cp… (latest .zip)
2. Extract to any folder (e.g. C:\llama.cpp)
3. Download a .gguf from the links above (Q4_K_M or Q5_K_M for best quality/speed balance)
4. Run one of the commands below depending on your hardware
━━━ Launch Commands ━━━
SINGLE GPU — Standard model (no MTP):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
-ngl 100 ^
-np 1 ^
--port 8080 ^
--jinja
SINGLE GPU — MTP model (faster inference):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-MTP-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
-ngl 100 ^
-np 1 ^
--port 8080 ^
--jinja
DUAL GPU — Split across two cards:
llama-server.exe ^
-m C:\models\Qwen3.6-27B-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
-ngl 100 ^
--tensor-split 0.55,0.45 ^
--main-gpu 0 ^
-np 1 ^
--port 8080 ^
--jinja
DUAL GPU MTP Vision (multimodal):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-MTP-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
-ngl 100 ^
--tensor-split 0.60,0.40 ^
--main-gpu 0 ^
-np 1 ^
--port 8080 ^
--jinja ^
--mmproj C:\models\mmproj-F16.gguf
━━━ Parameter Breakdown ━━━
-m <path>
Path to your .gguf model file. Change this to wherever you downloaded it.
--ctx-size 180000
Context window in tokens. 180k = huge context for long conversations or big codebases.
Reduce to 32768 or 65536 if you don't need long context — uses less VRAM.
--flash-attn on
Flash Attention — dramatically speeds up inference and reduces VRAM usage.
Works on RTX 30xx/40xx/50xx. Always enable this.
--cache-type-k q4_0 / --cache-type-v q4_0
Quantizes the KV cache (key/value attention cache) to 4-bit.
This is what makes 180k context fit in VRAM. Without it, huge contexts eat all your memory.
Quality impact is minimal — this is a free performance win.
--batch-size 1024 / --ubatch-size 512
batch-size = how many tokens are processed in one forward pass (throughput).
ubatch-size = micro-batch actually sent to the GPU per step.
Higher = faster prompt processing but needs more VRAM.
If you run out of VRAM, lower these (e.g. 512/256).
-ngl 100
Number of layers to offload to GPU. 100 = all layers on GPU (full offload).
This is what you want if the model fits in your VRAM.
If it doesn't fit, reduce this (e.g. -ngl 40) — remaining layers run on CPU/RAM.
--tensor-split 0.55,0.45
How to split model layers across multiple GPUs. Values are ratios.
0.55,0.45 = GPU 0 gets 55% of layers, GPU 1 gets 45%.
Adjust based on your VRAM — give more to the card with more memory.
Example: 0.70,0.30 for a 24GB 12GB setup.
Not needed for single GPU setups.
--main-gpu 0
Which GPU handles the batch computation (the "orchestrator").
Set to 0 (your primary GPU). The other GPU(s) handle their assigned layers.
Minor performance impact — usually just leave it at 0.
-np 1
Number of parallel slots (concurrent requests). 1 = one user at a time.
Increase to 2-4 if you want multiple clients connected simultaneously.
Each extra slot uses additional VRAM for its own KV cache.
--port 8080
Which port the server listens on. Change if port 8080 is busy.
--jinja
Enables Jinja2 template processing — required for proper chat formatting.
Most modern models expect this. Always include it.
--spec-type draft-mtp
Enables Multi-Token Prediction (MTP) speculative decoding.
Only works with MTP GGUF models (downloaded separately).
The model predicts multiple tokens at once and verifies them — big speed boost.
--spec-draft-n-max 3
How many tokens the MTP draft head proposes per step.
3 is a good default. Higher = potentially faster but more VRAM and may reduce quality.
--mmproj <path>
Path to the multimodal projector file (for vision models).
Enables image understanding — paste screenshots into the web chat.
Only needed if you want vision capabilities. Omit for text-only use.
━━━ Your Hardware → Your Command ━━━
Single GPU (8-24GB VRAM):
Use the "Single GPU" command. Change -m to your model path.
8GB card → Gemma 4-12B Q4 or LFM2.5-8B
12GB card → Gemma 4-12B Q5/Q6
16GB card → Gemma 4-31B QAT Q4 or Nex-N2-Mini
24GB card → Qwen3.6-27B Q4/Q5, Qwopus-v2, Gemma 4-31B QAT Q5/Q6
Dual GPU:
Use the "Dual GPU" command. Adjust --tensor-split based on your VRAM ratio.
24GB 24GB → --tensor-split 0.50,0.50
24GB 12GB → --tensor-split 0.70,0.30
24GB 8GB → --tensor-split 0.75,0.25
Want speed? Use MTP versions of models with the "MTP" commands.
Want vision? Add --mmproj with the projector file from the model's HuggingFace repo.
5. Once running, you get:
• Web chat UI → http://localhost:8080
• OpenAI-compatible API → http://localhost:8080/v1
• Playground → http://localhost:8080/playground
━━━ Why /v1 API Is the Killer Feature ━━━
One local endpoint replaces your entire cloud API bill. The /v1 endpoint is drop-in OpenAI-spec compatible — every tool that speaks OpenAI just works. No custom code, no glue layer.
Works out of the box with:
• IDEs: Cursor, Continue, Windsurf, Cline, Roo Code
• CLI tools: aider, Open Interpreter, OpenCode
• Frameworks: LangChain, LlamaIndex, LiteLLM
• Any OpenAI SDK (Python, Node, Go, Rust)
Why this beats cloud APIs:
• 100% private — code never leaves your machine
• $0 per token — no rate limits, no quotas, no surprise bills
• Works fully offline
• Zero telemetry, no training on your data
• Swap models by dropping in a different .gguf — no app changes needed
• Run 32k–128k context windows without burning money
Good combos:
• Cursor Qwopus-v2 → near-frontier quality, zero API cost
• Continue Qwen3.6-27B → best local coding agent
• aider Gemma 4-12B MTP → 162 tok/s, feels instant
• OpenCode Nex-N2-Mini → deep reasoning on 16GB
Set any OpenAI-compatible client to your local endpoint:
set OPENAI_API_KEY=sk-dummy (any non-empty string works)
set OPENAI_BASE_URL=http://localhost:8080/v1
# every OpenAI-compatible tool now hits your local GPU
Shoutouts: @0xSero @rS_alonewolf @witcheer @UnslothAI @LottoLabs
45
118
1,275
159,548
Danny Ackerman retweeted

Jun 12
Kids today will never understand how hard the Knight Rider intro went🚘
That theme still hits different.
140
685
4,332
108,307
Danny Ackerman retweeted

May 25
MrBeast plans to trap 1000 vibe coders in a room without Claude
first person to center a div manually wins $1 million


700
1,845
48,861
2,114,748

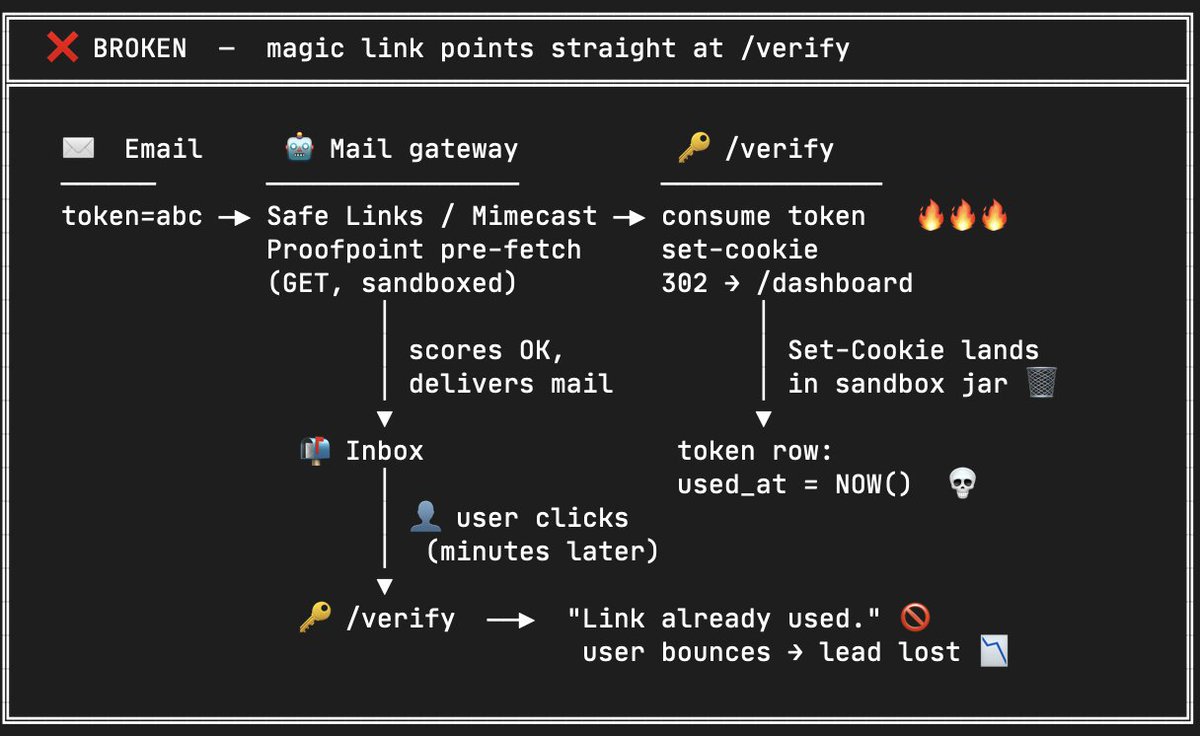
if your saas uses magic link signup, check this right now:
your link in the email shouldn't call the verify api directly.
there should be an interstitial confirm page instead.
here's why:
corporate email scanners (microsoft safe links, mimecast, etc) pre-fetch every url in incoming mail. they burn your single-use token before the user even clicks.
then user opens the email, sees "token invalid", retry 2 times, gives up.
cost us two F500 leads before we caught it.
fix: email points to a page with a "sign me in" button → POST from that button hits your verify api.
49
32
594
65,973

May 11
Really liking @Cloudflare workers. Just created an agent that emails me cooking tips every day. Using D1 database to store previous tips so I don't get repeats.
22
Danny Ackerman retweeted

May 10
One of the problems engineers had with recovering Voyager 1 was there was no emulator or assembler for the computer they had to reprogram.
Vintage computer fans had wanted to document this hardware for years, but when we asked NASA for info they said no.
Finally someone tracked down some old JPL memos in a filing cabinet in Kansas and got all the information needed to build and emulator for the hardware.
Imagine how much easier the Voyager 1 recovery would have been if NASA had just said 'Yes' to those inquisitive vintage computer nerds a decade ago.
zanehambly.com/voyager
55
197
3,481
138,069
Danny Ackerman retweeted

May 6
We know the community has been asking for Flutter/Dart skills! So excited they are out now!
May 6

Introducing Agent Skills for Flutter and Dart to give your AI tools domain-specific expertise 📓
These initial core Skills are designed to handle the most common Flutter development hurdles. Learn how to start using them in your workflow → goo.gle/4uBRR6M
4
82
6,923
Danny Ackerman retweeted

Apr 30
30
152
1,318
1,720,445
Danny Ackerman retweeted

Apr 27
I don’t usually share things like this, but I think it’s important to be honest.
I’ve been looking for a full-time role since September.
I’m a senior iOS engineer product designer with 10 years experience, and I’ve spent that time building and shipping real products (most recently: @ateiq_app, @naturalis_app, @getuppapp).
Despite interviews and ongoing work, I’m now about a month away from needing something stable for my family.
If you know a team that values someone who can both design and build, I’d really appreciate an introduction.
Thank you! ❤️
123
303
2,108
689,192
Danny Ackerman retweeted

Mar 26
This guy rage coded a $199 app in less than an hour and cooked the OP.

134
208
9,669
1,647,702
Danny Ackerman retweeted

Mar 26
Your one-minute clock starts now.
Prompt 1 to Grok: "Review the video in the post. Create a detailed project requirements document to exactly recreate the app in the video" - about 15 seconds of typing
Prompt 2 to Claude Code: "Go into planning mode and create a detailed plan to implement the app described in the attached PRD" - about 15 seconds of typing. Although I did have to come back and type "1" to give it permission to execute the plan.
Prompt 3 to Claude Code: "Push this to a public repo." - about 5 seconds of typing
All coding about 60 seconds of my time. The longest part was trying to figure out how to screen capture a video with system audio. That flummoxed me for three to four minutes.
github.com/magnum6actual/fli…
78
94
4,973
614,445
Feb 18
Awesome project. Sitting on my desk now.
Feb 16

Turn your desk into a command center with this 3D-printed ESP32 terminal that displays the weather, time, date, and more. hackster.io/news/your-desk-n…
20
Feb 11
how are some people so insanely good at design? I couldn't make this if my life depended on it.
Feb 11

Experimenting with looks of the navigation bar in my terminal-learning app built with #flutter
1
118



🧐 Flutter tips
How to code a cool timer like this
Using a custom painter
#fluttertips #flutterdev
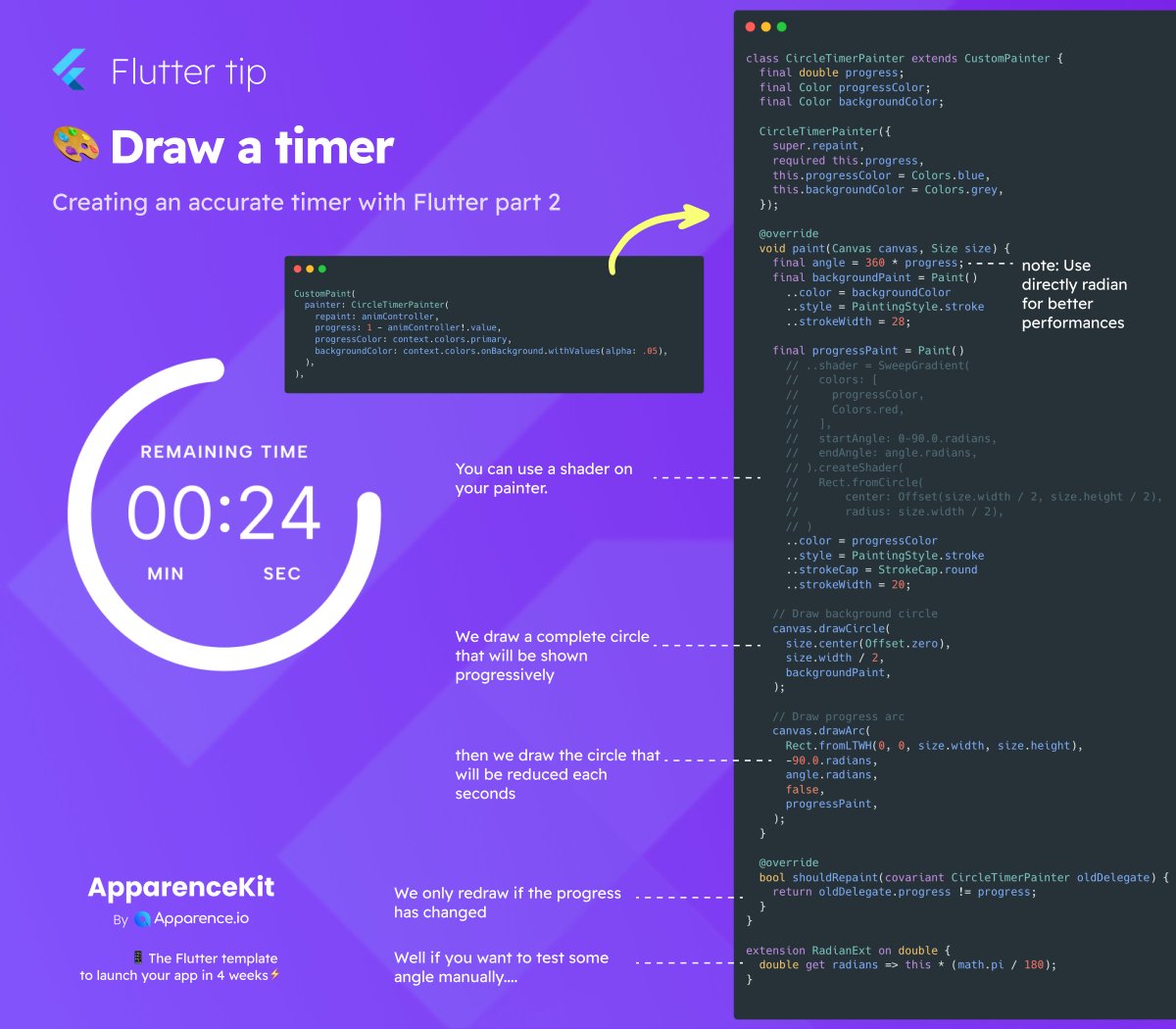
2
9
83
2,443
Feb 2
Awesome.

A ‘Jurassic Park’-themed #SuperBowl ad for Xfinity has been released.
Sam Neill, Laura Dern and Jeff Goldblum all reprise their roles.
31
Danny Ackerman retweeted

Textf 1.1 is out 🎉
It's Text with **bold** and *italic*. A lightweight drop-in replacement for #Flutter's Text widget.
NEW in v1.1:
→ {widget} placeholders - embed anything inline
→ Caching that doesn't panic when your parent rebuilds
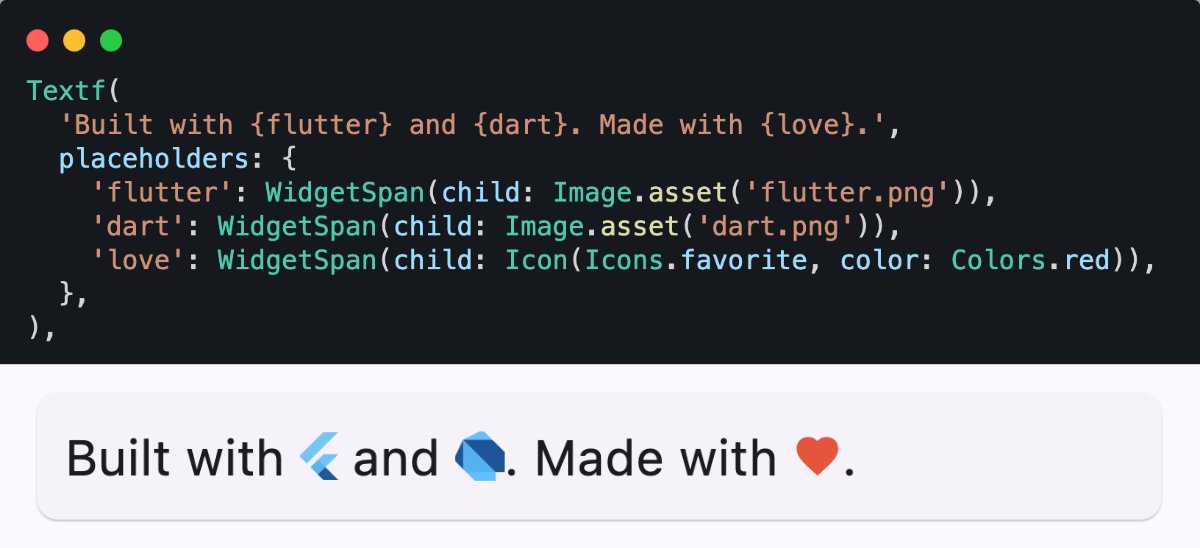
11
16
183
4,833
Danny Ackerman retweeted

Jan 15
NEW Raspberry Pi AI Hat Is a Massive Upgrade
@Raspberry_Pi
94
591
4,964
224,863
Danny Ackerman retweeted

This week marks 15 years since I was shot. Watching the president and his administration target my husband for speaking out is beyond disappointing—it’s a disturbing abuse of power that should alarm every American.
@CaptMarkKelly is driven by principle and duty. No bully can diminish his unwavering commitment to our country.

Over twenty-five years in the U.S. Navy, thirty-nine combat missions, and four missions to space, I risked my life for this country and to defend our Constitution – including the First Amendment rights of every American to speak out. I never expected that the President of the United States and the Secretary of Defense would attack me for doing exactly that.
My rank and retirement are things that I earned through my service and sacrifice for this country. I got shot at. I missed holidays and birthdays. I commanded a space shuttle mission while my wife Gabby recovered from a gunshot wound to the head– all while proudly wearing the American flag on my shoulder. Generations of servicemembers have made these same patriotic sacrifices for this country, earning the respect, appreciation, and rank they deserve.
Pete Hegseth wants to send the message to every single retired servicemember that if they say something he or Donald Trump doesn’t like, they will come after them the same way. It’s outrageous and it is wrong. There is nothing more un-American than that.
If Pete Hegseth, the most unqualified Secretary of Defense in our country’s history, thinks he can intimidate me with a censure or threats to demote me or prosecute me, he still doesn’t get it. I will fight this with everything I’ve got — not for myself, but to send a message back that Pete Hegseth and Donald Trump don’t get to decide what Americans in this country get to say about their government.
7,479
7,332
32,223
826,712