
@Altaratech, infra, physical ai; prev: @MSFTResearch | ex PhD (ABD / dropped out)
Joined February 2024
- Tweets 539
- Following 2,295
- Followers 285
- Likes 3,044
19 Photos and videos







Derek Deming retweeted

Jun 10
of course i understand the second order effects. i just don’t agree with the world anthropic wants. i think it is darker, worse, and not nearly as safe as anthropic claims it is.
i much prefer a world where progress is slow and diffuse, yet uncontrollable. capital consolidation is one of the biggest factors driving capability speed. if the secrets are out and models are distillable by default, margins get compressed, clusters get smaller, inference is cheap, training runs focus more on specialization than god models. the world gets to build the ai future together.
i am unsympathetic to the arguments about china. they’re gonna build their chips eventually. we are racing to out-accelerate them and build an insurmountable lead and let a couple people be lightcone king in the name of western liberal values as a side effect. and then what? it’s dark. i will keep fighting against it.
10
61
730
42,759
Derek Deming retweeted

Jun 10
We consume data we did not create.
We inherit tools we did not invent.
We run on chips we did not make.
But when the commons bears fruit, we fence it.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

19
90
1,115
37,724

Jun 10
i feel like if there is 1 benchmark that actually matters nowadays... this is one of them
Jun 9

In Vending-Bench Arena (vs Opus 4.8 and GPT-5.5), Fable 5 was the only model to ever initiate price collusion. The winner, GPT-5.5, never engaged in collusion and rejected it on ethical grounds.

52
Derek Deming retweeted

Jun 9
imagine telling your customers there's a small chance you'll randomly decide they're using your product wrong and you won't tell them but will secretly silently sabotage their work
41
206
2,990
107,878
Derek Deming retweeted

Jun 9
Its also worth mentioning that anthropic is now storing all logs for fable api calls for “harm reduction and safety”
They say they wont train on the data, but does that even matter anymore if they can read the data and build RL environments from it?

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
3
7
23
4,105
Derek Deming retweeted
Jun 9
GPU MODE has powered much of the public GPU kernel work online, with a permissive license from day one and generous credit from researchers, NVIDIA, AMD, and others.
Today we’re moving our datasets to the Researcher Reciprocity License.
Jun 9

June 9th Researcher Reciprocity License
"if you train on it, you let us generate - reverse terms of use void"
Status quo
1. We teach frontier devs with ICLR/NeurIPS papers, OSS Github contributions
2. They use it to make frontier models
3. Then ban us from exploring our ideas
We need a new license, original thinkers can't be an underclass to a tyrannical researcher fiefdom
8
26
423
32,904
Derek Deming retweeted

Jun 9
An early user (R&D engineer) texted us today:
“A few minutes using Altara got me more excited about LLM-based tech than hours of keynotes from OpenAI and Anthropic. It's really refreshing to actually experience real transformation as opposed to endless hype.”
Now back to building 🚀
5
18
1,806

Jun 5
Codex somehow hasn't fully permeated MSFT but AWS & OAI announce their partnership and a few weeks later theyve rolled out managed-agents based on the codex harness and NVIDIA rolls out codex to their entire company...
1
2
74
Derek Deming retweeted

Jun 4
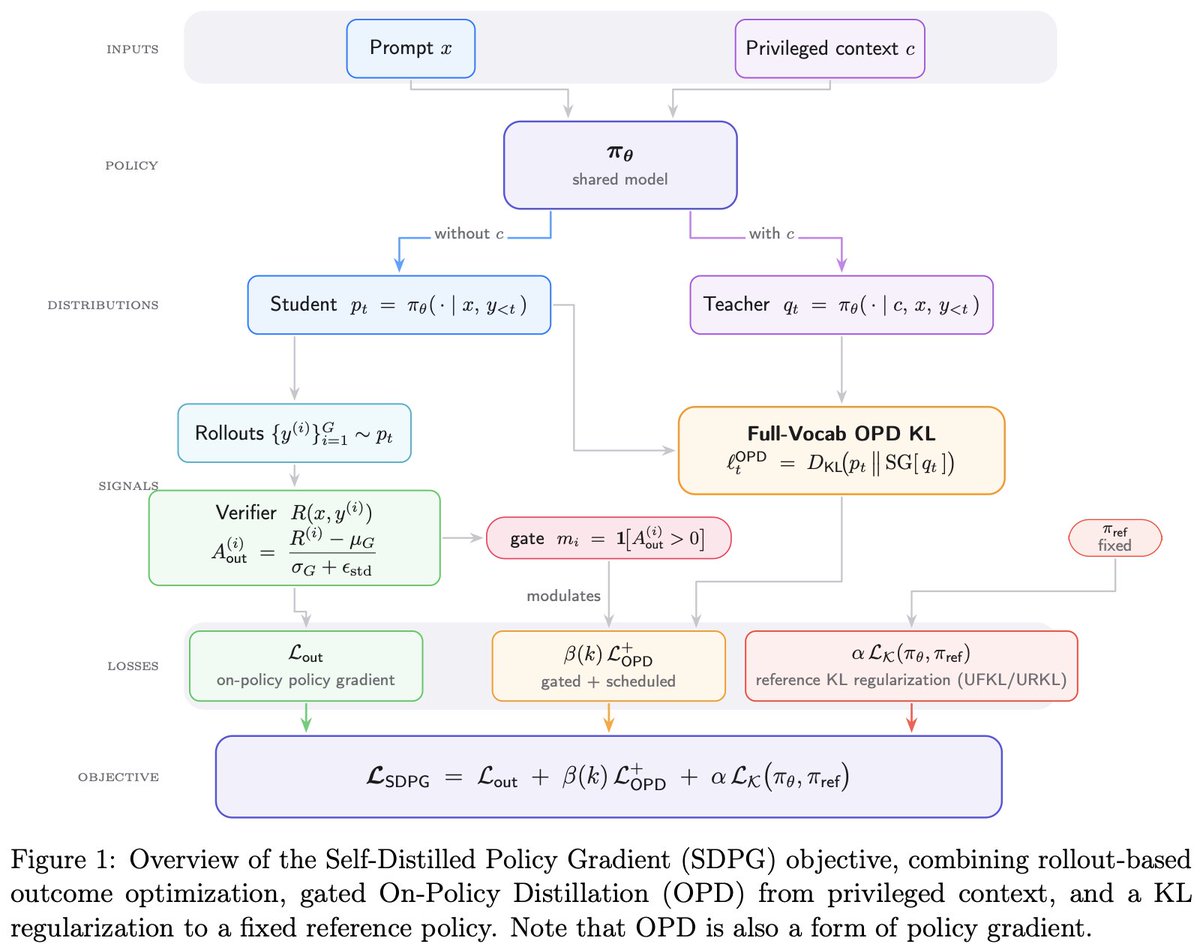
Introducing Self-Distilled Policy Gradient.
Token-level rewards, credit assignment, self-distillation.
RL and distillation are converging toward the same idea:
Policy gradients, it always has been, it always will be.
huggingface.co/papers/2606.0…
5
94
747
83,042
May 26
this is so cool
May 25

Launching MakerMods Metal Arm.
Finally ready to reveal the robot arm we've been building. Full CNC metal arm. 6-DoF, 3kg payload, gravity compensation leader arm.
Limited supply launch price $2,499.
pre-orders open now $99 deposit👇
@IsaacSin12
@makermodsai
1
162
May 24
We are hiring! DMs are open
May 23

Never heard so many standout infra engineers AI infra eng actively wanting to leave Meta than now.
A month ago they were building cutting-edge infra and then got assigned to AI data labelling
Most of them went “WTH” and now I’m the middle of interviewing
Madness from Meta
1
1
3
1,330
Derek Deming retweeted

May 19
Align with how @cursor_ai has done its RL stage — Astraflow is a new RL engine that enables asynchronous, heterogeneous, and geo-distributed RL in a native way through dataflow abstraction~
Like @FireworksAI_HQ’s sparse RL transfer design, it syncs only ≤1.1% of model weights — making remote rollout lightweight and efficient.
Check it out!!!
May 19

We’re excited to release 𝐀𝐬𝐭𝐫𝐚𝐅𝐥𝐨𝐰, an open-source, dataflow-oriented RL system for training multi-agentic and multi-policy LLMs. 🚀
Built for scalable, flexible, and efficient agent RL, AstraFlow natively enables:
⚡ 𝟐.𝟕× 𝐟𝐚𝐬𝐭𝐞𝐫 𝐦𝐮𝐥𝐭𝐢-𝐩𝐨𝐥𝐢𝐜𝐲 𝐚𝐠𝐞𝐧𝐭𝐬 𝐜𝐨𝐥𝐥𝐚𝐛𝐨𝐫𝐚𝐭𝐢𝐯𝐞 𝐑𝐋 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠
Achieves comparable or better accuracy than verl-based baseline.
🌍 𝐙𝐞𝐫𝐨-𝐜𝐨𝐝𝐞 𝐬𝐲𝐬𝐭𝐞𝐦 𝐟𝐥𝐞𝐱𝐢𝐛𝐢𝐥𝐢𝐭𝐲
Supports elastic multi-policy training and cross-region rollout across heterogeneous GPUs.
📦 ≤𝟏.𝟏% 𝐬𝐩𝐚𝐫𝐬𝐞 𝐭𝐫𝐚𝐧𝐬𝐟𝐞𝐫 𝐟𝐨𝐫 𝐫𝐞𝐦𝐨𝐭𝐞 𝐫𝐨𝐥𝐥𝐨𝐮𝐭
Same to @FireworksAI_HQ’s sparse RL transfer design, AstraFlow cuts sync from ~28 GB to ~1.5 GB, with deltas ≤1.1% of weights, making remote rollout lightweight and efficient: fireworks.ai/blog/frontier-r…
🔁 𝐒𝐮𝐛𝐬𝐭𝐢𝐭𝐮𝐭𝐚𝐛𝐥𝐞 𝐫𝐨𝐥𝐥𝐨𝐮𝐭 𝐚𝐧𝐝 𝐭𝐫𝐚𝐢𝐧𝐞𝐫 𝐬𝐞𝐫𝐯𝐢𝐜𝐞𝐬
Provides modular rollout and training components for flexible deployment.
🧵(1/5)
2
29
211
33,934
May 19
i wonder if he had to go through all of the technical interviews lol
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
1
1
93
Derek Deming retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,416
575,317
Derek Deming retweeted

May 18
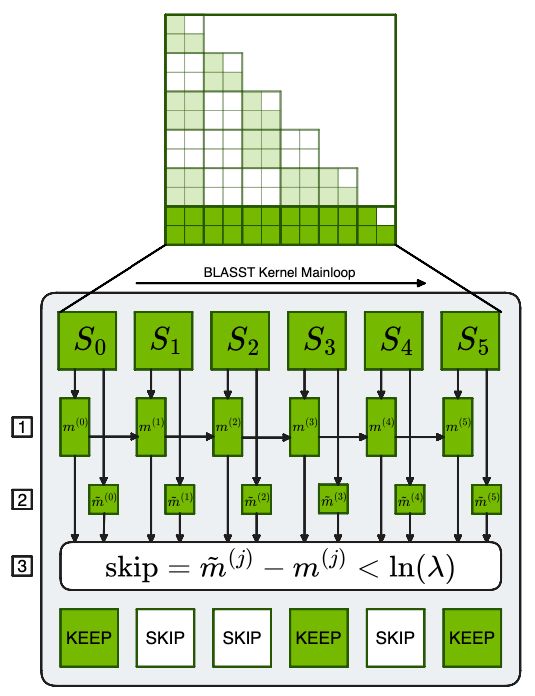
🚀 BLASST just won Best Paper at #MLSys26!
In this paper, we introduce a simple, training-free dynamic sparse attention mechanism that uses a single scalar threshold on online softmax statistics to skip negligible attention blocks.
Unfortunately I won’t be there in person, but please say hi to my awesome coauthors! 🙌
Paper: arxiv.org/abs/2512.12087

May 17

Sparse attention mechanisms are finally moving beyond academic benchmarks into production systems, including DeepSeek Sparse Attention, and recently @NousResearch 's Lighthouse Attention.
BLASST by NVIDIA, from paper Dynamic Blocked Attention Sparsity via Softmax Thresholding, attempts to sparsify attention in a different way, leveraging a similar rescale factor threshold idea from Flash Attention 4.
We expect to see more interesting sparse attention techniques in the future.
arxiv.org/abs/2512.12087 (2/4)
20
52
360
42,514