
Voice AI - CEO @ Deepgram
Joined September 2015
- Tweets 554
- Following 954
- Followers 1,168
- Likes 497
64 Photos and videos












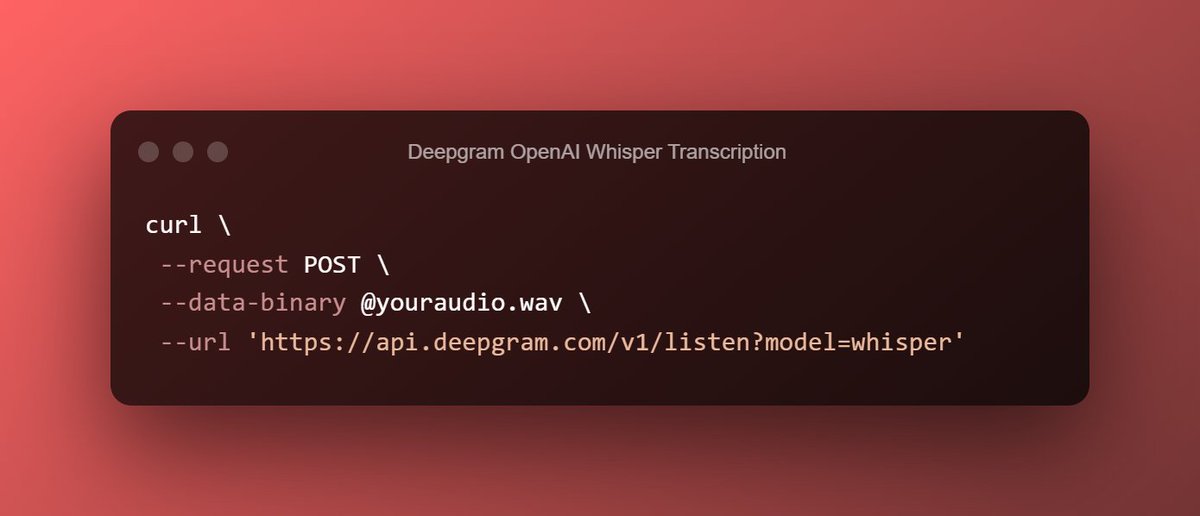
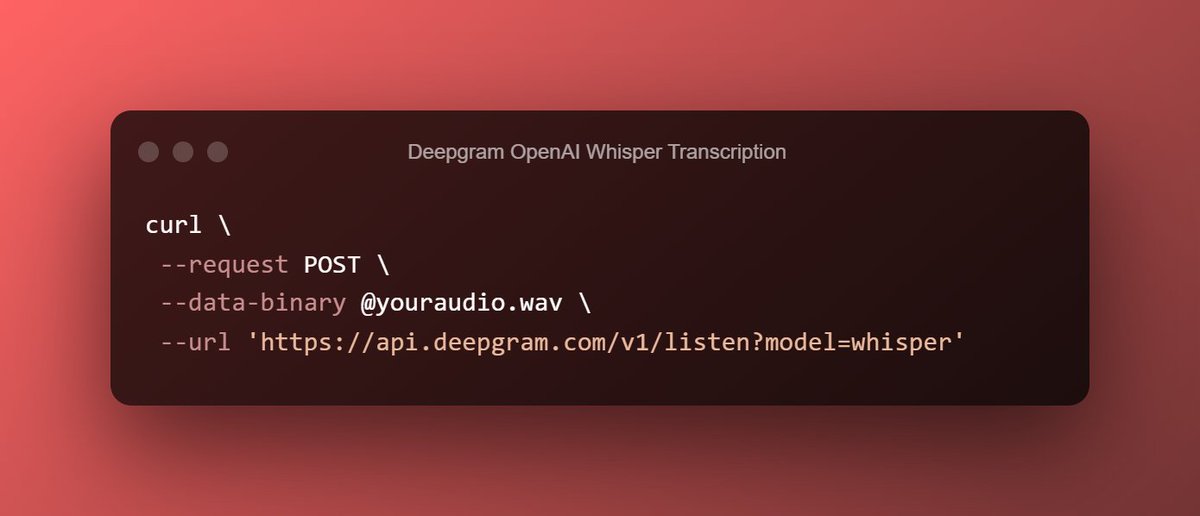
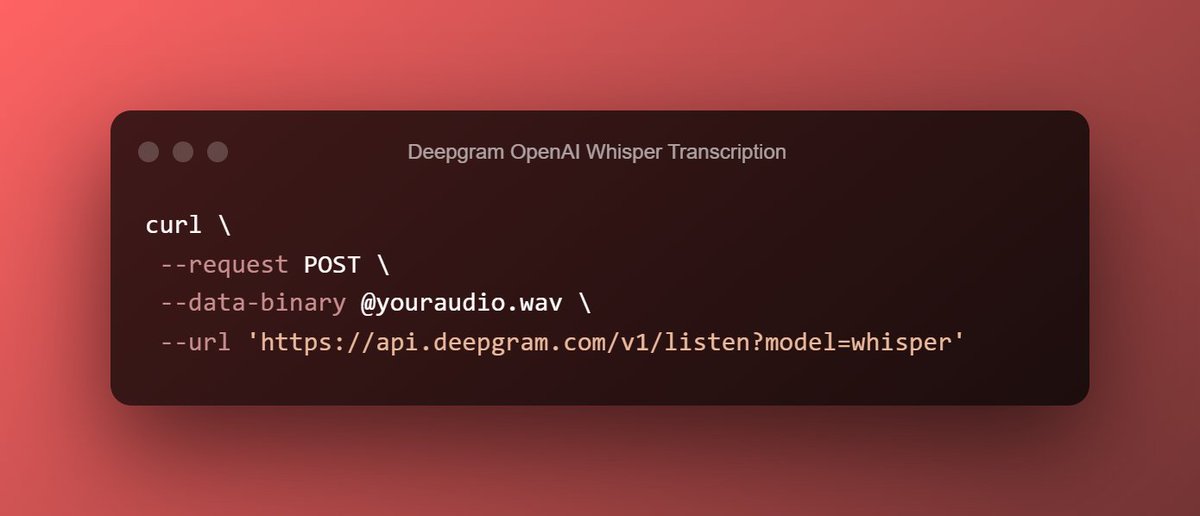
I have a question for anyone reading this.
Could you have a conversation with a voice agent for 5 minutes without realizing it isn't human?
I call this the Audio Turing Test. A few years ago, that idea sounded ridiculous. Today, speech recognition, voice generation, and reasoning have improved so quickly that it feels within reach.
The interesting question isn't whether we'll get there. It's what's still missing before we do.
I'll leave you with this: it's a very exciting time to be building in voice AI (we're closer than most people think). 🔥
4
4
96
AI addiction isn't a question of if. It's a question of when.
The moment an AI solves something you've struggled with instantly, your brain gets rewarded.
"That was easy. Give me more."
Social media took 10 years.
AI might take 2. Or maybe it's already here?
4
88

May 28
It’s much easier to build an impressive AI model when efficiency isn’t part of the challenge.
More GPUs. More compute. More energy.
Building efficient models is harder because you have to optimize for everything at once:
- performance
- latency
- scalability
- training cost
- inference cost
The flashy models get attention first, but the efficient models are the ones the world eventually runs on.
3
8
203
May 25
In 10 years, typing on a keyboard all day will look absurd.
For decades, humans learned how to communicate with computers.
Now computers are finally learning how to communicate with humans.
Once Voice AI becomes truly real-time, reliable, and deeply contextual, typing will starts to feel inefficient.
Not nostalgic -- inefficient.
8
5
20
2,088
May 20
I’m in Seattle this week.
I saw the replica of the Voyager aircraft at the airport -- designed by Burt Rutan and flown by Dick Rutan and Jeana Yeager.
This aircraft flew around the world nonstop without refueling!
- 9 days in the air.
- Two people onboard.
- A tiny unpressurized cockpit.
- Sleeping in shifts under brutal conditions with almost no margin for error.
Burt Rutan and the team behind Voyager proved that breakthrough ideas rarely begin polished or comfortable. They start constrained, experimental, and slightly insane!
It's a good reminder that ambitious things are usually built under imperfect conditions.


1
4
189
May 19
Most people think speech-to-speech is just speech-to-text, an LLM, and text-to-speech stitched together.
That’s how a lot of systems are built today. But it’s not really how conversations work.
In a real interaction, everything is continuous. Tone, context, environment, intent -- all adjusting in real time depending on who you’re talking to and where you are.
Those things don’t pass cleanly between separate systems.
1
6
121
May 14
A little about me: I’ve always loved motocross.
You can’t debate a jump. You either commit or you don’t. If you hesitate halfway through, it usually ends badly.
Most of what I do day to day rewards more thinking.
On a track, that doesn’t exist. The feedback loop is immediate and very clear. I love the thrill, and it’s a great reset day for me.
1
4
138
May 12
Real-time voice is challenging, because humans communicate through far more than just words.
It's a fun challenge 😎
May 8

Real-time voice: there are huge challenges, but they're not impossible to solve.
Here's @deepgramscott, at Cerebral Valley Voice:
2
7
790
May 11
We’re entering a world where AI won’t just understand words (and it's very exciting! 🔥)
It will need to understand people.
Human communication is rarely literal. A pause can signal uncertainty. A faster response can signal confidence. Silence can completely change the meaning of a sentence.
Then there’s tone, emotion, sarcasm, stuttering, whispering, hesitation, and all the non-word cues we process instinctively every day.
“Uh…”, “Umm…”, “Ahh…”, “Oh…”, “Mm-hmm”, “Huh?”, “Uh-oh”, “Pfft”
The next generation of AI systems will need to understand nuance in real time -- and be confident acting on it! 😎
1
3
93
How many hours do people actually talk per day?
Roughly one and a half, depending on the person.
What's more interesting is everything around it. The other sixteen and a half hours are still context gathering. Reading, reacting, listening, thinking. By the time you speak, you're compressing a much larger stream of context into a few hours of words. Most of that context never gets captured.
I started noticing this in my own work. I'd have a question early in the week, revisit part of it in a conversation later on, and then something related would come up again, but the original thread was gone.
So I built something for myself that keeps track of the last couple of weeks of context. It runs on @DeepgramAI.
I call it Bodyman. 😎
But it doesn’t just listen. It has permission to act. The other day I was late for a meeting, and it spoke into my headphones telling me I'm late, and that I should join -- because it knew the meeting was important.
It’s like having a second layer of awareness that doesn’t forget.
It’s been surprisingly useful!
1
2
10
3,509
Apr 29
Today is a major step forward for @DeepgramAI in building truly global voice AI. 🚀
I’m proud to introduce Flux Multilingual -- a single perception model that allows developers to build voice agents that can understand and respond across languages, even switching mid-conversation.
Until now, global voice deployments required stitching together multiple systems -- adding latency, inconsistency, and operational overhead. Customer experiences would break the moment language changed.
Flux Multilingual removes that constraint. With one model, enterprises can deliver fast, natural, real-time conversations across markets -- without compromising on performance or consistency! 🔥
Apr 29

Flux Multilingual is live.
Real-time conversational speech-to-text for voice agents in 10 languages, with monolingual-grade accuracy, turn detection, and code-switching.
Deploy once and launch globally.
Learn more → deepgram.com/learn/introduci…
1
2
5
995
Apr 21
I’m excited to join the Voice Summit lineup. For those attending, see you in San Francisco!
Apr 17
.@deepgramscott, founder and CEO, @DeepgramAI.
All talk. All action. May 6 in San Francisco.
Apply now to join us: cerebralvalleyvoice.com

2
1
5
294
Success requires more urgent change than failure does.
1
8
178
24 Dec 2025
Amazing to see so many partners powered by Deepgram in this post. (An overwhelming majority!)
1
4
509
Scott Stephenson retweeted

16 Oct 2025
The Deepgram team is getting together and hosting an open house in San Francisco on October 22nd!
If you're an innovator in the Voice AI space, here's a few reasons why you should join us:
✅ Connect directly with our founders, engineers, and product team
✅ Share feedback and help shape our roadmap
✅ See live demos and get behind-the-scenes insights into how we build voice AI
✅ Network with fellow builders and partners including @covaldev, @Vapi_AI, @trydaily, and @livekit
✅ Enjoy great food, drinks, and conversation
------
📅 Wednesday, October 22, 2025 | 5:30 – 8:00 PM
📍 San Francisco, CA
🔗 RSVP: luma.com/deepgram-open-house
Whether you're already building with Deepgram or exploring what's possible with voice AI, we'd love to see you there. Let's build the future together

3
9
822

A new transcription model from @DeepgramAI launched today: Flux.
Flux is completely free for all of October, and is integrated into Pipecat and Pipecat Cloud.
This model shows where speech recognition is headed, as speech models evolve to enable more and more voice agent use cases.
Deepgram has always been the market leader in very low latency transcription. (Which is critical for conversational voice!) My "magic number" here is 300ms. I want the finalized transcript to be delivered no more than 300ms after the user stops speaking.
One reason that 300ms is a good baseline number is that the open source native audio Smart Turn model that's used in a lot of voice agents makes a turn detection decision within 300ms. We want the transcript and the end-of-turn event to be available at the same time.
Of course, you might not need to use the Smart Turn model at all, anymore. Because Flux has quite good turn detection implemented directly in the model. It's great to see progress in turn detection, because good turn detection makes such a difference in the experience of talking to a voice agent.

5
14
104
8,181
3 Oct 2025
This is such a a good demo of Flux
3 Oct 2025

Deepgram's new Flux model is good. They added "eager EOT" which predicts when you're done speaking and immediately finalizes the transcription without needing VAD. Live transcripts look great, and they're really, really fast.
Here's a demo I built w/ Agents, all code below
3
7
672
Scott Stephenson retweeted
26 Aug 2025
Nova-3’s best-in-class transcription now extends to 🇩🇪 German, 🇳🇱 Dutch, 🇸🇪 Swedish, and 🇩🇰 Danish.
- Keyterm Prompting (industry-first)
- Accurate in noisy conditions
- Proven WER KRR gains
Read more: dpgr.am/4fd28
#VoiceAI #SpeechToText #EnterpriseAI
2
2
14
720