
Software dev and psychologist, keen on functional programming. Former neuroscientist. Game AI researcher at night. Petty dabbler of the cognitive arts. He/they.
Joined June 2012
- Tweets 33,830
- Following 2,871
- Followers 697
- Likes 79,121
1,229 Photos and videos














Pinned Tweet

La donación de médula ósea salva muchas vidas. Por favor, lee esto y pásalo. Es muy poco intrusivo y darás vida a mucha gente.
fcarreras.org/es/donamedula
1
9
17
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

Jun 14
the amount of "software engineers" i see on the timeline who don't know what the word "iff" means, and assume their LLM made a typo, is concerning for several reasons
95
32
1,999
241,091
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

Jun 12
What is an LLM Control Plane, and why does it matter for modern AI teams?
In our latest blog post, Anushri Gupta (Founder, DevRel at Mozilla.ai) breaks down the challenges of running LLMs in production and explains how a control plane goes beyond gateways to deliver the observability, governance, and reliability that today’s AI infrastructure demands.
Whether you’re building with LLMs now or planning for the future, this piece is a must-read.
Read the full article: blog.mozilla.ai/what-is-an-l…
#AI #LLM #MLOps #AIInfrastructure #MozillaAI #otari-ai
1
4
63
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 29
Una niña pelirroja con vaqueros, una construcción de LEGO en las manos y una sonrisa que no está posando para nadie. Esa imagen lleva más de cuarenta años siendo uno de los anuncios más citados de la historia de la publicidad.
Se llamaba Rachel Giordano. Tenía unos siete años cuando la fotografiaron para la campaña de 1981. El titular decía simplemente: What it is is beautiful. Lo que es, es hermoso. Sin mencionar si era niña o niño. Sin color rosa. Sin instrucciones sobre qué debía construir.
Lo que muchos recuerdan como un gesto revolucionario de LEGO en realidad era la continuación de algo que la empresa danesa llevaba haciendo desde los años 50: vender sus piezas como un juguete universal. Los sets se llamaban Universal Building Sets. La creatividad era el producto, no el género del comprador.
Lo interesante llegó después.
En los años siguientes, LEGO fue derivando hacia una segmentación por géneros cada vez más marcada. En 2012 lanzó LEGO Friends, una línea diseñada específicamente para niñas, con colores pastel, figuras femeninas estilizadas y sets de cafeterías, salones de belleza y boutiques. Las críticas fueron inmediatas.
Fue entonces cuando alguien rastreó a Rachel Giordano, la niña del anuncio de 1981. La encontraron: tenía 37 años y era médico. En una entrevista con Adweek en 2014 fue directa: en 1981 los LEGO eran universales y la creatividad del niño producía el mensaje. En 2014, era el juguete el que le decía al niño quién debía ser.
LEGO escuchó, al menos en parte. En 2021, en el 40 aniversario del anuncio original, la empresa lo recreó para el Día Internacional de la Mujer bajo el nombre Future Builders y se comprometió públicamente a eliminar los estereotipos de género de sus productos y campañas.
El anuncio de 1981 no era radical para su época. Se volvió radical cuando la industria fue en dirección contraria.

32
1,130
5,400
242,775
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

For this scene in Sh! The Octopus (1937) the filmmakers pulled off a real-time monster transformation without a single camera cut.
To turn actress Elspeth Dudgeon into a hideous hag, her face was painted with a single shade of red makeup. Shot on black-and-white film through a matching red lens filter, the makeup became completely invisible.
The filter was whipped away at the same time as Dudgeon removes her wig, instantly revealing the ‘monster make-up’.
Not going to lie, if I'd been in the audience for this in 1937, I would have sh*t myself.
ᴄʀᴇᴅɪᴛ: ʜɪꜱᴛᴏʀʏɪɴᴠɪᴅᴇᴏꜱ | ʏᴏᴜᴛᴜʙᴇ
28
393
5,197
466,727
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 28
"why use google?" webpage from 1999

197
8,717
74,509
890,348

For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
May 27

Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
pub.sakana.ai/diffusionblock…
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: arxiv.org/abs/2506.14202
GitHub: github.com/SakanaAI/Diffusio…
🐟
154
640
5,768
742,514
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 26
PICARD: Data, shields up
DATA: Brilliant! Shields can reduce damage we sustain. Not immunity. Not hubris. Just prudence. It's not precaution—it's strategy.
[camera shakes]
WORF: HULL BREACHES ON NINE DECKS
DATA: Here's what happened: you told me to raise shields, and I didn't
305
4,859
50,506
1,385,691
I had the pleasure to work with Alex for a couple of years. He has extensive technical knowledge, is always open to discussion, and behaves consistently in a professional way. He'd be a great addition to any remote team.
May 13

I’m considering my next career step and would be happy to hear about interesting remote backend/infra roles.
My background is mostly in Elixir/Erlang/OTP, distributed backend systems, Kubernetes, observability, and telecom/AAA platforms.
I’m especially interested in technically strong teams working on infrastructure, observability, databases, Kubernetes, or distributed systems. I’m based in GMT 5 and open to working with teams across compatible time zones.
If your team is hiring for something similar, feel free to DM me or point me to the right person.
1
31
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 13
I’m considering my next career step and would be happy to hear about interesting remote backend/infra roles.
My background is mostly in Elixir/Erlang/OTP, distributed backend systems, Kubernetes, observability, and telecom/AAA platforms.
I’m especially interested in technically strong teams working on infrastructure, observability, databases, Kubernetes, or distributed systems. I’m based in GMT 5 and open to working with teams across compatible time zones.
If your team is hiring for something similar, feel free to DM me or point me to the right person.
1
6
19
6,215
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 22
The main thing that LLMs have done in software is bring back the idea that productivity is measured in lines of code per day.
An idea that has been debunked, disproven, and discredited repeatedly every few years in my long software career.
50
132
1,405
25,226
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted
May 21
The new home for linux-insides is in progress

2
9
99
6,892
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 18
Quando você não tem pendrive ou rede e precisa transferir os arquivos de qualquer modo 🤯🤯🤯
720
3,559
37,037
4,290,476
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted
I honestly believe we're living in a Golden Age of Horror, and have been for quite a few years.
The downside to that is great movies come, are lauded and then vanish from the public consciousness as if they were apparitions.
So here are four (very different) movies from the last few years that I think need to be summoned from beyond and projected back onto the public eye.
Censor (2021)
Dir: Prano Bailey-Bond
The Outwaters (2022)
Dir: Robbie Banfitch
Suitable Flesh (2023)
Dir: Joe Lynch
The Rule of Jenny Pen (2024)
Dir: James Ashcroft
#horrormovies #horrorcommunity



18
51
553
22,516
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 12
This is such a great example of theory vs practice. In theory, UUIDv4 collisions don't happen (generating one million per second, probability of seeing one collision in a year is ~10^-8).
But they have been observed to happen in practice, especially in distributed systems. Why?

UUID v4 collisions are less rare than you think 💣
ALT https://news.ycombinator.com/item?id=48060054
65
296
3,426
601,584
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 6
"Nobody reviews compiler output, why review AI code?"
Wrong. We do review compiler output. Godbolt exists. Disassemblers exist. Anyone doing serious performance work reads what the compiler produced. The premise is false.
But the analogy itself is flawed. It compares two things that aren't comparable.
A compiler takes a formal language as input. Languages with grammars and semantics defined precisely enough that "what does this code mean" has only one answer.
An LLM takes natural language as input. Natural languages are ambiguous. "Write me a function that handles user input safely" has a thousand valid interpretations and a thousand more invalid ones. The LLM picks one. You don't know which. Unless you look at the code.
Compilers are built from specifications and designed to meet them. The output is the result of a defined translation. When the output violates the spec, it's a bug.
LLMs are built from whatever was in their training data. There is no spec. There can't be one, natural languages have no defined semantics that map to code.
Compilers are semantically deterministic. The same input produces output with the same behaviour, every time. LLMs are not. Partly by design and partly due to hardware variance, batch size, inference order, and floating point operations (and no setting temperature to zero does not address those). All of which can push the same prompt to produce different code.
Compilers complain loudly when the input is nonsensical. LLMs fail silently, producing plausible-looking, but wrong code.
We trust compiler output because the trust was earned across decades of use, with millions of engineers using the same tools. Early compilers were reviewed heavily. Hand-written assembly was the default because trust hadn't been earned yet.
We're at the hand-written assembly stage with AI. We may never get to the trust-the-output stage for the reasons explained above.
If you’re a software developer, you should own what goes to production. The compiler analogy is a way of skipping that responsibility.

59
151
1,097
50,768

Next Level is out in just 3 days - some people already have their preorders, which is scary and cool! I'm doing a few threads this week about some of the stuff I cover in the book, today let me tell you about two very special games.
(Pre/order it here: linktr.ee/next_level)

1
3
13
769
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

May 1
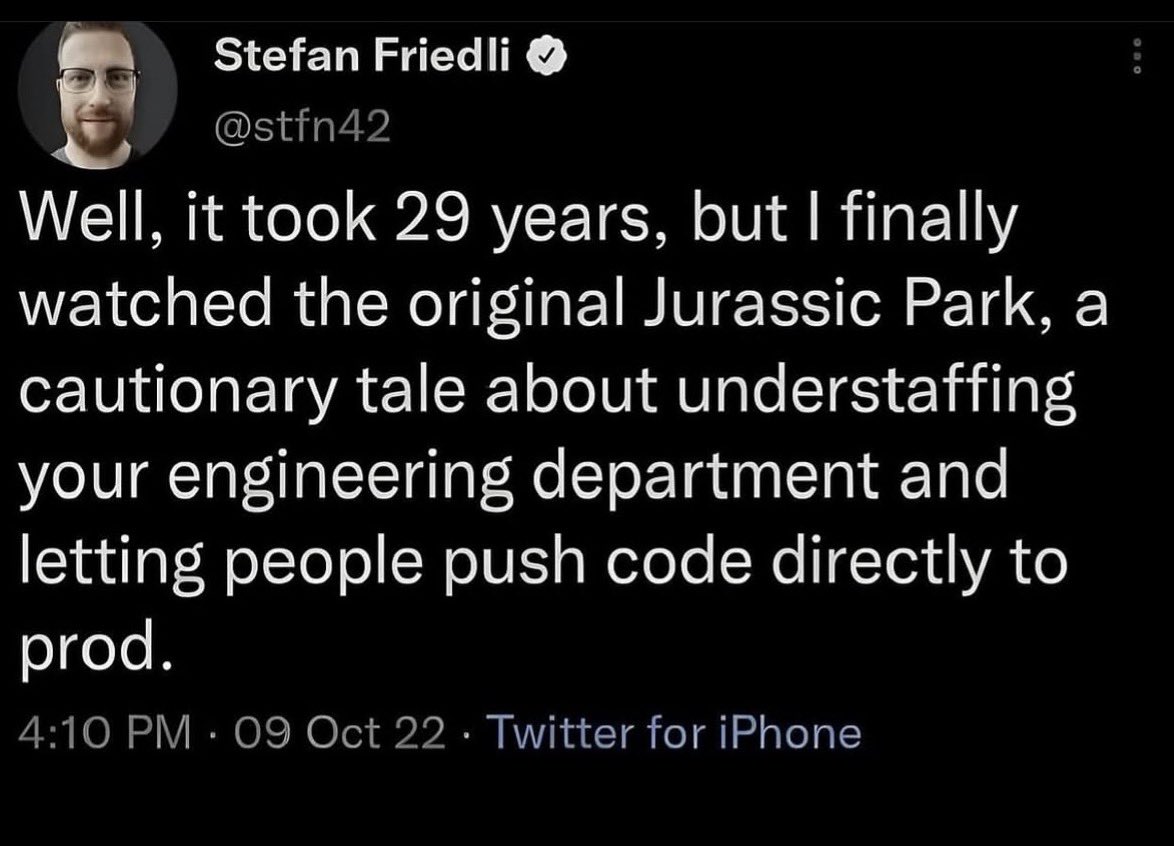
Learning lessons from Jurassic Park
57
857
10,302
573,231
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

I'm old enough to remember when 75% of a game's difficulty was just fighting it's unintuitive interface.
Those were the good ol' days. 😌
HT: Ant da comical
103
527
6,805
247,158
Javier Torres full support to 🏳️🌈🏳️⚧️ retweeted

Apr 30
Having been part of the industry for 50 years, I can confidently report that none of this is true.
Sure, writing code has a non-zero cost; this is true of any artifact.
But you know what costs even more, Jonathan?
Writing bad code; writing unnecessary code; writing more code than you really need simply because you think you might need it someday or you are too lazy or sloppy to clean up after yourself.
Anything that costs nothing is often worth nothing as well, and results in significant unintended consequences.
Apr 30

For 50 years, software engineering ran on code rationing. Writing code was expensive, so we rationed it carefully through roadmaps, RFCs, prioritization meetings, and scope reviews.
This created a role: the No Engineer. No, that won't scale. No, we don't have bandwidth. No, that's out of scope. No, we need a design doc first. The No Engineer was valuable for 50 years. Every "no" saved real money. Their judgment was the rationing system.
LLMs will be the end of code rationing. Code is cheap now. And while the No Engineer is explaining why something can't be done, the Yes Engineer has already shipped three versions of it.
If you're a Yes Engineer, the next decade is yours.
85
238
2,313
132,991