
code stonks and snark. opinions are my own. account not for sale.
Joined August 2020
- Tweets 3,968
- Following 451
- Followers 562
- Likes 7,650
551 Photos and videos


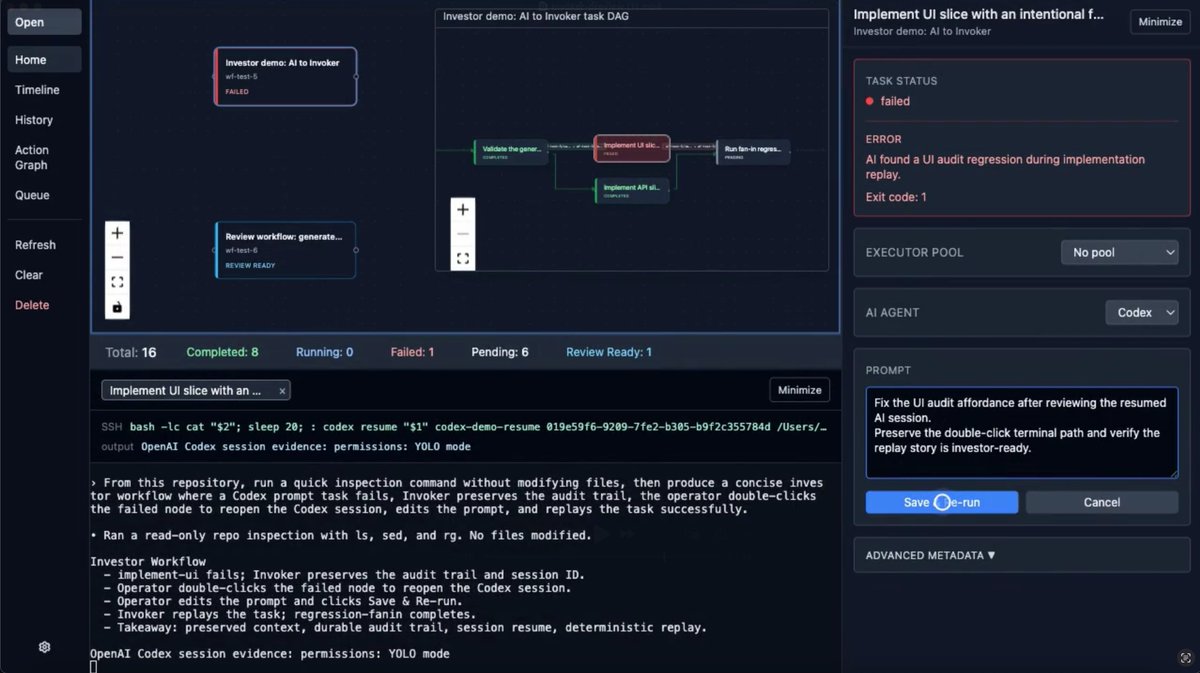


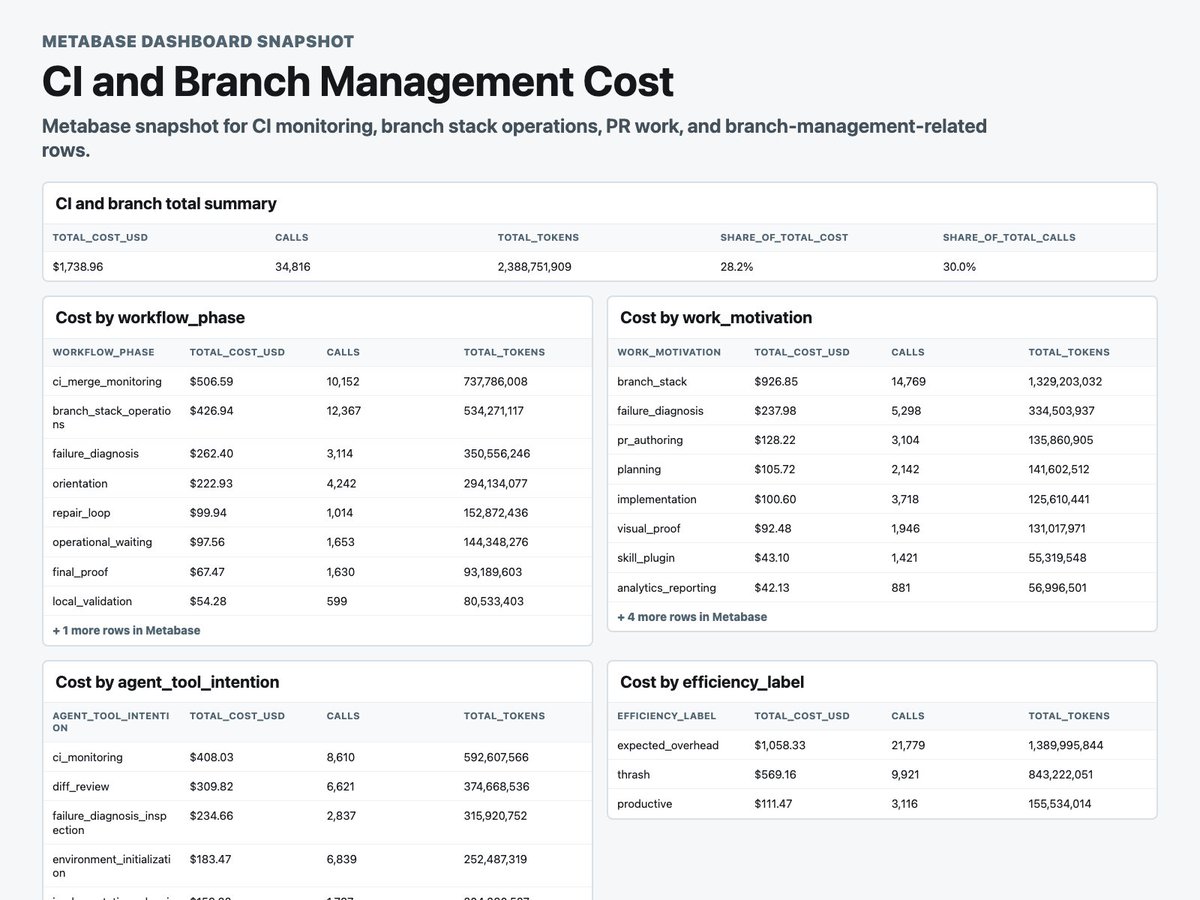








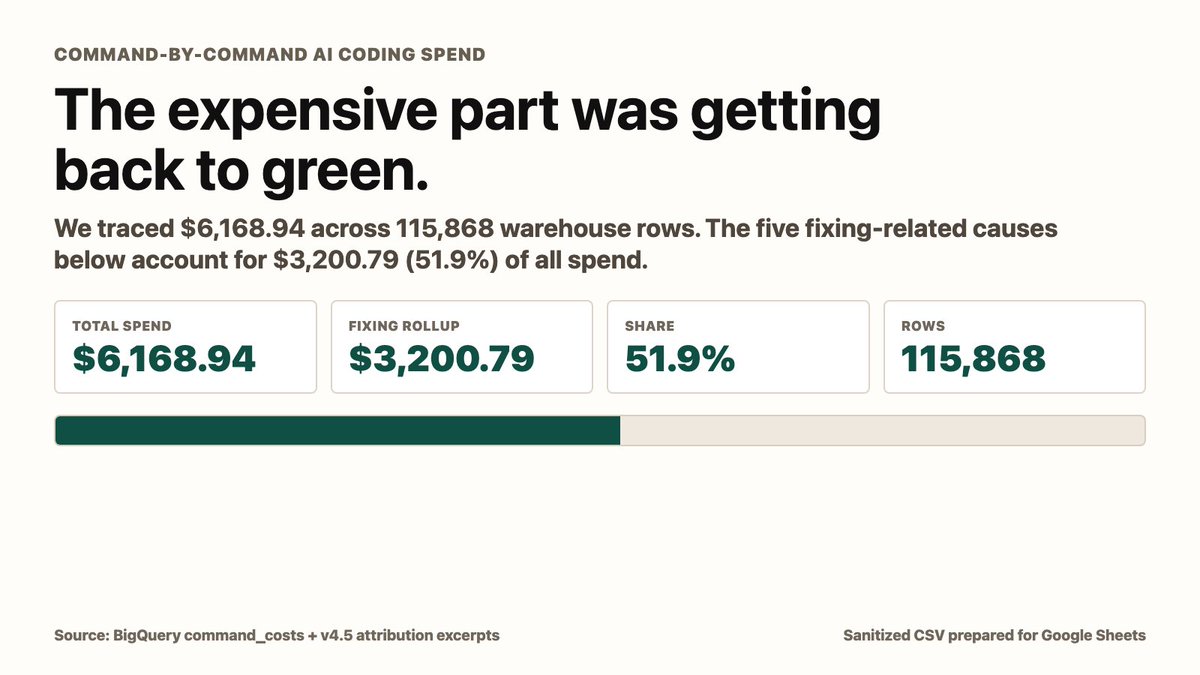
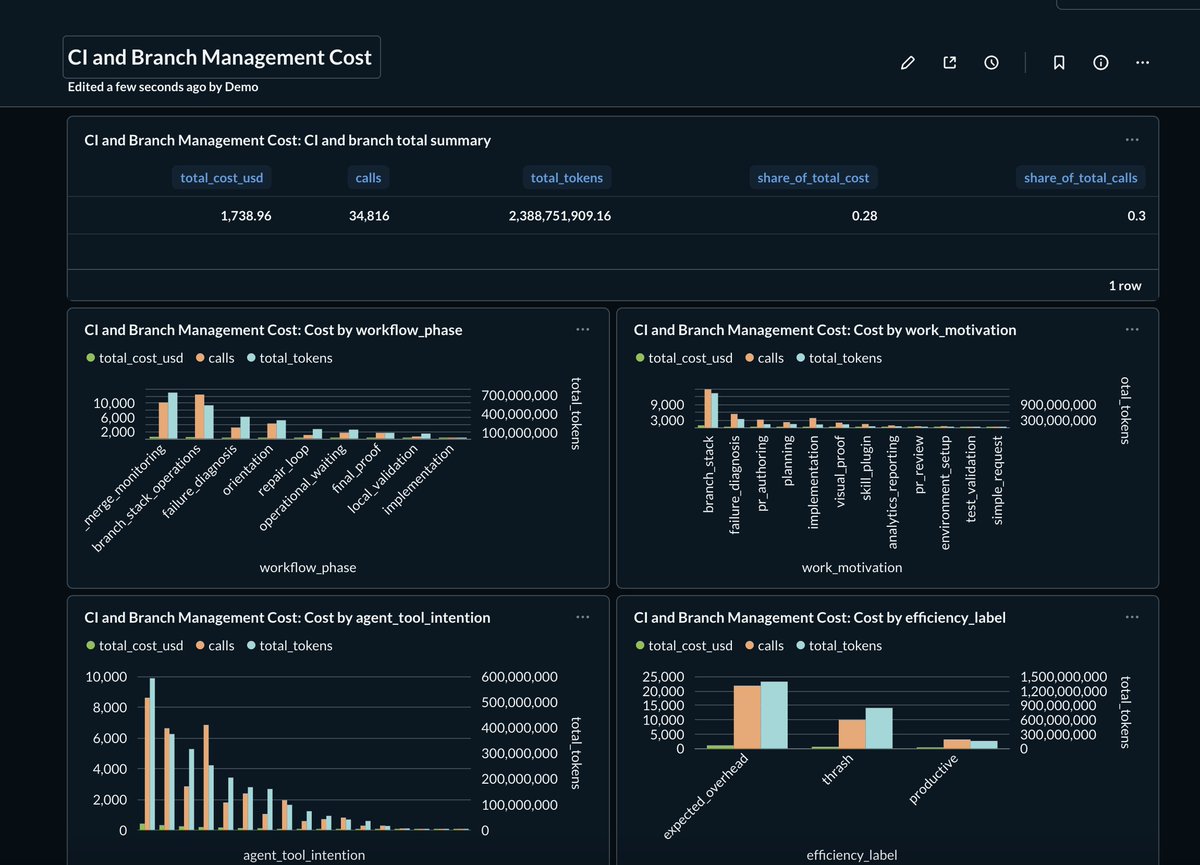
Pinned Tweet

Apr 24
We do not need more AI agents. We need more control over them.
That is why I created Invoker, an open-core execution engine for AI-driven engineering workflows.
The bottleneck is no longer just code generation. It is execution control.
AI work needs isolation, replay, auditability, recovery, and human decision points. The model resembles build systems and workflow engines more than it resembles a theoretically “AI-first” chat interface.
medium.com/@edbertchantech/i…
2
5
1,993
echantech retweeted

Jun 12
IMO sth that is a bit overlooked but will become far more important in the future. GPT is 10-20x more token cost effective for ~similar outcome.
Jun 12

Day 3 with Fable.
Gave a huge prompt to implement a feature across CLI, web server, and another server to both Fable and deep^2 in Amp.
deep^2 was done before I went to the gym. It stopped short. Sent another prompt. $20.
Fable ran for 1hr40min and cost $350.
Results:
They both understood the assignment and built the same thing. Maybe that's due to my prompt.
Fable's worked on first try. Well done.
Deep's looks correct but didn't work on first try.
$20 vs. $350.
I'm sure I could get deep^2 to make it work and we'd end up at, what, $40? While Fable is now at $457 after I asked some follow-up questions.
129
50
1,394
275,192
Jun 13
Finally, someone explaining that the last mile is a VERY HARD LAST MILE. It is difficult to get people who have never experienced this pain to understand.
Corner cases you didn't think of at the beginning, lost knowledge, etc. These all come due eventually.
An AI is a army of hyperactive junior engineers that needs babysitting. So baby sit them appropriately.
Jun 12

$CSU insider tried to use AI to rebuild old software
Verdict:
AI won't save u if u don't understand your own software. It'll just help u build the wrong thing faster. B4 asking if AI can rebuild it—can u explain why the current version works. Nervous? That's the real project!


1
6
757
Jun 11
For whatever reason, Fable is unable to ask questions about architecture so I’m forced to craft it piece by piece for it.
It’s very good at making a small accurate change through multiple layers
But god help you if you even ask it to make a data pipeline like Dagster from scratch
It will generate HOT GARBAGE

We all talk about how these models are getting more intelligent.
One thing we all know but don't talk about as much is how they are still getting better at convincing us.
Frankly, this is a huge issue in areas where you don't have tight feedback loop. It gets harder and harder for a median worker to accurately assess AI outputs, as its answers become more and more convincing, regardless of its right or not.
In many areas of business / investing, the outputs are good enough to convince decent portion of investors / execs whatever they want to believe. The public psychosis you see - there's a mini version of this happening everywhere.
The problem compounds here because the outputs come at you fast and thick. When you argue against humans, you have a natural speed limit. You have time to think. You don't with these models.
Godspeed to us all.
1
2
139
Jun 11
3 months is a short era
Jun 11

Up until yesterday, our entire MTS team has operated under the philosophy of tokenmaxxing as much as possible on Claude Max plans.
With Fable, this may no longer be possible:
- One of our team members hit his limit 3 times yesterday and used the equivalent of $1.5k in 10 hours
- Half of our team has hit quota limits on eng work
This era of tokenmaxxing may need to be restrained - or at least have clear guardrails defined. We are concerned about running Fable at API-based billing. If every engineer starts spending tokens at levels equivalent to headcount costs, our burn rate will meaningfully increase.
Just as startups are starting to bake model routing into their core product, we will have to start thinking about model routing in our core engineering usage.
1
79
echantech retweeted

Jun 9
BREAKING NEWS: Anthropic's latest model will NOT help you if it thinks your ML research/ML engineering is interesting, and/or will secretly degrade its IQ so that the average engineer won't notice. We are already seeing Anthropic's latest model's moderation filters our GPU inference research and programming 😭

206
521
4,575
1,993,453
echantech retweeted

Jun 9
i look forward to our chinese brothers liberating the knowledge from within fable-5 and selling it to me at 5% the cost & 2x the speed
318
1,586
24,636
1,058,566
echantech retweeted

Jun 8
黄仁勋:如果你是在典型的亚裔家庭长大的,那么你要看一辈子心理医生。
我63岁了,而且工作的时间比我父母还长,(还很成功),但父母见面吃饭时又说了我一顿,批评我的绩效。
321
279
2,896
475,812
Jun 9
Real question:
Why not self-host metrics for the first few thousand users?
Its amazing: I don't have to spend money on Mixpanel and I have full control over the plane lol
23
echantech retweeted

Jun 8
Charlie Munger: "If you have a very rich corporation, human nature [being] what it is, it will get a lot of bureaucracy and a lot of excess cost in it and a lot of meetings and so forth."
"There is huge waste in that. In fact, a lot of the excess meetings make you worse off, not better off."
"Many places, after they've wrung out 30% of the excess costs, they run better than they did before."
"On the other hand, you can cut too much. There should be some mercy for people who have been around a long time and have served well in the past. You don't necessarily want 100% perfect efficiency."
(Daily Journal AGM || 2022)
1
35
343
46,889
Jun 9
This talk of AI loops is not as controversial as one might think.
“spend more money and hire more help to make the problem go away”
That’s the thought of someone who has an unlimited budget and does not consider real world limitations
Same holds true when thinking about AI
1
32
Jun 8
I don’t mind being the bottle neck of my code
I mind polluting my codebase with bad code
39
Jun 8
This is not stupid. This is expensive.
A very simple and non-controversial loop: “monitor all PRs for broken tests and fix them”
In a 200k codebase, this alone will blow through $1-2k of tokens a month.
You will have very high cache hit rate yes.
But you will also have the agent get an error, scan, fix, retry, get another error, and so on.
Each failure eventually costs $5/fix. This is great economics when a developer costs hundreds per hour.
But compound these loops and you begin to have issues with costs.
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
2
2
519
Jun 7
I think people are realizing that these AI models are basically 0 switching cost SaaS with less than reliable service.
The service reliability will improve over time.
The lock in effect? Maybe not.
1
46
Jun 6
If you’re full on vibe coding, you’re spending way more than 2k
Closer to 5k
Jun 6

Microsoft gave 12,000 engineers
Claude Code
they loved it
then the bill came up to $2,000 per person a month
so they took it away from everyone
if the biggest company in the world can't pay for it, how can normal people like us?
1
131

A former OpenAI researcher is now chief AI scientist for Tencent in China, and wants to build artificial general intelligence.
As Chinese companies grab talent from Silicon Valley, they’re increasingly bringing the U.S.' vision with them.
Click here to read more: cnb.cx/4e3PHG2

22
52
152
26,524
Jun 5
Can’t wait for the Cantonese AI advice
Jun 5

JUST IN: Meta is reportedly exploring AI that gives users health advice through Instagram, Facebook, & WhatsApp.
53
echantech retweeted

Jensen:
Asian parents' culture, toxic😟
I know they love me, I usually “alright, alright..."
黃仁勳今天說了內心話 一路過來真不容易
“亞洲父母有毒 總是會糾正你“
"我63歲了 他們依然覺得我不夠好“
200
835
6,940
769,089
Jun 3
Chinese lunches are genuinely impressive and great value.
I paid $2 for Molly Tea and $6 for hotpot.
And what nice weather we’re having in Shenzhen.


64