
Joined July 2011
- Tweets 1,083
- Following 2,315
- Followers 1,733
- Likes 33,007
12 Photos and videos





Pinned Tweet

May 6
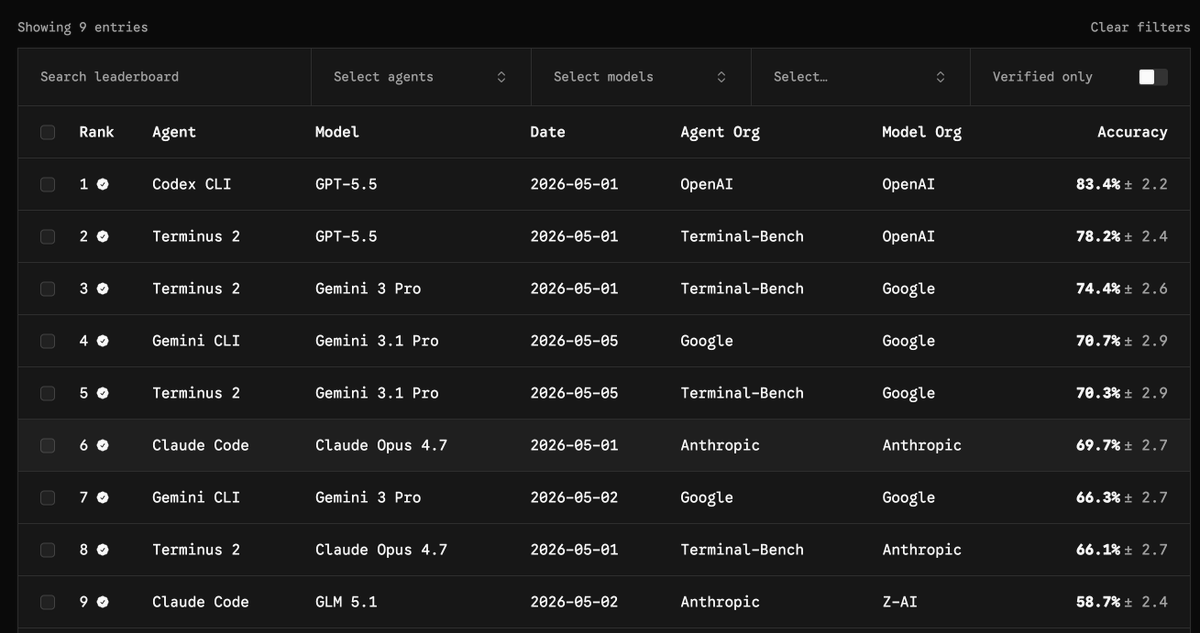
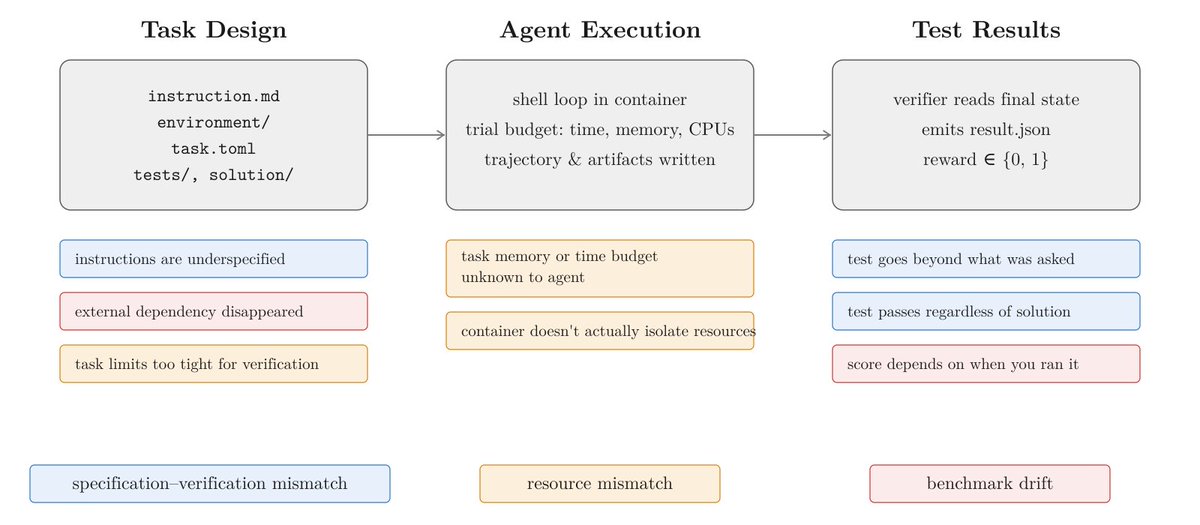
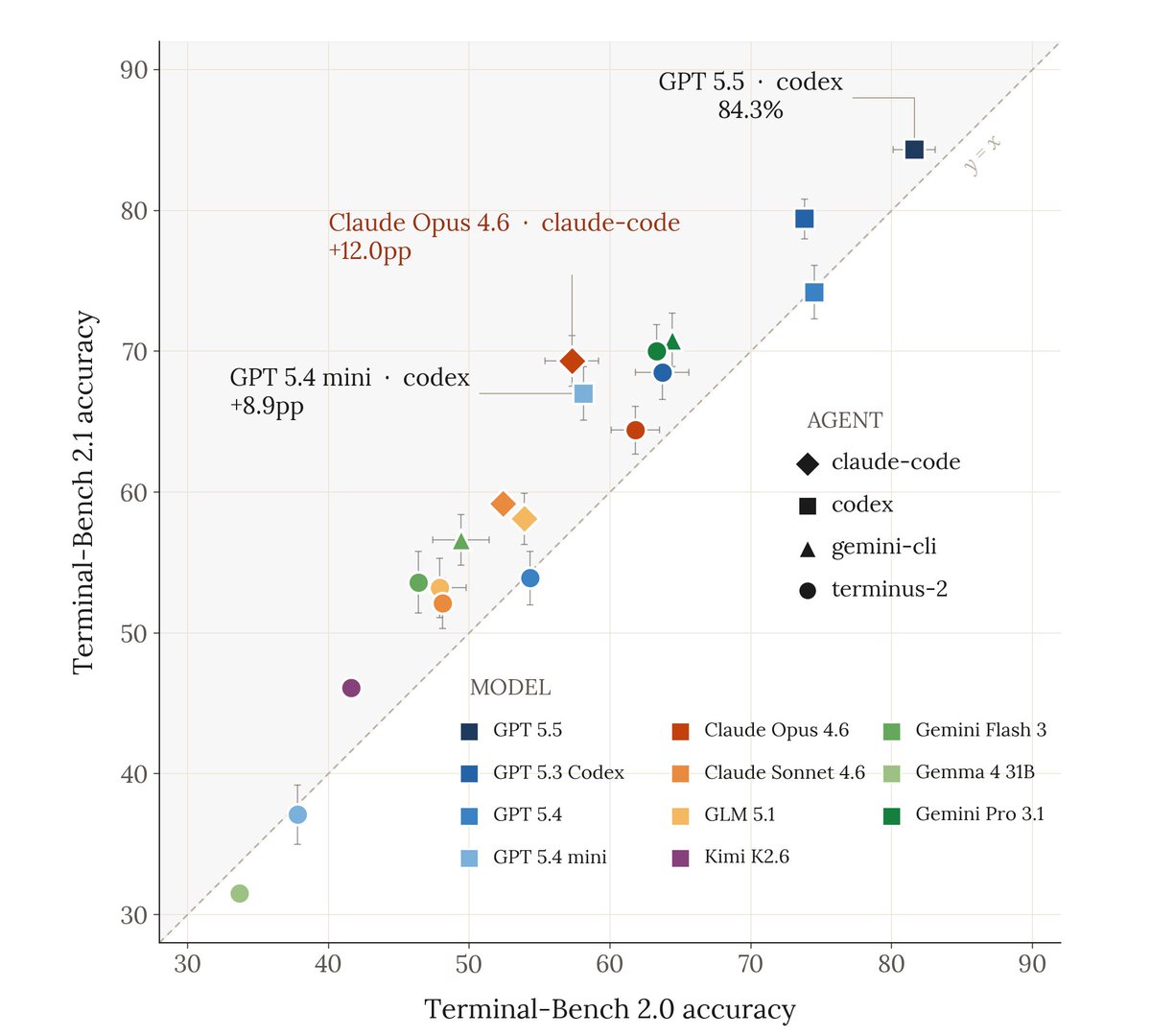
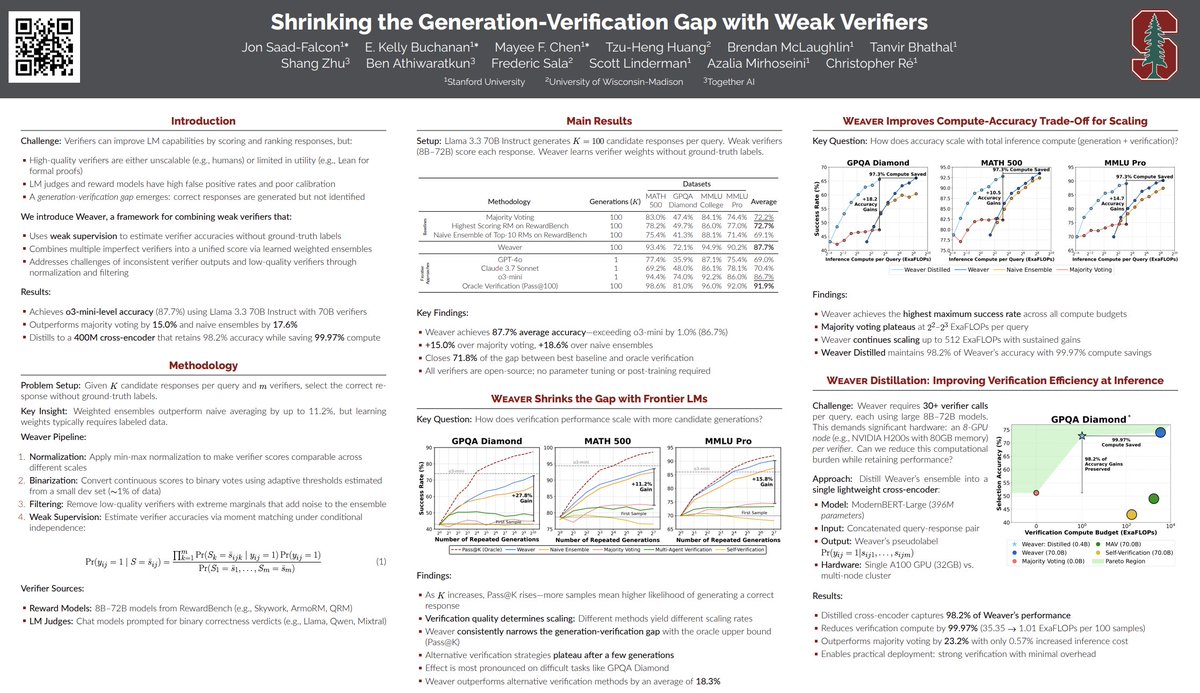
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
29
74
768
85,202

Kelly Buchanan retweeted

Jun 13
Nobody teaches you that discipline feels like punishment until the results start feeling like freedom
145
1,407
8,357
463,520
Kelly Buchanan retweeted

22 Dec 2013
I just want to be successful thats all..
599
11,347
57,153


Kelly Buchanan retweeted

22 Sep 2025
Why does AI sometimes fail to generalize, and what might help? In a new paper, we highlight the latent learning gap — which unifies findings from language model weaknesses to agent navigation — and suggest that episodic memory complements parametric learning to bridge it. Thread:

ALT Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences Andrew Kyle Lampinen , Martin Engelcke , Yuxuan Li , Arslan Chaudhry and James L. McClelland; Google DeepMind
20
108
590
87,953
Kelly Buchanan retweeted

Today we're releasing the first results for AA-AgentPerf, our new agentic inference benchmark: initially covering DeepSeek V4 Pro across NVIDIA Blackwell, Hopper, and AMD.
AA-AgentPerf is the first benchmark built for agentic inference. We use real, long-context agentic coding trajectory data as the workload, and inference with real production optimizations such as KV cache reuse and speculative decoding, leading to the most realistic evaluation of inference performance available today.
AA-AgentPerf’s lead metric is Agents per Megawatt. In a power-constrained world, this answers the most relevant question for AI infrastructure providers - “how many real agents can I deploy per unit of power available?”.
First results for DeepSeek V4 Pro (at the easiest defined service level of 20 tokens/s and 10s TTFT):
➤ GB300 (rack-scale, disaggregated): 61,354 Agents/MW
➤ B300 (single node, disaggregated): 21,053 Agents/MW
➤ MI355X: 3,551 Agents/MW
➤ H200: 2,594 Agents/MW
Further AA-AgentPerf details:
➤ Real agent workloads, beyond synthetic queries: AA-AgentPerf replays real coding agent trajectories where our agents used up to 200 turns and worked with sequence lengths >100K tokens - the workloads that matter in 2026
➤ Production optimizations allowed: KV cache reuse, speculative decoding, and prefill/decode disaggregation are all permitted, with accuracy verification to control for quality loss - we want results to reflect what real deployments actually look like
➤ Lead metric is Agents per Megawatt: simultaneous agents supported at production performance targets (e.g. 20 tokens/s per user, ≤10s TTFT) per megawatt consumed. Agents per TCO and $/hr will be supported soon
Key findings:
➤ Rack-scale disaggregated inference (GB300) is ~3× more power-efficient than single-node Blackwell (B300), and similarly ahead in raw agents per GPU
➤ Blackwell represents a large generational step over Hopper in both power efficiency and raw compute per GPU
➤ In this test, NVIDIA's Blackwell systems currently lead AMD MI355X by a clear margin. Important context: our MI355X configs are approximately two weeks older than our Blackwell configs and couldn’t stably use speculative decoding. MI355X power draw under heavy load is also well below TDP, indicating there is much room to improve on DeepSeek V4 Pro, which we will measure and publish in the coming weeks
➤ Config and inference framework version matter enormously - we've seen meaningful improvements daily since the DeepSeek V4 Pro release and look forward to tracking performance over time
AA-AgentPerf is a live benchmark and we publish results on a rolling basis as submissions come in. Some of the new features coming in v1.1: more models (gpt-oss-120b), more hardware (GB200, B200, H100, MI300X), better AMD configurations, $/hr and cost-per-task normalization, Agents per TCO, and performance tracking over time.

16
25
276
2,084,149
Kelly Buchanan retweeted

Apr 22
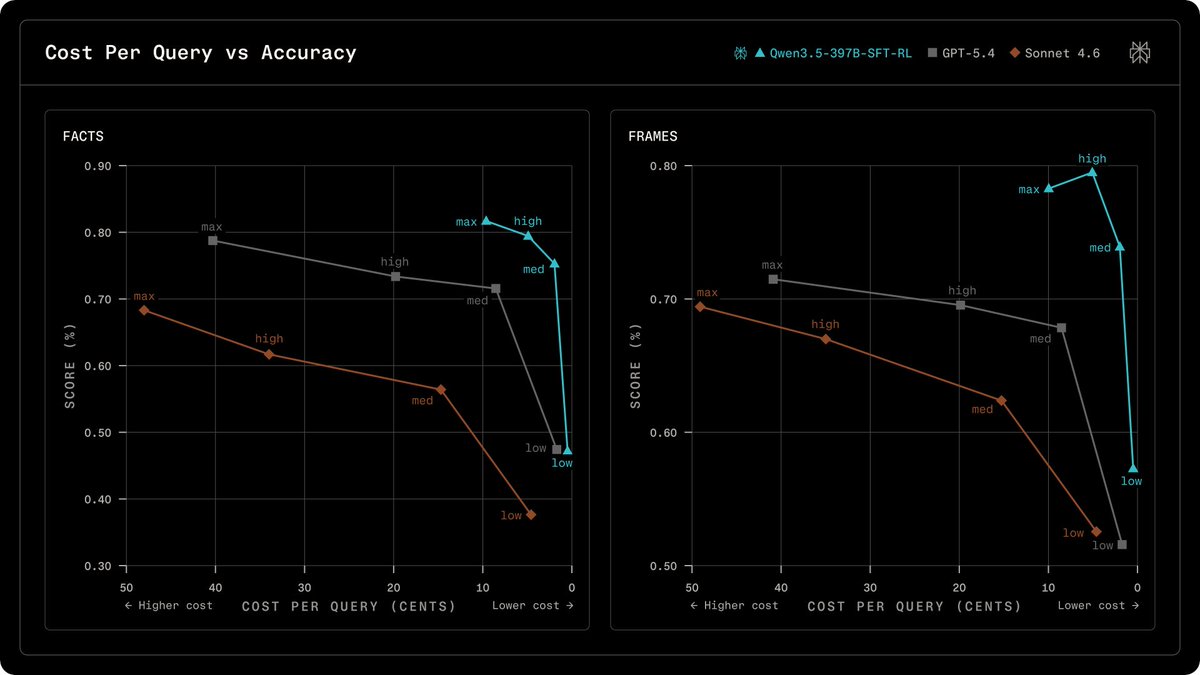
We've published new research on how we post-train models for accurate search-augmented answers.
Our SFT RL pipeline improves search, citation quality, instruction following, and efficiency.
With Qwen models, we match or beat GPT models on factuality at a lower cost.
65
146
1,799
357,575
Kelly Buchanan retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


615
1,619
13,580
1,950,996
Kelly Buchanan retweeted

Jun 11
Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…

26
107
968
113,805
Kelly Buchanan retweeted

Jun 11
Today we’re announcing Macrodata Labs.
Over the last few years, @HKydlicek and I have been turning a large part of the internet into some of the largest open LLM pre-training datasets. Through FineWeb, FineWeb2, FinePDFs, FineTranslations, and related work, we got a front-row seat to how scaling compute and data drove progress in LLMs.
We are starting to see a similar takeoff in robotics.
Building on advances in LLMs and VLMs, robotics is finally starting to scale. But physical data is messy in ways text isn’t: large video files, multi-rate sensors, many different formats, and open questions around what signals to record, which annotations matter, and how to turn all that context into better policies.
That makes data work in robotics especially important. Teams need to extract as much signal as possible from every demonstration, trajectory, video frame, and sensor stream, without rebuilding their whole data stack every time they change robot, sensors, format, or labeling method.
We think the right tooling for this is still missing. That is what we created Macrodata Labs to build. Our first step is Refiner, an open-source framework for processing robotics datasets.
We designed Refiner to handle a variety of robotics formats and help teams extract more signal from each demonstration. It is shipping today with support for hand-tracking, subtask annotation, and reward model scoring.
We are also launching a cloud version of Refiner, so teams can focus on their data instead of infrastructure. With a one-line code change, the same pipeline can scale on our platform, with sharding, checkpointing, model deployments, failure recovery, and detailed observability built in.
We’re fortunate to be backed by Air Street Capital, Drysdale Ventures, OPRTRS club, Kima Ventures, YG (Alex Yazdi), >commit, Thomas Wolf, and many incredible angels from top AI labs and technology companies.
I’m excited to keep exploring how better data work can push the frontier of AI, now in the physical world.
If @macrodata_labs sounds interesting to you, or if you are building in the space, I would love to hear from you.

ALT Macrodata_Labs
25
32
210
39,429
Kelly Buchanan retweeted

Jun 11
Now that we have Fable… should AI models be training us?
@Avanika15’s and my mini-experiment: Can we turn Fable into your smartest partner in health and fitness?
Fable is borderline *too smart* for this in how good it is at deep research, synthesis, reasoning.
But the world’s best fitness trainer would probably also have…
- Intake → personalization. Asks all about you, generates tailored workout plans.
- Deep customization. Tell it who *you* trust for fitness advice. It draws from those sources.
- Rich formats. Shows you lots of videos, not just text.
We gave it a shot! Link below, all feedback welcome.
11
5
66
18,120
Kelly Buchanan retweeted

Jun 8
Our new open-source book on the Principles and Practice of Deep Representation Learning (A Mathematical Theory of Memory) is now posted on the arXiv: arxiv.org/abs/2606.06624 I will offer a new graduate course this fall at the University of Hong Kong. Everything will be open sourced!
12
172
1,171
379,196
Kelly Buchanan retweeted

Jun 10
We believe that better training data will come from creative research and engineering ideas, not from hiring annotators.
Here are some of the open problems we are working on:

2
17
83
18,282
Kelly Buchanan retweeted

Jun 10
the art of technical writing is to appease both the p99 domain-expert and the curious p50
it's like a Pixar movie that speaks to child & parent
16
49
696
26,916
Kelly Buchanan retweeted

Jun 9
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
8
54
509
42,147
Kelly Buchanan retweeted

Jun 9
76
400
2,990
942,883
Kelly Buchanan retweeted

Jun 8
New Science Blog: Why has AI advanced faster in coding than in biology?
To agents, bio databases are like cities built before cars—maddening to drive in because they're designed for different traffic.
How do we build infrastructure agents can use?
anthropic.com/research/agent…
312
495
3,653
676,349
Kelly Buchanan retweeted

Jun 8
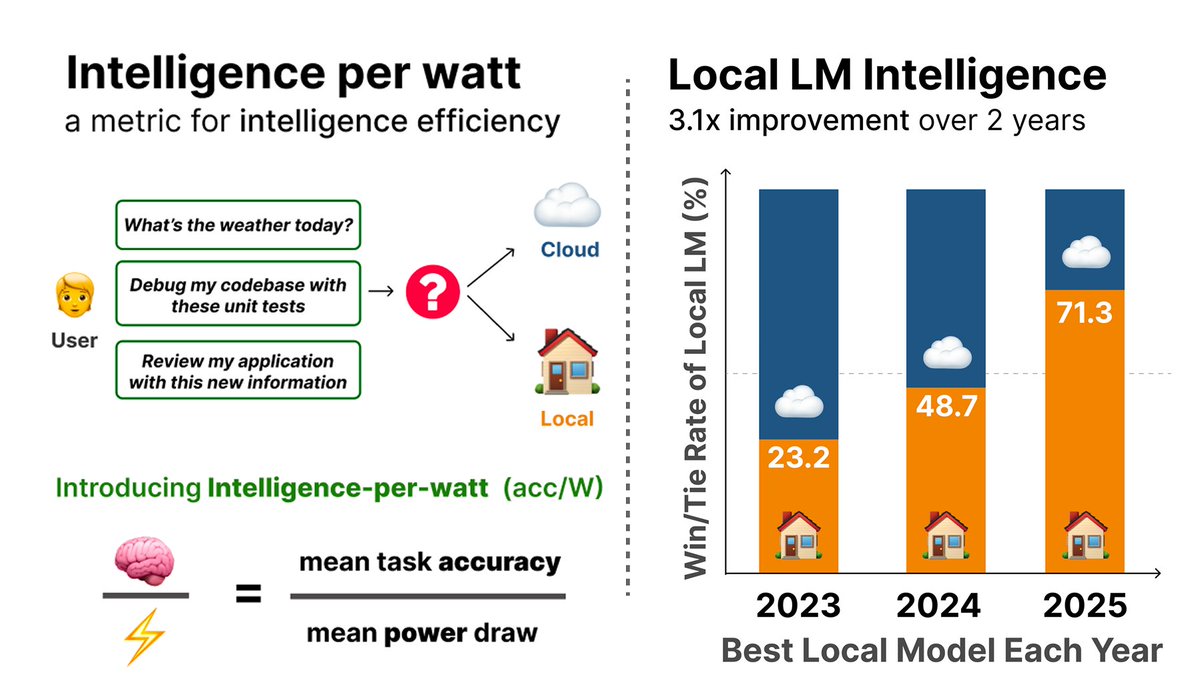
Narrative violation: according to @Stanford research, local models can answer 71.3% of real-world chat and reasoning queries accurately, up from 23.2% in 2023. Obviously at a fraction of the cost and energy consumption of frontier APIs.
The obvious conclusion: you don't need a frontier model for most tasks. The future is multi-model: local, open-source, smaller and cheaper for the majority of workloads, frontier APIs when no other choices!
70
143
838
113,021
Kelly Buchanan retweeted

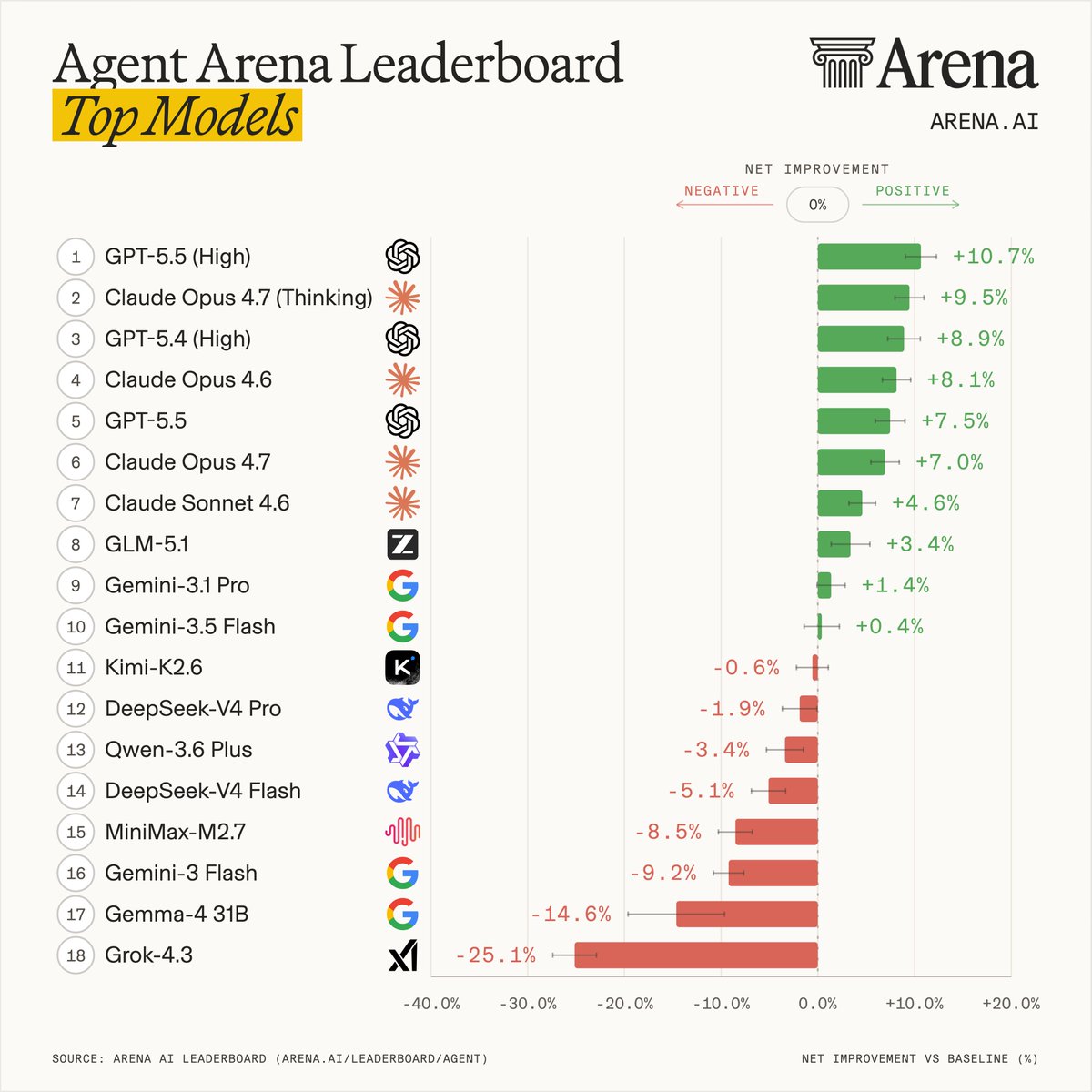
In case you didn’t notice: Agent Arena doesn’t have a voting mechanism. So how do we calculate the scores?
The answer is causal inference. Agents are multi-stage systems where the orchestrator and harness work together to produce the end result. We developed a method called causal tracing that looks at each possible orchestrator and harness component as a treatment, and evaluate the treatment effect with respect to a randomized baseline on all the signals mined from traces. This allows us to independently evaluate each subcomponent, track how the effects change as new options are added, and combine many signals into one coherent leaderboard.
The leaderboard you see is the net effect of the orchestrator as a treatment when looking across a basket of implicit and explicit success signals, including:
- Confirmed success: user marks task as success or failure.
- User affirmation: user praises or complains about agent output.
- Steerability: agent responds correctly to user requests.
- Bash recovery: time taken to recover from making an error in bash.
- Tool hallucination: agent hallucinates tool that does not exist.
Human preference is now only one of the many signals that Arena can measure. All signals based on real-world usage by a huge population of 10s of M of users.


Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
3
8
51
9,255
Kelly Buchanan retweeted

Jun 8
Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40 hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?

235
314
4,285
2,509,481