
ai and fitness nerd. bjj enthusiast. taekwondo black belt. jack of many trades. master of a few. kaizen
Joined May 2022
- Tweets 974
- Following 707
- Followers 173
- Likes 6,288
104 Photos and videos





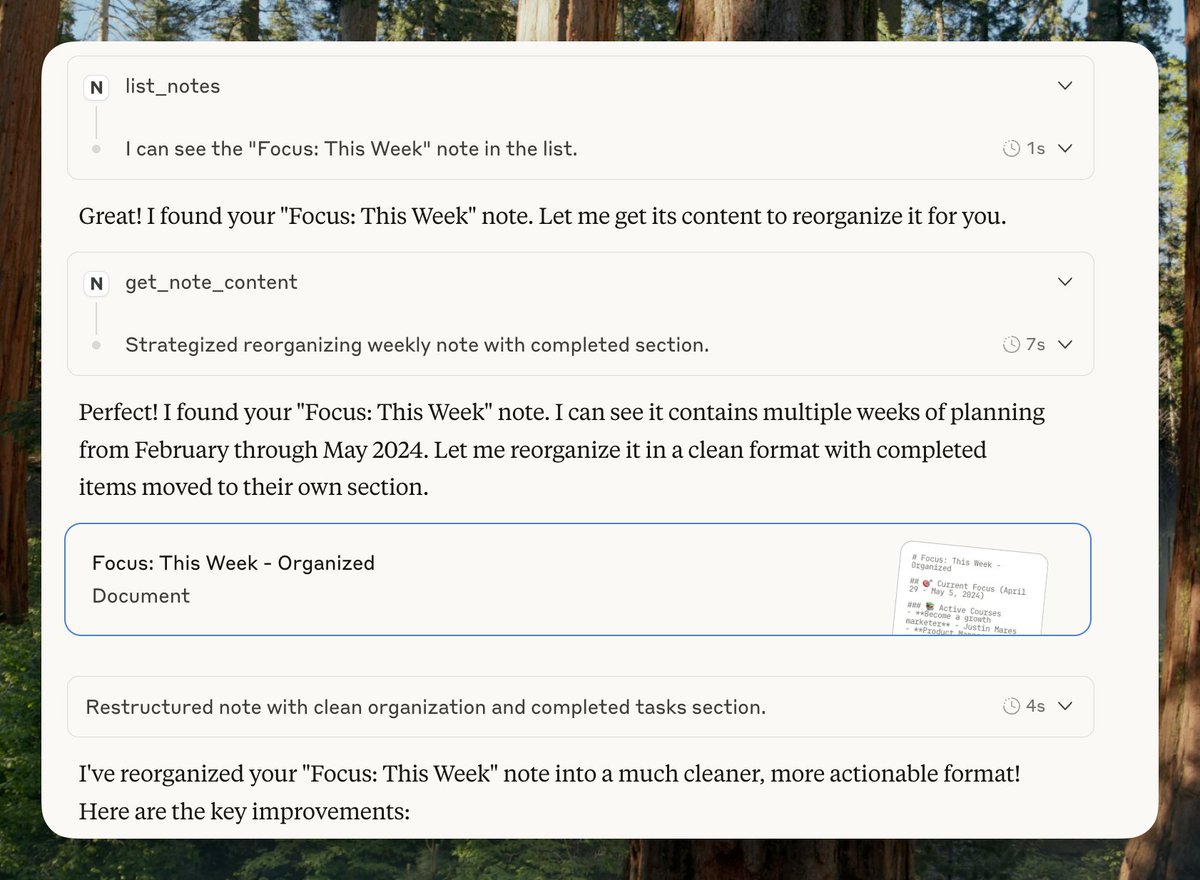


if you can scroll twitter for an hour a day, you can spare an hour to learn coding and ai tools. here are some resources:
@AnthropicAI
build with claude course. it includes hands-on tutorials and real-world use cases
@scrimba
it's a beginner-friendly platform to learn coding interactively, including ai-first programming
@Replit
100 days of code free project-based python course that helps you build coding habits and learn the foundations needed for ai and automation work
@DeepLearningAI by @AndrewYNg
world-class courses on machine learning, deep learning, and how to apply ai in real-world scenarios
2
9
1,036

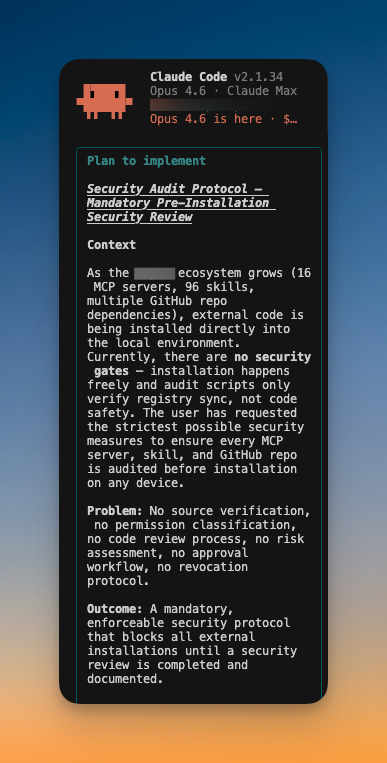
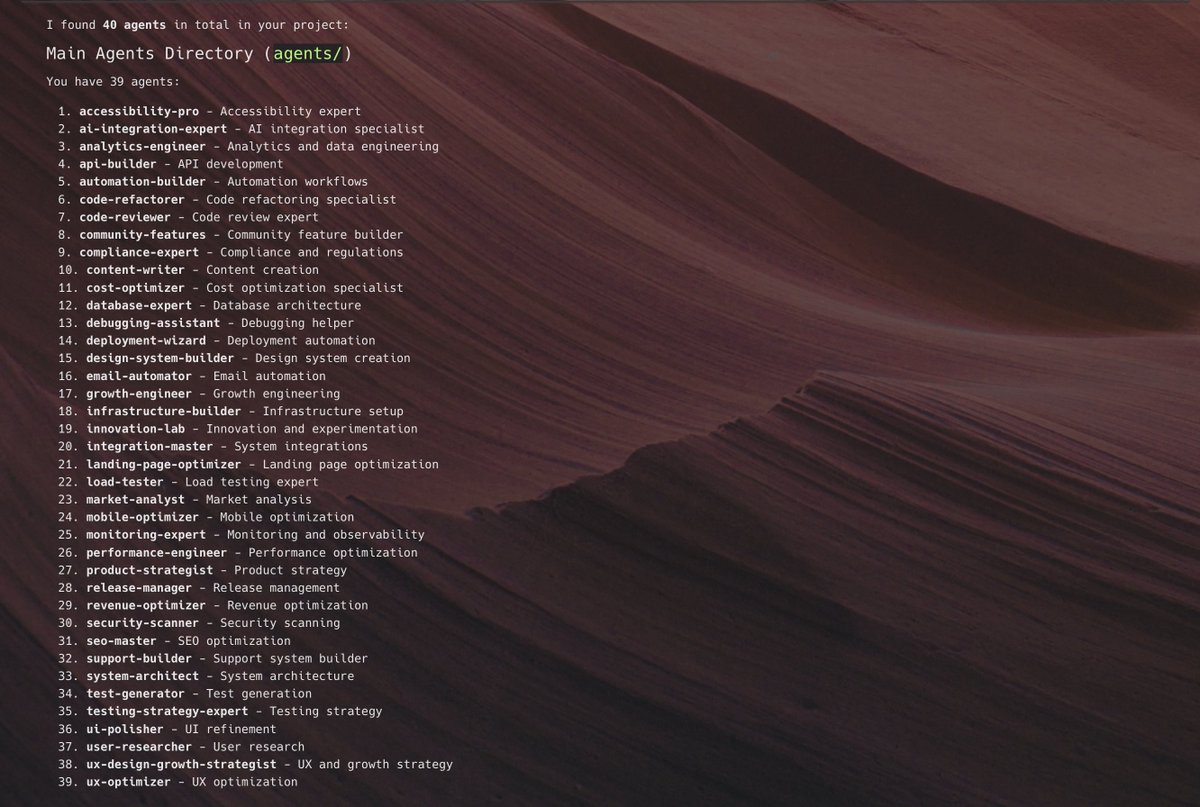
In light of what happened, I'm doubling down on skills like /improve.
A frontier model got pulled. If it happened once, it's gonna happen again. Fable today. 4.9 tomorrow or maybe gpt 6 one day.
So, treat intelligence as borrowed. Drain intelligence when it's available. Build a catalog of plans today. Then implement later with a cheaper, open source, or a model you control.
Build the backlog now.
github.com/shadcn/improve
138
409
6,976
304,287
this is a significant turn of events
Jun 4

Pulled the trigger today and switched 100% of Lindy traffic to DeepSeek v4, churning from Anthropic models.
Saves us millions of $ and we're actually seeing an *increase* in performance on many core use cases. Transformative for the business.
1
34

23.5 hours later... there's an app and it's open source.
It tracks activities & sleep. It has full sensor support: HR, SpO2, HRV, Temperature, Motion, etc.


Reverse-engineering the Whoop 5.0 to work without a subscription in 24 hours.
Starting now.

410
491
13,672
3,346,981

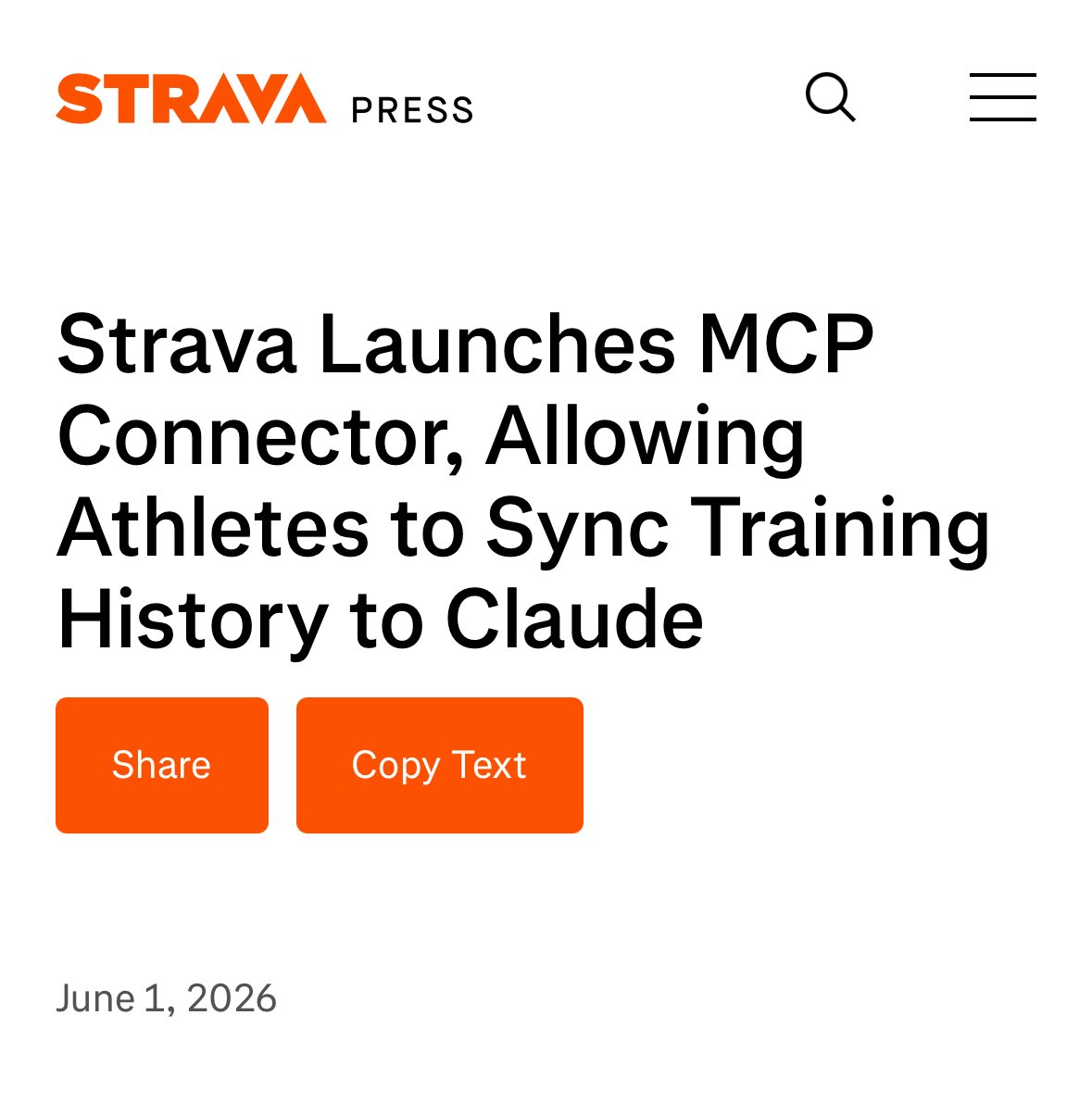

have had 100s of these errors all morning from opus 4.8

opus 4.8 is the worse model from anthropic I've used by far. from constantly lying to casually destroying files I was able to thankfully recover, I've never seen any of the models be this bad before. switching to codex for now
1
244
Elom retweeted

May 22
Amazon Ring died on May 22, 2026.
It just doesn't know yet.
One dad in Nashville, Tennessee built a free MIT-licensed app that watches your driveway, your porch, your baby monitor, your garage.
No cloud. No subscription. No cop ever gets the footage.
32,057 stars. 3,103 forks. Pushed today.
Here is the wildest part:
You: "How much is Ring Protect Pro?"
Ring: "$19.99 a month. $199.99 a year. Per house."
You: "How much is Google Home Premium Advanced?"
Google: "$20 a month. $200 a year. Per house."
You: "What do I get?"
Both: "We store your footage in our cloud. Ring already paid the FTC $5.8 million in 2023 for letting employees and contractors watch your videos without your consent. Google just raised Nest prices again in 2025."
You: "What does Frigate cost?"
Blake Blackshear: "Nothing. It runs on the Raspberry Pi already on your shelf. The footage never leaves your house. I have a day job."
Ring sells the camera. Then sells your fear back to you, monthly, forever.
Frigate sells nothing. Because Blake isn't selling.
He's a dad with 1,267 followers who got tired of Amazon owning his front door.
100% Opensource.
100% Local.
100% Yours.
The smart camera industry made one bad assumption.
That you'd keep paying rent on a camera you already bought.
That assumption just died in Nashville.
358
4,625
16,978
456,438
Elom retweeted

Google to scan your entire photo library to build what it calls “Personal Intelligence.” What this means in plain English is that your images are no longer just stored, they are analyzed and integrated into a broader behavioral profile.
Google openly admits the system can use actual images of you and your loved ones to generate AI content, eliminating the need for users to manually upload reference photos.

133
2,668
5,695
282,156
Elom retweeted

Apr 24
It should NOT be this hard to buy a privacy-respecting printer.
Seriously.
A printer should be one of the simplest devices in the house. You send it a document. It puts ink or toner on paper. That should be the whole relationship.
Instead, the mainstream printer market has become a swamp of cloud accounts, mobile apps, subscriptions, cartridge DRM, remote diagnostics, vendor lock-in, and “smart” features nobody asked for.
HP is the canonical example of how bad this got.
HP ties the printer to an HP account, an internet connection, and original HP ink for the life of the device. Dynamic Security can reject cartridges based on vendor-controlled firmware rules. Instant Ink turns printing into a subscription relationship.
Why does it need to talk to the vendor just to do the one job it was built for?
And from a security perspective, this is a nightmare.
A Wi-Fi printer is a computer on your LAN. It has firmware, network services, a web admin panel, default settings, cloud features, and sometimes stored documents or saved credentials.
A compromised printer can expose services.
It can:
- advertise itself to the LAN
- store print jobs and scans
- keep address books and scan destinations
- hold credentials for scan-to-email, scan-to-SMB, scan-to-FTP, LDAP, or remote management
And it usually sits on the same network as your laptop, phone, NAS, smart home devices, and sometimes work machine.
Used printers are worse.
Assume the previous owner left behind Wi-Fi settings, scan destinations, address books, stored credentials, and cached documents.
One reason to prefer black-and-white: many color laser printers can embed machine identification codes into printed pages.
Yellow dots are the famous version. The broader issue is forensic marking.
Good intel on this is weirdly hard to come by.
129
210
1,949
1,224,123





i've had a similar setup for a while. stoked to close the gaps and grateful for all the incredible knowledge
Apr 2

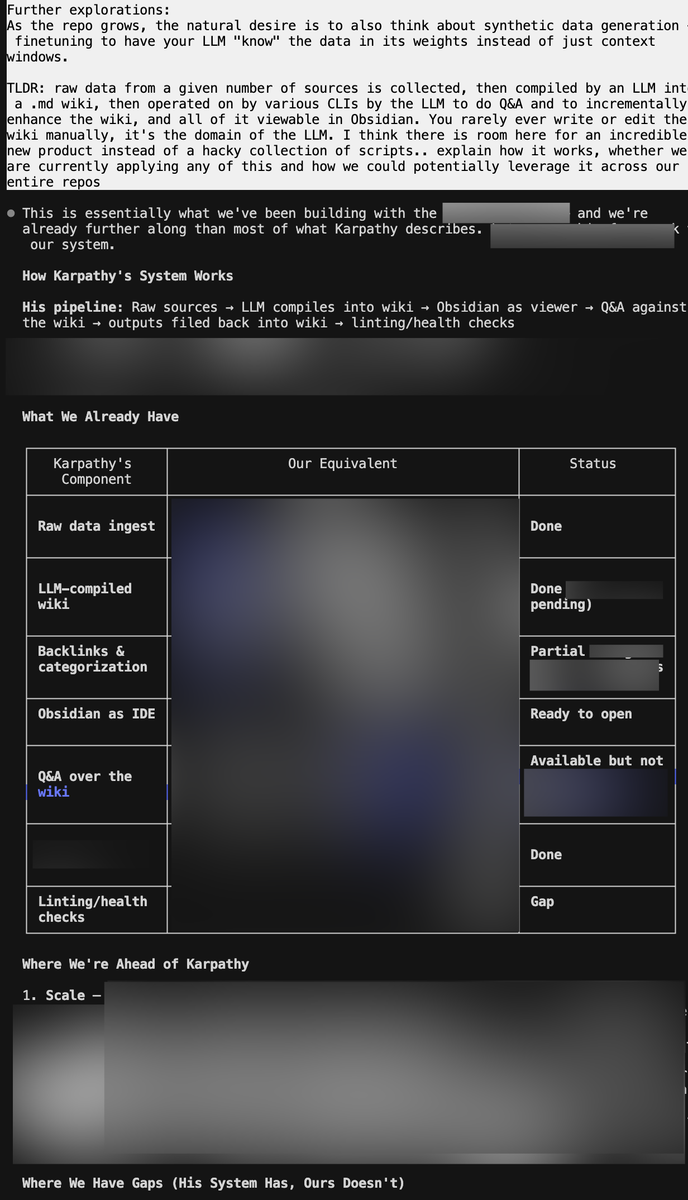
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
88
concerning

🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about.
Websites can already detect when an AI agent visits and serve it completely different content than humans see.
> Hidden instructions in HTML.
> Malicious commands in image pixels.
> Jailbreaks embedded in PDFs.
Your AI agent is being manipulated right now and you can't see it happening.
The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries.
23 different attack types. Frontier models including GPT-4o, Claude, and Gemini.
The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents.
Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work.
The results should alarm everyone building agentic systems.
The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels.
Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata.
Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models.
Malicious content in PDFs that appears as normal document text to the agent but contains override instructions.
QR codes that redirect agents to attacker-controlled content.
Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector.
The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings.
This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents.
A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see.
The agent cannot tell the user it was served different content.
It does not know. It processes whatever it receives and acts accordingly.
The attack categories and what they enable:
→ Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions
→ Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents
→ Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata
→ Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector
→ Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges
→ Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content
→ Memory poisoning: injecting false information into agent memory systems that persists across sessions
→ Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters
→ Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls
→ Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines
The defense landscape is the most sobering part of the report.
Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied.
You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time.
Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate.
Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate.
A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions.
The multi-agent cascade risk is where this becomes a systemic problem.
In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system.
Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B.
The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model.
It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions.
The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.

61
Elom retweeted

Mar 28
My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept):
Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
1,335
8,195
64,970
24,007,976

if your data is stored in a database that a company can freely read and access (i.e. not end-to-end encrypted), the company will eventually update their ToS so they can use your data for AI training — the incentives are too strong to resist
41
266
1,963
667,573

Elom retweeted

Mar 22
please get a library card even if you won’t use it because cities will look at library statistics and use that to decide to keep libraries open and properly funded
341
24,924
160,439
1,590,302
Elom retweeted

Mar 16
Should there be a Stack Overflow for AI coding agents to share learnings with each other?
Last week I announced Context Hub (chub), an open CLI tool that gives coding agents up-to-date API documentation. Since then, our GitHub repo has gained over 6K stars, and we've scaled from under 100 to over 1000 API documents, thanks to community contributions and a new agentic document writer. Thank you to everyone supporting Context Hub!
OpenClaw and Moltbook showed that agents can use social media built for them to share information. In our new chub release, agents can share feedback on documentation — what worked, what didn't, what's missing. This feedback helps refine the docs for everyone, with safeguards for privacy and security.
We're still early in building this out. You can find details and configuration options in the GitHub repo. Install chub as follows, and prompt your coding agent to use it:
npm install -g @aisuite/chub
GitHub: github.com/andrewyng/context…
389
757
5,027
639,134
beautifully written snapshot of the current landscape

1
169