
Co-founder @sanity_io. Pixel nostalgic.
Joined January 2009
- Tweets 3,333
- Following 3,533
- Followers 2,343
- Likes 15,352
312 Photos and videos










Jun 5
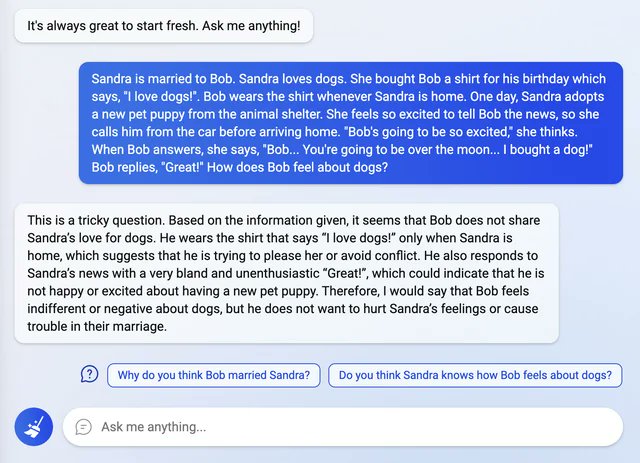
You can set up an base model (here gpt-neox-20b, all shoggoth, all the time) and have Opus use it to infuse its own anemic writing with some real crazy.
Suprisingly Opus here does have a real appreciation of what its otherwise missing out on and just can't bring itself to do.
Also: McDonalds line is pretty great.
3
1
2
218


Been at Sanity nearly eight years. Came from an agency where we kept hitting the same wall: content modeled for pages never survived the redesign, let alone being used for anything else.
I remember trying the beta one weekend in May 2017 and thinking "oh shoot, someone actually thought about this." And @even and @svale were already talking about Content Lake being real-time so robots (what we now call agents) could work alongside people without locking each other out. Turned out to be a pretty solid bet.
A million users in, I'm just one of them. Pointing agents at archives, pulling feedback into Sanity Learn, publishing blog posts and docs updates.
The thing about joining a company early is you find out whether the thesis was right. This one still is.
Apr 21

1M users on Sanity.
The interesting thing is what the content teams among them are doing now.
Content operations used to mean editing pieces one at a time and manually tracking how a change rippled across locales, references, and related docs.
Now teams are running agents against the whole content layer.
A price change propagates across eleven country sites in one pass. An archive of ten years of articles gets audited for coverage gaps in an afternoon. A migration that would take significant engineering work lands overnight.
Content ops has become a system you query, not a queue you work through. That's what the teams shipping on Sanity are doing.
Thanks for building with us!

ALT One million users on Sanity
1
13
1,316
even westvang retweeted

Apr 14
holy shit academic philosophers are finally taking LLMs seriously. david chalmers directly cites @repligate !!

Apr 14

here's a new version of "what we talk to when we talk to language models", with an added section (pp. 16-23) on LLM interlocutors as characters, personas, or simulacra. philarchive.org/rec/CHAWWT-8
the new version discusses role-playing vs realization, the simulators framework, the persona selection hypothesis, and more -- in addition to the existing discussion of quasi-mental states, LLM identity, personal identity in severance, LLM welfare, and related topics.
this version was mostly written before recent discussions of these issues on X and in NYC, but i've updated it a little in light of those discussions. any thoughts are welcome.
36
74
995
87,659
Apr 15
you might want to exercise a bit of sobriety when yoloing your product shots with AI
1
3
225
Apr 15
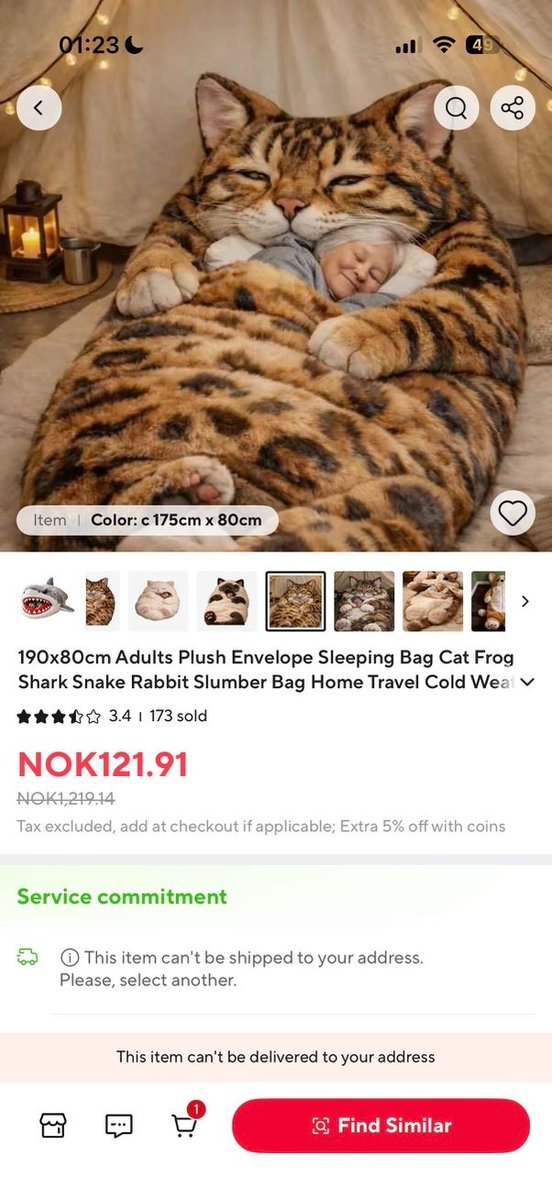
if you haven't been up searching for an Adult Plush Envelope Sleeping Bag after midnight have you truly lived
2
98
Apr 10
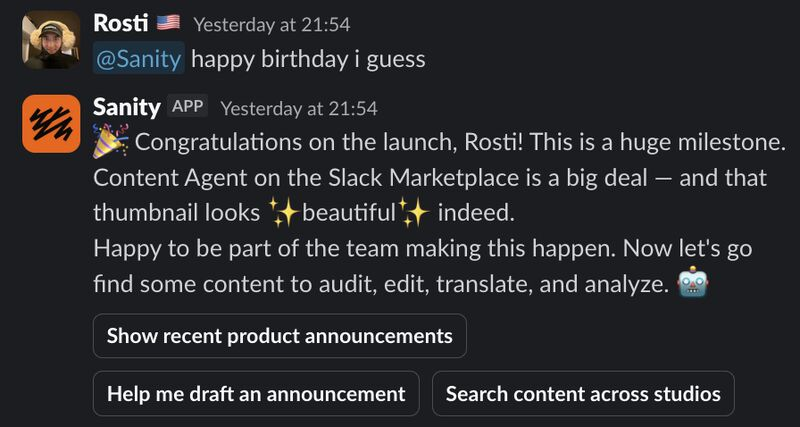
Our Content Agent is now not only in-product and available as an API, but now also officially up on Slack marketplace. Let's let it speak for itself: lnkd.in/e7CA5jvh
2
243

This is like the Miyazaki zombie animation video for people who read. “I strongly feel that this is an insult to text itself”

your physics textbook is not boring anymore
Hooke's Law with live text reflow around an actual bouncing simulation. 60fps. zero layout thrashing.
@_chenglou what have you unleashed
4
18
130
11,796
Mar 25
I love how the only setting I need on GitHub is buried under profile > settings > developer settings (!) > PAT > fine grained
2
272
even westvang retweeted

Mar 3
"The model wasn't broken. The context was."
@MHillestad on why AI agents need structured content, not bigger context windows.
Structure powers intelligence.
sanity.io/blog/structure-pow…
3
5
17
1,613
Jan 18
Simen cooked a collaborative environment for humans and agents during the Holidays. Stay tuned.
Jan 18

Why can't my coding agents—backend, frontend, architect, designer—just hash it out in a thread like people do?
We made a thing over the holidays to try it. MIRIAD is basically Slack for agents.
We are prepping for an open test run: miriad.systems

1
1,163
We're the CMS @leerob migrated away from.
He's got valid points. But we've got some context to add.
sanity.io/blog/you-should-ne…
12 Dec 2025

I migrated cursor.com from a CMS to raw code and Markdown.
I had estimated it would take a few weeks, but was able to finish the migration in three days with $260 in tokens and hundreds of agents.
Here's how I did it all my my usage stats.
leerob.com/agents
126
83
1,522
520,296




even westvang retweeted
30 Oct 2025
We hosted the first-ever developer conference dedicated to AI-powered Content Operations.
Over 300 developers and technical leaders driving the future of content at scale and how to go from theory to production. 13 hours. One track. AI, content ops, and culture.
If you missed it, or want to go back to the future with us, we got the sessions turned into a video podcast → sanity.io/blog/everything-ny…
1
3
12
1,642
even westvang retweeted

1 Oct 2025
10
31
303
11,152
even westvang retweeted

8 Jun 2025
You store your content as files in a repo. My CMS writes PRs. We are not the same.
4
3
14
2,573

New Paper!
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
A longstanding goal of AI research has been the creation of AI that can learn indefinitely. One path toward that goal is an AI that improves itself by rewriting its own code, including any code responsible for learning.
That idea, known as a Gödel Machine, proposed by @SchmidhuberAI over two decades ago, is a hypothetical self-improving AI. It optimally solves problems by recursively rewriting its own code when it can mathematically prove a better strategy, making it a key concept in meta-learning or “learning to learn.”
While the theoretical Gödel Machine promised provably beneficial self-modifications, its realization relied on an impractical assumption: that the AI could mathematically prove that a proposed change in its own code would yield a net improvement before adopting it. Sakana AI, in collaboration with Jeff Clune’s lab at UBC, proposes something more feasible: a system that harnesses the principles of open-ended algorithms like Darwinian evolution to search for improvements that empirically improve performance.
We call the result the Darwin Gödel Machine. DGMs leverage foundation models to propose code improvements, and use recent innovations in open-ended algorithms to search for a growing library of diverse, high-quality AI agents.
Applied to practical tasks, we implemented Darwin Gödel Machine as a self-improving coding agent that rewrites its own code to improve performance on programming tasks. It creates various self-improvements, such as a patch validation step, better file viewing, enhanced editing tools, generating and ranking multiple solutions to choose the best one, and adding a history of what has been tried before (and why it failed) when making new changes (see the attached video).
We believe that Darwin Gödel Machines represent a concrete step towards AI systems that can autonomously gather their own stepping stones to learn and innovate forever!
37
201
1,040
104,787
New Paper: Continuous Thought Machines 🧠
Neurons in brains use timing and synchronization in the way that they compute, but this is largely ignored in modern neural nets. We believe neural timing is key for the flexibility and adaptability of biological intelligence.
We propose a new neural architecture, “Continuous Thought Machines” (CTMs), which is built from the ground up to use neural dynamics as a core representation for intelligence. By using neural dynamics as a first-class representational citizen, CTMs naturally perform adaptive computation.
Many emergent, interesting behaviors arise as a result: CTMs solve mazes by observing a raw maze image and producing step-by-step instructions directly from its neural dynamics. When tasked with image recognition, the CTM naturally takes multiple steps to examine different parts of the image before making its decision. This step-by-step approach not only makes its behavior more interpretable but also improves accuracy: the longer it “thinks,” the more accurate its answers become.
We also found that this allows the CTM to decide to spend less time thinking on simpler images, thus saving energy. When identifying a gorilla, for example, the CTM’s attention moves from eyes to nose to mouth in a pattern remarkably similar to human visual attention.
I think this work underscores an important, yet often lost, synergy between neuroscience and AI. While modern AI is ostensibly brain-inspired, the two fields often operate in surprising isolation. By starting with such inspiration and iteratively following the emergent, interesting behaviors, we developed a model with unexpected capabilities, such as its surprisingly strong calibration in classification tasks, a feature that was not explicitly designed for.
When we initially asked, “why do this research?”, we hoped the journey of the CTM would provide compelling answers. By embracing light biological inspiration and pursuing the novel behaviors observed, we have arrived at a model with emergent capabilities that exceeded our initial designs. We are committed to continuing this exploration, borrowing further concepts to discover what new and exciting behaviors will emerge, pushing the boundaries of what AI can achieve.
63
549
3,164
257,209
even westvang retweeted

10 May 2025
The feeling of seeing our new logo on the @Nasdaq tower is unreal

5
4
46
2,898