
Cofounder, @LeashBio. Ex-Recursion, Arima Genomics, Nanocellect, Salk, UT Austin, Baylor College of Medicine, Rice. He/him.
Joined May 2010
- Tweets 6,961
- Following 2,607
- Followers 1,195
- Likes 20,362
365 Photos and videos








Ian Quigley retweeted

Jun 11
New paper! How do RNAs "know" where to go inside a cell? We dug into the sequence elements that route RNAs to the right place. It turns out that, in mammals, they're surprisingly massive (>200 nt), multipartite, and wonderfully complicated. 🧵
15
125
575
59,858
Ian Quigley retweeted

Jun 12
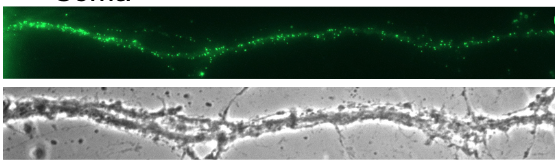
🌱 504k public plant RNA-seq samples × 1,200 species → live interactive
UMAP atlas.
Click any organ (256 PO terms) or evo-devo trait (57 of them) → top
gene families upregulated pop up on the right.
huggingface.co/spaces/mutwil…
17
81
3,594
Ian Quigley retweeted

Jun 10
For the first time, most biotech deal value now goes to assets from China:

4
16
70
15,392
Ian Quigley retweeted

Jun 9
No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…

15
93
381
95,473

Ian Quigley retweeted

Done.
Jun 4

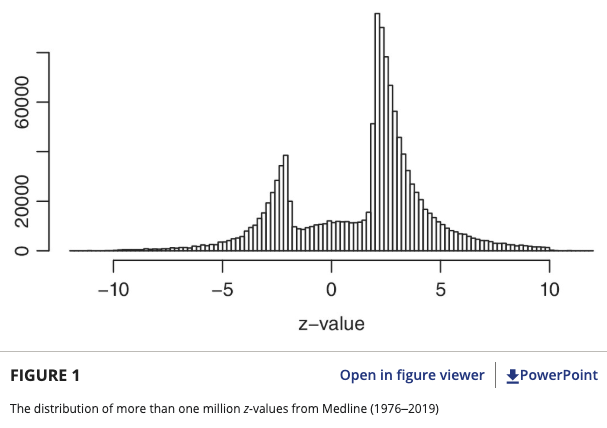
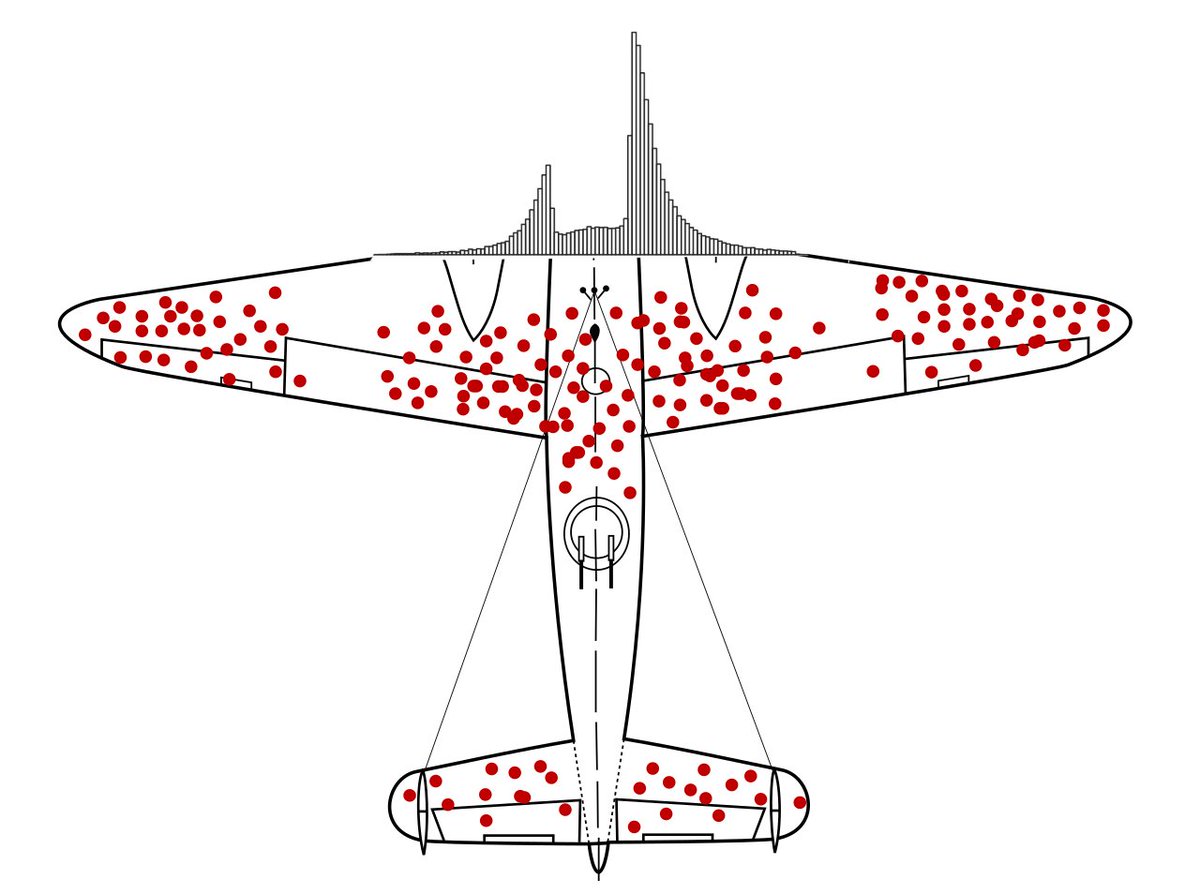
I'm on a mission to make this plot as publicly recognizable as the one with the holes in the WW2 airplane
1
13
818
Ian Quigley retweeted

Big funding agencies / VCs / companies etc interested in powering true breakthroughs in AI for biology should fund tech dev efforts that can produce & scale the right types of data to push models out of zones they struggle in. 8/
1
1
16
1,310

Jun 4
I like this but the Takifugu rubripes genome is ~1/8 as big as ours, has about the same number of genes, has bones gut neurons etc, maybe start there?

How much of the human genome is essential?
Two pieces out today from our lab: 1) a method to map essential genomic intervals at gigabase scale, and 2) an argument that it's time to consider synthesizing a minimal human genome.
biorxiv.org/content/10.64898…
nature.com/articles/d41586-0…
1
334
Jun 4
I'm on a mission to make this plot as publicly recognizable as the one with the holes in the WW2 airplane
Jun 4
35
140
4,450
441,955
Jun 4
Jun 3

Most experiments fail, and negative results rarely get published. This means LLMs are unaware of the outcomes of most experiments.
8
80
1,436
640,265
Another great research piece by @_DimensionCap @bauer_lesavage on Training Data for Bio AI.
Models will only be as good as the underlying data, and the biology they learn will be constrained by the limitations of that data.
We need to think deeply about scaling the best quality data to solve human bio with AI. Our thesis from day 1 at @NOETIK_ai.

The training data market has exploded for LLMs and bio foundation models are next.
But biological data is extremely complex and requires a data generation playbook that prioritizes quality over immediate scale.
@_DimensionCap Research article live now!
research.dimensioncap.com/p/…

6
13
84
12,378
Jun 1
Somebody needs to do this and then throw a DEL at it and do in situ sequencing of the DEL barcodes. You could get cellular chemistry tropism at scale
Jun 1

Hello world, meet 1,000× Expansion Microscopy.
1,000,000,000× expansion by volume! A gel that starts at a few centimeters will then expand to the volume of an Olympic swimming pool. biorxiv.org/content/10.64898…
In our new bioRxiv preprint, work carried out between MIT and UMG, led by Helena Hu in collaboration with scientists from the labs of @eboyden3 Ed Boyden, Silvio Rizzoli, and myself, we present Thousandfold Expansion Microscopy.
By enlarging biological specimens across multiple rounds of expansion, molecular-scale features, as small as the distances between adjacent amino acids, can be visualized with conventional optical microscopes.
Democratizing super-resolution microscopy.

2
3
19
2,574
Jun 1
Probably noisy as hell but if you were smart about the chemical library design .. so crazy it just might work
1
97
Jun 1
This is such a banger of an ASCO

A new cancer drug works like a molecular handcuff. One arm grabs a passing immune cell. The other grabs the tumor. It clamps them together and forces the kill, whether the cancer agrees to the meeting or not.
That trick cleared blood cancers a decade ago. Blinatumomab still does it in leukemia.
Solid tumors blocked it for one reason: the old handcuffs could only grab a protein sitting on the cell’s surface, and solid tumors hide their tells inside the cell.
This one reads the inside. Its grabbing arm is built from a T-cell receptor, so it spots the scraps of internal proteins that every cell puts on display. In a phase 1 study, 61 patients, it shrank head and neck, melanoma, and lung tumors that surface-only drugs never reached.
Solid tumors are most cancer. This is the first handcuff that fits them.
2
3
1,481
Ian Quigley retweeted

May 29
Animals have expanded the evolutionary legacy of unicellular ancestors in blood cells
pnas.org/doi/10.1073/pnas.25…
2
4
433
Ian Quigley retweeted

May 29
For those of you who think macrophages do almost everything, rethink “almost.”
They are programmable cells, recruited into whatever new function evolution needs.
science.org/doi/10.1126/scie…
4
68
290
72,012
Ian Quigley retweeted

May 29
We built a joint experimental and computational platform for scalable multi-modal single-cell chemical screens — profiling RNA, protein (including phospho-signaling), and chromatin accessibility responses to thousands of small molecule perturbations in parallel. biorxiv.org/content/10.64898…

2
40
180
13,661


May 20
Physical dynamics of proteins in an intact tissue measured over time, driven by cytoskeletal interactions.
Biology like this is why virtual cell efforts are woefully incomplete. Nobody is able to detect this kind of stuff at scale! (1/n)
May 19

💥 🚀 New preprint! 🎉🥳
How do hundreds of organelles organize themselves into near-perfect patterns inside a cell, without a blueprint? We dive deep into how basal bodies (BBs) self-organize in MCCs - and how actin actively tunes their dynamics into order 🍪
🧵👇 (1/17)
1
3
232
May 20
Being thoughtful about what we can model from existing measurement modalities is going to be how we help patients in the near term, and we should also be thoughtful about what technologies to build to measure things we can't model yet.
1
1
48
May 20
So let's help where we can now, and invent ways to measure things where we can't. A mechanistic model of a cell is probably going to be pretty bad right now, since we can't possibly measure all of the important aspects. (n/n)
1
1
45