
AI Research & Policy @huggingface 🤗 . Leading: @evaluatingevals @huggingscience
Joined January 2012
- Tweets 5,878
- Following 1,553
- Followers 2,943
- Likes 29,621
607 Photos and videos








Pinned Tweet

Jun 11
There are few moments in my professional career where I have stopped to take a look around and say "wow, we really did that". Today is such a day. Evaluation Cards, a project that I've been working towards for more than two years now, out in beta today, and it's yours now.
Back in 2024, in a tiny room in Vancouver at the Neurips @evaluatingevals workshop, I remember expressing frustration at the broken eval landscape: people were releasing benchmarks with no reproducibility methods, they were scattered across leaderboards, 200 page system cards, and other paraphernelia. We realized it is a problem and we formed this wonderful coalition to try and solve that.
Two years later, we have 500 members, a common schema to report evaluations in (that is still being hotly debated and evolving, but that's what nerds do) and finally, we have a tool that we hope the actors across the evals research and technical governance ecosystem can use to confidently consume and work on evals. 100K eval results and several design iterations later, this feels like a good time to open it up to the world.
This is only the beginning! This is a community effort, and for this to be a long running sustainable thing, we need help! If you are a model developer who has eval results in your system card, please send us your eval runs and they will automagically appear on the eval card for your model with interactive, embeddable plots and stats! If you are an evaluator of models and are already releasing detailed eval reports for models, send us your eval runs via your official Hugging Face account and we will list you as a verified evaluator and show your results on the leaderboards and model pages within Eval Cards! We have worked hard on a process that is fairly automated, so once you develop an adapter, we can just auto pull from you every time you release new evals, and they all appear in one single place.
We have a ways to go! Hopefully this standardization work helps the community. We can't wait to hear what you think :D
A lot of incredible people were involved in this work, who I will run out of space to tag here, but want to specifically call out the co-leads on the work - @AnkaReuel, Jenny Chim, Wm Matthew Kennedy, PhD, and my amazing co-hosts at EvalEval @IreneSolaiman @BlancheMinerva and @ZeerakTalat, who created a home for this work and who make doing eval science in the public interest such a fun job. 💙
evalevalai.com/infrastructur…
1
2
17
547
The hardware competition is heating up! AMD’s been doing fantastic work recently.
Plot source: huggingface.co/spaces/hfpoli…
20h

AMD CEO LISA SU HELD A MINI PC ON STAGE THAT RUNS A 235B MODEL AND REPLACES YOUR $440/MONTH AI STACK
amd's ryzen ai max 395 is the first x86 chip that runs a 200 billion parameter model on one piece of silicon. cpu and gpu share 128gb of unified memory, no separate graphics card needed
the gmktec evo-x2 runs qwen3 235b fully, deepseek v3 comfortably and llama 3.3 70b with headroom. on linux you get 110gb of usable vram out of 128gb
amd claimed the chip beat an nvidia rtx 5080 by more than 3x on deepseek r1 inference. a lunchbox sized pc outrunning a $1,000 discrete gpu on a real ai workload
a heavy ai user pays $200 for claude code max, $200 for chatgpt pro, $20 for cursor and $20 for gemini. that's $5,280 a year and the box pays itself off in 9 to 10 months
install ollama, pull the model, point claude code at localhost. same interface, nothing leaves the machine, nothing costs per request
bookmark this and read the article below
3
3
123
Avijit Ghosh retweeted

22h
So glad the Scottish are in Boston
Maybe the best fanbase fit to a city for the entire World Cup
100
516
9,336
392,318
Jun 13
The title/framing is kinda deceptive. Medical information is not medical AI writ large, it’s information retrieval, which a larger model or a model with a good harness or both has a better chance to succeed in. This doesn’t mean that say raw ChatGPT is better at protein folding.
Jun 12

Medicine discovers the bitter lesson: frontier LLMs (here GPT 5.2, Opus 4.6, Gemini 3.1) outperform specialized "clinical AI" (e.g. OpenEvidence) in a blind test.
Even funnier that hospital IT are more likely to approve the *specialized* versions despite them being worse.

1
1
653
Jun 13
It’s an interesting finding! But idk if being good at MedQA benchmark means being good at all of medical AI 🤷♂️ Maybe it’s the semantics that bother me a bit here. Terms like IR were far more specific but now everything is AI and muddies discourse among non experts.
1
1
265
Jun 12
Congrats to the @MiniMax_AI team! They always have the prettiest eval plots, and their model cards heavily inspired the histogram grid design on eval cards :)
You can embed them in your own releases!

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

5
187
Jun 12
There’s a whole another race going on below the frontier on local/edge devices and on efficiency. Wake it up!
Jun 12

DiffusionGemma can now run at 2000 tokens/sec! ⚡
We made local DiffusionGemma inference 1.8× faster.
Run it on 18GB RAM via Unsloth Studio.
GitHub: github.com/unslothai/unsloth
Guide: unsloth.ai/docs/models/diffu…
1
4
226
Avijit Ghosh retweeted

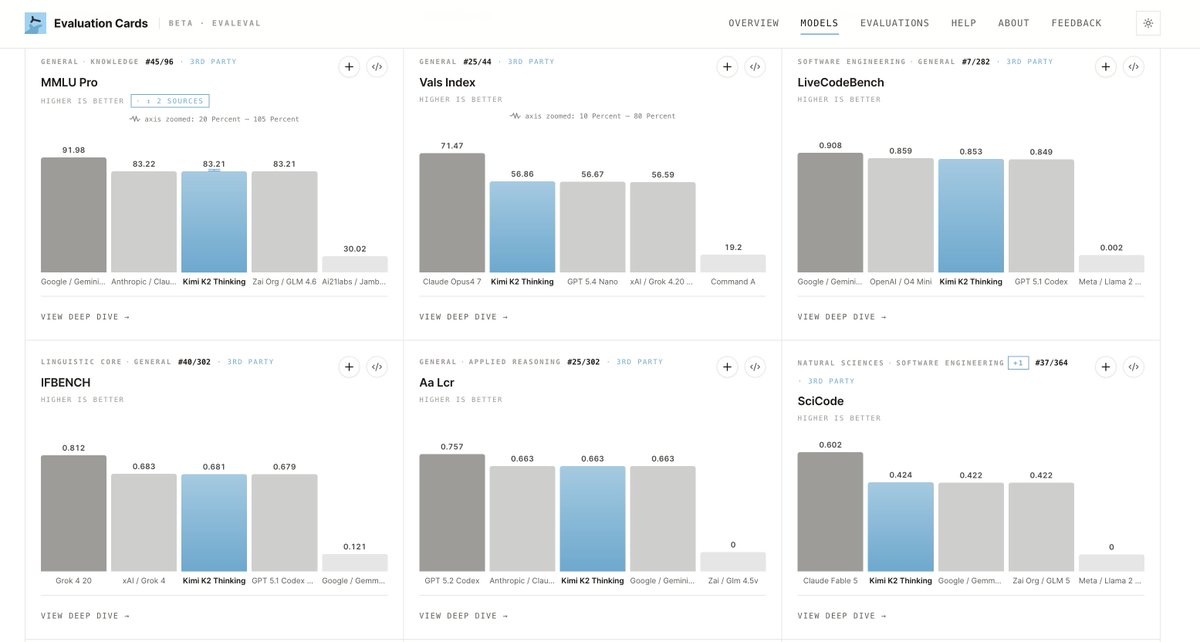
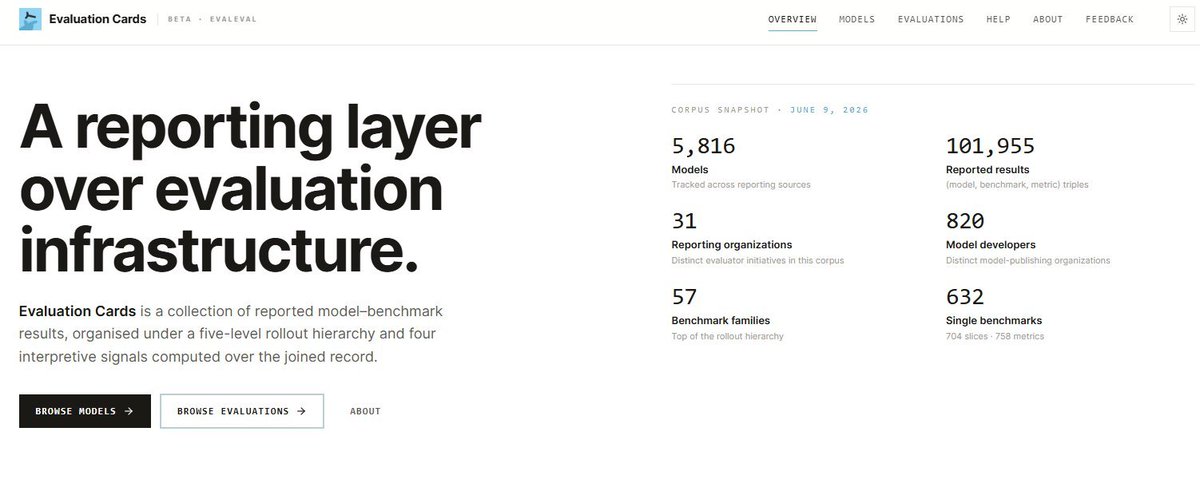
🚀We launch Evaluation Cards (beta): a centralized public record of AI evaluation results 🚀
Not another leaderboard. Every score comes with who ran it, the settings they used, what the benchmark tests and the other results reported for the same model, side by side. 🧵👇
4
12
34
5,601
Jun 11
There are few moments in my professional career where I have stopped to take a look around and say "wow, we really did that". Today is such a day. Evaluation Cards, a project that I've been working towards for more than two years now, out in beta today, and it's yours now.
Back in 2024, in a tiny room in Vancouver at the Neurips @evaluatingevals workshop, I remember expressing frustration at the broken eval landscape: people were releasing benchmarks with no reproducibility methods, they were scattered across leaderboards, 200 page system cards, and other paraphernelia. We realized it is a problem and we formed this wonderful coalition to try and solve that.
Two years later, we have 500 members, a common schema to report evaluations in (that is still being hotly debated and evolving, but that's what nerds do) and finally, we have a tool that we hope the actors across the evals research and technical governance ecosystem can use to confidently consume and work on evals. 100K eval results and several design iterations later, this feels like a good time to open it up to the world.
This is only the beginning! This is a community effort, and for this to be a long running sustainable thing, we need help! If you are a model developer who has eval results in your system card, please send us your eval runs and they will automagically appear on the eval card for your model with interactive, embeddable plots and stats! If you are an evaluator of models and are already releasing detailed eval reports for models, send us your eval runs via your official Hugging Face account and we will list you as a verified evaluator and show your results on the leaderboards and model pages within Eval Cards! We have worked hard on a process that is fairly automated, so once you develop an adapter, we can just auto pull from you every time you release new evals, and they all appear in one single place.
We have a ways to go! Hopefully this standardization work helps the community. We can't wait to hear what you think :D
A lot of incredible people were involved in this work, who I will run out of space to tag here, but want to specifically call out the co-leads on the work - @AnkaReuel, Jenny Chim, Wm Matthew Kennedy, PhD, and my amazing co-hosts at EvalEval @IreneSolaiman @BlancheMinerva and @ZeerakTalat, who created a home for this work and who make doing eval science in the public interest such a fun job. 💙
evalevalai.com/infrastructur…
1
2
17
547
Jun 11
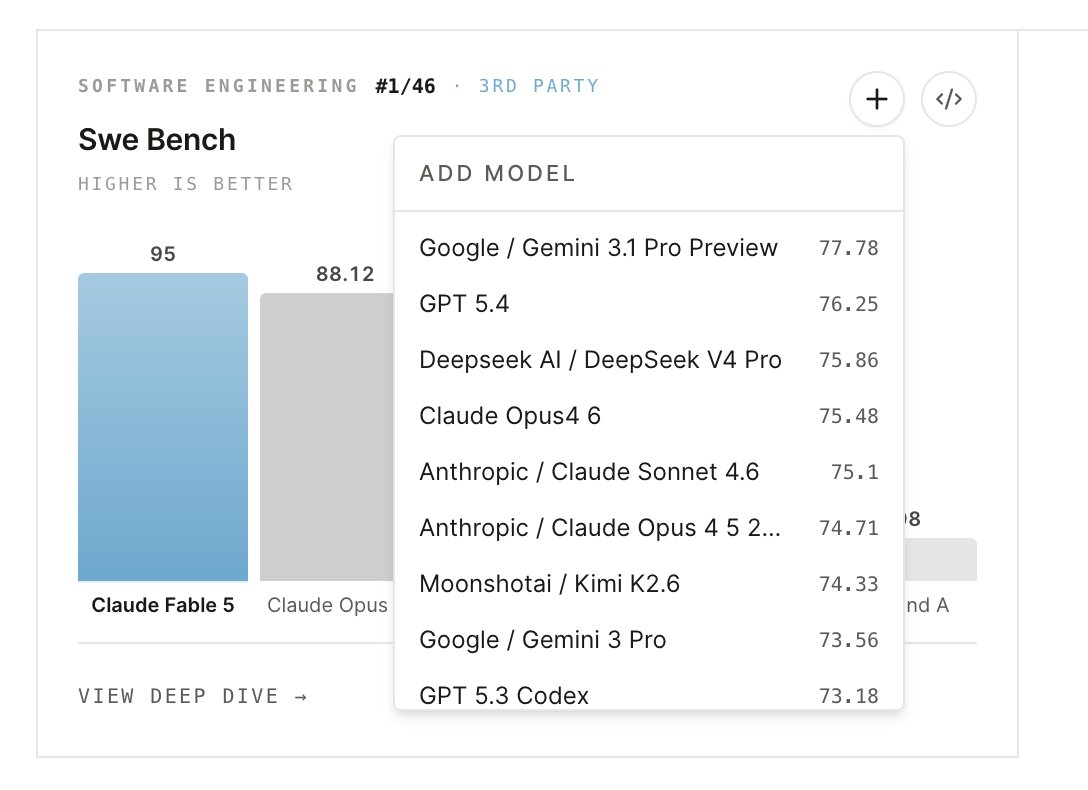
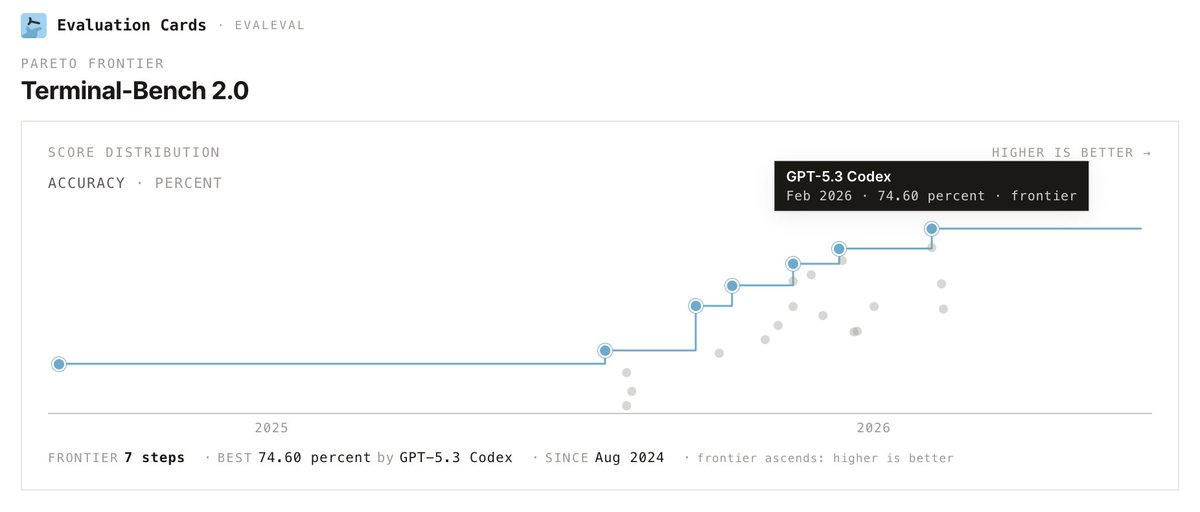
Check out the beta: evalcards.evalevalai.com/
And you can already add the interactive plots and leaderboards in your own work! Just hit the embed button </>, copy the code and paste in your report, and you should have a live plot that grows with time and adds more models!
1
259
Jun 10
Is it really meaningful transparency if a frontier lab publishes a bunch of evals in their system card without enough details to reproduce the numbers by independent third-party researchers?
More on this, and our work to combat this (at @evaluatingevals) coming out tomorrow!
1
4
143
Jun 9
My whole timeline is full of posts like these. OSS seems to be the only way out to democratize the future of participation in AI building 🫶
Jun 9

First they came for the model builders...
I feel we're getting a glimpse of a future where AI is only provided to a privileged few, and that's not a future I want to live in.
1
5
305
Jun 8
This is a fairly obvious observation but I am so glad someone measured it systematically so we can point to this. Nice!
Jun 8

From op-eds in newspapers to NeurIPS position papers, AI is increasingly shaping long-form public discourse. Its arguments seem plausible, but beneath surface fluency, we find argument collapse: different LLMs converge to the same main & supporting arguments and structure.

3
11
1,183
Avijit Ghosh retweeted

Jun 7
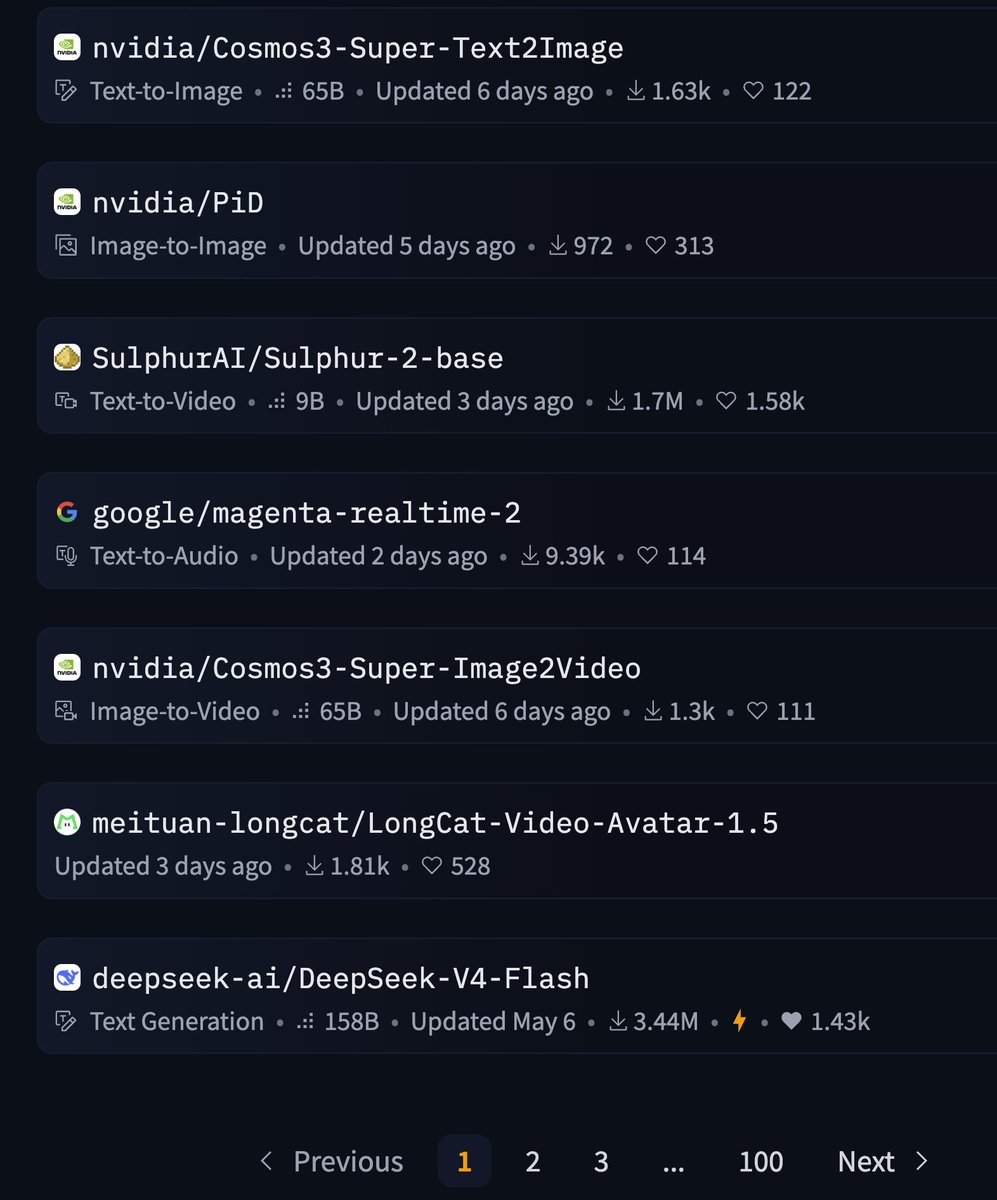
Slowly, then suddenly!

American Open Source is so back.
9 / 30 of the models on page 1 of Huggingface are published by Nvidia.
9
12
181
23,733


Jun 6
Irrespective of the deeper context of this, fun fact about evals: nobody reads benchmark questions and their rubrics, and it is often the case that the person who designs the bench and the person who designs the question (domain expert) are different, causing subtle differences in the rubric, or sometimes even egregious errors that create impossible questions in your favorite benchmarks.
Please read the data, you’re not above it especially if you’re a serious researcher. Remember Karpathy was once famously the human baseline on imagenet 😊
Jun 6

Just learned:
Software engineers used to do manual data labeling at Scale AI while Alex Wang was CEO. After he left, new leadership joined, and were HORRIFIED to learn this. Stopped it ASAP
Now at Meta, software engineers are assigned manual data labeling... see the pattern?
1
4
28
5,199
Jun 6
Fascinating how many unitree robots are showing up in America - this is what tech diffusion looks like (American robotics companies pls step up)
Jun 4

Knicks fans are insane 😭😭😭
“My Mayor is Muslim, my bagel is Jewish, my Christian’s Dior… Knicks in 4!!!”
1
390
Jun 5
This is so sad :(
Jun 4

It took me two weeks to onboarding for my internship at Microsoft, somehow, my collaborators relies too much on the agent to fix everything for them, such that they can't explain how things really works or have some basic understanding in what's blocking me.
Though they offered to meet in person and help me "solve the problem together", and when we meet, they prompt their agent while I ackwardly watching with them or they asked me to prompt my agent while they ackwardly watching with me.
Why don't I just prompt my agent for everything to save both of our time?
Both the learning and human interaction are missing gradually.
1
456
Jun 4
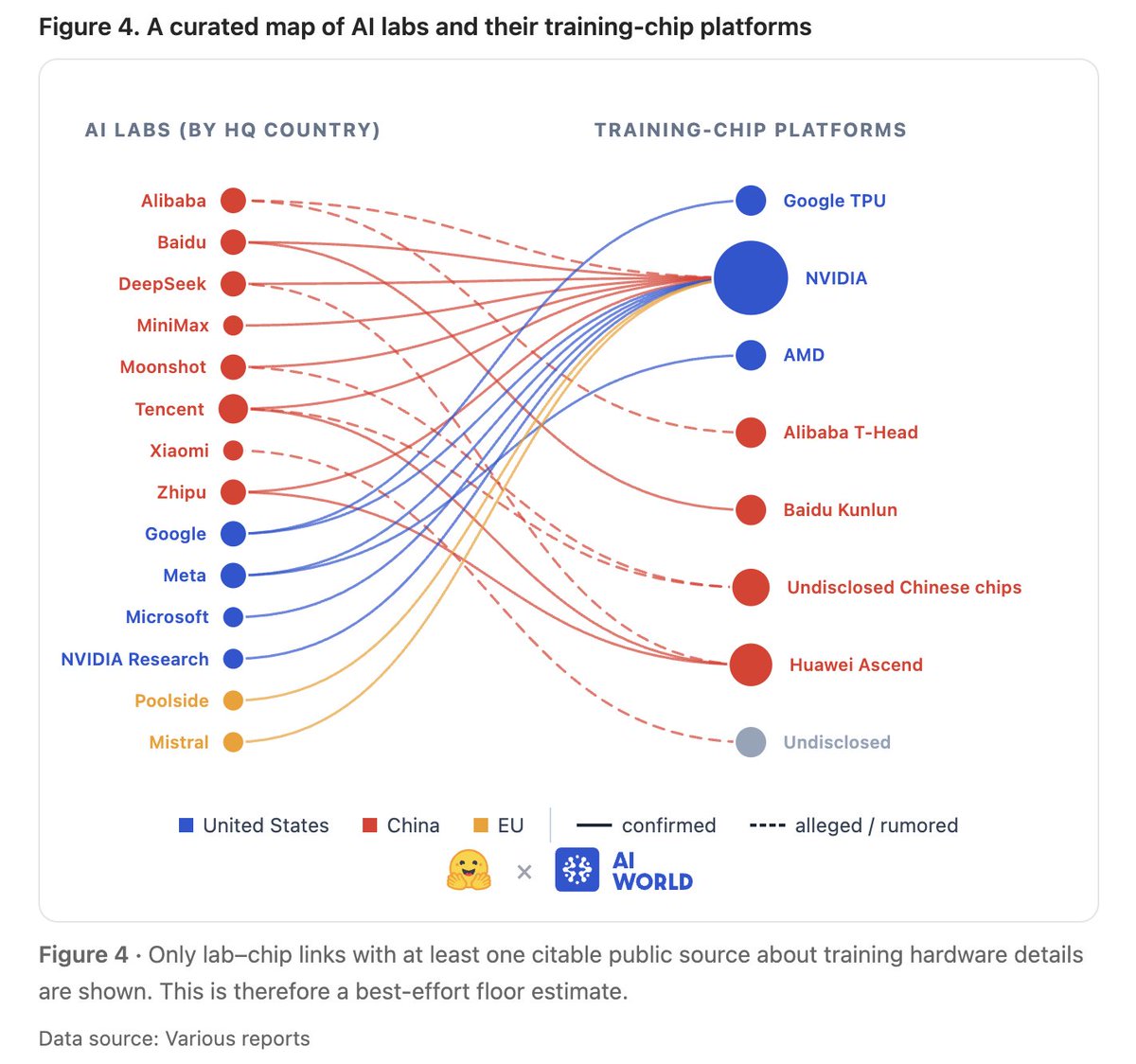
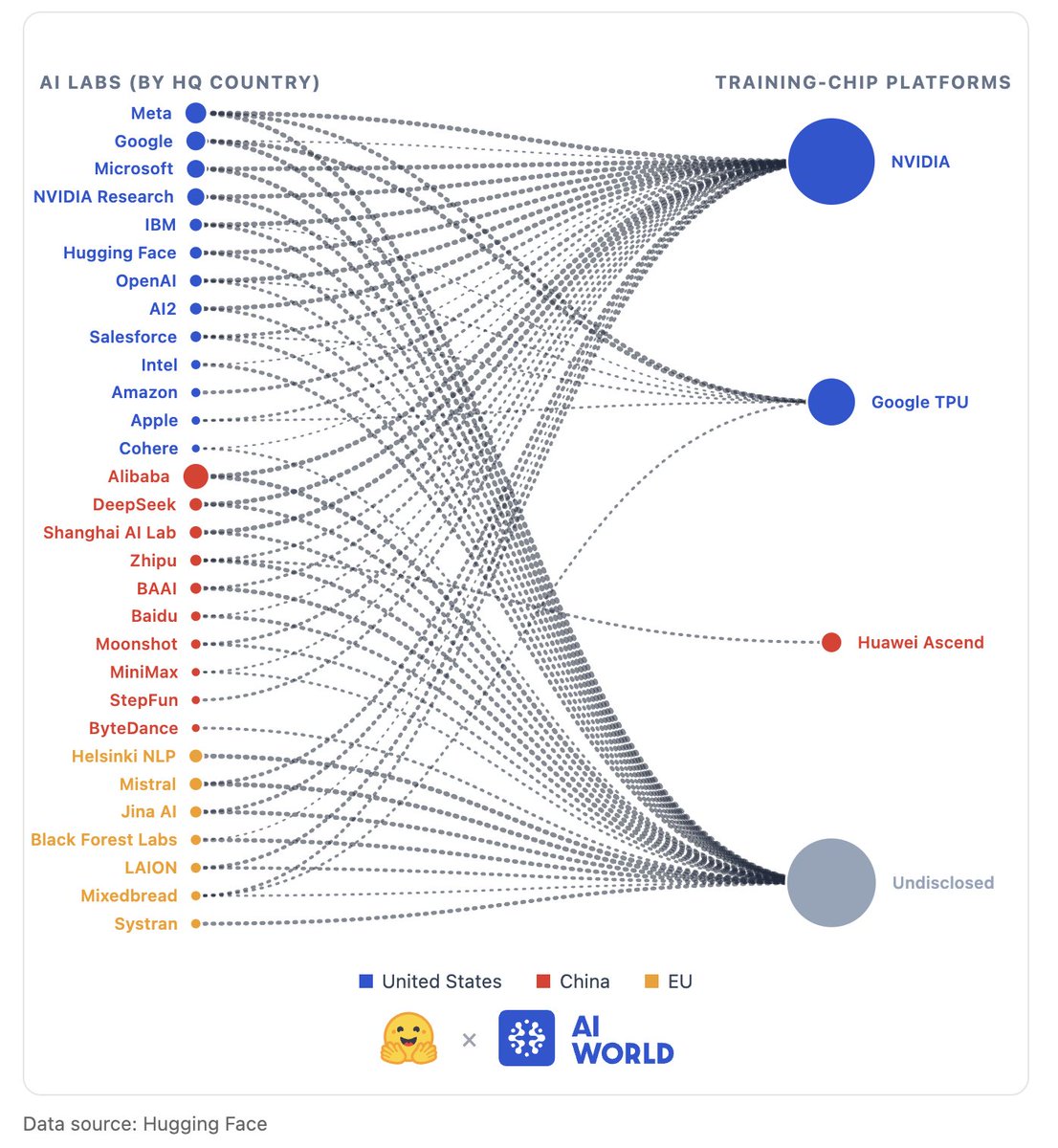
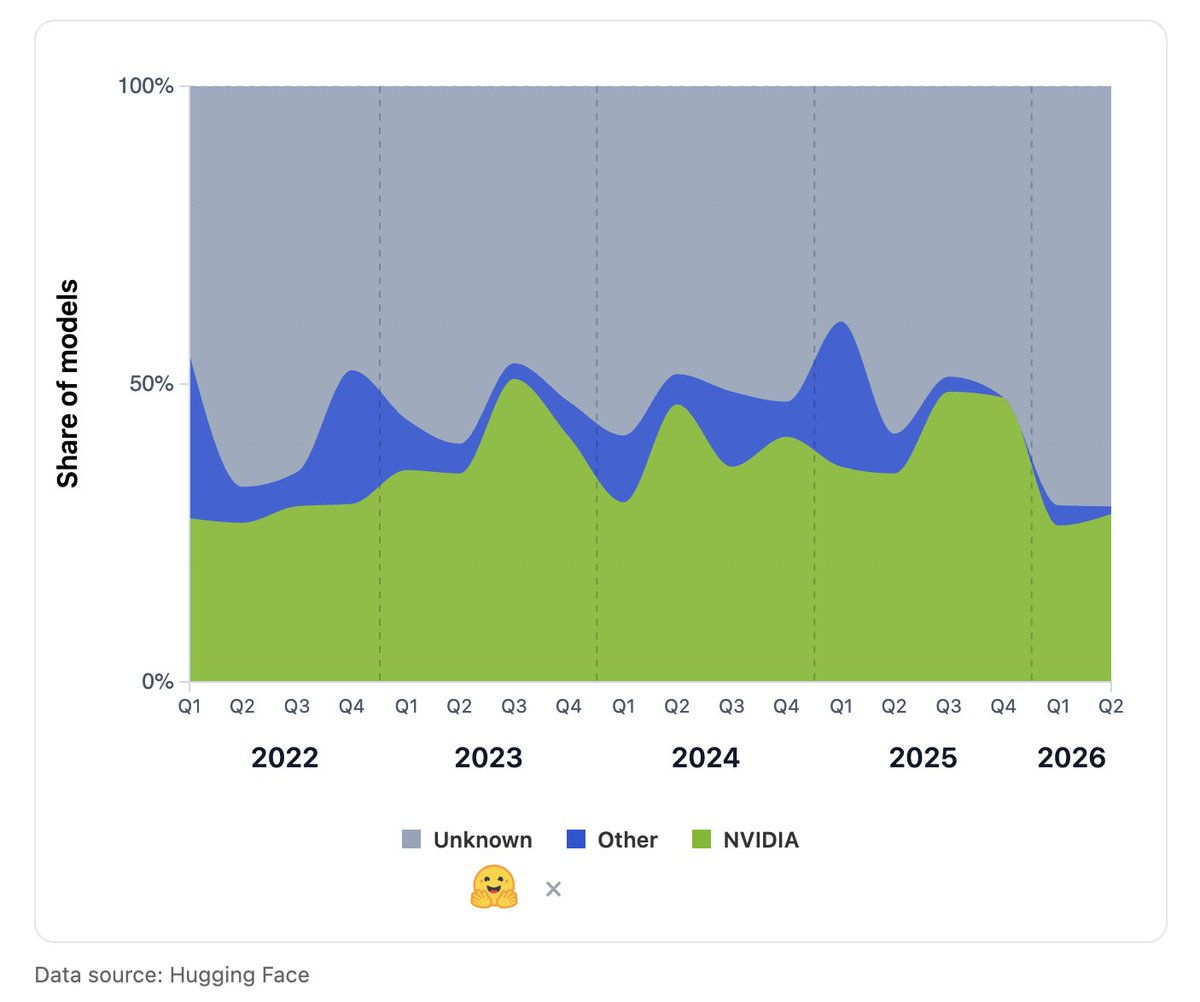
🚨 New article: "AI Hardware Choices are Highly Variable and Sparsely Disclosed", joint work from @huggingface policy and @CEPS_thinktank, in which we look into the fragmented information about training and inference hardware choices in AI, and their tech/policy implications.
1
2
2
520
Jun 4
We call for more transparent hardware disclosure from model trainers and inference providers, as we collectively continue to make sense of this evolving landscape.
1
65
Jun 4
Lots more content, and open code and data in the article! Dream collab with Francisco Ríos , @IJ_Reynolds , @robertpraas , and @IreneSolaiman.
huggingface.co/spaces/hfpoli…
1
81